Foglio di controllo per il pool SQL dedicato (in precedenza SQL DW) in Azure Synapse Analytics
Questo foglio informativo fornisce suggerimenti utili e procedure consigliate per creare rapidamente soluzioni pool SQL dedicato (in precedenza Azure SQL Data Warehouse).
Il grafico seguente illustra il processo di progettazione di un data warehouse con un pool SQL dedicato (in precedenza SQL Data Warehouse):
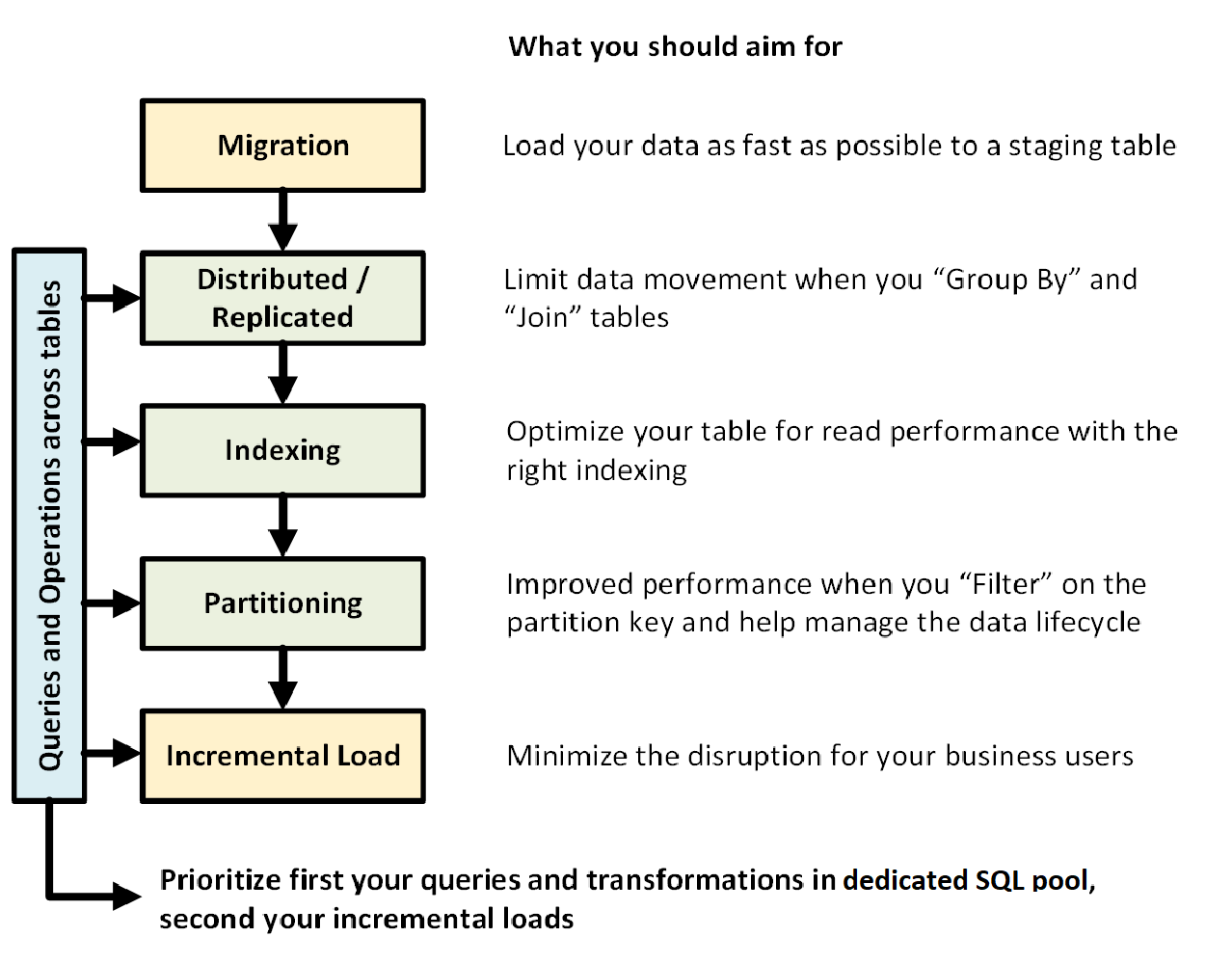
Query e operazioni tra tabelle
Se si conoscono in anticipo le operazioni e le query principali da eseguire nel data warehouse, è possibile definire la priorità dell'architettura del data warehouse per queste operazioni. Queste query e operazioni possono includere:
- Join di una o due tabelle dei fatti con tabelle delle dimensioni, applicazione di un filtro alla tabella combinata e aggiunta dei risultati in un data mart.
- Aggiornamenti di lieve o notevole entità alle vendite dei fatti.
- Accodamento di soli dati alle tabelle.
Conoscere in anticipo il tipo di operazioni consente di ottimizzare la progettazione delle tabelle.
Migrazione dei dati
Prima di tutto, caricare i dati in Azure Data Lake Store o in Archiviazione BLOB di Azure. Usare quindi l'istruzione COPY per caricare i dati nelle tabelle di staging. Usare la configurazione seguente:
| Progettazione | Recommendation |
|---|---|
| Distribuzione | Round robin |
| Indicizzazione | Heap |
| Partizionamento | nessuno |
| Classe di risorse | largerc o xlargerc |
Sono disponibili altre informazioni sulla migrazione dei dati, sul caricamento dei dati e sul processo di estrazione, caricamento e trasformazione (ELT - Extract, Load, and Transform).
Tabelle distribuite o replicate
A seconda delle proprietà della tabella usare le strategie seguenti:
| Type | Ideale per... | Prestare attenzione se... |
|---|---|---|
| Replicata | * Tabelle delle dimensioni ridotte in uno schema star con meno di 2 GB di spazio di archiviazione dopo la compressione (compressione di circa 5 volte) | * Molte transazioni di scrittura si trovano nella tabella (ad esempio insert, upsert, delete, update) * Si modifica Data Warehouse Unità di provisioning (DWU) di frequente * Si usano solo colonne 2-3, ma la tabella include molte colonne * Si indicizza una tabella replicata |
| Round robin (predefinita) | * Tabella temporanea/staging * Nessuna chiave di aggiunta ovvia o colonna valida candidato |
* Le prestazioni sono lente a causa del movimento dei dati |
| Hash | * Tabelle dei fatti * Tabelle di dimensioni di grandi dimensioni |
* La chiave di distribuzione non può essere aggiornata |
Suggerimenti:
- Iniziare con round robin ma mirare a una strategia di distribuzione hash per sfruttare i vantaggi di un'architettura parallela elevata.
- Assicurarsi che le chiavi hash comuni abbiano lo stesso formato di dati.
- Non eseguire la distribuzione in formato varchar.
- Le tabelle delle dimensioni con chiave hash comune in una tabella dei fatti con operazioni di join frequenti possono essere distribuite tramite hash.
- Usare sys.dm_pdw_nodes_db_partition_stats per analizzare eventuali asimmetrie nei dati.
- Usare sys.dm_pdw_request_steps per analizzare gli spostamenti dei dati protetti da query e monitorare il tempo richiesto dalle operazioni di trasmissione e casuali. È consigliabile rivedere la strategia di distribuzione.
Sono disponibili altre informazioni sulle tabelle replicate e le tabelle distribuite.
Indicizzare la tabella
L'indicizzazione è utile per leggere rapidamente le tabelle. È disponibile un set univoco di tecnologie che è possibile usare in base alle proprie esigenze:
| Type | Ideale per... | Prestare attenzione se... |
|---|---|---|
| Heap | * Tabella di staging/temporanea * Tabelle ridotte con ricerche limitate |
* Qualsiasi ricerca analizza la tabella completa |
| Indice cluster | * Tabelle con meno di 100 milioni di righe * Tabelle estese (più di 100 milioni di righe) con solo 1-2 colonne usate di frequente |
* Usato in una tabella replicata * Sono presenti query complesse che coinvolgono più operazioni join e Group By * Si apportano aggiornamenti sulle colonne indicizzate: richiede memoria |
| Indice columnstore cluster (CCI) (predefinito) | * Tabelle di grandi dimensioni (più di 100 milioni di righe) | * Usato in una tabella replicata * Si apportano operazioni di aggiornamento di grandi dimensioni nella tabella * Si sovrapartiziona la tabella: i gruppi di righe non si estendono tra nodi di distribuzione e partizioni diversi |
Suggerimenti:
- Su un indice cluster si potrebbe voler aggiungere un indice non cluster a una colonna usata di frequente per il filtro.
- Prestare attenzione a come viene gestita la memoria in una tabella con indice columnstore cluster. Quando si caricano i dati, è opportuno che l'utente (o la query) tragga vantaggio da una classe di risorse di grandi dimensioni. Assicurarsi di evitare il trimming e la creazione di molti gruppi di righe compressi di piccole dimensioni.
- In Gen2, le tabelle con indice ColumnStore cluster vengono memorizzati nella cache in locale sui nodi di calcolo per ottimizzare le prestazioni.
- Per l'indice columnstore cluster può verificarsi un rallentamento delle prestazioni a causa della scarsa compressione dei gruppi di righe. In questo caso, ricompilare o riorganizzare l'indice columnstore cluster. Sono necessarie almeno 100.000 righe per gruppi di righe compressi. La soluzione ideale è 1 milione di righe in un gruppo di righe.
- In base alle dimensioni e alla frequenza di caricamento incrementale, è possibile procedere all'automatizzazione quando si riorganizzano o si ricompilano gli indici. È sempre utile fare pulizia.
- Adottare una strategia per il trimming di un gruppo di righe. Quanto devono essere grandi i gruppi di righe aperti? Quanti dati si prevedere di caricare nei prossimi giorni?
Sono disponibili altre informazioni sugli indici.
Partizionamento
È possibile partizionare la tabella in presenza di tabelle dei fatti estese (con oltre 1 miliardo di righe). Nel 99% dei casi la chiave di partizione deve essere basata sulla data.
Con le tabelle di staging che richiedono ELT, è possibile trarre vantaggio dal partizionamento, che facilita la gestione del ciclo di vita dei dati. Prestare attenzione a non sovrapartizionare il fatto o la tabella di staging, soprattutto in un indice columnstore cluster.
Sono disponibili altre informazioni sulle partizioni.
Carico incrementale
Se si intende caricare i dati in modo incrementale, è necessario assicurarsi di allocare le classi di risorse di dimensioni maggiori al caricamento dei dati. Questa operazione è particolarmente importante quando si esegue il caricamento in tabelle con indici columnstore cluster. Per altri dettagli, vedere le classi di risorse.
È consigliabile usare PolyBase e ADF V2 per automatizzare le pipeline di ELT nel data warehouse.
Per un grande batch di aggiornamenti nei dati cronologici, prendere in considerazione l'uso di CTAS per scrivere i dati da mantenere in una tabella, invece di usare INSERT, UPDATE e DELETE.
Gestire le statistiche
È importante aggiornare le statistiche quando vengono apportate modifiche significative ai dati. Per determinare se sono state apportate modifiche significative, vedere Aggiornare le statistiche. Statistiche aggiornate consentono di ottimizzare i piani di query. Se si ritiene che la gestione di tutte le statistiche richieda troppo tempo, scegliere in modo più selettivo le colonne con le statistiche.
È anche possibile definire la frequenza degli aggiornamenti. Potrebbe ad esempio essere consigliabile aggiornare le colonne di data, in cui potrebbero venire aggiunti nuovi valori su base giornaliera. Il massimo vantaggio è offerto dalle statistiche sulle colonne usate nei join, su quelle usate nella clausola WHERE e sulle colonne presenti in GROUP BY.
Sono disponibili altre informazioni sulle statistiche.
classe di risorse
I gruppi di risorse vengono usati come un modo per allocare memoria alle query. Se si necessita di maggiore memoria per migliorare la velocità di caricamento o delle query, è consigliabile allocare più classi di risorse. D'altra parte, l'uso di classi di risorse di dimensioni maggiori incide sulla concorrenza. È consigliabile prendere in considerazione questo aspetto prima di spostare tutti gli utenti in una classe di risorse di grandi dimensioni.
Se si nota che le query richiedono troppo tempo, verificare che gli utenti non vengano eseguiti in classi di risorse di grandi dimensioni. Le classi di risorse estese usano molti slot di concorrenza e possono comportare l'accodamento di altre query.
Infine, con la versione Gen2 del pool SQL dedicato (in precedenza SQL Data Warehouse), ogni classe di risorse ottiene 2,5 volte di memoria in più rispetto a Gen1.
Sono disponibili altre informazioni su come lavorare con classi di risorse e concorrenza.
Ridurre i costi
Una funzionalità chiave di Azure Synapse è la possibilità di gestire le risorse di calcolo. È possibile sospendere il pool SQL dedicato (in precedenza SQL Data Warehouse) quando non è in uso, interrompendo così la fatturazione delle risorse di calcolo. È possibile ridimensionare le risorse per soddisfare le richieste di prestazioni. Per sospendere, usare il portale di Azure o PowerShell. Per dimensionare, usare il portale di Azure, PowerShell, T-SQL o un'API REST.
Procedere ora al ridimensionamento automatico in corrispondenza del momento desiderato con Funzioni di Azure:

Ottimizzare l'architettura per le prestazioni
È consigliabile prendere in considerazione il database SQL e Azure Analysis Services in un'architettura hub-spoke. Questa soluzione può fornire l'isolamento del carico di lavoro tra gruppi di utenti diversi, usando anche alcune funzionalità di protezione avanzate del database SQL e di Azure Analysis Services. Anche questo è un modo per fornire concorrenza illimitata agli utenti.
Vedere altre informazioni sulle architetture tipiche che traggono vantaggio dal pool SQL dedicato (in precedenza SQL Data Warehouse) in Azure Synapse Analytics.
Distribuire con un clic del mouse gli spoke nei database SQL dal pool SQL dedicato (in precedenza SQL Data Warehouse):