Ottimizzare le prestazioni aggiornando il pool SQL dedicato (in precedenza SQL Data Warehouse) in Azure Synapse Analytics
Aggiornare il pool SQL dedicato (in precedenza SQL Data Warehouse) alla generazione più recente dell'architettura di archiviazione e hardware di Azure.
Ragioni dell'aggiornamento
È ora possibile eseguire facilmente l'aggiornamento al livello Gen2 con ottimizzazione per il calcolo del pool SQL dedicato (in precedenza SQL Data Warehouse) nel portale di Azure per le aree supportate. Se l'area non supporta l'aggiornamento automatico, è possibile eseguire l'aggiornamento a un'area supportata o attendere la disponibilità dell'aggiornamento autonomo nella propria area. Eseguire subito l'aggiornamento per sfruttare i vantaggi della generazione più recente di hardware e architettura di archiviazione migliorata di Azure, che include prestazioni più veloci, una maggiore scalabilità e archiviazione a colonne illimitata.
Importante
Questo aggiornamento si applica ai pool SQL dedicati (in precedenza SQL Data Warehouse) di livello Gen1 con ottimizzazione per il calcolo nelle aree supportate.
Operazioni preliminari
Controllare se l'area è supportata per la migrazione da Gen1 a Gen2. Tenere presente le date di migrazione automatica. Per evitare conflitti con il processo automatizzato, pianificare la migrazione manuale prima della data di inizio processo automatizzato.
Se ci si trova in un'area non è ancora supportata, continuare a controllare che la propria area venga aggiunta oppure eseguire l'aggiornamento tramite ripristino in un'area supportata.
Se l'area è supportata, eseguire l'aggiornamento tramite il portale di Azure
Selezionare il livello di prestazioni consigliato per il pool SQL dedicato (in precedenza SQL Data Warehouse) in base al livello di prestazioni corrente del livello Gen1 con ottimizzazione per il calcolo usando il mapping seguente:
Livello Gen1 con ottimizzazione per il calcolo Livello Gen2 con ottimizzazione per il calcolo DW100 DW100c DW200 DW200c DW300 DW300c DW400 DW400c DW500 DW500c DW600 DW500c DW1000 DW1000c DW1200 DW1000c DW1500 DW1500c DW2000 DW2000c DW3000 DW3000c DW6000 DW6000c
Nota
I livelli di prestazioni consigliati non sono una conversione diretta. Ad esempio, è consigliabile passare da DW600 DW500c.
Eseguire l'aggiornamento in un'area supportata tramite portale di Azure
- La migrazione da Gen1 a Gen2 tramite il portale di Azure è permanente. Non esiste un processo per tornare a Gen1.
- Il pool SQL dedicato (in precedenza SQL Data Warehouse) deve essere in esecuzione per eseguire la migrazione a Gen2
Operazioni preliminari
Nota
È consigliabile usare il modulo Azure Az PowerShell per interagire con Azure. Per iniziare, vedere Installare Azure PowerShell. Per informazioni su come eseguire la migrazione al modulo AZ PowerShell, vedere Eseguire la migrazione di Azure PowerShell da AzureRM ad Az.
- Accedere al portale di Azure.
- Assicurarsi che il pool SQL dedicato (in precedenza SQL Data Warehouse) sia in esecuzione. Questa condizione è necessaria per eseguire la migrazione a Gen2
Comandi di aggiornamento di PowerShell
Se il pool SQL dedicato (in precedenza SQL Data Warehouse) di livello Gen1 con ottimizzazione per il calcolo da aggiornare viene sospeso, riprendere il pool SQL dedicato (in precedenza SQL Data Warehouse).
Questa operazione potrebbe comportare alcuni minuti di inattività.
Identificare tutti i riferimenti del codice ai livelli di prestazioni Gen1 con ottimizzazione per il calcolo e modificarli impostando il livello di prestazioni equivalente Gen2 con ottimizzazione per il calcolo. Di seguito sono riportati due esempi di in cui è necessario aggiornare i riferimenti del codice prima dell'aggiornamento:
Comando Gen1 PowerShell originale:
Set-AzSqlDatabase -ResourceGroupName "myResourceGroup" -DatabaseName "mySampleDataWarehouse" -ServerName "mynewserver-20171113" -RequestedServiceObjectiveName "DW300"Modificato come segue:
Set-AzSqlDatabase -ResourceGroupName "myResourceGroup" -DatabaseName "mySampleDataWarehouse" -ServerName "mynewserver-20171113" -RequestedServiceObjectiveName "DW300c"Nota
-RequestedServiceObjectiveName "DW300" diventa RequestedServiceObjectiveName "DW300c"
Comando Gen1 T-SQL originale:
ALTER DATABASE mySampleDataWarehouse MODIFY (SERVICE_OBJECTIVE = 'DW300') ;Modificato come segue:
ALTER DATABASE mySampleDataWarehouse MODIFY (SERVICE_OBJECTIVE = 'DW300c') ;Nota
SERVICE_OBJECTIVE = 'DW300' diventa SERVICE_OBJECTIVE = 'DW300c'
Avviare l'aggiornamento
Passare al pool SQL dedicato (in precedenza SQL Data Warehouse) di livello Gen1 ottimizzato per il calcolo nel portale di Azure. Se il pool SQL dedicato (in precedenza SQL Data Warehouse) di livello Gen1 con ottimizzazione per il calcolo da aggiornare viene sospeso, riprendere il pool SQL dedicato.
Selezionare la scheda Aggiorna alla seconda generazione nella scheda attività:
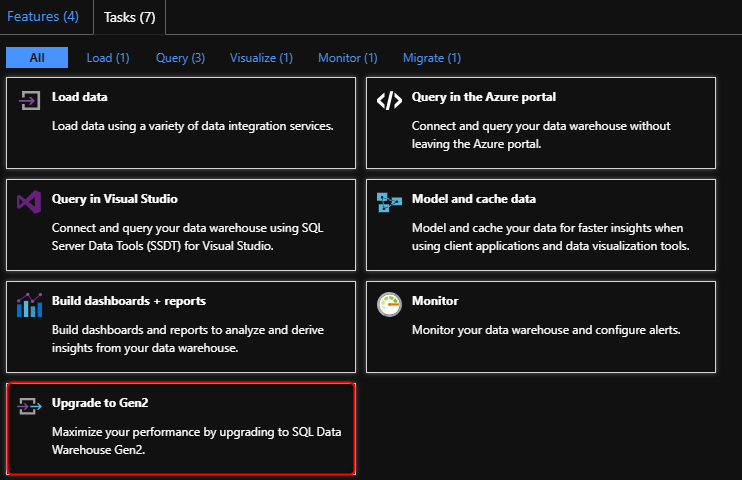
Nota
Se la scheda Aggiorna alla seconda generazione non è visualizzata sotto la scheda Attività, il tipo di sottoscrizione è limitato nell'area corrente. Inviare un ticket di supporto per ottenere l'approvazione della sottoscrizione.
Assicurarsi che il carico di lavoro abbia completato l'esecuzione e sia inattivo prima dell'aggiornamento. Si avrà un tempo di inattività per alcuni minuti prima che il pool SQL dedicato (in precedenza SQL Data Warehouse) sia di nuovo online come pool SQL dedicato (in precedenza SQL Data Warehouse) di livello Gen2 con ottimizzazione per il calcolo. Selezionare l'aggiornamento:

Monitorare l'aggiornamento controllando lo stato nel portale di Azure:
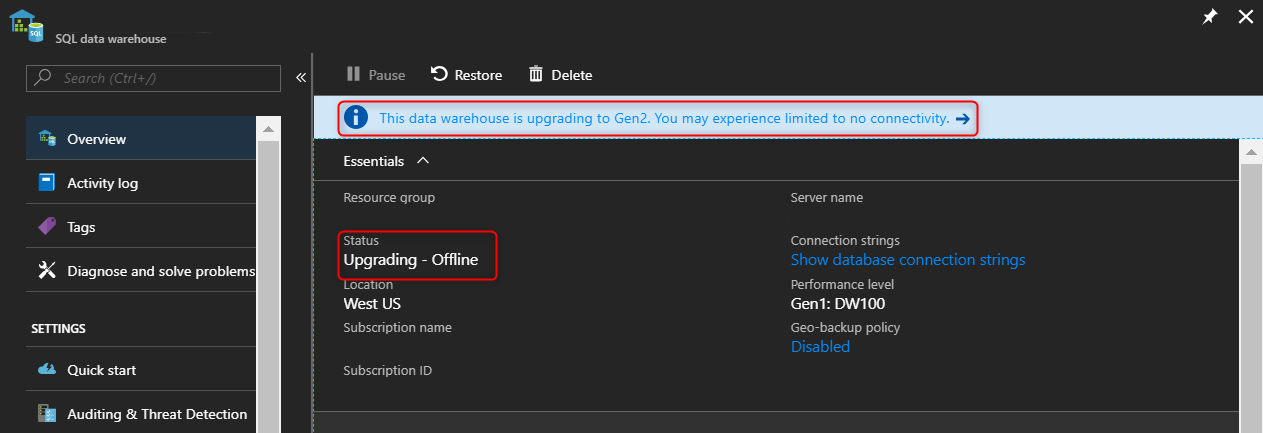
Il primo passaggio del processo di aggiornamento prevede l'operazione di ridimensionamento ("Aggiornamento - Offline") in cui verranno terminate tutte le sessioni ed interrotte tutte le connessioni.
Il secondo passaggio del processo di aggiornamento è la migrazione dei dati ("Aggiornamento - Online"). La migrazione dei dati è un processo in background con flusso irregolare. Questo processo sposta lentamente i dati a colonne dall'architettura di archiviazione precedente alla nuova architettura di archiviazione usando la cache SSD locale. Durante questo periodo, il pool SQL dedicato (in precedenza SQL Data Warehouse) sarà online per l'esecuzione di query e caricamenti. I dati saranno disponibili per le query indipendentemente dal fatto che sia stata o meno completata la migrazione. La migrazione dei dati avviene a velocità variabili a seconda delle dimensioni dei dati, del livello di prestazioni e del numero di segmenti columnstore.
Raccomandazione facoltativa: al termine dell'operazione di ridimensionamento, è possibile velocizzare il processo in background di migrazione dei dati. È possibile forzare immediatamente lo spostamento dei dati eseguendo ALTER INDEX REBUILD su tutte le tabelle columnstore primarie su cui si prevede di eseguire query, con SLO e classe di risorse più grandi. Questa operazione è offline, confrontata con il processo un processo in background con flusso irregolare, che può richiedere ore a seconda di numero e dimensione delle tabelle. Tuttavia, al termine dell'operazione la migrazione dei dati sarà molto più veloce per via della nuova architettura di archiviazione migliorata con gruppi di righe di qualità elevata.
Nota
ALTER INDEX REBUILD è un'operazione offline, pertanto le tabelle non saranno disponibili fino al completamento della ricompilazione.
La query seguente genera i comandi Alter Index Rebuild necessari per velocizzare la migrazione dei dati:
SELECT 'ALTER INDEX [' + idx.NAME + '] ON ['
+ Schema_name(tbl.schema_id) + '].['
+ Object_name(idx.object_id) + '] REBUILD ' + ( CASE
WHEN (
(SELECT Count(*)
FROM sys.partitions
part2
WHERE part2.index_id
= idx.index_id
AND
idx.object_id =
part2.object_id)
> 1 ) THEN
' PARTITION = '
+ Cast(part.partition_number AS NVARCHAR(256))
ELSE ''
END ) + '; SELECT ''[' +
idx.NAME + '] ON [' + Schema_name(tbl.schema_id) + '].[' +
Object_name(idx.object_id) + '] ' + (
CASE
WHEN ( (SELECT Count(*)
FROM sys.partitions
part2
WHERE
part2.index_id =
idx.index_id
AND idx.object_id
= part2.object_id) > 1 ) THEN
' PARTITION = '
+ Cast(part.partition_number AS NVARCHAR(256))
+ ' completed'';'
ELSE ' completed'';'
END )
FROM sys.indexes idx
INNER JOIN sys.tables tbl
ON idx.object_id = tbl.object_id
LEFT OUTER JOIN sys.partitions part
ON idx.index_id = part.index_id
AND idx.object_id = part.object_id
WHERE idx.type_desc = 'CLUSTERED COLUMNSTORE';
Eseguire l'aggiornamento da un'area geografica di Azure con l'esecuzione del ripristino tramite il portale di Azure
Creare un il punto di ripristino definito dall'utente usando il portale di Azure
Accedere al portale di Azure.
Passare al pool SQL dedicato (in precedenza SQL Data Warehouse) per cui si vuole creare un punto di ripristino.
Nella parte superiore della sezione della panoramica, selezionare + Nuovo punto di ripristino.
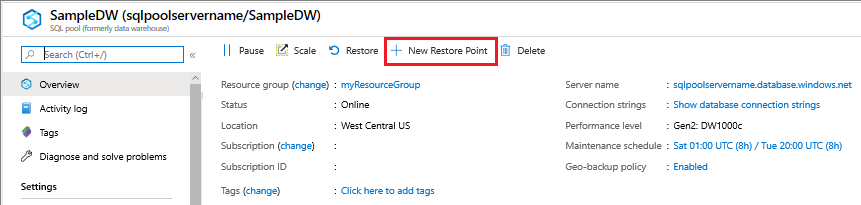
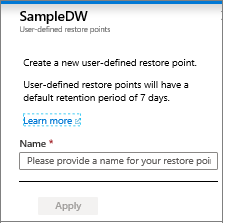
Specificare un nome per il punto di ripristino.
Ripristinare un database attivo o sospeso con il portale di Azure
Accedere al portale di Azure.
Passare al pool SQL dedicato (in precedenza SQL Data Warehouse) dal quale si vuole eseguire il ripristino.
Nella parte superiore della sezione della panoramica, selezionare + Ripristino.
Selezionare Punto di ripristino automatico o Punti di ripristino definiti dall'utente. Per i punti di ripristino definiti dall'utente, selezionare un punto di ripristino definito dall'utente o Creare un nuovo punto di ripristino definito dall'utente. Per il server, selezionare Crea nuovo e scegliere un server in un'area geografica supportata da Gen2.
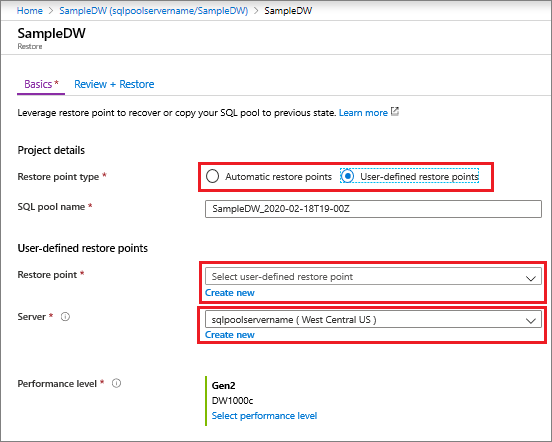
Eseguire il ripristino da un'area geografica di Azure con PowerShell
Nota
È consigliabile usare il modulo Azure Az PowerShell per interagire con Azure. Per iniziare, vedere Installare Azure PowerShell. Per informazioni su come eseguire la migrazione al modulo AZ PowerShell, vedere Eseguire la migrazione di Azure PowerShell da AzureRM ad Az.
Per ripristinare un database, usare il cmdlet Restore-AzSqlDatabase.
Nota
È possibile eseguire un ripristino geografico alla seconda generazione. A tale scopo, specificare ServiceObjectiveName di seconda generazione (ad es. DW1000c) come parametro facoltativo.
- Apri Windows PowerShell.
- Connettersi al proprio account Azure ed elencare tutte le sottoscrizioni associate all'account.
- Selezionare la sottoscrizione che contiene il database da ripristinare.
- Selezionare il database che si desidera ripristinare.
- Creare la richiesta di ripristino per il database, specificando un parametro ServiceObjectiveName Gen2.
- Verificare lo stato del database recuperato con il ripristino geografico.
Connect-AzAccount
Get-AzSubscription
Select-AzSubscription -SubscriptionName "<Subscription_name>"
# Get the database you want to recover
$GeoBackup = Get-AzSqlDatabaseGeoBackup -ResourceGroupName "<YourResourceGroupName>" -ServerName "<YourServerName>" -DatabaseName "<YourDatabaseName>"
# Recover database
$GeoRestoredDatabase = Restore-AzSqlDatabase –FromGeoBackup -ResourceGroupName "<YourResourceGroupName>" -ServerName "<YourTargetServer>" -TargetDatabaseName "<NewDatabaseName>" –ResourceId $GeoBackup.ResourceID -ServiceObjectiveName "<YourTargetServiceLevel>" -RequestedServiceObjectiveName "DW300c"
# Verify that the geo-restored database is online
$GeoRestoredDatabase.status
Nota
Per configurare il database al termine del ripristino, vedere Configurare il database dopo il ripristino.
Il database ripristinato sarà abilitato TDE se il database di origine è abilitato per questa tecnologia.
Se si riscontrano problemi con il pool SQL dedicato, creare una richiesta di supporto indicando "Aggiornamento a Gen2" come possibile causa.
Passaggi successivi
Il pool SQL dedicato (in precedenza SQL Data Warehouse) aggiornato è online. Per sfruttare i vantaggi dell'architettura avanzata, vedere Classi di risorse per la gestione del carico di lavoro.