Trasformare i dati eseguendo un notebook Synapse
SI APPLICA A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita.
L'attività del notebook di Azure Synapse in una pipeline di Synapse esegue un notebook di Synapse nell'area di lavoro di Azure Synapse. Questo articolo si basa sull'articolo relativo alle attività di trasformazione dei dati che presenta una panoramica generale della trasformazione dei dati e le attività di trasformazione supportate.
Creare un'attività del notebook di Synapse
È possibile creare un'attività del notebook di Synapse direttamente dal canvas della pipeline di Synapse o dall'editor di notebook. L'attività del notebook di Synapse viene eseguita nel pool di Spark scelto nel notebook di Synapse.
Aggiungere un'attività del notebook di Synapse dal canvas della pipeline
Trascinare e rilasciare il notebook di Synapse in Attività nel canvas della pipeline di Synapse. Selezionare la casella dell'attività del notebook di Synapse e configurare il contenuto del notebook per l'attività corrente nelle impostazioni. È possibile selezionare un notebook esistente dall'area di lavoro corrente o aggiungerne uno nuovo.
Se si seleziona un notebook esistente dall'area di lavoro corrente, è possibile fare clic sul pulsante Apri per aprire direttamente la pagina del notebook.
(Facoltativo) Nelle impostazioni è possibile riconfigurare anche Pool di Spark\Dimensioni di executor\Allocare dinamicamente gli executor\Numero minimo di executor\Numero massimo di executor\Dimensioni driver. Si noti che le impostazioni riconfigurate qui sostituiranno le impostazioni della sessione di configurazione in Notebook. Se non viene impostato nulla nelle impostazioni dell'attività del notebook corrente, questa verrà eseguita con le impostazioni della sessione di configurazione di tale notebook.
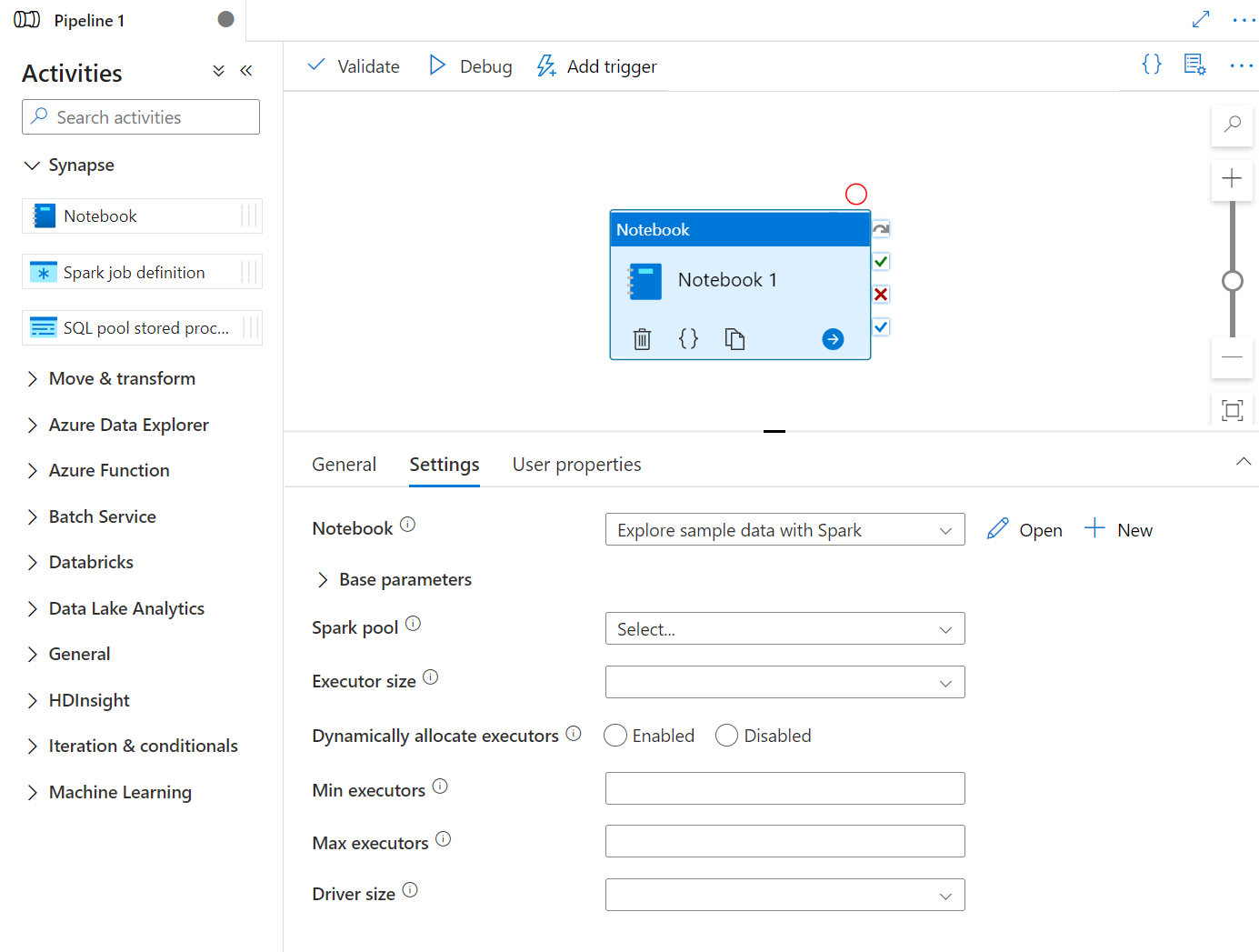
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| Pool Spark | Riferimento al pool di Spark. È possibile selezionare il pool di Apache Spark dall'elenco. Se questa impostazione è vuota, verrà eseguita nel pool di Spark del notebook stesso. | No |
| Dimensioni executor | Numero di core e memoria da usare per gli executor allocati nel pool di Apache Spark specificato per la sessione. | No |
| Allocare dinamicamente gli executor | Questa impostazione esegue il mapping alla proprietà di allocazione dinamica nella configurazione Spark per l'allocazione degli executor dell'applicazione Spark. | No |
| Numero minimo di executor | Numero minimo di executor da allocare nel pool di Spark specificato per il processo. | No |
| Numero massimo di executor | Numero massimo di executor da allocare nel pool di Spark specificato per il processo. | No |
| Dimensioni driver | Numero di core e memoria da usare per il driver indicato nel pool di Apache Spark specificato per il processo. | No |
Nota
L'esecuzione di notebook Spark paralleli nelle pipeline di Azure Synapse viene accodata ed eseguita in modalità FIFO, l'ordine dei processi nella coda è in base alla sequenza temporale, la scadenza di un processo nella coda è di 3 giorni. Si noti che la coda per i notebook funziona solo nella pipeline di Synapse.
Aggiungere un notebook alla pipeline di Synapse
Selezionare il pulsante Aggiungi alla pipeline nell'angolo in alto a destra per aggiungere un notebook a una pipeline esistente o creare una nuova pipeline.

Passaggio dei parametri
Designare una cella di parametri
Per parametrizzare il notebook, selezionare i puntini di sospensione (...) per accedere ad altri comandi nella barra degli strumenti della cella. Selezionare quindi Attiva/Disattiva la cella di parametri per designare la cella come cella di parametri.

Azure Data Factory cerca la cella di parametri e usa i valori come valori predefiniti per i parametri passati in fase di esecuzione. Il motore di esecuzione aggiungerà una nuova cella sotto la cella di parametri con i parametri di input per sovrascrivere i valori predefiniti.
Assegnare i valori dei parametri da una pipeline
Dopo aver creato un notebook con parametri, è possibile eseguirlo da una pipeline con l'attività del notebook di Synapse. Dopo aver aggiunto l'attività al canvas della pipeline, sarà possibile impostare i valori dei parametri nella sezione Parametri di base della scheda Impostazioni.

Quando si assegnano i valori dei parametri, è possibile usare il linguaggio delle espressioni della pipeline o le variabili di sistema.
Leggere il valore di output della cella del notebook di Synapse
È possibile leggere il valore di output della cella del notebook nelle attività successive seguendo questa procedura:
Chiamare l'API mssparkutils.notebook.exit nell'attività del notebook di Synapse per restituire il valore da visualizzare nell'output dell'attività, ad esempio:
mssparkutils.notebook.exit("hello world")Salvando il contenuto del notebook e riattivando la pipeline, l'output dell'attività del notebook conterrà il valore exitValue che potrà essere utilizzato per le attività seguenti nel passaggio 2.
Leggere la proprietà exitValue dall'output dell'attività del notebook. Di seguito è riportata un'espressione di esempio usata per verificare se il valore exitValue recuperato dall'output dell'attività del notebook è uguale a "hello world":


Eseguire un altro notebook di Synapse
È possibile fare riferimento ad altri notebook in un'attività del notebook di Synapse chiamando %run magic o le utilità per notebook mssparkutils. Entrambi supportano l'annidamento delle chiamate di funzione. Le differenze principali di questi due metodi da considerare in base allo scenario sono:
- %run magic copia tutte le celle dal notebook di riferimento alla cella %run e condivide il contesto della variabile. Quando notebook1 fa riferimento a notebook2 tramite
%run notebook2e notebook2 chiama una funzione mssparkutils.notebook.exit, l'esecuzione della cella in notebook1 verrà arrestata. È consigliabile usare %run magic quando si vuole "includere" un file di notebook. - Le utilità per notebook mssparkutils chiamano il notebook di riferimento come metodo o funzione. Il contesto della variabile non è condiviso. Quando notebook1 fa riferimento a notebook2 tramite
mssparkutils.notebook.run("notebook2")e notebook2 chiama una funzione mssparkutils.notebook.exit, l'esecuzione della cella in notebook1 continuerà. È consigliabile usare le utilità per notebook mssparkutils quando si vuole "importare" un notebook.
Visualizzare la cronologia di esecuzione dell'attività del notebook
Passare a Esecuzioni della pipeline nella scheda Monitoraggio per visualizzare la pipeline attivata. Aprire la pipeline contenente l'attività del notebook per visualizzare la cronologia di esecuzione.
È possibile visualizzare lo snapshot di esecuzione del notebook più recente, inclusi l'input e l'output delle celle selezionando il pulsante Apri notebook.

Aprire lo snapshot del notebook:

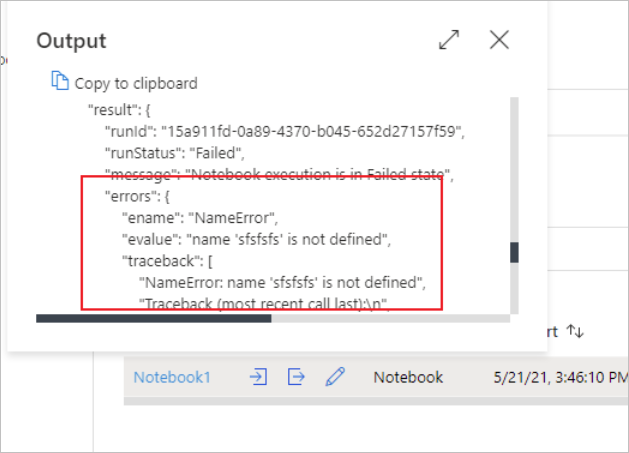
È possibile visualizzare l'input o l'output dell'attività del notebook selezionando il pulsante Input o Output. Se la pipeline non è riuscita a causa di un errore utente, selezionare l'output per controllare il campo del risultato e visualizzare il traceback dettagliato dell'errore utente.
Definizione dell'attività del notebook di Synapse
Ecco la definizione JSON di esempio di un'attività del notebook di Synapse:
{
"name": "parameter_test",
"type": "SynapseNotebook",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"notebook": {
"referenceName": "parameter_test",
"type": "NotebookReference"
},
"parameters": {
"input": {
"value": {
"value": "@pipeline().parameters.input",
"type": "Expression"
}
}
}
}
}
Output dell'attività del notebook di Synapse
Ecco il codice JSON di esempio di un output dell'attività del notebook di Synapse:
{
{
"status": {
"Status": 1,
"Output": {
"status": <livySessionInfo>
},
"result": {
"runId": "<GUID>",
"runStatus": "Succeed",
"message": "Notebook execution is in Succeeded state",
"lastCheckedOn": "2021-03-23T00:40:10.6033333Z",
"errors": {
"ename": "",
"evalue": ""
},
"sessionId": 4,
"sparkpool": "sparkpool",
"snapshotUrl": "https://myworkspace.dev.azuresynapse.net/notebooksnapshot/{guid}",
"exitCode": "abc" // return value from user notebook via mssparkutils.notebook.exit("abc")
}
},
"Error": null,
"ExecutionDetails": {}
},
"effectiveIntegrationRuntime": "DefaultIntegrationRuntime (West US 2)",
"executionDuration": 234,
"durationInQueue": {
"integrationRuntimeQueue": 0
},
"billingReference": {
"activityType": "ExternalActivity",
"billableDuration": [
{
"meterType": "AzureIR",
"duration": 0.06666666666666667,
"unit": "Hours"
}
]
}
}
Problemi noti
Se il nome del notebook è parametrizzato nell'attività del notebook della pipeline, non è possibile fare riferimento alla versione del notebook con stato non pubblicato nelle esecuzioni di debug.