Migrazione di Time Series Insights (TSI) Gen2 ad Azure Esplora dati
Nota
Il servizio Time Series Insights (TSI) non sarà più supportato dopo marzo 2025. Valutare la possibilità di eseguire la migrazione di ambienti Time Series Insights esistenti a soluzioni alternative il prima possibile. Per altre informazioni sulla deprecazione e la migrazione, visitare la documentazione.
Panoramica
Raccomandazioni generali sulla migrazione.
| Funzionalità | Stato Gen2 | Migrazione consigliata |
|---|---|---|
| Inserimento di JSON dall'hub con appiattimento ed escape | Inserimento TIME | ADX - Inserimento/Procedura guidata di OneClick |
| Aprire l'archivio ad accesso sporadico | Account Archiviazione cliente | Esportazione continua dei dati nella tabella esterna specificata dal cliente in ADLS. |
| PbI Connessione or | Anteprima privata | Usare ad ADX PBI Connessione or. Riscrivere TSQ in KQL manualmente. |
| Connettore Spark | Anteprima privata. Eseguire query sui dati di telemetria. Eseguire query sui dati del modello. | Eseguire la migrazione dei dati ad ADX. Usare il connettore ADX Spark per i dati di telemetria e il modello di esportazione in JSON e caricare in Spark. Riscrivere le query in KQL. |
| Caricamento in blocco | Anteprima privata | Usare ADX OneClick Ingest e LightIngest. Facoltativamente, configurare il partizionamento all'interno di ADX. |
| Modello Time Series | Può essere esportato come file JSON. Può essere importato in ADX per eseguire join in KQL. | |
| TSI Explorer | Attivazione/disattivazione di caldo e freddo | Dashboard ADX |
| Linguaggio di query | Query time series (TSQ) | Riscrivere le query in KQL. Usare gli SDK Kusto invece di QUELLI TSI. |
Migrazione dei dati di telemetria
Usare PT=Time la cartella nell'account di archiviazione per recuperare la copia di tutti i dati di telemetria nell'ambiente. Per altre informazioni, vedere Data Archiviazione.
Passaggio 1 della migrazione: ottenere statistiche sui dati di telemetria
Dati
- Panoramica di Env
- Record Environment ID from first part of Data Access FQDN (ad esempio, d390b0b0-1445-4c0c-8365-68d6382c1c2a From .env.crystal-dev.windows-int.net)
- Panoramica di Env -> Configurazione Archiviazione -> Account Archiviazione
- Usare Archiviazione Explorer per ottenere le statistiche delle cartelle
- Dimensioni del record e numero di BLOB della
PT=Timecartella. Per i clienti in anteprima privata dell'importazione bulk, anchePT=Importle dimensioni e il numero di BLOB.
- Dimensioni del record e numero di BLOB della
Passaggio 2 della migrazione: eseguire la migrazione dei dati di telemetria ad ADX
Creare un cluster ADX
Definire le dimensioni del cluster in base alle dimensioni dei dati usando ADX Cost Estimator.
- Dalle metriche di Hub eventi (o hub IoT), recuperare la frequenza di quanti dati vengono inseriti al giorno. Dall'account Archiviazione connesso all'ambiente TSI recuperare la quantità di dati presenti nel contenitore BLOB usato da TSI. Queste informazioni verranno usate per calcolare le dimensioni ideali di un cluster ADX per l'ambiente in uso.
- Aprire Azure Esplora dati Cost Estimator e compilare i campi esistenti con le informazioni trovate. Impostare "Tipo di carico di lavoro" come "Archiviazione Ottimizzato" e "Dati ad accesso frequente" con la quantità totale di dati sottoposti attivamente a query.
- Dopo aver fornito tutte le informazioni, Azure Esplora dati Cost Estimator suggerisce le dimensioni e il numero di istanze della macchina virtuale per il cluster. Analizzare se le dimensioni dei dati sottoposti a query attiva si adattano alla cache ad accesso frequente. Moltiplicare il numero di istanze suggerite dalle dimensioni della cache delle dimensioni della macchina virtuale, ad esempio:
- Suggerimento stima costi: 9x DS14 + 4 TB (cache)
- Totale cache ad accesso frequente consigliato: 36 TB = [9x (istanze) x 4 TB (di Cache ad accesso frequente per nodo)]
- Altri fattori da considerare:
- Crescita dell'ambiente: quando si pianificano le dimensioni del cluster ADX, considerare la crescita dei dati nel tempo.
- Idratazione e partizionamento: quando si definisce il numero di istanze nel cluster ADX, considerare nodi aggiuntivi (di 2-3 volte) per velocizzare l'idratazione e il partizionamento.
- Per altre informazioni sulla selezione del calcolo, vedere Selezionare lo SKU di calcolo corretto per il cluster di azure Esplora dati.
Per monitorare al meglio il cluster e l'inserimento dati, è necessario abilitare i Impostazioni di diagnostica e inviare i dati a un'area di lavoro Log Analytics.
Nel pannello Azure Esplora dati passare a "Monitoraggio | Impostazioni di diagnostica" e fare clic su "Aggiungi impostazione di diagnostica"
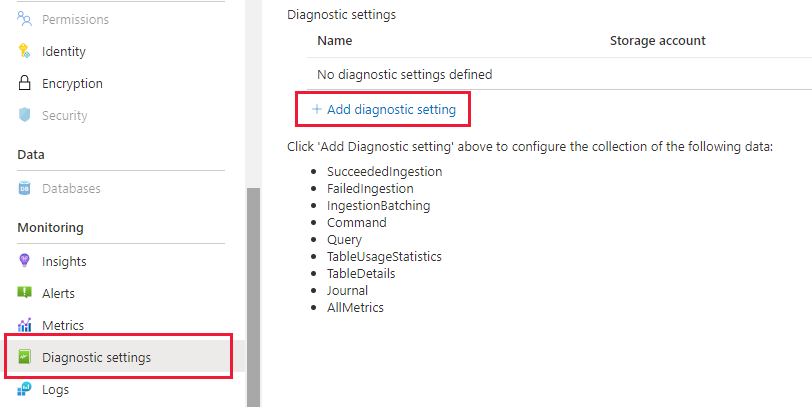
Compilare quanto segue
- Nome dell'impostazione di diagnostica: Nome visualizzato per questa configurazione
- Log: selezionare almeno SucceededIngestion, FailedIngestion, IngestionBatching
- Selezionare l'area di lavoro Log Analytics per inviare i dati a (se non è necessario effettuarne il provisioning prima di questo passaggio)
Partizionamento dei dati.
- Per la maggior parte dei set di dati, il partizionamento ADX predefinito è sufficiente.
- Il partizionamento dei dati è utile in un set molto specifico di scenari e non deve essere applicato in caso contrario:
- Miglioramento della latenza delle query nei set di Big Data in cui la maggior parte delle query filtra su una colonna di stringa di cardinalità elevata, ad esempio un ID serie temporale.
- Quando si inseriscono dati non ordinati, ad esempio quando gli eventi del passato possono essere inseriti giorni o settimane dopo la generazione nell'origine.
- Per altre informazioni, vedere Criteri di partizionamento dei dati ADX.


Preparare l'inserimento dati
Vai a https://dataexplorer.azure.com.
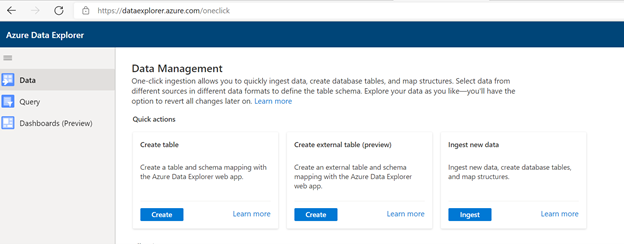
Passare alla scheda Dati e selezionare "Inserimento dal contenitore BLOB"

Selezionare Cluster, Database e creare una nuova tabella con il nome scelto per i dati TSI

Selezionare Avanti: Origine
Nella scheda Origine selezionare:
- Dati storici
- "Select Container" (Seleziona contenitore)
- Scegliere la sottoscrizione e l'account Archiviazione per i dati tsi
- Scegliere il contenitore correlato all'ambiente TSI
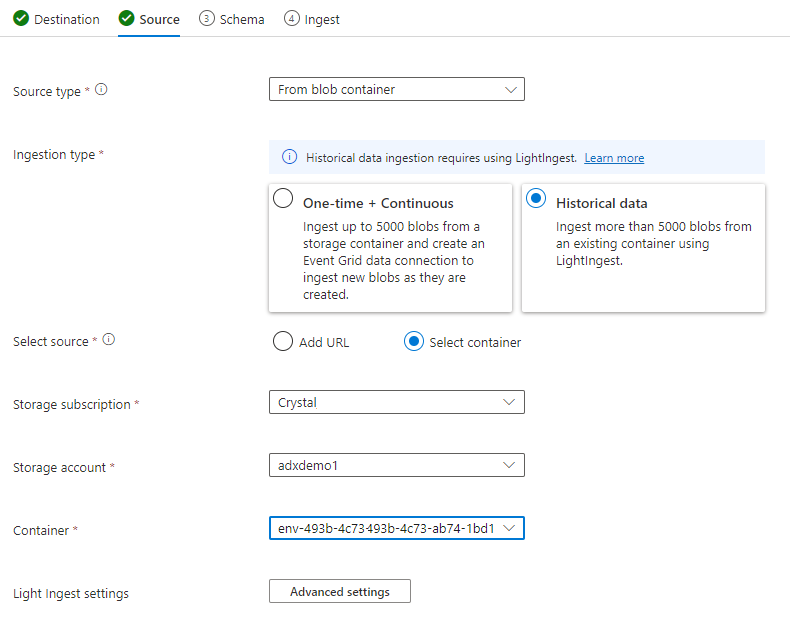
Selezionare Impostazioni avanzate
- Modello di tempo di creazione: '/'yyyyMmddHHmmssfff'_'
- Modello di nome BLOB: *.parquet
- Selezionare "Non attendere il completamento dell'inserimento"

In Filtri file aggiungere il percorso della cartella
V=1/PT=Time
Selezionare Avanti: Schema
Nota
Time Series Insights applica alcuni elementi flat ed escaping durante la persistenza delle colonne nei file Parquet. Per altri dettagli, vedere questi collegamenti: appiattimento e escape delle regole, aggiornamenti delle regole di inserimento.






Se lo schema è sconosciuto o variabile
Rimuovere tutte le colonne su cui viene eseguita raramente una query, lasciando almeno timestamp e colonne TSID.

Aggiungere una nuova colonna di tipo dinamico ed eseguirne il mapping all'intero record usando $ path.
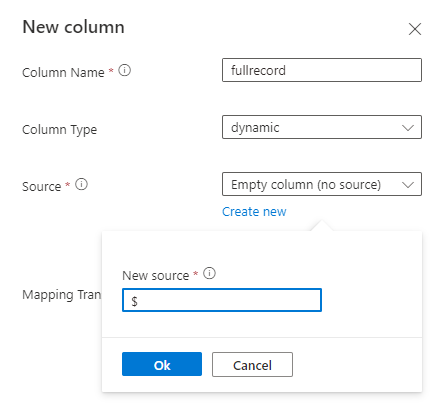
Esempio:

Se lo schema è noto o fisso
- Verificare che i dati siano corretti. Correggere eventuali tipi, se necessario.
- Selezionare Avanti: Riepilogo



Copiare il comando LightIngest e archiviarlo in un punto qualsiasi in modo da poterlo usare nel passaggio successivo.

Inserimento di dati
Prima di inserire i dati è necessario installare lo strumento LightIngest. Il comando generato dallo strumento con un clic include un token di firma di accesso condiviso. È consigliabile generarne uno nuovo in modo da avere il controllo sulla scadenza. Nel portale passare al contenitore BLOB per l'ambiente TSI e selezionare "Token di accesso condiviso"

Nota
È anche consigliabile aumentare le prestazioni del cluster prima di avviare un inserimento di grandi dimensioni. Ad esempio, D14 o D32 con 8+ istanze.
Impostare quanto segue
- Autorizzazioni: lettura ed elenco
- Scadenza: impostare su un periodo in cui si è a proprio agio che la migrazione dei dati sarà completata
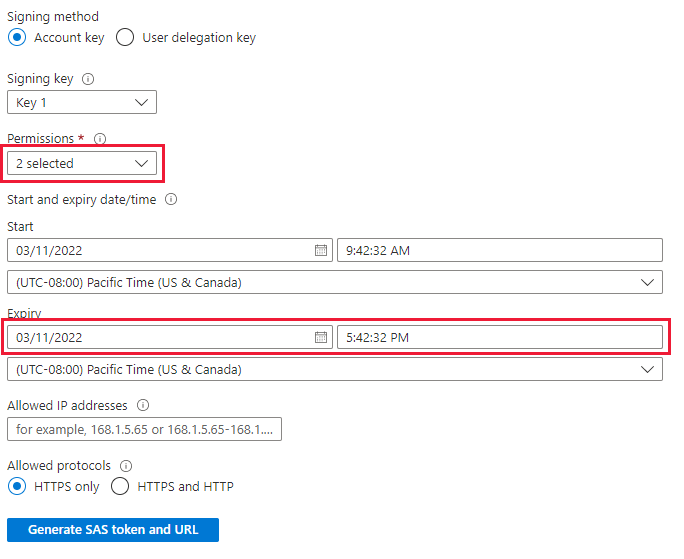
Selezionare "Genera token di firma di accesso condiviso e URL" e copiare l'URL di firma di accesso condiviso blob

Passare al comando LightIngest copiato in precedenza. Sostituire il parametro -source nel comando con questo "URL BLOB di firma di accesso condiviso"
Opzione 1: inserire tutti i dati. Per gli ambienti più piccoli, è possibile inserire tutti i dati con un singolo comando.
- Aprire un prompt dei comandi e passare alla directory in cui è stato estratto lo strumento LightIngest. Al termine, incollare il comando LightIngest ed eseguirlo.

Opzione 2: inserire i dati per anno o mese. Per ambienti più grandi o per testare un set di dati più piccolo, è possibile filtrare ulteriormente il comando Lightingest.
Per anno: modificare il parametro -prefix
- Prima:
-prefix:"V=1/PT=Time" - Dopo:
-prefix:"V=1/PT=Time/Y=<Year>" - Esempio:
-prefix:"V=1/PT=Time/Y=2021"
- Prima:
Per mese: modificare il parametro -prefix
- Prima:
-prefix:"V=1/PT=Time" - Dopo:
-prefix:"V=1/PT=Time/Y=<Year>/M=<month #>" - Esempio:
-prefix:"V=1/PT=Time/Y=2021/M=03"
- Prima:



Dopo aver modificato il comando, eseguirlo come sopra. Uno degli inserimenti è completo (usando l'opzione di monitoraggio seguente) modificare il comando per l'anno e il mese successivo che si vuole inserire.
Monitoraggio dell'inserimento
Il comando LightIngest include il flag -dontWait in modo che il comando stesso non attenda il completamento dell'inserimento. Il modo migliore per monitorare lo stato di avanzamento durante l'esecuzione consiste nell'usare la scheda "Insights" all'interno del portale. Aprire la sezione del cluster Esplora dati di Azure all'interno del portale e passare a "Monitoraggio | Insights'

È possibile usare la sezione "Inserimento (anteprima)" con le impostazioni seguenti per monitorare l'inserimento durante l'esecuzione
- Intervallo di tempo: ultimi 30 minuti
- Esaminare Successful e by Table
- In caso di errori, vedere Failed and by Table (Errore e tabella)
Si saprà che l'inserimento è completo dopo aver visualizzato le metriche passare a 0 per la tabella. Per visualizzare altri dettagli, è possibile usare Log Analytics. Nella sezione Cluster Esplora dati di Azure selezionare la scheda "Log":

Query utili
Informazioni sullo schema se viene usato lo schema dinamico
| project p=treepath(fullrecord)
| mv-expand p
| summarize by tostring(p)
Accesso ai valori nella matrice
| where id_string == "a"
| summarize avg(todouble(fullrecord.['nestedArray_v_double'])) by bin(timestamp, 1s)
| render timechart
Migrazione del modello Time Series (TSM) ad Azure Esplora dati
Il modello può essere scaricato in formato JSON dall'ambiente TSI usando l'esperienza utente di Tsi Explorer o l'API Batch TSM. È quindi possibile importare il modello in un altro sistema come Azure Esplora dati.
Scaricare TSM dall'esperienza utente tsi.
Eliminare le prime tre righe usando VSCode o un altro editor.
Uso di VSCode o di un altro editor, cercare e sostituire come espressione regolare
\},\n \{con}{
Inserire come JSON in ADX come tabella separata usando la funzionalità Carica da file.




Convertire query time series (TSQ) in KQL
GetEvents
{
"getEvents": {
"timeSeriesId": [
"assest1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"inlineVariables": {},
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where assetId_string == "assest1" and siteId_string == "siteId1" and dataid_string == "dataId1"
| take 10000
GetEvents con filtro
{
"getEvents": {
"timeSeriesId": [
"deviceId1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"filter": {
"tsx": "$event.sensors.sensor.String = 'status' AND $event.sensors.unit.String = 'ONLINE"
}
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where deviceId_string== "deviceId1" and siteId_string == "siteId1" and dataId_string == "dataId1"
| where ['sensors.sensor_string'] == "status" and ['sensors.unit_string'] == "ONLINE"
| take 10000
GetEvents con variabile proiettata
{
"getEvents": {
"timeSeriesId": [
"deviceId1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"inlineVariables": {},
"projectedVariables": [],
"projectedProperties": [
{
"name": "sensors.value",
"type": "String"
},
{
"name": "sensors.value",
"type": "bool"
},
{
"name": "sensors.value",
"type": "Double"
}
]
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where deviceId_string== "deviceId1" and siteId_string == "siteId1" and dataId_string == "dataId1"
| take 10000
| project timestamp, sensorStringValue= ['sensors.value_string'], sensorBoolValue= ['sensors.value_bool'], sensorDoublelValue= ['sensors.value_double']
AggregateSeries
{
"aggregateSeries": {
"timeSeriesId": [
"deviceId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:00.0000000Z",
"to": "2021-11-05T00:00:00.0000000Z"
},
"interval": "PT1M",
"inlineVariables": {
"sensor": {
"kind": "numeric",
"value": {
"tsx": "coalesce($event.sensors.value.Double, todouble($event.sensors.value.Long))"
},
"aggregation": {
"tsx": "avg($value)"
}
}
},
"projectedVariables": [
"sensor"
]
}
events
| where timestamp >= datetime(2021-11-01T00:00:00.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.0000000Z)
| where deviceId_string == "deviceId1"
| summarize avgSensorValue= avg(coalesce(['sensors.value_double'], todouble(['sensors.value_long']))) by bin(IntervalTs = timestamp, 1m)
| project IntervalTs, avgSensorValue
AggregateSeries con filtro
{
"aggregateSeries": {
"timeSeriesId": [
"deviceId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:00.0000000Z",
"to": "2021-11-05T00:00:00.0000000Z"
},
"filter": {
"tsx": "$event.sensors.sensor.String = 'heater' AND $event.sensors.location.String = 'floor1room12'"
},
"interval": "PT1M",
"inlineVariables": {
"sensor": {
"kind": "numeric",
"value": {
"tsx": "coalesce($event.sensors.value.Double, todouble($event.sensors.value.Long))"
},
"aggregation": {
"tsx": "avg($value)"
}
}
},
"projectedVariables": [
"sensor"
]
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:00.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.0000000Z)
| where deviceId_string == "deviceId1"
| where ['sensors.sensor_string'] == "heater" and ['sensors.location_string'] == "floor1room12"
| summarize avgSensorValue= avg(coalesce(['sensors.value_double'], todouble(['sensors.value_long']))) by bin(IntervalTs = timestamp, 1m)
| project IntervalTs, avgSensorValue
Migrazione da Tsi Power BI Connessione or ad ADX Power BI Connessione or
I passaggi manuali coinvolti in questa migrazione sono
- Convertire una query di Power BI in TSQ
- Convertire TSQ in query KQL di Power BI in TSQ: la query di Power BI copiata da Tsi UX Explorer è simile alla seguente:
Per dati non elaborati (API GetEvents)
{"storeType":"ColdStore","isSearchSpanRelative":false,"clientDataType":"RDX_20200713_Q","environmentFqdn":"6988946f-2b5c-4f84-9921-530501fbab45.env.timeseries.azure.com", "queries":[{"getEvents":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"take":250000}}]}
- Per convertirlo in TSQ, compilare un file JSON dal payload precedente. La documentazione dell'API GetEvents include anche esempi per comprenderlo meglio. Query - Esecuzione - API REST (Azure Time Series Insights) | Microsoft Docs
- Il TSQ convertito è simile a quello illustrato di seguito. Si tratta del payload JSON all'interno di "query"
{
"getEvents": {
"timeSeriesId": [
"Arctic Ocean",
"null"
],
"searchSpan": {
"from": "2019-10-31T23:59:39.590Z",
"to": "2019-11-01T05:22:18.926Z"
},
"take": 250000
}
}
Per Aggradate Data(API Aggregate Series)
- Per una singola variabile inline, la query di PowerBI di Tsi UX Explorer è simile alla figura seguente:
{"storeType":"ColdStore","isSearchSpanRelative":false,"clientDataType":"RDX_20200713_Q","environmentFqdn":"6988946f-2b5c-4f84-9921-530501fbab45.env.timeseries.azure.com", "queries":[{"aggregateSeries":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"interval":"PT1M", "inlineVariables":{"EventCount":{"kind":"aggregate","aggregation":{"tsx":"count()"}}},"projectedVariables":["EventCount"]}}]}
- Per convertirlo in TSQ, compilare un file JSON dal payload precedente. La documentazione dell'API AggregateSeries include anche esempi per comprenderlo meglio. Query - Esecuzione - API REST (Azure Time Series Insights) | Microsoft Docs
- Il TSQ convertito è simile a quello illustrato di seguito. Si tratta del payload JSON all'interno di "query"
{
"aggregateSeries": {
"timeSeriesId": [
"Arctic Ocean",
"null"
],
"searchSpan": {
"from": "2019-10-31T23:59:39.590Z",
"to": "2019-11-01T05:22:18.926Z"
},
"interval": "PT1M",
"inlineVariables": {
"EventCount": {
"kind": "aggregate",
"aggregation": {
"tsx": "count()"
}
}
},
"projectedVariables": [
"EventCount",
]
}
}
- Per più variabili inline, aggiungere il codice JSON in "inlineVariables" come illustrato nell'esempio seguente. La query di Power BI per più variabili inline è simile alla seguente:
{"storeType":"ColdStore","isSearchSpanRelative":false,"clientDataType":"RDX_20200713_Q","environmentFqdn":"6988946f-2b5c-4f84-9921-530501fbab45.env.timeseries.azure.com","queries":[{"aggregateSeries":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"interval":"PT1M", "inlineVariables":{"EventCount":{"kind":"aggregate","aggregation":{"tsx":"count()"}}},"projectedVariables":["EventCount"]}}, {"aggregateSeries":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"interval":"PT1M", "inlineVariables":{"Magnitude":{"kind":"numeric","value":{"tsx":"$event['mag'].Double"},"aggregation":{"tsx":"max($value)"}}},"projectedVariables":["Magnitude"]}}]}
{
"aggregateSeries": {
"timeSeriesId": [
"Arctic Ocean",
"null"
],
"searchSpan": {
"from": "2019-10-31T23:59:39.590Z",
"to": "2019-11-01T05:22:18.926Z"
},
"interval": "PT1M",
"inlineVariables": {
"EventCount": {
"kind": "aggregate",
"aggregation": {
"tsx": "count()"
}
},
"Magnitude": {
"kind": "numeric",
"value": {
"tsx": "$event['mag'].Double"
},
"aggregation": {
"tsx": "max($value)"
}
}
},
"projectedVariables": [
"EventCount",
"Magnitude",
]
}
}
- Per eseguire una query sui dati più recenti("isSearchSpanRelative": true), calcolare manualmente searchSpan come indicato di seguito
- Trovare la differenza tra "from" e "to" dal payload di Power BI. Chiamiamo questa differenza come "D" dove "D" = "from" - "to"
- Prendere il timestamp corrente("T") e sottrarre la differenza ottenuta nel primo passaggio. Sarà nuovo "from"(F) di searchSpan dove "F" = "T" - "D"
- A questo punto, il nuovo "from" è "F" ottenuto nel passaggio 2 e il nuovo "to" è "T"(timestamp corrente)