Risoluzione dei problemi di scalabilità automatica con set di scalabilità di macchine virtuali di Microsoft Azure
Problema: è stata creata un'infrastruttura di scalabilità automatica in Azure Resource Manager usando set di scalabilità di macchine virtuali, ad esempio distribuendo un modello come questo: https://github.com/Azure/azure-quickstart-templates/blob/master/application-workloads/python/vmss-bottle-autoscale/azuredeploy.parameters.json sono state definite le regole di scalabilità e funziona bene, ad eccezione della quantità di carico inserita nelle macchine virtuali, non viene eseguita la scalabilità automatica.
Passaggi per la risoluzione dei problemi
Alcuni aspetti da considerare:
Quanti vCPU sono presenti in ogni macchina virtuale e viene caricato ogni singolo vCPU? Il modello di avvio rapido di Azure di esempio riportato sopra ha uno script do_work.php, che carica un singolo vCPU. Se si usa una macchina virtuale di dimensioni superiori a una macchina virtuale a vCPU singola, ad esempio Standard_A1 o D1, è necessario eseguire questo carico più volte. Per verificare il numero di vCPU delle macchine virtuali, vedere Dimensioni delle macchine virtuali in Azure
Quante macchine virtuali nel set di scalabilità di macchine virtuali vengono eseguite su ognuna di esse?
Un aumento del numero di istanze ha luogo unicamente quando l'uso medio della CPU tra tutte le macchine virtuali in un set di scalabilità supera il valore di soglia, in base al tempo definito all'interno delle regole di scalabilità automatica.
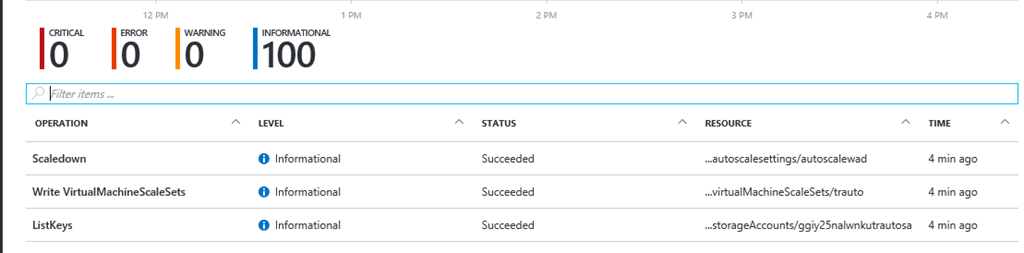
Sono stati persi eventi di scalabilità?
Cercare gli eventi di scalabilità nei log di controllo nel portale di Azure. Potrebbero essersi verificati un aumento e poi una riduzione delle prestazioni non rilevati. È possibile filtrare in base a "Scale".
Le soglie di aumento e riduzione del numero di istanze sono sufficientemente diverse?
Si supponga di impostare una regola per aumentare il numero di istanze quando l'uso medio della CPU è superiore al 50% in cinque minuti e per ridurre il numero di istanze quando l'uso medio della CPU è inferiore al 50%. Questa impostazione causerebbe un problema di "flapping" quando l'utilizzo della CPU è vicino alla soglia, con azioni di scalabilità che aumentano costantemente e riducono le dimensioni del set. A causa di questa impostazione, il servizio di scalabilità automatica tenta di impedire il "flapping", che può manifestarsi come non ridimensionamento. Assicurarsi che le soglie di aumento e riduzione del numero di istanze siano sufficientemente diverse per consentire le azioni di ridimensionamento.
È stato scritto un modello JSON personalizzato?
È facile commettere errori. È quindi consigliabile partire da un modello funzionante come quello riportato sopra e apportare piccole modifiche incrementali.
È possibile eseguire manualmente l'aumento o la riduzione del numero di istanze?
Provare a ridistribuire la risorsa del set di scalabilità di macchine virtuali con un'impostazione di "capacità" diversa per modificare manualmente il numero di macchine virtuali. Un modello di esempio è il seguente: https://github.com/Azure/azure-quickstart-templates/tree/master/quickstarts/microsoft.compute/vmss-scale-existing potrebbe essere necessario modificare il modello per assicurarsi che abbia la stessa dimensione della macchina che usa il set di scalabilità. Se è possibile modificare manualmente il numero di macchine virtuali, il problema è limitato alla scalabilità automatica.
Verificare lo stato delle risorse Microsoft.Compute/virtualMachineScaleSet e Microsoft.Insights in Esplora risorse di Azure
Esplora risorse di Azure è uno strumento di risoluzione dei problemi indispensabile che mostra lo stato delle risorse di Azure Resource Manager. Fare clic sulla sottoscrizione ed esaminare il gruppo di risorse di cui si sta provando a risolvere i problemi. Nel provider di risorse di calcolo esaminare il set di scalabilità di macchine virtuali creato e controllare la visualizzazione istanza, che mostra lo stato di una distribuzione. Controllare anche la visualizzazione dell'istanza delle macchine virtuali nel set di scalabilità di macchine virtuali. Accedere quindi al provider di risorse Microsoft.Insights e verificare lo stato delle regole di scalabilità automatica.
L'estensione della diagnostica funziona e genera dati sulle prestazioni?
Aggiornamento: la funzione di scalabilità automatica di Azure è stata migliorata per l'uso di una pipeline di metriche basate su host che non richiede più l'installazione di un'estensione di diagnostica. I paragrafi seguenti non avranno più validità se si crea un'applicazione di scalabilità automatica usando la nuova pipeline. Un esempio di modelli di Azure che sono stati convertiti per l'utilizzo della pipeline su host è disponibile qui: https://github.com/Azure/azure-quickstart-templates/blob/master/application-workloads/python/vmss-bottle-autoscale/azuredeploy.parameters.json.
È consigliabile usare le metriche basate su host per eseguire la scalabilità automatica per i motivi seguenti:
Meno componenti variabili poiché non è più necessario installare alcuna estensione di diagnostica.
Modelli più semplici. È sufficiente aggiungere regole di scalabilità automatica di Insights a un modello del set di scalabilità esistente.
Creazione di report più affidabile e avvio più veloce delle nuove macchine virtuali.
Si potrebbe voler usare un'estensione di diagnostica soltanto se ci fosse l'esigenza di scalare/creare report di diagnostica della memoria. Le metriche basate su host non creano report della memoria.
Tenendo questo a mente, continuare a leggere l'articolo solo se si intende usare le estensioni di diagnostica per la scalabilità automatica.
La funzione di scalabilità automatica in Azure Resource Manager può (ma non dovrà più) essere eseguita tramite un'estensione della macchina virtuale denominata estensione Diagnostica. L'estensione invia i dati sulle prestazioni a un account di archiviazione specificato nel modello. I dati vengono quindi aggregati dal servizio Monitoraggio di Azure.
Se il servizio Insights non riesce a leggere i dati dalle macchine virtuali, è consigliabile inviare un messaggio di posta elettronica. Ad esempio, si riceve un messaggio di posta elettronica se le macchine virtuali non sono attive. Controllare la posta all'indirizzo di posta elettronica specificato al momento della creazione dell'account di Azure.
È anche possibile esaminare i dati personalmente. Esaminare l'account di archiviazione di Azure con uno strumento di esplorazione cloud. Ad esempio, usando Visual Studio Cloud Explorer, accedere e selezionare la sottoscrizione di Azure in uso. Selezionare il nome dell'account di archiviazione di diagnostica a cui si fa riferimento nella definizione dell'estensione della diagnostica nel modello di distribuzione.

Verrà visualizzata una serie di tabelle in cui vengono archiviati i dati di ogni macchina virtuale. Prendendo ad esempio Linux e la relativa metrica della CPU, esaminare le righe più recenti. Visual Studio Cloud Explorer supporta un linguaggio di query per poter eseguire una query. Ad esempio, è possibile eseguire una query per "Timestamp gt datetime'2016-02-02T21:20:00Z'" per assicurarsi di ottenere gli eventi più recenti. Il fuso orario è impostato su UTC. I dati visualizzati corrispondono alle regole di scalabilità impostate? Nell'esempio seguente, l'uso della CPU nel computer 20 è aumentato fino al 100% negli ultimi cinque minuti.
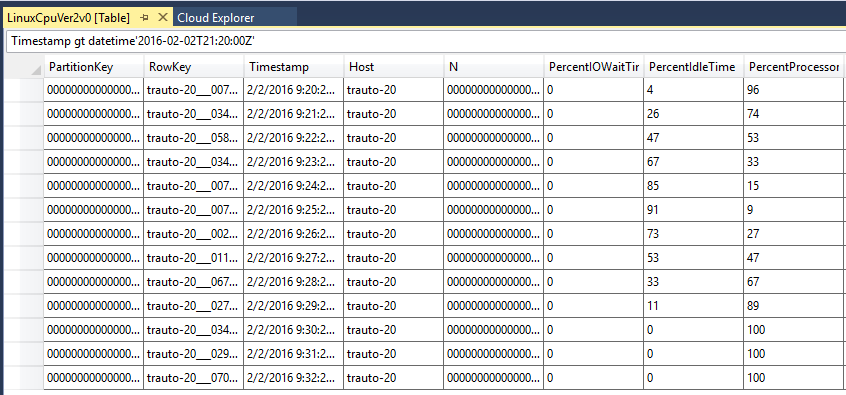
Se i dati non sono presenti, il problema riguarda l'estensione della diagnostica in esecuzione nelle macchine virtuali. Se i dati sono presenti, il problema può riguardare le regole di scalabilità oppure il servizio Insights. Verificare lo Stato di Azure.
Dopo aver eseguito questi passaggi, se si verificano ancora problemi di scalabilità automatica, è possibile provare le risorse seguenti:
- Vedere la pagina Risoluzione dei problemi comuni relativi ai set di scalabilità di macchine virtuali
- Leggere i forum sulla pagina delle domande di Domande e risposte Microsoft o sull'overflow dello stack
- Registrare una chiamata del supporto. Sarà necessario, condividere il modello e la visualizzazione dei dati sulle prestazioni.