Distribuzione DBMS per IBM Db2 di Macchine virtuali di Azure per un carico di lavoro SAP
Con Microsoft Azure è possibile eseguire facilmente la migrazione dell'applicazione SAP esistente in esecuzione in IBM Db2 per Linux, UNIX e Windows (LUW) alle macchine virtuali di Azure. Con SAP in IBM Db2 per LUW, gli amministratori e gli sviluppatori possono continuare a usare gli stessi strumenti di sviluppo e amministrazione disponibili in locale. Le informazioni generali sull'esecuzione di SAP Business Suite in IBM Db2 per LUW sono disponibili tramite SAP Community Network (SCN) in SAP in IBM Db2 per Linux, UNIX e Windows.
Per altre informazioni e aggiornamenti su SAP in Db2 per LUW in Azure vedere la nota SAP 2233094.
Sono disponibili vari articoli per il carico di lavoro SAP in Azure. È consigliabile iniziare con Introduzione a SAP in macchine virtuali di Azure e quindi leggere altre aree di interesse.
Le note SAP seguenti sono correlate a SAP in Azure relativamente all'area coperta in questo documento:
| Numero della nota | Title |
|---|---|
| 1928533 | Applicazioni SAP in Azure: prodotti supportati e tipi di macchine virtuali di Azure |
| 2015553 | SAP in Microsoft Azure: prerequisiti per il supporto |
| 1999351 | Risoluzione dei problemi del monitoraggio avanzato di Azure per SAP |
| 2178632 | Metriche chiave del monitoraggio per SAP in Microsoft Azure |
| 1409604 | Virtualizzazione in Windows: monitoraggio avanzato |
| 2191498 | SAP in Linux con Azure: monitoraggio avanzato |
| 2233094 | DB6: Informazioni aggiuntive sulle applicazioni SAP in Azure che usano IBM DB2 per Linux, UNIX e Windows |
| 2243692 | Linux in una macchina virtuale di Microsoft Azure (IaaS): problemi delle licenze SAP |
| 1984787 | SUSE LINUX Enterprise Server 12: note di installazione |
| 2002167 | Red Hat Enterprise Linux 7. x: installazione e aggiornamento |
| 1597355 | Raccomandazione sullo spazio di scambio per Linux |
Come prelettura di questo documento, vedere Considerazioni per la distribuzione di DBMS di Azure Macchine virtuali per il carico di lavoro SAP. Esaminare altre guide nel carico di lavoro SAP in Azure.
Supporto della versione di IBM Db2 per Linux, UNIX e Windows
SAP in IBM Db2 per LUW nei servizi Macchine virtuali di Microsoft Azure è supportato a partire da Db2 versione 10.5.
Per informazioni sui prodotti SAP supportati e sui tipi di macchine virtuali di Azure (Macchine virtuali), vedere la nota SAP 1928533.
Linee guida per la configurazione di IBM Db2 per Linux, UNIX e Windows per le installazioni di SAP nelle VM di Azure
Configurazione dell'archiviazione
Per una panoramica dei tipi di archiviazione di Azure per il carico di lavoro SAP, vedere l'articolo Archiviazione di Azure tipi per il carico di lavoro SAP Tutti i file di database devono essere archiviati nei dischi montati dell'archiviazione a blocchi di Azure (Windows: NTFS, Linux: xfs, supportato a partire da Db2 11.1 o ext3).
I volumi condivisi remoti come i servizi di Azure negli scenari elencati non sono supportati per i file di database Db2:
Servizio file di Microsoft Azure per tutti i sistemi operativi guest.
Azure NetApp Files per Db2 in esecuzione nel sistema operativo guest Windows.
I volumi condivisi remoti come i servizi di Azure negli scenari elencati sono supportati per i file di database Db2:
- L'hosting di file di dati e di log del sistema operativo guest Linux in condivisioni NFS ospitate in Azure NetApp Files è supportato.
Se si usano dischi basati su AZURE Page BLOB Archiviazione o Managed Disks, le istruzioni effettuate in Considerazioni per la distribuzione dbms di Azure Macchine virtuali dbms per il carico di lavoro SAP si applicano anche alle distribuzioni con DBMS Db2.
Come spiegato in precedenza nella parte generale del documento, esistono quote relative alla velocità effettiva delle operazioni di I/O al secondo per i dischi di Azure. Le quote esatte dipendono dal tipo di VM usato. Un elenco dei tipi di VM con le rispettive quote è disponibile qui (per Linux) e qui (per Windows).
Se la quota corrente di operazioni di I/O al secondo per disco è sufficiente, è possibile archiviare tutti i file di database in un singolo disco montato. Mentre è sempre consigliabile separare i file di dati e i file di log delle transazioni nei diversi dischi/dischi rigidi virtuali.
Per le considerazioni sulle prestazioni, vedere anche il capitolo relativo alle considerazioni sulle prestazioni e la sicurezza dei dati per le directory di database nelle guide di installazione di SAP.
In alternativa, è possibile usare pool di Windows Archiviazione, disponibili solo in Windows Server 2012 e versioni successive, come descritto Considerazioni per la distribuzione dbMS di Azure Macchine virtuali per il carico di lavoro SAP. In Linux è possibile usare LVM o mdadm per creare un dispositivo logico di grandi dimensioni su più dischi.
Per la macchina virtuale serie M di Azure, è possibile ridurre la latenza di scrittura nei log delle transazioni rispetto alle prestazioni di archiviazione Premium di Azure quando si usa l'acceleratore di scrittura di Azure. È pertanto necessario distribuire l'acceleratore di scrittura di Azure per uno o più dischi rigidi virtuali che formano il volume per i log delle transazioni Db2. I dettagli sono disponibili nel documento relativo all'acceleratore di scrittura.
Ibm Db2 LUW 11.5 ha rilasciato il supporto per le dimensioni del settore da 4 KB. Anche se è necessario abilitare l'utilizzo delle dimensioni del settore da 4 KB con 11,5 tramite l'impostazione delle configurazioni di db2set DB2_4K_DEVICE_SUPPORT=ON come documentato in:
Per le versioni precedenti di Db2, è necessario usare una dimensione del settore a 512 byte. I dischi SSD Premium sono nativi di 4 KB e hanno emulazione di 512 byte. Per impostazione predefinita, il disco Ultra usa dimensioni di settore da 4 KB. È possibile abilitare le dimensioni del settore a 512 byte durante la creazione di un disco Ultra. I dettagli sono disponibili usando i dischi Ultra di Azure. Questa dimensione del settore di 512 byte è un prerequisito per le versioni IBM Db2 LUW inferiori a 11,5.
In Windows usando pool di Archiviazione per i percorsi di archiviazione Db2 per log_dirle sapdata directory e saptmp è necessario specificare una dimensione del settore disco fisico di 512 byte. Quando si usano i pool di archiviazione di Windows, è necessario creare manualmente i pool di archiviazione con l'interfaccia della riga di comando usando il parametro -LogicalSectorSizeDefault. Per altre informazioni, vedere New-Archiviazione Pool.
Raccomandazione sulla macchina virtuale e sulla struttura del disco per la distribuzione ibm Db2
IBM Db2 for SAP NetWeaver Applications è supportato in qualsiasi tipo di macchina virtuale elencato nella nota di supporto SAP 1928533. Le famiglie di macchine virtuali consigliate per l'esecuzione del database IBM Db2 sono Esd_v4/Eas_v4/Es_v3 e serie M/M_v2 per database multi-terabyte di grandi dimensioni. Le prestazioni di scrittura del disco del log delle transazioni IBM Db2 possono essere migliorate abilitando l'acceleratore di scrittura serie M.
Di seguito è riportata una configurazione di base per varie dimensioni e usi di SAP nelle distribuzioni Db2 da piccole a grandi dimensioni. L'elenco è basato sull'archiviazione Premium di Azure. Tuttavia, anche il disco Ultra di Azure è completamente supportato con Db2 e può essere usato anche. Usare i valori per capacità, velocità effettiva burst e operazioni di I/O al secondo burst per definire la configurazione del disco Ultra. È possibile limitare le operazioni di I/O al secondo per /db2/<SID>/log_dir a circa 5000 operazioni di I/O al secondo.
Sistema SAP di piccole dimensioni aggiuntive: dimensioni del database da 50 a 200 GB: esempio di Solution Manager
| Nome macchina virtuale/Dimensioni | Punto di montaggio Db2 | Disco Premium di Azure | Numero di dischi | IOPS | Attraverso- put [MB/s] |
Dimensioni [GB] | Operazioni di I/O al secondo in modalità burst | Burst Through- put [GB] |
Dimensioni di striping | Memorizzazione nella cache |
|---|---|---|---|---|---|---|---|---|---|---|
| E4ds_v4 | /db2 | P6 | 1 | 240 | 50 | 64 | 3.500 | 170 | ||
| vCPU: 4 | /db2/<SID>/sapdata |
P10 | 2 | 1,000 | 200 | 256 | 7.000 | 340 | 256 KB |
ReadOnly |
| RAM: 32 GiB | /db2/<SID>/saptmp |
P6 | 1 | 240 | 50 | 128 | 3.500 | 170 | ||
/db2/<SID>/log_dir |
P6 | 2 | 480 | 100 | 128 | 7.000 | 340 | 64 KB |
||
/db2/<SID>/offline_log_dir |
P10 | 1 | 500 | 100 | 128 | 3.500 | 170 |
Sistema SAP di piccole dimensioni: dimensioni del database da 200 a 750 GB: small Business Suite
| Nome macchina virtuale/Dimensioni | Punto di montaggio Db2 | Disco Premium di Azure | Numero di dischi | IOPS | Attraverso- put [MB/s] |
Dimensioni [GB] | Operazioni di I/O al secondo in modalità burst | Burst Through- put [GB] |
Dimensioni di striping | Memorizzazione nella cache |
|---|---|---|---|---|---|---|---|---|---|---|
| E16ds_v4 | /db2 | P6 | 1 | 240 | 50 | 64 | 3.500 | 170 | ||
| vCPU: 16 | /db2/<SID>/sapdata |
P15 | 4 | 4.400 | 500 | 1.024 | 14.000 | 680 | 256 kB | ReadOnly |
| RAM: 128 GiB | /db2/<SID>/saptmp |
P6 | 2 | 480 | 100 | 128 | 7.000 | 340 | 128 KB | |
/db2/<SID>/log_dir |
P15 | 2 | 2.200 | 250 | 512 | 7.000 | 340 | 64 KB |
||
/db2/<SID>/offline_log_dir |
P10 | 1 | 500 | 100 | 128 | 3.500 | 170 |
Sistema SAP medio: dimensioni del database da 500 a 1000 GB: small Business Suite
| Nome macchina virtuale/Dimensioni | Punto di montaggio Db2 | Disco Premium di Azure | Numero di dischi | IOPS | Attraverso- put [MB/s] |
Dimensioni [GB] | Operazioni di I/O al secondo in modalità burst | Burst Through- put [GB] |
Dimensioni di striping | Memorizzazione nella cache |
|---|---|---|---|---|---|---|---|---|---|---|
| E32ds_v4 | /db2 | P6 | 1 | 240 | 50 | 64 | 3.500 | 170 | ||
| vCPU: 32 | /db2/<SID>/sapdata |
P30 | 2 | 10,000 | 400 | 2.048 | 10,000 | 400 | 256 kB | ReadOnly |
| RAM: 256 GiB | /db2/<SID>/saptmp |
P10 | 2 | 1,000 | 200 | 256 | 7.000 | 340 | 128 KB | |
/db2/<SID>/log_dir |
P20 | 2 | 4,600 | 300 | 1.024 | 7.000 | 340 | 64 KB |
||
/db2/<SID>/offline_log_dir |
P15 | 1 | 1.100 | 125 | 256 | 3.500 | 170 |
Sistema SAP di grandi dimensioni: dimensioni del database da 750 a 2000 GB: Business Suite
| Nome macchina virtuale/Dimensioni | Punto di montaggio Db2 | Disco Premium di Azure | Numero di dischi | IOPS | Attraverso- put [MB/s] |
Dimensioni [GB] | Operazioni di I/O al secondo in modalità burst | Burst Through- put [GB] |
Dimensioni di striping | Memorizzazione nella cache |
|---|---|---|---|---|---|---|---|---|---|---|
| E64ds_v4 | /db2 | P6 | 1 | 240 | 50 | 64 | 3.500 | 170 | ||
| vCPU: 64 | /db2/<SID>/sapdata |
P30 | 4 | 20.000 | 800 | 4.096 | 20.000 | 800 | 256 kB | ReadOnly |
| RAM: 504 GiB | /db2/<SID>/saptmp |
P15 | 2 | 2.200 | 250 | 512 | 7.000 | 340 | 128 KB | |
/db2/<SID>/log_dir |
P20 | 4 | 9.200 | 600 | 2.048 | 14.000 | 680 | 64 KB |
||
/db2/<SID>/offline_log_dir |
P20 | 1 | 2.300 | 150 | 512 | 3.500 | 170 |
Sistema SAP multi-terabyte di grandi dimensioni: dimensioni del database 2 TB+: sistema Global Business Suite
| Nome macchina virtuale/Dimensioni | Punto di montaggio Db2 | Disco Premium di Azure | Numero di dischi | IOPS | Attraverso- put [MB/s] |
Dimensioni [GB] | Operazioni di I/O al secondo in modalità burst | Burst Through- put [GB] |
Dimensioni di striping | Memorizzazione nella cache |
|---|---|---|---|---|---|---|---|---|---|---|
| M128s | /db2 | P10 | 1 | 500 | 100 | 128 | 3.500 | 170 | ||
| vCPU: 128 | /db2/<SID>/sapdata |
P40 | 4 | 30.000 | 1.000 | 8.192 | 30.000 | 1.000 | 256 kB | ReadOnly |
| RAM: 2.048 GiB | /db2/<SID>/saptmp |
P20 | 2 | 4,600 | 300 | 1.024 | 7.000 | 340 | 128 KB | |
/db2/<SID>/log_dir |
P30 | 4 | 20.000 | 800 | 4.096 | 20.000 | 800 | 64 KB |
Scrivere- Acceleratore |
|
/db2/<SID>/offline_log_dir |
P30 | 1 | 5,000 | 200 | 1.024 | 5,000 | 200 |
Uso di Azure NetApp Files
L'uso dei volumi NFS v4.1 basato su Azure NetApp Files (ANF) è supportato con IBM Db2, ospitato nel sistema operativo guest Suse o Red Hat Linux. È consigliabile creare almeno quattro volumi diversi, ad esempio:
- Volume condiviso per saptmp1, sapmnt, usr_sap,
<sid>_home, db2<sid>_home, db2_software - Un volume di dati da sapdata1 a sapdatan
- Un volume di log per la directory di log di rollforward
- Un volume per gli archivi di log e i backup
Un quinto volume potenziale può essere un volume ANF usato per i backup a lungo termine usati per creare snapshot e archiviare gli snapshot nell'archivio BLOB di Azure.
La configurazione potrebbe essere simile alla seguente:
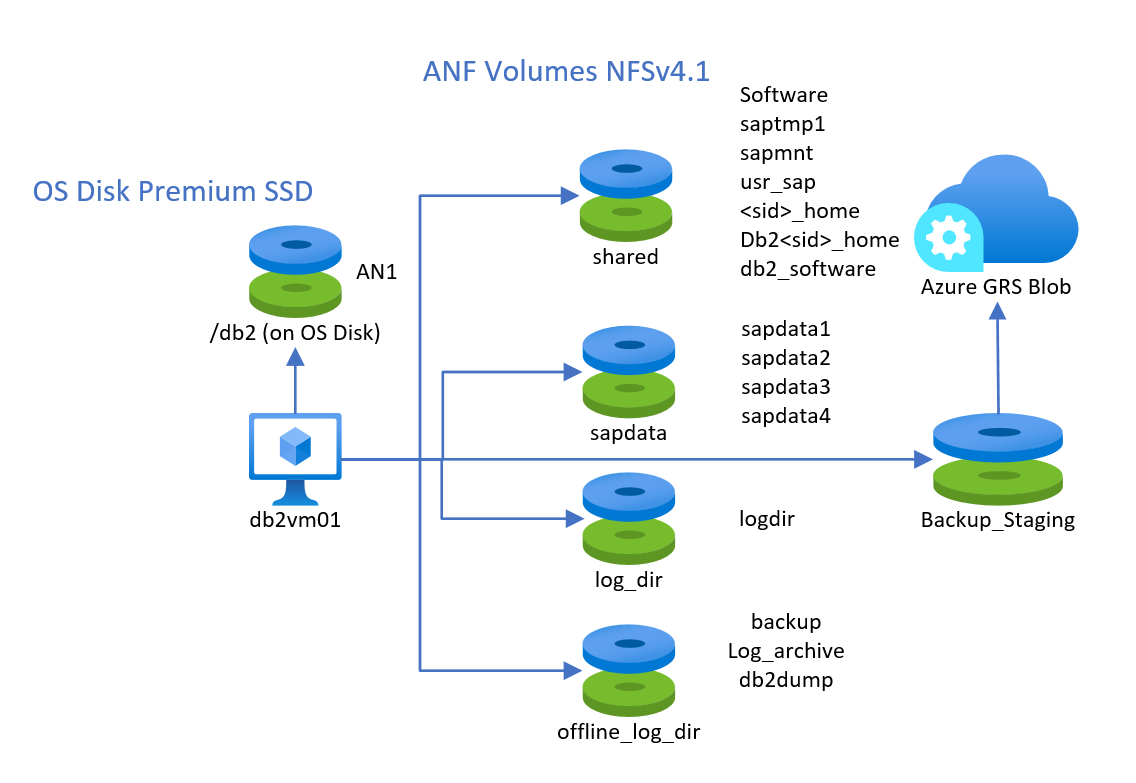
Il livello di prestazioni e le dimensioni dei volumi ospitati ANF devono essere scelti in base ai requisiti di prestazioni. È tuttavia consigliabile usare il livello di prestazioni Ultra per i dati e il volume di log. Non è supportato combinare l'archiviazione a blocchi e i tipi di archiviazione condivisa per i dati e il volume di log.
A partire dalle opzioni di montaggio, il montaggio di tali volumi potrebbe essere simile a (è necessario sostituire <SID> e <sid> con il SID del sistema SAP):
vi /etc/idmapd.conf
# Example
[General]
Domain = defaultv4iddomain.com
[Mapping]
Nobody-User = nobody
Nobody-Group = nobody
mount -t nfs -o rw,hard,sync,rsize=262144,wsize=262144,sec=sys,vers=4.1,tcp 172.17.10.4:/db2shared /mnt
mkdir -p /db2/Software /db2/AN1/saptmp /usr/sap/<SID> /sapmnt/<SID> /home/<sid>adm /db2/db2<sid> /db2/<SID>/db2_software
mkdir -p /mnt/Software /mnt/saptmp /mnt/usr_sap /mnt/sapmnt /mnt/<sid>_home /mnt/db2_software /mnt/db2<sid>
umount /mnt
mount -t nfs -o rw,hard,sync,rsize=262144,wsize=262144,sec=sys,vers=4.1,tcp 172.17.10.4:/db2data /mnt
mkdir -p /db2/AN1/sapdata/sapdata1 /db2/AN1/sapdata/sapdata2 /db2/AN1/sapdata/sapdata3 /db2/AN1/sapdata/sapdata4
mkdir -p /mnt/sapdata1 /mnt/sapdata2 /mnt/sapdata3 /mnt/sapdata4
umount /mnt
mount -t nfs -o rw,hard,sync,rsize=262144,wsize=262144,sec=sys,vers=4.1,tcp 172.17.10.4:/db2log /mnt
mkdir /db2/AN1/log_dir
mkdir /mnt/log_dir
umount /mnt
mount -t nfs -o rw,hard,sync,rsize=262144,wsize=262144,sec=sys,vers=4.1,tcp 172.17.10.4:/db2backup /mnt
mkdir /db2/AN1/backup
mkdir /mnt/backup
mkdir /db2/AN1/offline_log_dir /db2/AN1/db2dump
mkdir /mnt/offline_log_dir /mnt/db2dump
umount /mnt
Nota
L'opzione di montaggio è hard e sync sono necessarie
Backup/Ripristino
La funzionalità di backup/ripristino per IBM Db2 per LUW è supportata esattamente come nei sistemi operativi Windows Server standard e in Hyper-V.
Assicurarsi di disporre di una strategia di backup del database valida.
Come nelle distribuzioni bare metal, le prestazioni di backup/ripristino dipendono dalla quantità di volumi leggibili in parallelo e dalla velocità effettiva di tali volumi. Inoltre, l'uso di CPU associato alla compressione del backup può avere un ruolo significativo per VM con un massimo di otto thread CPU. Si può quindi presumere quanto segue:
- Minore è il numero dei dischi usati per l'archiviazione dei dispositivi del database, più bassa è la velocità effettiva generale nella lettura
- Minore è il numero di thread CPU nella VM, più forte è l'impatto della compressione del backup
- Minore è il numero di destinazioni (directory di striping o dischi) in cui scrivere il backup, più bassa è la velocità effettiva
Per aumentare il numero di destinazioni in cui scrivere, è possibile usare/combinare due opzioni a seconda delle proprie esigenze:
- Striping del volume di destinazione di backup su più dischi per migliorare la velocità effettiva delle operazioni di I/O al secondo in quel volume con striping
- Uso di più di una directory di destinazione in cui scrivere il backup
Nota
Db2 in Windows non supporta la tecnologia Windows VSS. Di conseguenza, il backup della macchina virtuale coerente con l'applicazione del servizio Backup di Azure non può essere usato per le macchine virtuali in cui è distribuito Db2 DBMS.
Disponibilità elevata e ripristino di emergenza
Linux Pacemaker
Importante
Per Db2 versioni 11.5.6 e successive è consigliabile usare Pacemaker con IBM.
- Soluzione integrata con Pacemaker
- Sono supportate configurazioni alternative o aggiuntive disponibili nel ripristino di emergenza a disponibilità elevata (HADR) di Microsoft Azure Db2 con pacemaker. Sono supportati sia I sistemi operativi SLES che RHEL. Questa configurazione abilita la disponibilità elevata di IBM Db2 per SAP. Guide alla distribuzione:
- SLES: disponibilità elevata di IBM Db2 LUW in macchine virtuali di Azure su SU edizione Standard Linux Enterprise Server con Pacemaker
- RHEL: disponibilità elevata di IBM Db2 LUW in macchine virtuali di Azure in Red Hat Enterprise Linux Server
Windows Cluster Server
Microsoft Cluster Server (MSCS) non è supportato.
La disponibilità elevata e il ripristino di emergenza Db2 sono supportati. Se le macchine virtuali della configurazione a disponibilità elevata hanno una risoluzione dei nomi funzionanti, la configurazione in Azure non è diversa da qualsiasi configurazione eseguita in locale. Non è consigliabile basarsi solo sulla risoluzione IP.
Non usare la replica geografica per gli account di archiviazione che archiviano i dischi del database. Per altre informazioni, vedere il documento Considerazioni per la distribuzione dbms di Azure Macchine virtuali per il carico di lavoro SAP.
Rete accelerata
Per le distribuzioni Db2 in Windows, è consigliabile usare la funzionalità di rete accelerata di Azure come descritto nel documento Rete accelerata di Azure. Valutare anche i consigli offerti in Considerations for Azure Virtual Machines DBMS deployment for SAP workload (Considerazioni sulla distribuzione DBMS di macchine virtuali di Azure per un carico di lavoro SAP).
Informazioni specifiche per le distribuzioni di Linux
Se la quota corrente di operazioni di I/O al secondo per disco è sufficiente, è possibile archiviare tutti i file di database in un singolo disco. Mentre è sempre necessario separare i file di dati e i file di log delle transazioni in dischi diversi.
Se la velocità effettiva di I/O al secondo o I/O di un singolo disco rigido virtuale di Azure non è sufficiente, è possibile usare LVM (Logical Volume Manager) o MDADM, come descritto nel documento Considerazioni sulla distribuzione dbMS di Azure Macchine virtuali per il carico di lavoro SAP per creare un dispositivo logico di grandi dimensioni su più dischi.
Per i dischi contenenti i percorsi di archiviazione Db2 per sapdata le directory e saptmp , è necessario specificare una dimensione del settore del disco fisico di 512 KB.
Altro
Tutte le altre aree generali, ad esempio i set di disponibilità di Azure o il monitoraggio SAP, si applicano anche alle distribuzioni di macchine virtuali con il database IBM. Queste aree generali vengono descritte in Considerazioni per la distribuzione dbms di Azure Macchine virtuali per il carico di lavoro SAP.
Passaggi successivi
Leggi l'articolo: