Percorsi di integrazione di Microsoft Fabric per ISV
Microsoft Fabric offre tre percorsi distinti per gli ISV per l'integrazione senza problemi con Fabric. Per un ISV a partire da questo percorso, vogliamo esaminare varie risorse disponibili in ognuno di questi percorsi.
Interoperabilità con Fabric
L'obiettivo principale del modello di interoperabilità è consentire agli ISV di integrare le proprie soluzioni con OneLake Foundation. Per interagire con Microsoft Fabric, viene fornito l'integrazione usando le API REST per OneLake, una moltitudine di connettori in Data Factory, collegamenti in OneLake e mirroring del database.

Ecco alcuni modi per iniziare a usare questo modello:
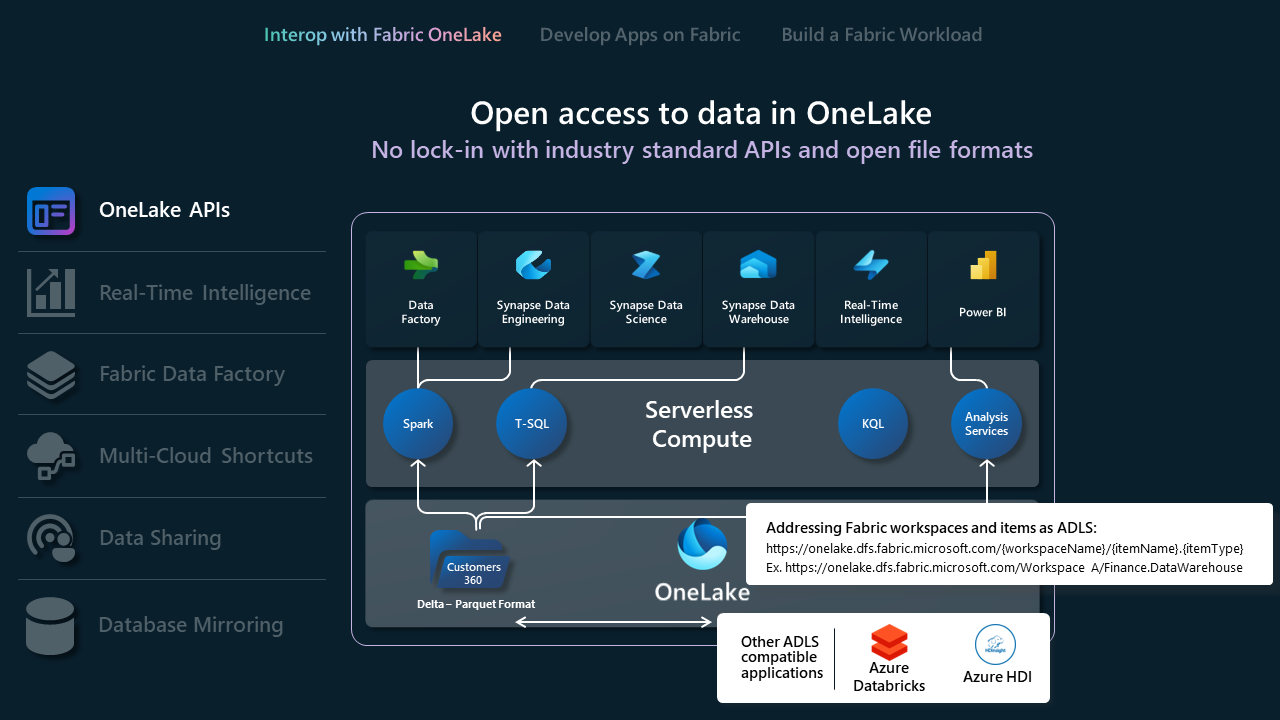
API OneLake
- OneLake supporta le API e gli SDK di Azure Data Lake Archiviazione Gen2 esistenti per l'interazione diretta, consentendo agli sviluppatori di leggere, scrivere e gestire i dati in OneLake. Altre informazioni sulle API REST di ADLS Gen2 e su come connettersi a OneLake.
- Poiché non tutte le funzionalità in ADLS Gen2 vengono mappate direttamente a OneLake, OneLake applica anche una struttura di cartelle impostata per supportare aree di lavoro e elementi di Fabric. Per un elenco completo dei diversi comportamenti tra OneLake e ADLS Gen2 quando si chiamano queste API, vedere Parità dell'API OneLake.
- Se si usa Databricks e si vuole connettersi a Microsoft Fabric, Databricks funziona con le API di ADLS Gen2. Integrare OneLake con Azure Databricks.
- Per sfruttare al meglio il formato di Archiviazione Delta Lake, esaminare e comprendere il formato, l'ottimizzazione della tabella e l'ordine V. Ottimizzazione della tabella Delta Lake e Ordine V.
- Una volta che i dati si trovano in OneLake, esplorare localmente usando OneLake Esplora file. OneLake File Explorer integra facilmente OneLake con Windows Esplora file. Questa applicazione sincronizza automaticamente tutti gli elementi di OneLake a cui si ha accesso in Windows Esplora file. È anche possibile usare qualsiasi altro strumento compatibile con ADLS Gen2, ad esempio Archiviazione di Azure Explorer.
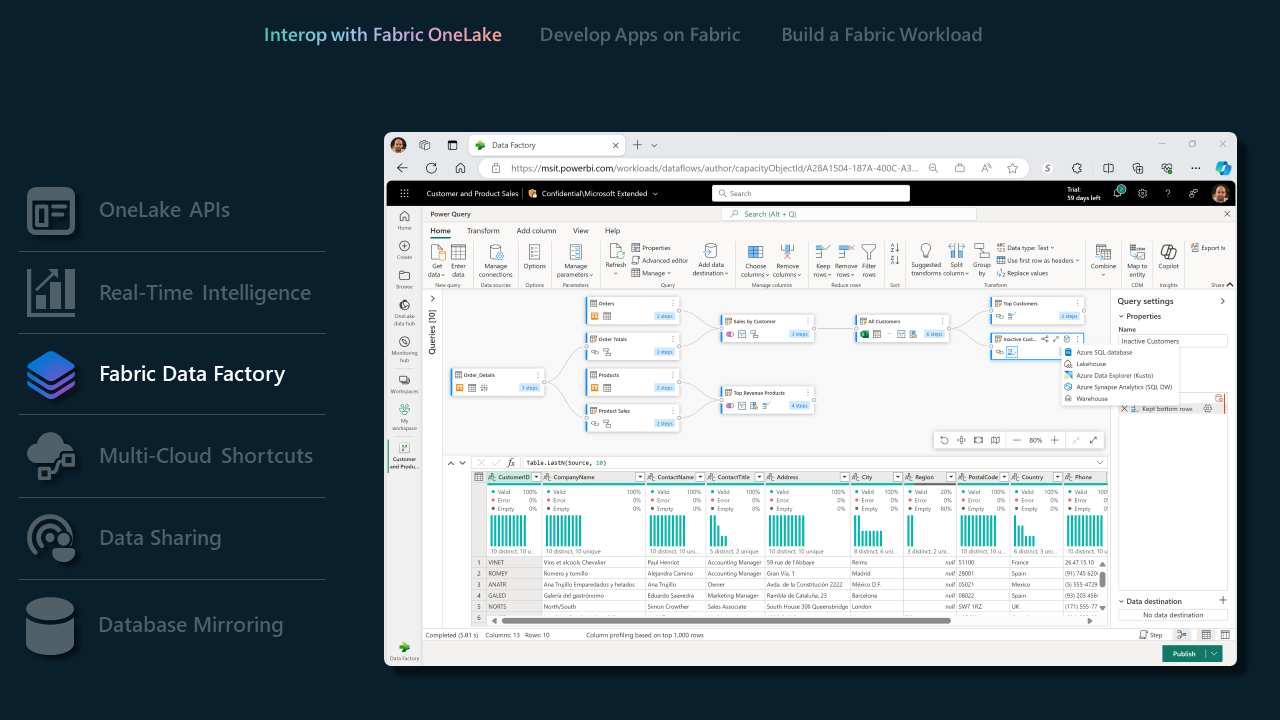
Data Factory in Fabric
- Data Pipelines offre un ampio set di connettori, consentendo agli ISV di connettersi senza problemi a una miriade di archivi dati. Che si tratti di interfaccia di database tradizionali o soluzioni moderne basate sul cloud, i connettori garantiscono un processo di integrazione uniforme. panoramica di Connessione or.
- Con i connettori di Dataflow Gen2 supportati, gli ISV possono sfruttare la potenza di Data Factory di Fabric per gestire flussi di lavoro di dati complessi. Questa funzionalità è particolarmente utile per gli ISV che cercano di semplificare le attività di elaborazione e trasformazione dei dati. Connettori di Dataflow Gen2 in Microsoft Fabric.
- Per un elenco completo delle funzionalità supportate da Data Factory in Fabric, vedere questo blog di Data Factory in Fabric.
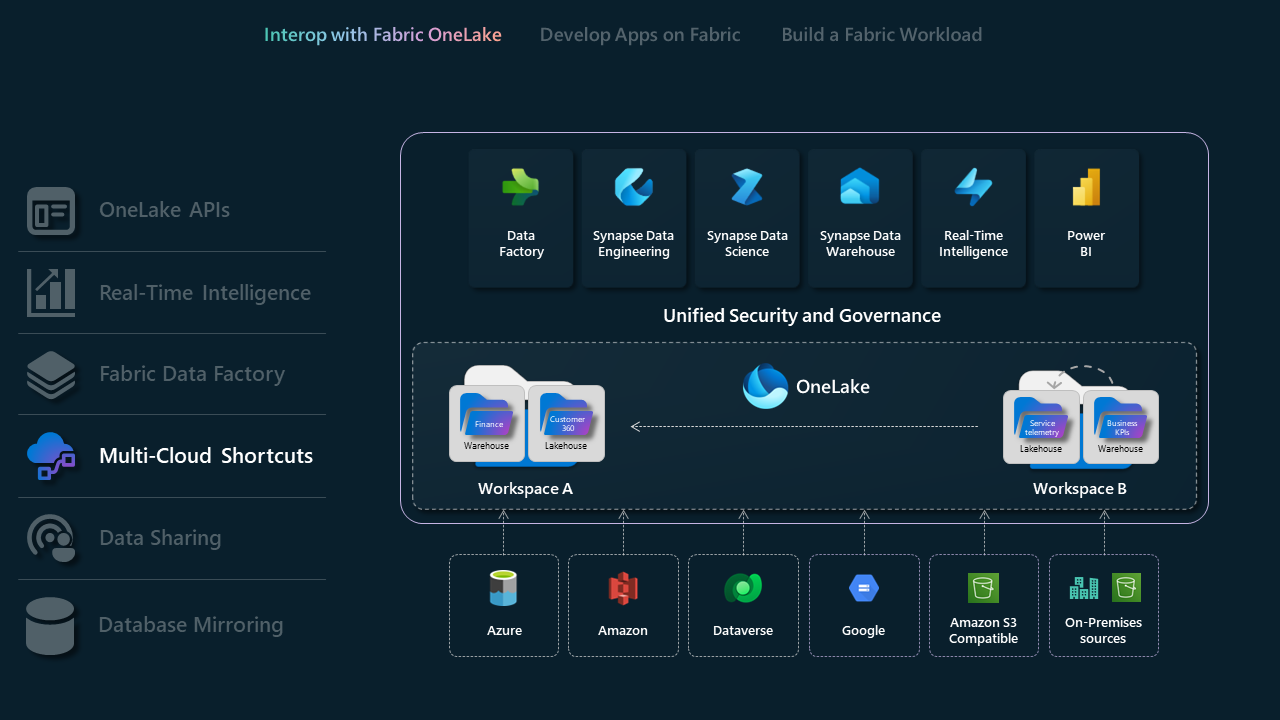
Tasti di scelta rapida multicloud
I collegamenti in Microsoft OneLake consentono di unificare i dati tra domini, cloud e account creando un singolo data lake virtuale per l'intera azienda. Tutte le esperienze dell'infrastruttura e i motori analitici possono puntare direttamente alle origini dati esistenti, ad esempio OneLake in un tenant diverso, Azure Data Lake Archiviazione Gen2, account di archiviazione Amazon S3 e Dataverse tramite uno spazio dei nomi unificato. OneLake presenta ISV con una soluzione di accesso ai dati trasformativa, senza problemi di integrazione tra domini e piattaforme cloud diverse.
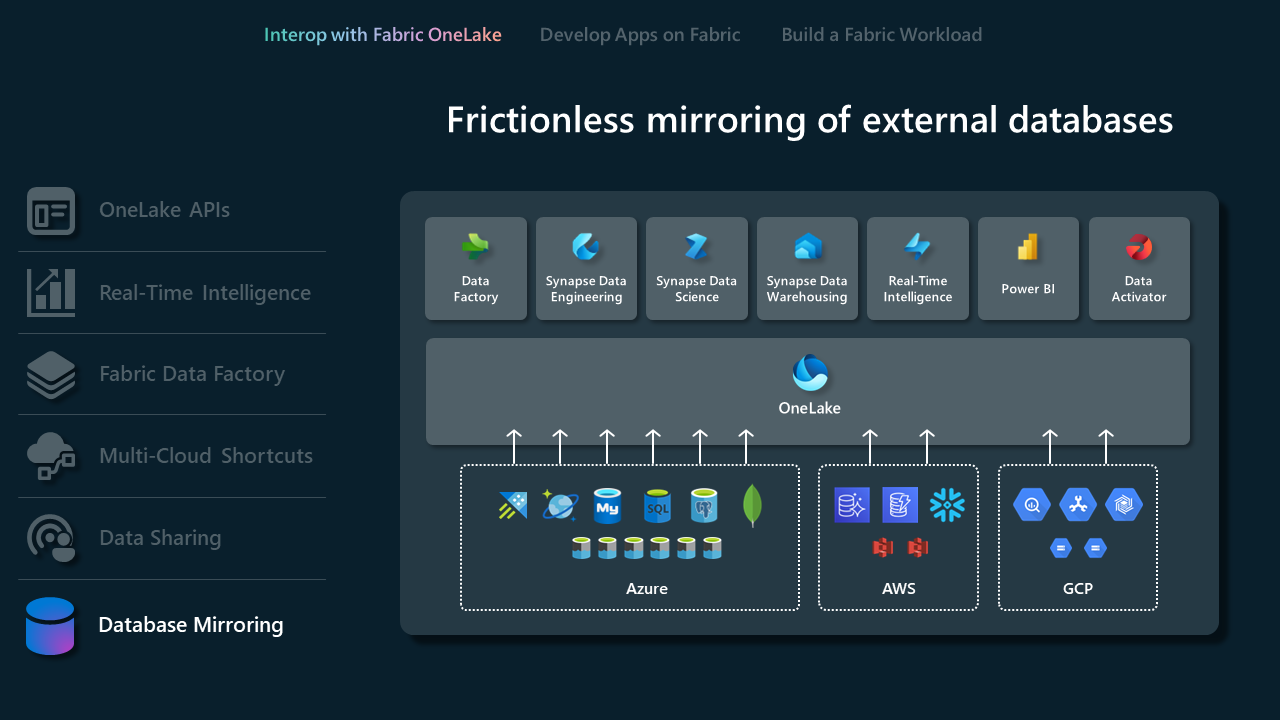
Mirroring del database
Sono state visualizzate le scelte rapide, ora ci si chiede di integrare le funzionalità con database esterni e warehouse. Il mirroring offre un modo moderno per accedere e inserire i dati in modo continuo e senza interruzioni da qualsiasi database o data warehouse nell'esperienza di data warehousing in Microsoft Fabric. Il mirror è tutto quasi in tempo reale, consentendo così agli utenti di accedere immediatamente alle modifiche nell'origine. Per altre informazioni sul mirroring e sui database supportati, vedere Introduzione al mirroring in Microsoft Fabric.
Sviluppare nell'infrastruttura
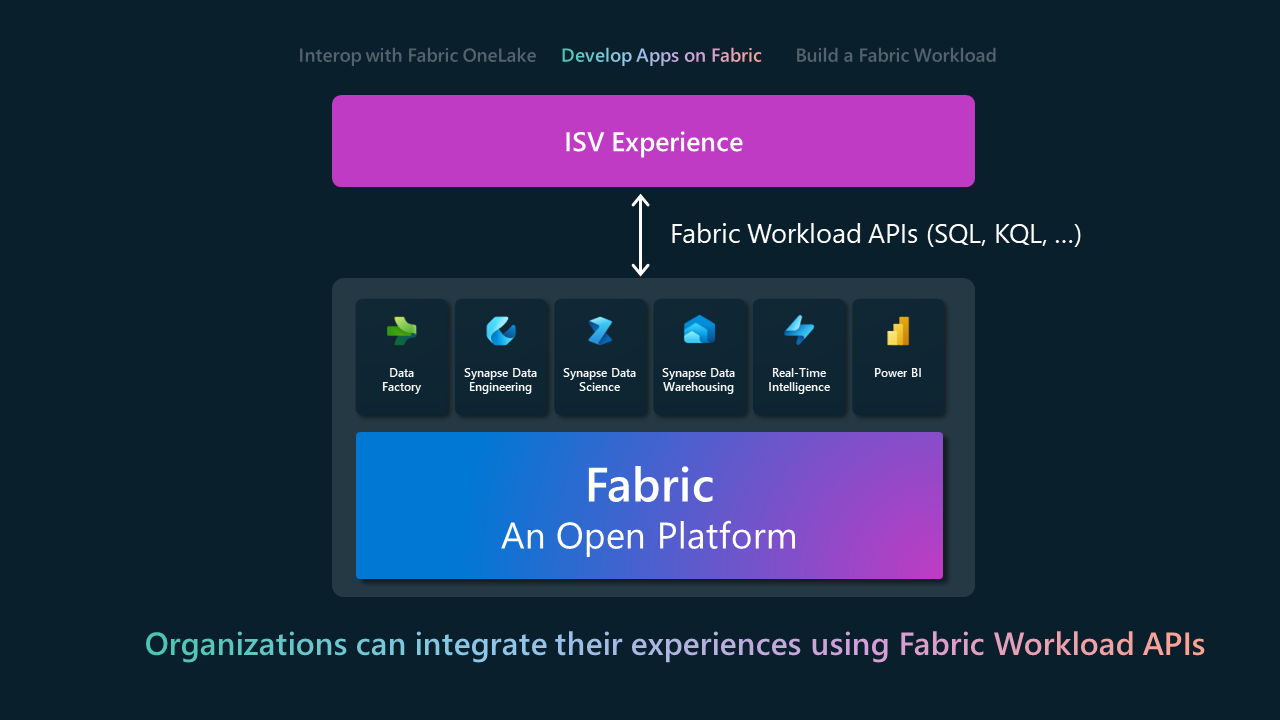
Con gli ISV del modello Develop on Fabric è possibile creare i propri prodotti e servizi oltre a Fabric o incorporare facilmente le funzionalità di Fabric all'interno delle applicazioni esistenti. Si tratta di una transizione dall'integrazione di base all'applicazione attiva delle funzionalità offerte da Fabric. La superficie di attacco di integrazione principale è tramite le API REST per vari carichi di lavoro di Fabric. Di seguito è riportato un elenco delle API REST attualmente disponibili.
| Esperienza infrastruttura | API | Descrizione |
|---|---|---|
| Data Warehouse | ||
| Creare un magazzino | Crea un data warehouse. | |
| Ottenere il magazzino | Ottenere i metadati relativi al warehouse. | |
| Aggiornare il magazzino | Aggiornare un magazzino esistente. | |
| Elimina magazzino | Eliminare un magazzino esistente. | |
| List Warehouse | Elencare i warehouse nell'area di lavoro. | |
| Ingegneria dei dati | ||
| Creare Lakehouse | Crea Lakehouse insieme all'endpoint di analisi SQL. | |
| Update Lakehouse | Aggiornamenti il nome di una lakehouse e dell'endpoint di analisi SQL. | |
| Eliminare Lakehouse | Elimina lakehouse e l'endpoint di analisi SQL associato. | |
| Ottenere le proprietà | Ottiene le proprietà di un lakehouse e dell'endpoint di analisi SQL. | |
| Elencare le tabelle | Elencare le tabelle nella lakehouse. | |
| Caricamento tabella | Crea tabelle differenziali da file e cartelle CSV e parquet. | |
| OneLake | ||
| Crea collegamento | Crea un nuovo collegamento. | |
| Elimina collegamento | Elimina il collegamento ma non elimina la cartella di archiviazione di destinazione. | |
| Ottieni collegamento | Restituisce le proprietà dei tasti di scelta rapida. | |
| API ADLS Gen2 | API ADLS Gen2 per creare e gestire file system, directory e percorso. | |
| Area di lavoro | ||
| API CRUD per la gestione dei ruoli dell'area di lavoro e dell'area di lavoro | Crea area di lavoro, Ottieni dettagli area di lavoro, Elimina area di lavoro, Assegna area di lavoro a una capacità, Aggiungi un'assegnazione di ruolo dell'area di lavoro. | |
| Fabric Data Factory | Presto disponibile | |
| Analytics in tempo reale | Presto disponibili |
Questa sezione verrà aggiornata man mano che diventano disponibili altre API fabric.
Creare un carico di lavoro di infrastruttura
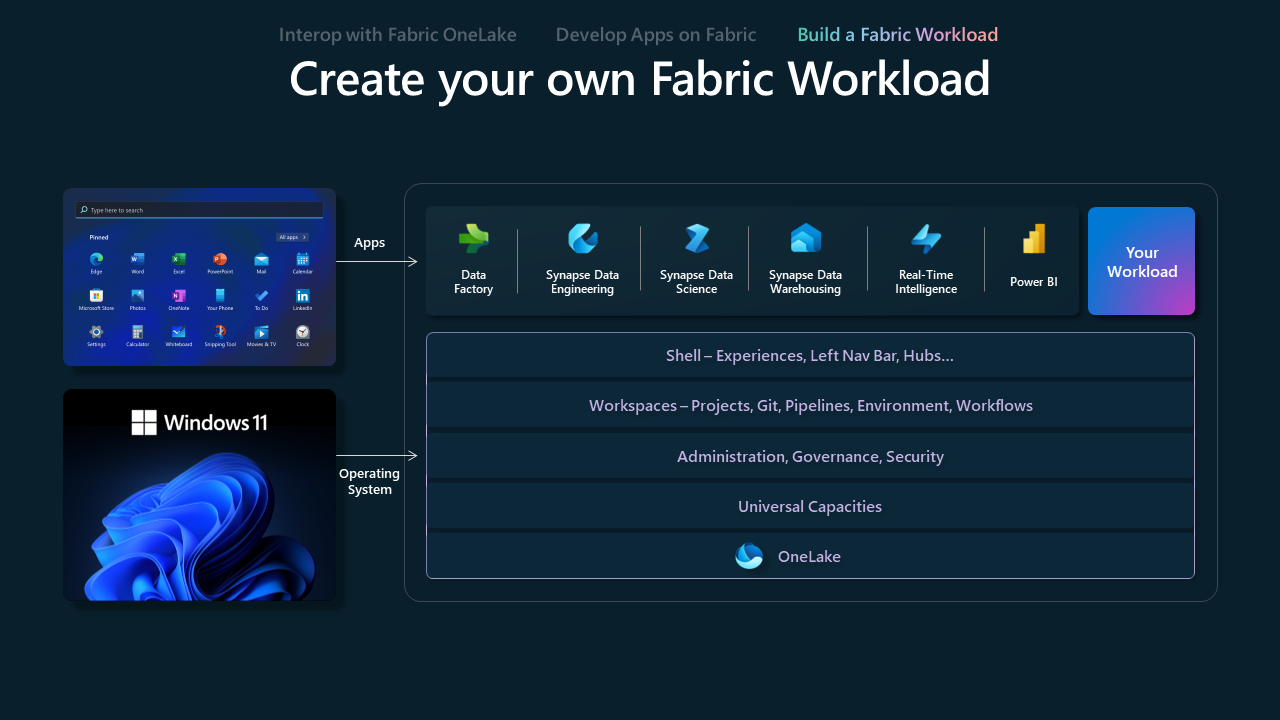
Creare un modello di carico di lavoro infrastruttura è progettato per fornire agli ISV gli strumenti e le funzionalità della piattaforma necessari per creare carichi di lavoro e esperienze personalizzati in Fabric. Consente agli ISV di personalizzare le offerte per offrire la propria proposta di valore sfruttando l'ecosistema Fabric combinando il meglio di entrambi i mondi. Stiamo lavorando a stretto contatto con i partner di progettazione selezionati per questo percorso di integrazione ed è attualmente disponibile solo per invito.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per