Come copiare dati usando l'attività di copia
Nella pipeline di dati è possibile usare il attività Copy per copiare i dati tra gli archivi dati che si trovano nel cloud.
Dopo aver copiato i dati, è possibile usare altre attività per trasformarli e analizzarli ulteriormente. È anche possibile usare il attività Copy per pubblicare i risultati della trasformazione e dell'analisi per business intelligence (BI) e l'utilizzo delle applicazioni.
Per copiare dati da un'origine a una destinazione, il servizio che esegue il attività Copy esegue questi passaggi:
- Legge i dati dall'archivio dati di origine.
- Esegue la serializzazione/deserializzazione, la compressione/decompressione, il mapping delle colonne e così via. Esegue queste operazioni in base alla configurazione.
- Scrive i dati nell'archivio dati di destinazione.
Prerequisiti
Per iniziare, è necessario completare i prerequisiti seguenti:
Un account tenant di Microsoft Fabric con una sottoscrizione attiva. Creare un account gratuitamente.
Assicurarsi di disporre di un'area di lavoro abilitata per Microsoft Fabric.
Aggiungere un'attività di copia usando l'assistente copia
Seguire questa procedura per configurare l'attività di copia usando l'assistente copia.
Iniziare con l'assistente copia
Aprire una pipeline di dati esistente o creare una nuova pipeline di dati.
Selezionare Copia dati nell'area di disegno per aprire lo strumento Copia assistente per iniziare. In alternativa, selezionare Usa assistente copia dall'elenco a discesa Copia dati nella scheda Attività della barra multifunzione.
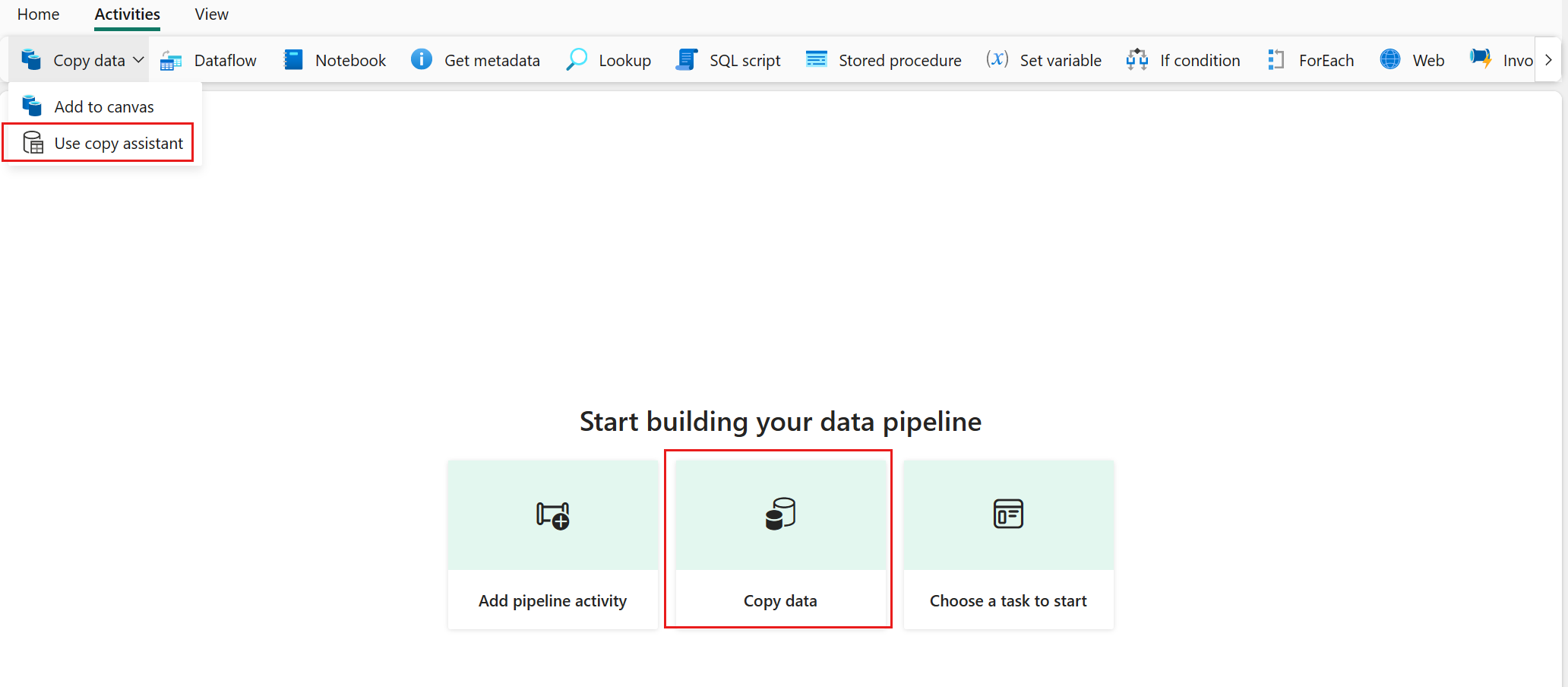

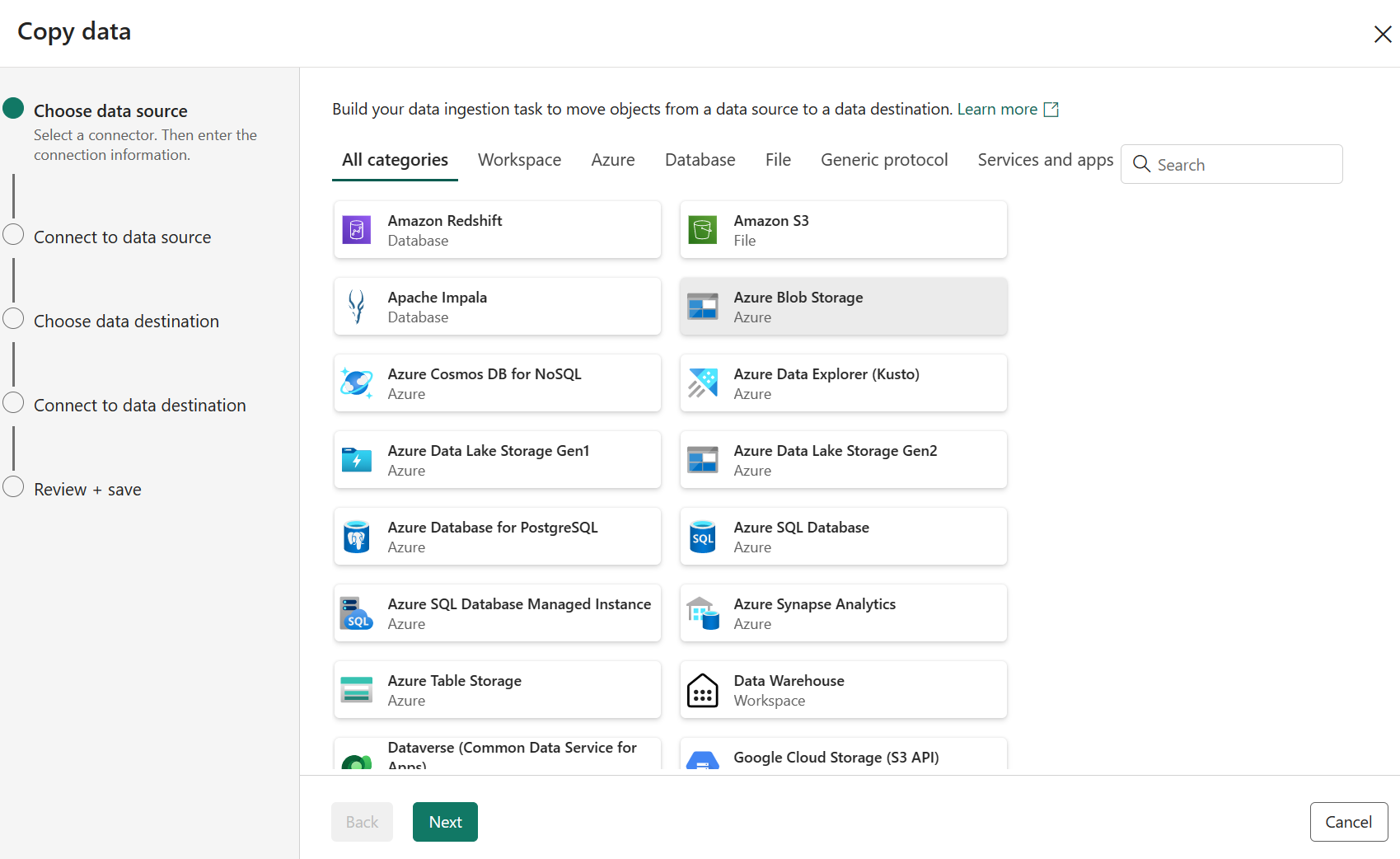
Configurare l'origine
Selezionare un tipo di origine dati dalla categoria. Si useranno Archiviazione BLOB di Azure come esempio. Selezionare Archiviazione BLOB di Azure e quindi avanti.
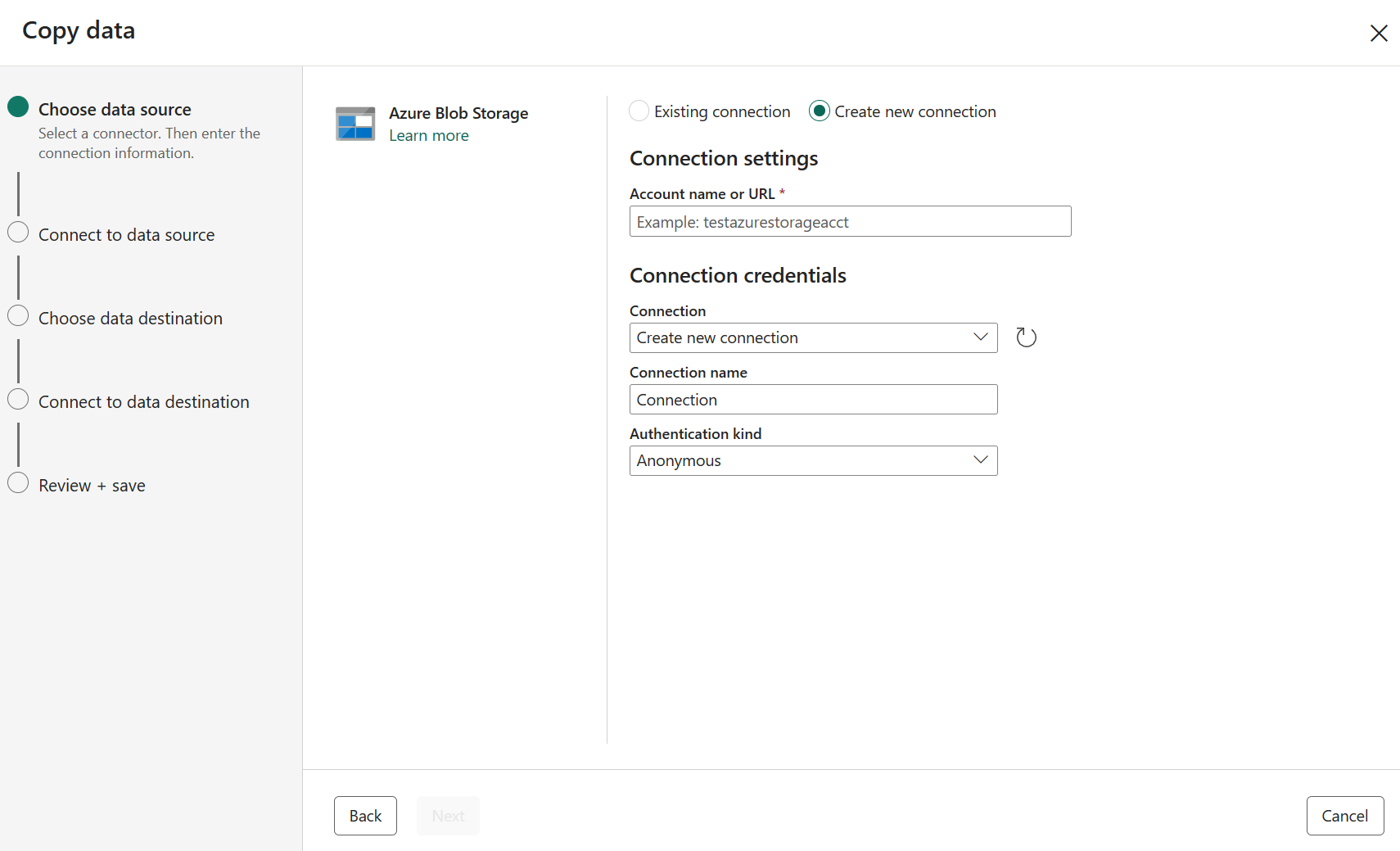
Creare una connessione all'origine dati selezionando Crea nuova connessione.

Dopo aver selezionato Crea nuova connessione, immettere le informazioni di connessione necessarie e quindi selezionare Avanti. Per informazioni dettagliate sulla creazione della connessione per ogni tipo di origine dati, è possibile fare riferimento a ogni articolo del connettore.
Se si dispone di connessioni esistenti, è possibile selezionare Connessione esistente e selezionare la connessione dall'elenco a discesa.
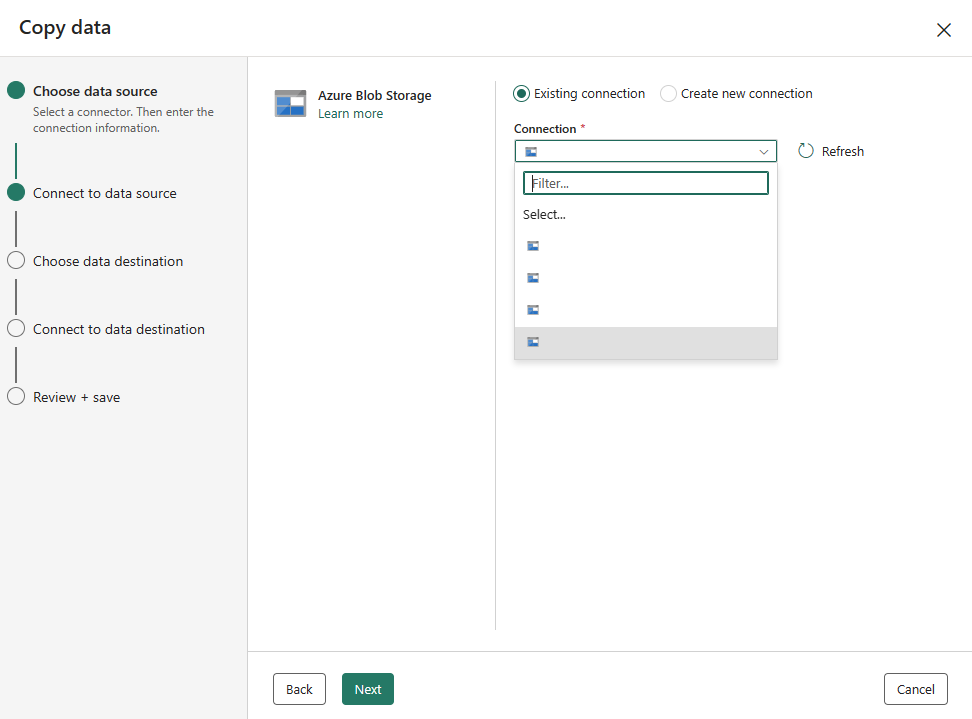
Scegliere il file o la cartella da copiare in questo passaggio di configurazione di origine e quindi selezionare Avanti.






Configurare la destinazione
Selezionare un tipo di origine dati dalla categoria. Si useranno Archiviazione BLOB di Azure come esempio. Selezionare Archiviazione BLOB di Azure e quindi selezionare Avanti.

È possibile creare una nuova connessione che collega a un nuovo account Archiviazione BLOB di Azure seguendo i passaggi della sezione precedente o usando una connessione esistente dall'elenco a discesa della connessione. Le funzionalità di Test connessione e Modifica sono disponibili per ogni connessione selezionata.

Configurare ed eseguire il mapping dei dati di origine alla destinazione. Selezionare quindi Avanti per completare le configurazioni di destinazione.






Esaminare e creare l'attività di copia
Esaminare le impostazioni dell'attività di copia nei passaggi precedenti e selezionare OK per completare. In alternativa, è possibile tornare ai passaggi precedenti per modificare le impostazioni, se necessario nello strumento.


Al termine, l'attività di copia verrà quindi aggiunta all'area di disegno della pipeline di dati. Tutte le impostazioni, incluse le impostazioni avanzate per questa attività di copia, sono disponibili nelle schede quando è selezionata.

È ora possibile salvare la pipeline di dati con questa singola attività di copia o continuare a progettare la pipeline di dati.
Aggiungere direttamente un'attività di copia
Seguire questa procedura per aggiungere direttamente un'attività di copia.
Aggiungere un'attività di copia
Aprire una pipeline di dati esistente o creare una nuova pipeline di dati.
Aggiungere un'attività di copia selezionando Aggiungi attività> pipeline attività Copy oppure selezionando Copia dati>Aggiungi all'area di disegno nella scheda Attività.

Configurare le impostazioni generali nella scheda Generale
Per informazioni su come configurare le impostazioni generali, vedere Generale.
Configurare l'origine nella scheda origine
Selezionare + Nuovo accanto al Connessione ion per creare una connessione all'origine dati.
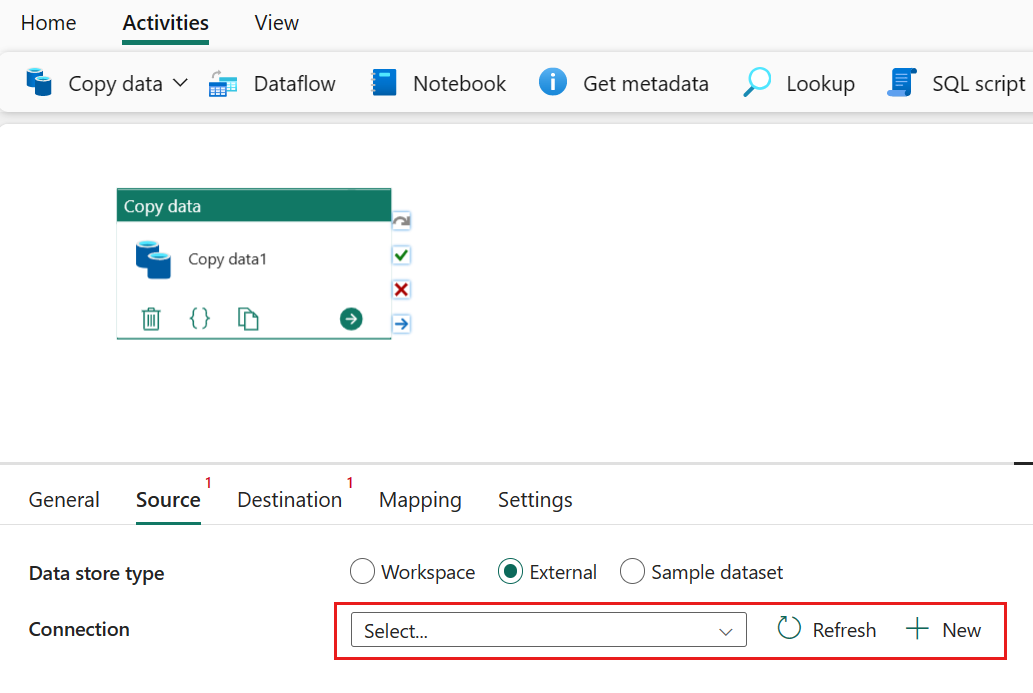
Scegliere il tipo di origine dati dalla finestra popup. Si userà database SQL di Azure come esempio. Selezionare Database SQL di Azure e quindi selezionare Continua.

Passa alla pagina di creazione della connessione. Immettere le informazioni di connessione necessarie nel pannello e quindi selezionare Crea. Per informazioni dettagliate sulla creazione della connessione per ogni tipo di origine dati, è possibile fare riferimento a ogni articolo del connettore.

Dopo aver creato correttamente la connessione, viene visualizzata nuovamente la pagina della pipeline di dati. Selezionare quindi Aggiorna per recuperare la connessione creata dall'elenco a discesa. È anche possibile scegliere una connessione database SQL di Azure esistente direttamente dall'elenco a discesa se è già stata creata in precedenza. Le funzionalità di Test connessione e Modifica sono disponibili per ogni connessione selezionata. Selezionare quindi database SQL di Azure nel tipo di Connessione ion.
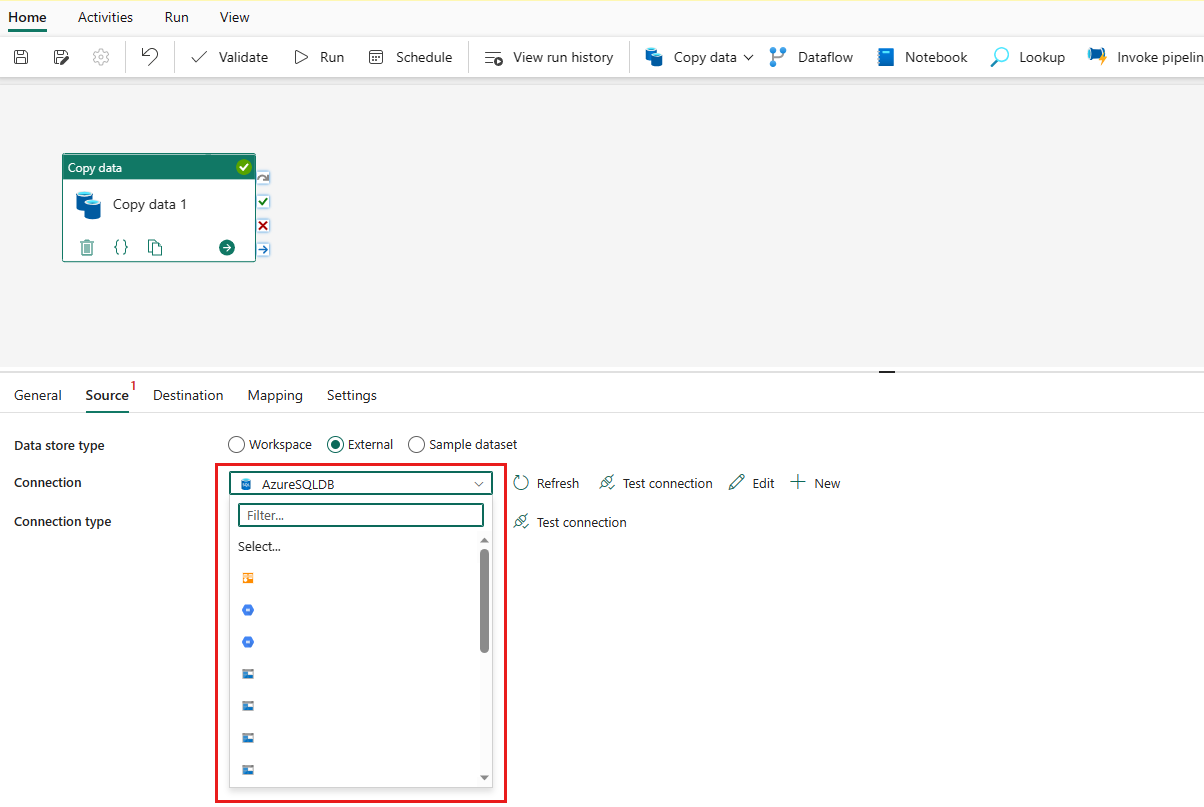
Specificare una tabella da copiare. Selezionare Anteprima dei dati per visualizzare in anteprima la tabella di origine. È anche possibile usare query e stored procedure per leggere i dati dall'origine.

Espandere Avanzate per impostazioni più avanzate.







Configurare la destinazione nella scheda destinazione
Scegliere il tipo di destinazione. Potrebbe trattarsi dell'archivio dati interno di prima classe dall'area di lavoro, ad esempio Lakehouse o dagli archivi dati esterni. Si userà Lakehouse come esempio.
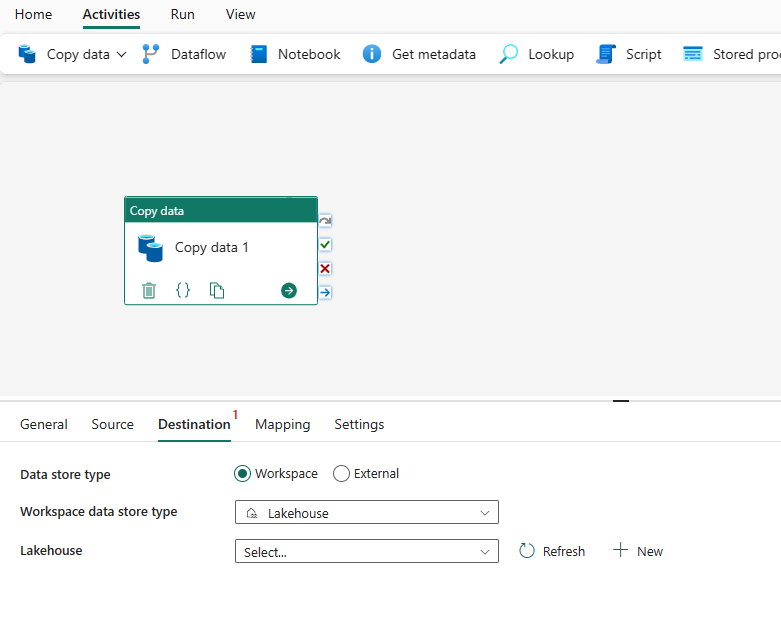
Scegliere di usare Lakehouse nel tipo di archivio dati dell'area di lavoro. Selezionare + Nuovo e passare alla pagina di creazione lakehouse. Specificare il nome di Lakehouse e quindi selezionare Crea.
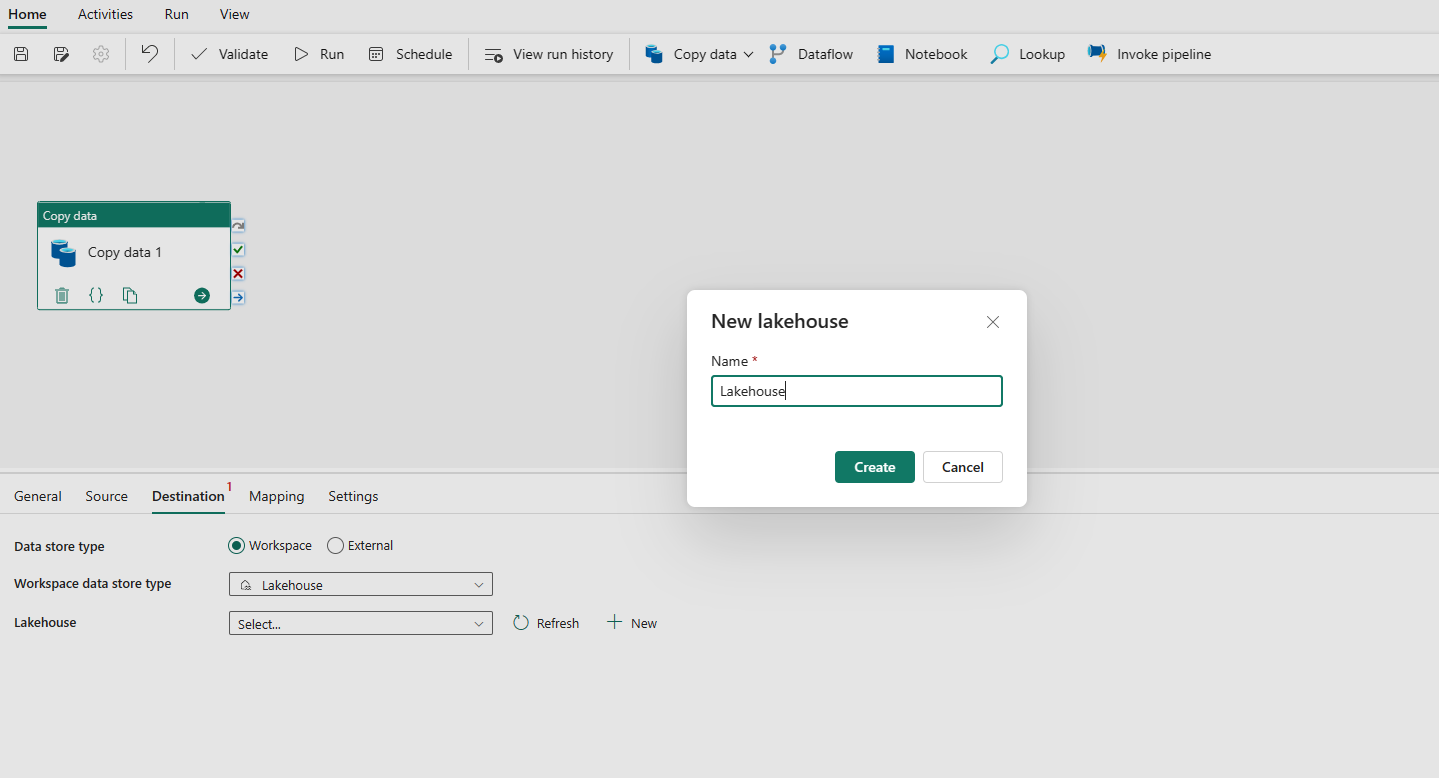
Dopo aver creato correttamente la connessione, viene visualizzata nuovamente la pagina della pipeline di dati. Selezionare quindi Aggiorna per recuperare la connessione creata dall'elenco a discesa. È anche possibile scegliere una connessione Lakehouse esistente dall'elenco a discesa direttamente se è già stata creata in precedenza.
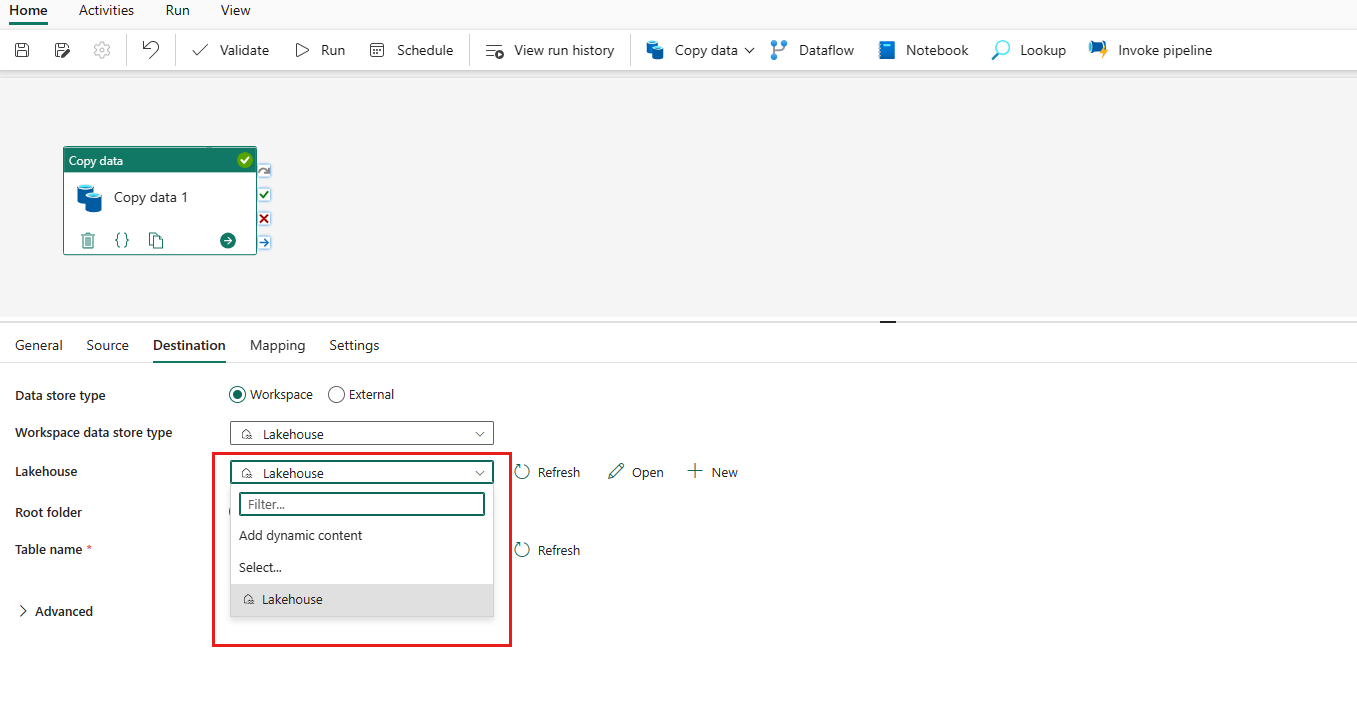
Specificare una tabella o impostare il percorso del file per definire il file o la cartella come destinazione. In questo caso selezionare Tabelle e specificare una tabella per scrivere dati.

Espandere Avanzate per impostazioni più avanzate.






È ora possibile salvare la pipeline di dati con questa singola attività di copia o continuare a progettare la pipeline di dati.
Configurare i mapping nella scheda Mapping
Se il connettore applicato supporta il mapping, è possibile passare alla scheda Mapping per configurare il mapping.
Selezionare Importa schemi per importare lo schema dei dati.

È possibile visualizzare il mapping automatico. Specificare la colonna Origine e la colonna Destinazione . Se si crea una nuova tabella nella destinazione, è possibile personalizzare il nome della colonna di destinazione qui. Se si desidera scrivere dati nella tabella di destinazione esistente, non è possibile modificare il nome della colonna di destinazione esistente. È anche possibile visualizzare il tipo di colonne di origine e di destinazione.



Inoltre, è possibile selezionare + Nuovo mapping per aggiungere nuovo mapping, selezionare Cancella per cancellare tutte le impostazioni di mapping e selezionare Reimposta per reimpostare tutta la colonna origine mapping.
Configurare la conversione del tipo
Espandere Impostazioni di conversione dei tipi per configurare la conversione del tipo, se necessario.

Per informazioni dettagliate sull'impostazione, vedere la tabella seguente.
| Impostazione | Descrizione |
|---|---|
| Consenti troncamento dei dati | Consente il troncamento dei dati durante la conversione dei dati di origine in destinazione con un tipo diverso durante la copia. Ad esempio, da decimale a integer, da DatetimeOffset a Datetime. |
| Considerare booleano come numero | Considerare booleano come numero. Ad esempio, considerare true come 1. |
| Formato data | Stringa di formato durante la conversione tra date e stringhe, ad esempio "aaaa-MM-gg". Per altre informazioni, vedere Stringhe di formato di data e ora personalizzato. La colonna date può essere letta come tipo di data per: • Amazon RDS per SQL Server • database SQL di Azure • database SQL di Azure Istanza gestita • Azure Synapse Analytics • Formato testo delimitato • Tabella lakehouse • Formato Parquet • SQL Server |
| Formato DateTime | Stringa di formato durante la conversione tra date senza differenza di fuso orario e stringhe. Ad esempio, "aa-MM-gg HH:mm:ss.fff". |
| Formato DateTimeOffset | Stringa di formato durante la conversione tra date con offset del fuso orario e stringhe. Ad esempio, "aaaa-MM-gg HH:mm:ss.fff zzz". |
| Formato TimeSpan | Stringa di formato durante la conversione tra periodi di tempo e stringhe. Ad esempio, "dd.hh:mm:ss". |
| Impostazioni cultura | Informazioni sulle impostazioni cultura da utilizzare durante la conversione dei tipi. Ad esempio, "en-us", "fr-fr". |
Configurare le altre impostazioni nella scheda Impostazioni
La scheda Impostazioni contiene le impostazioni delle prestazioni, della gestione temporanea e così via.

Per la descrizione di ogni impostazione, vedere la tabella seguente.
| Impostazione | Descrizione |
|---|---|
| Ottimizzazione della velocità effettiva intelligente | Specificare per ottimizzare la velocità effettiva. È possibile scegliere tra: • Auto • Standard • Bilanciato • Massimo Quando si sceglie Auto, l'impostazione ottimale viene applicata dinamicamente in base alla coppia di destinazione di origine e al modello di dati. È anche possibile personalizzare la velocità effettiva e il valore personalizzato può essere pari a 2-256, mentre un valore più alto implica ulteriori guadagni. |
| Grado di parallelismo di copia | Specificare il grado di parallelismo usato dal caricamento dei dati. |
| Tolleranza di errore | Quando si seleziona questa opzione, è possibile ignorare alcuni errori che si sono verificati durante il processo di copia. Ad esempio, righe incompatibili tra l'archivio di origine e di destinazione, il file eliminato durante lo spostamento dei dati e così via. |
| Abilitazione della registrazione | Quando si seleziona questa opzione, è possibile registrare file copiati, file ignorati e righe |
| Abilitare la gestione temporanea | Specificare se copiare i dati tramite un archivio di staging provvisorio. Abilitare la gestione temporanea solo per gli scenari vantaggiosi. |
| Connessione dell'account di gestione temporanea | Quando si seleziona Abilita gestione temporanea, specificare la connessione di un'origine dati di archiviazione di Azure come archivio di staging provvisorio. Selezionare + Nuovo per creare una connessione di staging se non è disponibile. |
Configurare i parametri in un'attività di copia
I parametri possono essere usati per controllare il comportamento di una pipeline e le relative attività. È possibile usare Aggiungi contenuto dinamico per specificare i parametri per le proprietà dell'attività di copia. Si userà ora Lakehouse/Data Warehouse/KQL Database come esempio per vedere come usarlo.
Nell'origine o nella destinazione, dopo aver selezionato Area di lavoro come tipo di archivio dati e specificando Il database KQL del data warehouse/Lakehouse/come tipo di archivio dati dell'area di lavoro, selezionare Aggiungi contenuto dinamico nell'elenco a discesa di Lakehouse o Data Warehouse o KQL Database.
Nel riquadro popup Aggiungi contenuto dinamico, nella scheda Parametri selezionare +.
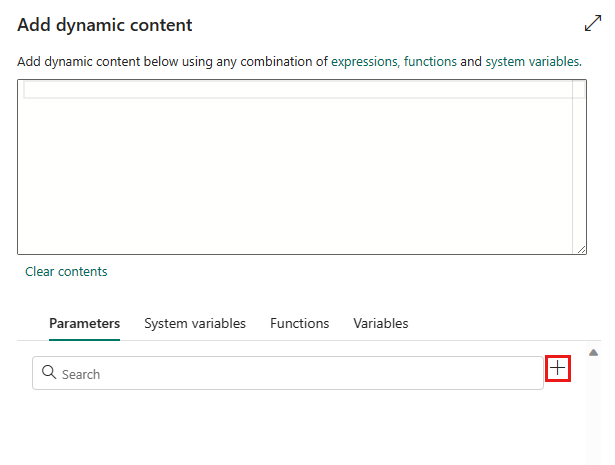
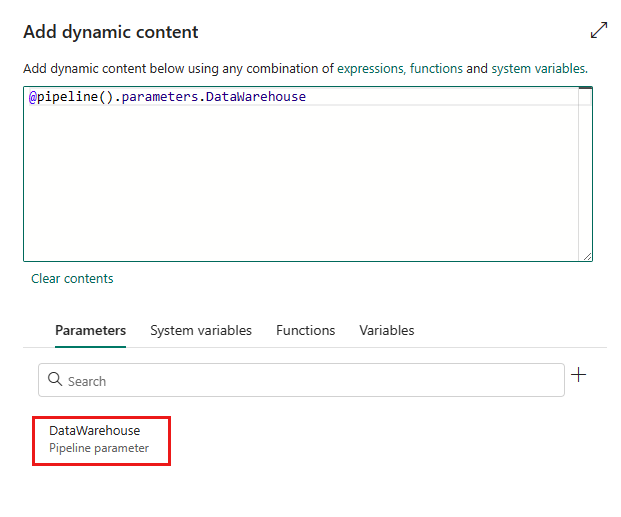
Specificare il nome per il parametro e assegnargli un valore predefinito, se necessario, oppure specificare il valore per il parametro dopo aver selezionato Esegui nella pipeline.

Si noti che il valore del parametro deve essere Lakehouse/Data Warehouse/KQL ID oggetto database. Per ottenere l'ID oggetto Database Lakehouse/Data Warehouse/KQL, aprire il database Lakehouse/Data Warehouse/KQL nell'area di lavoro e l'ID è successivo
/lakehouses/o/datawarehouses//databases/nell'URL.ID oggetto Lakehouse:

ID oggetto data warehouse:

ID oggetto database KQL:

Selezionare Salva per tornare al riquadro Aggiungi contenuto dinamico. Selezionare quindi il parametro in modo che venga visualizzato nella casella dell'espressione. Selezionare OK. Si tornerà alla pagina della pipeline e si noterà che l'espressione del parametro è specificata dopo l'ID/oggetto data warehouse dell'OGGETTO Lakehouse ID/KQL Database ID.
Contenuto correlato
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per