Modelli di calcolo e architetturali
In questa unità vengono esaminati i modelli di calcolo e architetturali di MapReduce.
Modello di calcolo
I processi MapReduce, come tutti i programmi distribuiti, possono incorporare un modello di calcolo sincrono o asincrono. Durante ogni fase e stadio, le attività MapReduce eseguono numerosi calcoli che dipendono dai risultati della fase o dello stadio precedente e possono procedere solo dopo l'arrivo dei dati. Un'attività di riduzione, ad esempio, può iniziare solo dopo l'arrivo di tutte le partizioni necessarie dagli stadi di shuffling e di unione e ordinamento. Inoltre, in una fase le attività non comunicano tra loro e le interazioni si verificano solo alla fine di uno stadio o di una fase. Qualsiasi sistema sincrono deve garantire questa proprietà di interazione2 e MapReduce rappresenta un valido esempio di tale modello di calcolo.
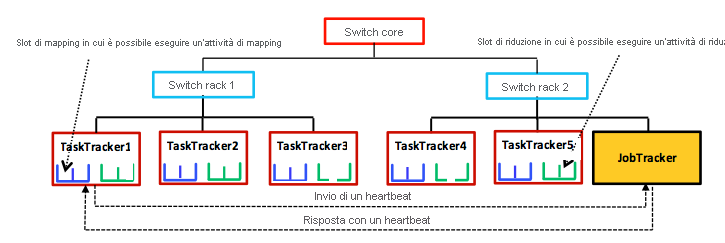
Figura 4: Esempio semplificato dell'architettura primario-subordinato di tipo albero utilizzata da Hadoop MapReduce.
Modello architetturale
Come illustrato dalla figura, MapReduce usa un'architettura primario-subordinato. Il nodo primario si chiama JobTracker (JT) e ogni subordinato si chiama TaskTracker (TT). Il JT e i TT comunicano sulla rete di cluster tramite un meccanismo di heartbeat periodico. Per impostazione predefinita, i TT inviano messaggi (heartbeat) al JT ogni tre secondi e il JT risponde6 con una nuova attività di mapping o di riduzione oppure con un messaggio diverso. Il JT usa questi heartbeat per rilevare errori nelle attività. Per impostazione predefinita, ogni TT ha due slot di mapping e due di riduzione in cui possono essere eseguite le attività corrispondenti. Questa allocazione di slot determina il numero massimo di attività di mapping e di riduzione (grado di parallelismo delle attività) che possono essere eseguite contemporaneamente nel TT.
Hadoop presuppone una topologia di rete gerarchica di tipo albero con switch rack e core, come illustrato nella figura. I TT sono suddivisi tra diversi rack e possono risiedere in uno o più data center. Tra ogni due TT la larghezza di banda di comunicazione dipende dalle loro posizioni relative nella topologia di rete. Ad esempio, i TT nello stesso rack possono interagire molto più velocemente tra loro che non con le controparti in un altro rack. La misurazione della larghezza di banda tra due TT è difficile in pratica,1 quindi in Hadoop si usa un semplice approccio basato sulla distanza. Questo approccio rappresenta le posizioni di rete dei TT come stringhe, ovvero la posizione di TaskTracker5 nella figura è /CoreSwitch/RackSwitch1/TaskTracker5. Hadoop presuppone una distanza unitaria tra qualsiasi TT e lo switch padre, per cui la distanza totale tra due TT può essere calcolata semplicemente sommando le distanze dal loro predecessore comune più vicino. In questo esempio,
Total-Distance(/CoreSwitch/RackSwitch2/TaskTracker1, /CoreSwitch/RackSwitch2/JobTracker) = 4.
6 Il JT non risponde a ogni heartbeat inviato da un TT. I TT possono inviare heartbeat solo per indicare che sono ancora attivi. Se un TT include nell'heartbeat una richiesta, ad esempio di un'attività di mapping o di riduzione, il JT risponde con un heartbeat che la soddisfa.
Riferimenti
- T. White (2011). Hadoop: The Definitive Guide, O'Reilly, seconda edizione
- D. P. Bertsekas and J. N. Tsitsiklis (January 1, 1997). Parallel and Distributed Computation: Numerical Methods Athena Scientific, First Edition