YARN
In questa unità viene esaminato Hadoop 2.0, noto come YARN.
Hadoop è stato sottoposto a una revisione significativa per risolvere diverse carenze tecniche inerenti, tra cui l'affidabilità e la disponibilità di JobTracker (JT) e l'allocazione di risorse statiche (slot di mapping e di riduzione)10 nei TaskTracker (TT). Il framework riprogettato risolve tali problemi nel JT, il nodo primario di Hadoop che è, di conseguenza, un singolo punto di guasto (SPOF). Un altro obiettivo principale della nuova versione di Hadoop è di supportare altri motori di analisi distribuita oltre a MapReduce. Ciò consente un maggior utilizzo dei cluster Hadoop ed elimina la necessità di distribuire un cluster di grandi dimensioni per ogni framework. Per Hadoop, il risultato è una nuova versione denominata Yet Another Resource Negotiator (YARN). Di seguito è riportata un'introduzione di YARN, sottolineando le differenze rispetto alla versione precedente di MapReduce, ossia MapReduce 1.0.
YARN corrisponde alla seconda generazione di Hadoop (versione 2.0 e successive). Il vantaggio principale di YARN rispetto alla precedente generazione di Hadoop è che l'allocazione delle risorse non è più fissa e YARN non è vincolato a nessun singolo framework di programmazione. Di conseguenza, YARN può funzionare da pianificatore indipendente del cluster, in grado di pianificare diversi carichi di lavoro e applicazioni. YARN è un pianificatore a due livelli. La responsabilità del Job Tracker di Hadoop v1 in YARN è separata nell'allocazione delle risorse e nella gestione delle attività, garantendo una facile scalabilità verticale dei cluster YARN.
Architettura e flusso di lavoro
Il cambiamento fondamentale perseguito nella riprogettazione di MapReduce 1.0 è la segregazione delle funzionalità JT in più daemon indipendenti, illustrati nella figura seguente. YARN usa ancora una topologia primario-subordinato, ma con l'aggiunta di questi miglioramenti significativi:
- Per supportare altri motori di analisi distribuita, oltre a MapReduce, il modulo di gestione delle risorse è stato completamente scollegato dal JT e definito come entità separata, Resource Manager (RM). Il componente RM è stato ulteriormente suddiviso in due componenti principali, Scheduler (S) e Applications Manager (ASM).
- Invece di usare un singolo nodo primario, JT, per tutte le applicazioni, YARN ne designa uno per ogni applicazione, detto Application Master (AM). I componenti AM possono essere distribuiti tra i nodi del cluster per evitare casi di SPOF delle applicazioni e potenziali riduzioni del livello delle prestazioni.
- I TT sono rimasti essenzialmente invariati, ma ora si chiamano Node Manager (NM).
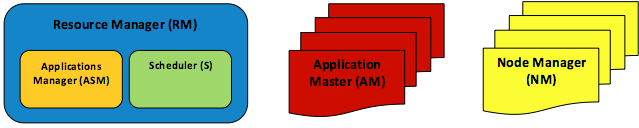
Figura 8: Elementi dell'architettura YARN: un RM, un ASM, uno S, molti AMS e molti NMS
Componenti di YARN
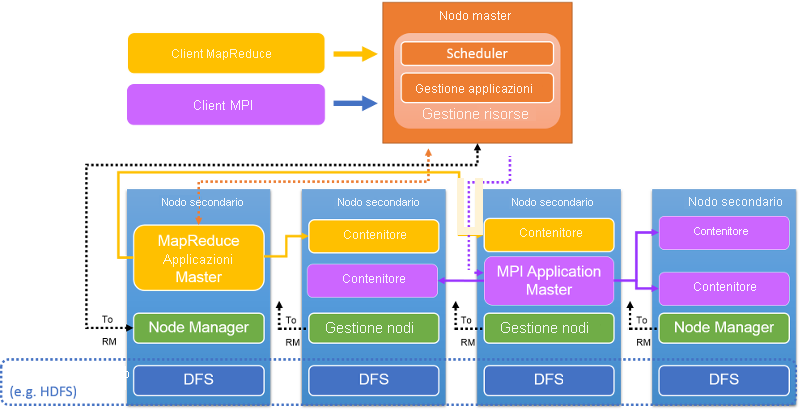
Figura 9: Architettura di un cluster YARN
Un componente Resource Manager per ogni cluster risiede nel nodo primario (figura 9). Il componente RM accetta l'invio di applicazioni/processi da parte di un client, alloca le risorse ai processi, monitora lo stato del cluster e gestisce l'accesso alle risorse. L'RM include due componenti: lo Scheduler, che pianifica il processo, e l'Applications Manager, che crea, gestisce, monitora, riavvia e termina i processi.
L'RM è l'autorità centrale, che arbitra l'allocazione delle risorse tra varie applicazioni e processi in competizione. L'RM alloca dinamicamente le risorse come lease alle applicazioni sotto forma di contenitori. I contenitori sono una rappresentazione logica delle risorse sotto forma di quantità di memoria o di numero di CPU. Attualmente, l'RM gestisce le capacità di memoria e le risorse di CPU, ma non supporta ancora i dischi o le risorse di rete. L'RM interagisce con i Node Manager per assemblare una visione globale del cluster e per applicare le assegnazioni delle risorse. L'RM tiene traccia dell'utilizzo delle risorse e dell'attività dei nodi tramite un meccanismo di heartbeat.
Il componente Scheduler fa parte dell'RM e crea un piano globale per le risorse del cluster, soddisfa le esigenze di risorse applicative e pianifica i processi in base a strategie come la pianificazione Capacity o Fair. L'Applications Manager, un altro componente dell'RM, accetta i processi inviati, negozia con lo Scheduler l'inizializzazione delle risorse (un contenitore) per l'esecuzione dell'Application Master di un processo e fornisce servizi per la tolleranza e il riavvio degli AM in caso di errori.
Il componente AM coordina l'esecuzione dell'applicazione (o del processo) in un cluster YARN. Ogni processo, sia che si tratti di un processo MapReduce, MPI o Spark, ha un AM dedicato nel cluster YARN. L'AM viene eseguito in un contenitore comune come altre attività. L'AM è responsabile del recupero dei contenitori e dell'allocazione delle relative attività. Calcola il set di risorse necessarie in base alle attività da eseguire e invia una richiesta all'RM. Una volta allocate le risorse, l'AM esegue le attività in questi contenitori. Una volta completate le risorse, l'AM le restituisce all'RM. Di seguito questo processo viene illustrato in maggior dettaglio.
Mentre l'AM viene eseguito in un contenitore, invia heartbeat periodici all'RM per aggiornarne l'attività e le richieste di risorse. L'AM calcola le richieste di risorse del proprio processo e invia una richiesta di contenitori insieme alle preferenze e ai vincoli all'interno di questo messaggio periodico di heartbeat inviato all'RM. A sua volta, l'RM risponde dinamicamente all'heartbeat sotto forma di lease di contenitori (forniti come token). L'AM usa i token quando contatta gli NM corrispondenti per avviare le attività del processo. L'AM tiene traccia dello stato delle attività in esecuzione tramite un meccanismo ombelicale. Durante l'esecuzione di un processo, l'RM non riconosce la pianificazione dell'AM. Per un processo MapReduce, l'AM è analogo al JobTracker in Hadoop versione 1.0.
Il Node Manager risiede in ogni nodo; è disponibile un singolo NM per ogni nodo del cluster YARN. Gli NM eseguono l'autenticazione dei lease di contenitori e monitorano l'utilizzo delle risorse. Gli NM contattano l'RM tramite gli heartbeat e terminano i contenitori se indicato dall'RM o dall'AM.
Un contenitore rappresenta un lease per una risorsa allocata nel cluster. Un lease è un bundle logico di risorse associate a un nodo. L'RM è l'unica autorità in grado di allocare qualsiasi contenitore ai processi. Ogni contenitore allocato ha un ContainerID univoco a livello globale. Ogni contenitore ha diversi attributi non statici: CPU, memoria, disco BW, rete BW. I contenitori possono essere confrontati agli slot di MapReduce in Hadoop versione 1.0. Un contenitore viene terminato subito dopo il completamento dell'attività in esecuzione al suo interno. L'RM revoca le risorse e le utilizza in un secondo momento.
Quando si richiedono risorse di calcolo, l'AM presenta allo Scheduler RM una serie di richieste di contenitori. Il protocollo riconosciuto dallo Scheduler è <priority, (host, rack, *), resources, #containers>. Lo Scheduler RM assegna o alloca i contenitori nello stesso formato. Uno snapshot del log RM mostra come l'RM alloca un contenitore (figura 10):

Figura 10: snapshot del log di un'assegnazione del contenitore in YARN. Le informazioni importanti in questa voce sono: 1. ContainerID, 2. Risorse del computer in questo ContainerID 3. ID del nodo in cui risiede il ContainerID e 4. Report delle risorse di questo nodo dopo l'allocazione.
Pianificazione di processi e attività
YARN è un pianificatore a due livelli. L'RM pianifica i processi e l'AM pianifica le relative attività nei contenitori allocati dall'RM. Lo Scheduler, che è responsabile della pianificazione dei processi nell'RM, usa strategie di pianificazione diverse:
- Utilità di pianificazione FIFO: si tratta di un'utilità di pianificazione semplice e di base con una singola coda first-in, first-out e pianifica le richieste del contenitore in base a tale utilità. In genere, un processo può occupare risorse esclusivamente all'interno del cluster durante l'esecuzione. Anche se è possibile offrire risorse di grandi dimensioni a ogni processo, questa opzione genera problemi, ad esempio la rimozione di risorse da altri processi e la mancata condivisione equa delle risorse disponibili. La pianificazione FIFO consente di impostare priorità per i processi. Di conseguenza, il processo con la priorità più alta viene selezionato come il successivo da eseguire. Tuttavia, poiché la pianificazione FIFO non supporta la precedenza, il problema della rimozione di risorse dai processi sussiste. Un processo con priorità alta può essere bloccato da un processo a esecuzione prolungata ma con priorità bassa.
- Utilità di pianificazione della capacità: questa utilità di pianificazione presuppone che i processi Hadoop siano in esecuzione in un cluster condiviso multi-tenant e ottimizzano la velocità effettiva e l'utilizzo del cluster. Il Capacity Scheduler offre garanzie di capacità agli utenti che condividono un cluster di grandi dimensioni. Organizza i processi in code. In genere, le code vengono configurate dagli amministratori in base al modo in cui il cluster YARN verrà partizionato e utilizzato da gruppi di utenti diversi (il gruppo 1, coda 1 ottiene il 50% del cluster). Il Capacity Scheduler offre una serie di limiti per assicurare che un singolo processo o una singola coda non possa consumare una quantità sproporzionata di risorse del cluster.
- Fair Scheduler: questa utilità di pianificazione è incentrata sull'esecuzione di processi YARN diversi in modo equo, fornendo processi con una uguale quota di risorse nel tempo. Per impostazione predefinita, una decisione di pianificazione effettuata dal Fair Scheduler si basa solo sulla memoria. Tuttavia, il Fair Scheduler è configurabile e può pianificare sia con la memoria che con la CPU. Il Fair Scheduler assicura il completamento di alcuni processi brevi in una quantità ragionevole di tempo senza distogliere risorse dai processi lunghi o di grandi dimensioni. Rappresenta anche una scelta valida nel caso in cui più utenti condividano lo stesso cluster. Oltre ad allocare equamente le risorse, il Fair Scheduler può pianificare i processi con priorità diverse. Le priorità, impostate dagli utenti, possono essere usate per determinare il numero di risorse da assegnare a ogni processo.
- Utilità di pianificazione: gli utenti possono collegare un'utilità di pianificazione dei processi personalizzata.
Le strategie di pianificazione possono essere configurate nel file yarn-site.xml. Sono inoltre disponibili molte proprietà che è possibile impostare in yarn-site.xml per ottimizzare i parametri operativi dei pianificatori menzionati sopra.
Dopo l'allocazione di risorse (contenitori) a un processo, l'AM è responsabile di pianificare le relative attività in questi contenitori. L'AM pianifica le attività allo stesso modo del JobTracker in Hadoop versione 1.0. Inoltre, l'AM si assume la responsabilità di monitorare lo stato delle attività, operazione eseguita dal TaskTracker in Hadoop versione 1.0.
Tolleranza di errore in YARN
Il Resource Manager è un singolo punto di guasto per un cluster YARN. Il RM aggiunge periodicamente checkpoint del proprio stato all'archiviazione permanente. Se si verifica un errore dell'RM, è possibile riavviarlo da uno dei checkpoint. Tutti gli AM in esecuzione vengono quindi terminati e riavviati, quindi è possibile pianificare ed eseguire le attività in sospeso dallo stato del checkpoint.
Per qualsiasi AM possono verificarsi errori. L'RM noterà che l'AM non riesce a inviare un heartbeat e lo riavvierà. Tuttavia, l'AM deve essere risincronizzato con tutti i contenitori in esecuzione per assicurare il corretto completamento dei processi.
Anche gli errori dell'NM possono essere rilevati dall'RM. In caso di errore dell'NM, tutti i contenitori di questo nodo verranno terminati e l'errore verrà segnalato a tutti gli AM in esecuzione. Gli AM sono responsabili dell'acquisizione di nuove risorse sotto forma di contenitori dall'RM per eseguire le attività terminate. Nel nodo in errore del cluster non verranno assegnati altri contenitori finché il problema non verrà ripristinato e segnalato all'RM.
Flusso dei processi MapReduce in YARN
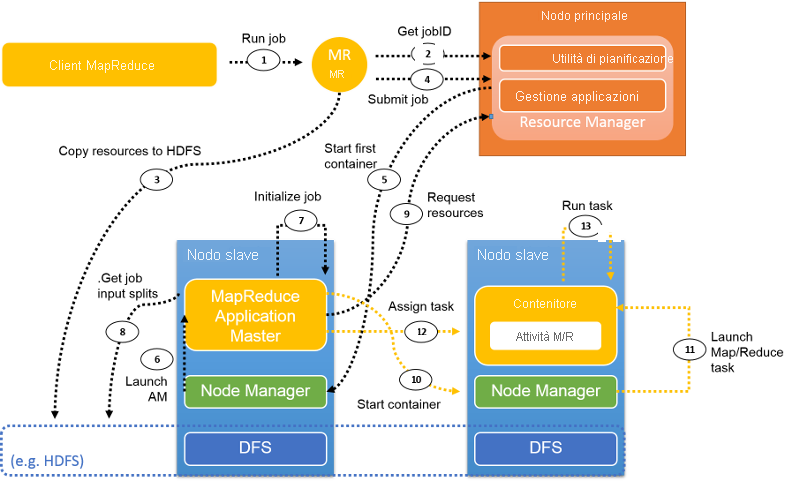
Figura 11: Flusso del processo in YARN che esegue un processo MapReduce
Questa figura illustra un tipico flusso di processi MapReduce in YARN. Le sezioni seguenti descrivono i passaggi del flusso.
Invio di processi
Passaggio 1: Il client MapReduce usa la stessa API di Hadoop versione 1.0 per inviare un processo a YARN. Quando mapreduce.framework.name è impostato su yarn nella configurazione del processo, viene attivato l'oggetto ClientProtocol di YARN. Un processo viene anche definito applicazione in YARN.
Passaggio 2. A differenza di Hadoop versione 1.0, in cui il JobTracker gestisce tutti i processi nel cluster, in YARN l'ID del nuovo processo viene recuperato dall'RM. Tuttavia, a volte un jobID in YARN viene anche chiamato applicationID.
Passaggio 3. Le risorse necessarie per il processo, ad esempio il file JAR, i file di configurazione e le informazioni sulle divisioni logiche, vengono copiate in un file system condiviso in preparazione per l'esecuzione del processo.
Passaggio 4. Il client del processo chiama submitApplication() nell'RM per l'invio del processo.
Inizializzazione dei processi
Passaggio 5. L'RM passa la richiesta del processo allo Scheduler dopo aver ricevuto la chiamata submitApplication (). Lo Scheduler alloca le risorse per l'esecuzione di un contenitore in cui risiederà l'Application Master. Quindi l'RM invia il lease di risorse ad alcuni Node Manager.
Passaggio 6. L'NE riceve un messaggio dall'RM e avvia un contenitore per l'AM.
Passaggio 7. L'AM si assume la responsabilità di inizializzare il processo. Per monitorare il processo vengono creati diversi oggetti bookkeeping. In seguito, durante l'esecuzione del processo, l'AM continuerà a ricevere gli aggiornamenti con lo stato di avanzamento delle attività.
Passaggio 8. L'AM interagisce con il file system condiviso (ad esempio, HDFS) per ottenere le divisioni logiche di input e altre informazioni, copiate nel file system condiviso nel passaggio 3.
Assegnazione attività
Passaggio 9. L'AM calcola il numero di attività di mapping, determinato dal numero di divisioni logiche di input (in modo simile a Hadoop versione 1.0). Il numero di attività di riduzione è un parametro configurabile impostato nel file di configurazione. L'AM richiede risorse per tutte le attività di mapping e di riduzione all'RM sotto forma di richiesta di contenitori. Una richiesta include le preferenze in termini di località dei dati (per le attività di mapping), la quantità di memoria e il numero di CPU in ogni contenitore.
ResourceRequest: <Priority: 20,
Resource: <vCores: 1, memory: 1024>,
Num Containers: 2,
Desired Host: 192.1.1.1,
Relax Locality: true>
Nell'esempio precedente priority definisce la priorità del contenitore, che può essere configurata in base al tipo di attività (ad esempio, mapping o riduzione). Le risorse necessarie per questa attività sono indicate come sottorecord denominato Resource. Qui il numero di vCores (CPU) è stato indicato come 1, mentre memory è un parametro intero definito in MB. Num containers indica il numero di contenitori di questo tipo richiesti da YARN. Desired host indica il requisito di località della richiesta. Relax locality indica se il requisito di località definito è rigoroso o se per questa attività è accettabile anche qualsiasi altra allocazione.
Fase 10 e fase 11. Dopo che l'RM risponde con i lease di contenitori, l'AM comunica con gli NM, i quali avviano i contenitori.
Passaggio 12. L'AP assegna un'attività a questo contenitore in base alla conoscenza della località. L'attività verrà eseguita da un'applicazione Java la cui classe principale è YarnChild.
Report stato
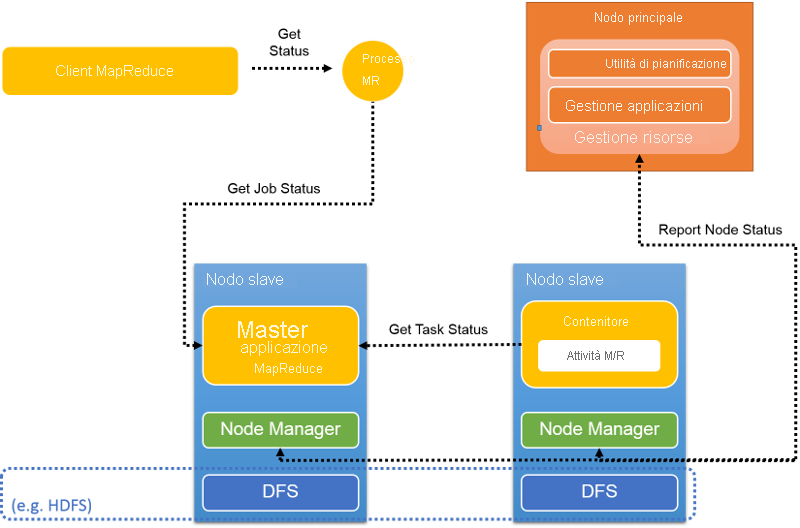
Figura 12: Report di heartbeat e stato in YARN
Durante l'esecuzione del processo, le attività continuano a segnalare il proprio avanzamento e lo stato dell'AM corrispondente. In questo modo l'AM avrà una visione aggregata del processo (figura 12). I Node Manager segnalano l'attività e l'utilizzo delle risorse all'RM, che ha una visione globale del cluster.
Completamento dei processi
Ogni cinque secondi, il client del processo controlla il relativo stato per verificare se è stato completato. La funzione chiamata è waitForCompletion(). Al termine del processo, viene chiamato il metodo di pulizia. Tutti i contenitori e lo stato di lavoro dell'AM verranno puliti. Il server di cronologia dei processi tiene traccia delle informazioni relative a questo processo.
Esempio: WordCount
Ecco un esempio di esecuzione di WordCount in un cluster YARN costituito da 1 nodo primario e 4 nodi subordinati. Viene usata l'istanza m1.large (2 vCPU, 6,5 ECU, 7,5 GB di memoria) offerta da Amazon Web Services (AWS). I dati di input vengono partizionati come 39 file di testo normale nel file system distribuito, ovvero 2,32 GB in totale. Il numero di attività di mapping viene impostato su 39 e il numero di attività di riduzione viene configurato su 7 nel file di configurazione del processo.
Gli snapshot seguenti illustrano il processo di esecuzione di questo processo in YARN:
Il client avvia l'esecuzione del processo WordCount.
L'RM assegna
jobIDper questo processo WordCount.Le informazioni per questo processo WordCount vengono salvate o copiate in HDFS.
Il processo WordCount viene inviato all'RM (figura 13).
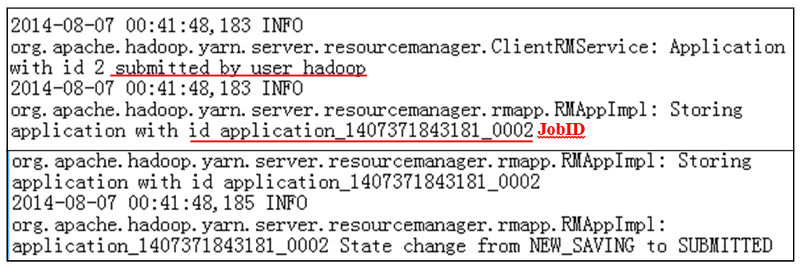
Figura 13: Log di invio del processo
L'RM comunica con l'NM per allocare un contenitore per l'AM.
L'NM autentica il lease di contenitori dall'RM.
L'RM riesce a avviare l'AM per il processo WordCount (figura 14).
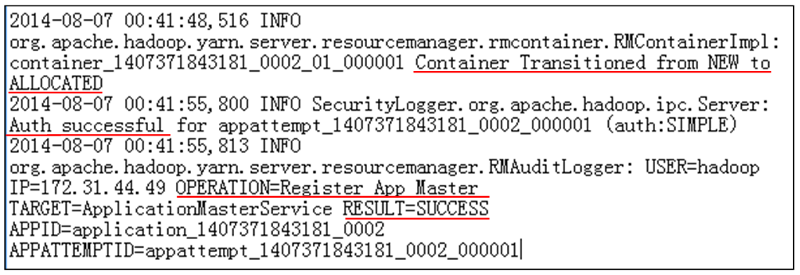
Figura 14: Log allocazione processi
L'AM inizia a essere in esecuzione e calcola le risorse necessarie per completare il processo WordCount: 39 attività di mapping e 7 attività di riduzione.
L'RM riceve le richieste dall'AM e alloca le risorse sotto forma di contenitori.
L'AM invia il lease agli NM viene avviata l'esecuzione di un gruppo di contenitori.
L'AM avvia i tentativi di attività di mapping, pronte per l'esecuzione nei contenitori. In questo caso, l'AM avvia prima di tutto 12 tentativi di attività di mapping, perché le risorse disponibili non sono sufficienti per un altro contenitore nel cluster a 4 noti.
L'AM assegna quindi i contenitori ai tentativi di attività di mapping in base alla conoscenza della località dei dati (figura 15).

Figura 15: Log di assegnazione processi
Viene avviata l'esecuzione delle attività di mapping. L'AM tiene traccia dello stato di ogni tentativo di attività tramite un meccanismo di heartbeat.
A un certo punto, l'esecuzione di un'attività di mapping termina in un contenitore e l'AM viene informato.
Questo contenitore viene quindi pulito dall'AM. Le risorse di calcolo vengono recuperate e l'NM avvia un nuovo contenitore con lo stesso processo descritto sopra. L'AM assegnerà ora un nuovo tentativo di attività di mapping o di riduzione al nuovo contenitore. È possibile eseguire una sola attività in un contenitore.
A causa dello shuffling anticipato, quando vengono completate diverse attività di mapping (almeno il 5% per impostazione predefinita), l'AM assegnerà un tentativo di attività di riduzione a un contenitore disponibile. Una fase di riduzione è costituita dallo shuffling, dall'unione e ordinamento e dall'esecuzione della funzione di riduzione. Un'attività di riduzione può terminare solo dopo che i relativi byte di output vengono scritti in HDFS.
L'AM gestisce tutte le attività di mapping e di riduzione e ne attende il completamento. Al termine dell'ultima attività di riduzione, l'intero processo verrà contrassegnato come completato.
L'AM comunica con gli NM per pulire tutti i contenitori rimanenti.
L'AM invierà una notifica all'RM per indicare il processo è stato completato.
L'RM pulisce l'AM. L'intero processo WordCount termina (figura 16).

Figura 16: Log pulizia processi
Sequenza temporale delle attività per l'esempio di processo WordCount
Poco dopo l'avvio del processo, viene avviata l'esecuzione di 12 attività di mapping (barre blu) (figura 17). Non è possibile eseguire altre attività di mapping perché nel cluster non sono disponibili altre risorse (contenitori) per avviarle. Nel primo ciclo vengono eseguite 12 attività di mapping in parallelo. Dopo un periodo di tempo, alcune attività di mapping terminano. A causa del meccanismo di shuffling anticipato, quando alcune attività di mapping terminano (5% per impostazione predefinita), vengono pianificate le attività di riduzione e ne viene avviato lo shuffling. In questo esempio sono disponibili risorse sufficienti per l'avvio di 4 attività di riduzione. Ogni attività di riduzione include 3 sottofasi sequenziali: shuffling (in rosso), unione e ordinamento (in giallo) e funzione di riduzione (in rosa). Mentre le 4 attività di riduzione eseguono uno shuffling anticipato, viene avviata l'esecuzione del secondo ciclo di attività di mapping. Una volta completata l'ultima attività di mapping, termina l'intera fase di mapping. È quindi possibile eseguire le attività di unione e ordinamento e le funzioni di riduzione. In seguito, i contenitori disponibili sono sufficienti per eseguire altre 3 attività di riduzione. Il processo termina subito dopo l'ultima attività di riduzione.
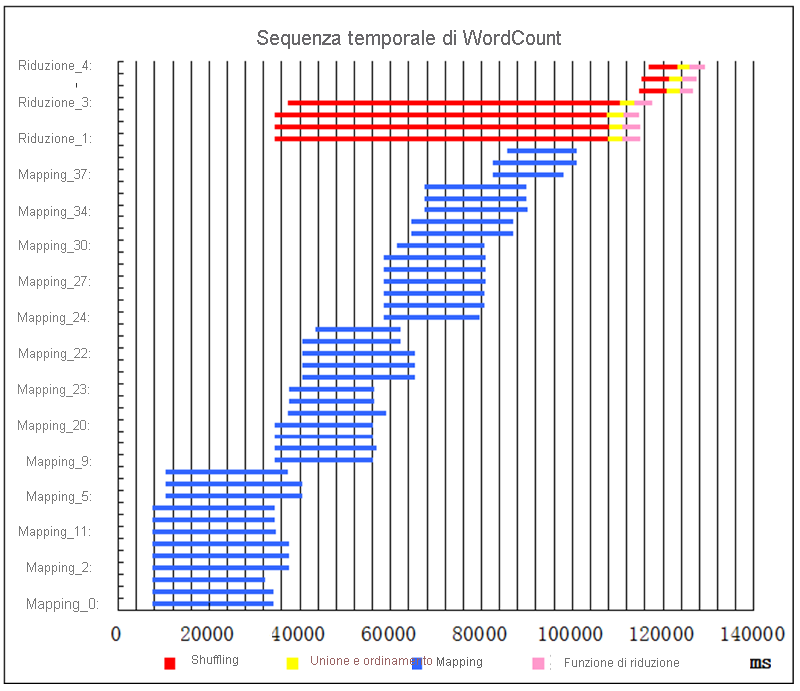
Figura 17: Sequenza temporale di esecuzione del processo per WordCount
10 Il numero di slot di mapping e il numero di slot di riduzione sono parametri configurabili, che gli utenti possono impostare prima di inviare processi a Hadoop MapReduce.