Panoramica dei dati
I dati sono semplicemente una raccolta di cifre e fatti non elaborati. Le applicazioni sono responsabili della generazione, dell'archiviazione, dell'analisi e dell'utilizzo dei dati o di una combinazione di tali attività.
La natura e le proprietà dei dati influiscono in genere sulla progettazione e sull'implementazione dei sistemi di archiviazione. Alcune proprietà includono volume, contenuto e frequenza di accesso ai dati. Ad esempio, Facebook2 ha di recente studiato i modelli di accesso alle immagini e ai contenuti video pubblicati dagli utenti scoprendo che la frequenza di accesso diminuisce in modo esponenziale con il passare del tempo. Facebook ha usato questi risultati per progettare e implementare un sistema di archiviazione specifico per le proprie esigenze. Nel video seguente vengono esaminate le varie proprietà dei dati che influiscono sulla progettazione dei sistemi di archiviazione.
Struttura dei dati
I dati possono essere classificati in base a dinamicità e struttura. In particolare, i dati possono essere segmentati a livello generale nei quattro quadranti illustrati nella figura seguente. Una categorizzazione rappresenta la struttura dei dati, che possono essere strutturati o non strutturati.

Figura 1: Segmentare i dati in vari tipi3
I dati strutturati hanno un modello di dati predefinito che ne consente l'organizzazione in una forma relativamente semplice da elaborare, archiviare, recuperare e gestire. I dati strutturati sono in genere piccoli dati che si adattano naturalmente al formato tabulare e possono quindi essere archiviati facilmente nei database tradizionali (ad esempio, i database relazionali). Un esempio di dati strutturati è costituito dalle informazioni sul contatto dei clienti archiviate in tabelle in un database CRM (Customer Relationship Management). Questi dati sono conformi a un modello piuttosto rigido (detto schema nei database relazionali), che consente archiviazione, accesso e modifica rapidi.
I dati non strutturati, d'altra parte, possono non avere necessariamente un modello organizzativo rigido predefinito. I dati non strutturati possono avere dimensioni più grandi e non si adattano naturalmente al formato tabulare, quindi non sono idonei per l'archiviazione in un database relazionale. Per questo motivo, i dati non strutturati possono essere relativamente difficili da organizzare in una forma semplice da elaborare, archiviare, recuperare e gestire. Esempi di dati non strutturati sono file binari flat contenenti informazioni di testo, audio o video. È importante notare che i dati non strutturati non sono necessariamente privi di struttura. Un documento, un video o un file audio può includere una struttura di codifica file o metadati associati. Di conseguenza, i dati con un tipo di struttura possono comunque essere caratterizzati come non strutturati se la relativa struttura non è utile per l'attività di elaborazione per cui sono necessari i dati. Ad esempio, una cache di grandi dimensioni di documenti di testo (non strutturati) è difficile da indicizzare e usare per le ricerche rispetto a un database relazionale che contiene informazioni sui clienti (strutturate). Ai fini di questo corso, i dati non strutturati possono essere definiti come dati che non si adattano naturalmente a un database relazionale. Alcuni dati possono inoltre essere considerati come non strutturati (non archiviati in un database) perché l'accesso avverrà tramite modelli di accesso imprevedibili e per tali dati le ottimizzazioni di database tradizionali sono inutili.
C'è un tipo di dati che si trova in posizione intermedia tra i dati strutturati e quelli non strutturati: i dati semistrutturati. I dati semistrutturati non sono conformi alla struttura formale dei modelli di dati associati a database relazionali o ad altre forme di tabelle dati, ma contengono tuttavia tag o altri marcatori per separare gli elementi semantici e applicare gerarchie di record e campi all'interno dei dati. Un esempio di dati semistrutturati sono i dati descritti tramite linguaggi di markup, come pagine Web, dati clickstream e oggetti Web. XML e JSON sono esempi tipici di rappresentazioni di dati semistrutturati, in quanto usano tag inline che descrivono anche i dati.
Dinamicità dei dati
Un'altra caratteristica è la dinamicità dei dati, che si riferisce alla frequenza con cui i dati cambiano. I dati dinamici, ad esempio i documenti di Microsoft Office e le voci transazionali in un database finanziario, cambiano relativamente spesso, mentre i dati fissi una volta creati non vengono modificati. Esempi di dati fissi includono i dati di diagnostica per immagini di risonanze magnetiche e TAC e i filmati video trasmessi archiviati in un catalogo video.
La segmentazione dei dati in uno di questi quadranti è utile per progettare e sviluppare una soluzione di archiviazione per i dati. I dati strutturati vengono in genere elaborati usando database relazionali in cui è possibile accedere ai dati nonché gestirli e modificarli usando comandi precisi, solitamente eseguiti in un linguaggio di query come SQL. I dati non strutturati possono essere archiviati in file flat in un file system o possono essere organizzati ulteriormente usando un database NoSQL (altre informazioni su NoSQL verranno fornite più avanti nel modulo).
La struttura e la dinamicità dei dati forniscono indicazioni su come è possibile progettare un sistema di archiviazione. Grandi quantità di dati relativamente statici possono essere archiviate in array di dischi, se i dati vengono letti di frequente. I sistemi di archiviazione progettati con architettura di memorizzazione nella cache a più livelli migliorano le prestazioni delle operazioni di lettura su tali dati.
Alcuni tipi di file system, ad esempio le versioni precedenti di HDFS (Hadoop Distributed File System), sono progettati per i dati relativamente statici. Consentono la scrittura di un file una sola volta e il file non può essere modificato dopo la scrittura. I dati statici, ad esempio immagini di unità e snapshot per i backup, possono essere archiviati in sistemi di archiviazione offline relativamente poco costosi, se non è necessario accedervi di frequente.
In sintesi, è necessario considerare la natura dei dati usati da un'applicazione per scegliere l'architettura di archiviazione appropriata.
Granularità e volume dei dati
Oltre al tipo di dati, è necessario prendere in considerazione il volume dei dati da archiviare ed elaborare per una particolare applicazione. Il volume dei dati è caratterizzato da due dimensioni, ovvero dalla dimensione complessiva dei dati (volume totale) rispetto alle dimensione di un segmento utile di dati (granularità dei dati). Si consideri ad esempio il caso di un sito Web di condivisione di fotografie con milioni di utenti che pubblicano decine o centinaia di fotografie. La dimensione totale dei dati può essere di decine o centinaia di terabyte o anche petabyte, ma la fotografia media può essere di pochi megabyte. In un sito Web come YouTube, invece, la dimensione totale di tutti i video nel sito è di molti petabyte e le dimensioni di un video possono variare da poche centinaia di megabyte a valori anche di gigabyte.
A questo proposito, c'è un termine che viene spesso usato per descrivere grandi volumi di dati: Big Data. Ci sono molte definizioni di Big Data, ma in linea generale si tratta di dati troppo grandi per essere gestiti con tecniche convenzionali.
Le tecnologie dell'informazione e della comunicazione (ICT, Information and Communications Technology) in rapida espansione e che permeano tutti gli aspetti della vita moderna hanno portato a un enorme aumento delle quantità di dati negli ultimi decenni. Gli importanti progressi nella connettività e nella digitalizzazione delle informazioni hanno comportato l'aumento delle quantità di dati creati ogni giorno. Questi dati sono di vario tipo, da immagini e video di telefoni cellulari che vengono caricati nei siti Web, ad esempio Facebook e YouTube, a trasmissioni TV digitali 24 ore su 24, 7 giorni su 7, fino ai video di sorveglianza di centinaia di migliaia di telecamere di sicurezza e agli esperimenti scientifici su larga scala, come quelli dell'acceleratore di particelle Large Hadron Collider, che producono molti terabyte di dati ogni giorno. L'ultimo studio di IDC (International Data Corporation) della serie Digital Universe prevede un aumento della quantità dei dati creati globalmente di 300 volte, da 130 exabyte (1028) nel 2012 a 30.000 exabyte nel 2020.
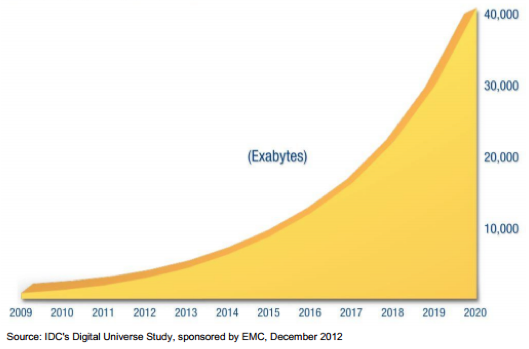
Figura 2: Crescita stimata dei dati dal 2009 al 20201
Le organizzazioni stanno cercando di sfruttare o di far fronte alle enormi quantità di dati che crescono a ritmi sempre maggiori. Microsoft, Google, Yahoo e Facebook sono passati dall'elaborare gigabyte e terabyte di dati a volumi nell'ordine di petabyte, con una conseguente forte pressione sulle infrastrutture di elaborazione che devono essere disponibili 24 ore su 24, 7 giorni su 7 e che devono poter essere ridimensionate facilmente, in quanto la quantità di dati generati aumenta in modo esponenziale. Queste sono le sfide a cui devono rispondere le tecnologie di archiviazione presenti e future.
Riferimenti
- John Gantz e David Reinsel (2012). White paper IDC, The Digital Universe in 2020
- Subramanian Muralidhar, Wyatt Lloyd, Sabyasachi Roy, Cory Hill, Ernest Lin, Weiwen Liu, Satadru Pan, Shiva Shankar, Viswanath Sivakumar, Linpeng Tang e Sanjeev Kumar (2014). f4: Facebook's Warm BLOB Storage System Undicesimo simposio USENIX su progettazione e implementazione dei sistemi operativi (OSDI 14) 383-398 USENIX Association
- Thomas Rivera (2012). Esercitazione, The Evolution of File Systems SNIA