File system locali
In un file system locale, il file system è collocato nella stessa posizione del server che esegue l'applicazione. A causa della natura del file system, i file system locali hanno scalabilità limitata e non consentono la condivisione dei dati tra client diversi in una rete:
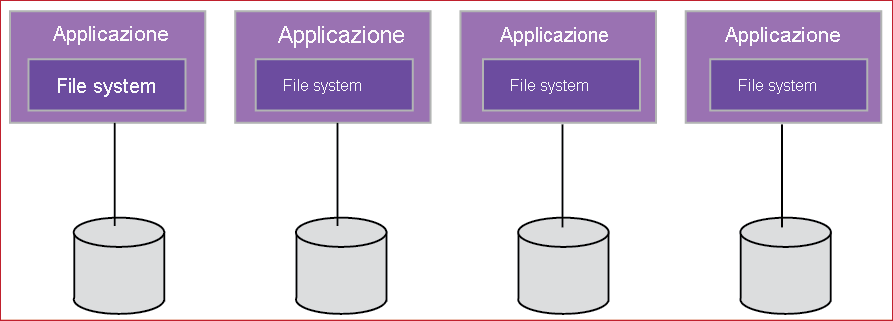
Figura 8: File systemlocali 1
I dati archiviati in un disco sono in genere rappresentati come blocchi o una raccolta di byte contigua non strutturata. I file system locali forniscono un'astrazione dei file, che sono semplicemente una raccolta di blocchi che rappresentano un file.
Le applicazioni che usano i file system locali non sono interessate al modo in cui i file sono rappresentati fisicamente nei supporti di archiviazione, alla quantità di dati trasferiti da o verso l'applicazione per ogni richiesta di file (detta dimensione del record), all'unità in base a cui i dati vengono trasferiti da e verso i supporti di archiviazione (detta dimensione del blocco) e così via. Tutti questi dettagli di basso livello vengono gestiti dai file system locali e vengono astratti in modo efficace dalle applicazioni utente. In linea di principio, i file system locali sono il sottostrato di base di ogni tipo di file system nel cloud. Ad esempio, i file system distribuiti (come Hadoop Distributed File System, che simula Google File System)2 e i file system paralleli (come PVFS) vengono creati ed eseguiti su più file system locali cooperativi. Inoltre, la capacità di una macchina virtuale o un computer fisico di rimanere indenne in caso di arresti anomali di software e hardware nel cloud e in altri sistemi dipende in parte dal modo in cui i file system locali sono progettati per gestire tali arresti anomali. In breve, praticamente ogni file system, sia condiviso che di rete, si basa sui file system locali.

Figura 9: Layout di un file system
Il file system UNIX è un file system locale classico progettato negli anni '70 e da allora ampiamente usato in molte forme (FFS, EXT-2 e così via). Sebbene i dati all'interno di un file vengano distribuiti come una serie di blocchi in un dispositivo di archiviazione, il file system mantiene l'astrazione del file insieme ai dati associati. Come illustrato nella figura precedente, un file system locale di base include un blocco di avvio, un superblocco, una lista degli inode (I-list) e un'area dati. Il blocco di avvio contiene il programma di avvio che legge l'immagine binaria del sistema operativo (OS) nella memoria all'avvio del sistema operativo. In sostanza, il blocco di avvio non ha nulla a che fare con i processi e le funzionalità di gestione del file system. Il superblocco descrive il layout e le caratteristiche del file system locale, tra cui la dimensione del file system, la dimensione dei blocchi, il numero di blocchi, la dimensione e la posizione della lista degli inode e così via.
Nella lista degli inode, lo stato di ogni file è incapsulato come inode (nodo di indice, come illustrato nella figura seguente) UNIX. L'inode funge da struttura dei dati primaria di un file e archivia i metadati relativi a un file, inclusi i puntatori ai singoli blocchi di file nell'archiviazione, la proprietà e gli elenchi di controllo di accesso, il timestamp dell'ultimo accesso del file e così via.
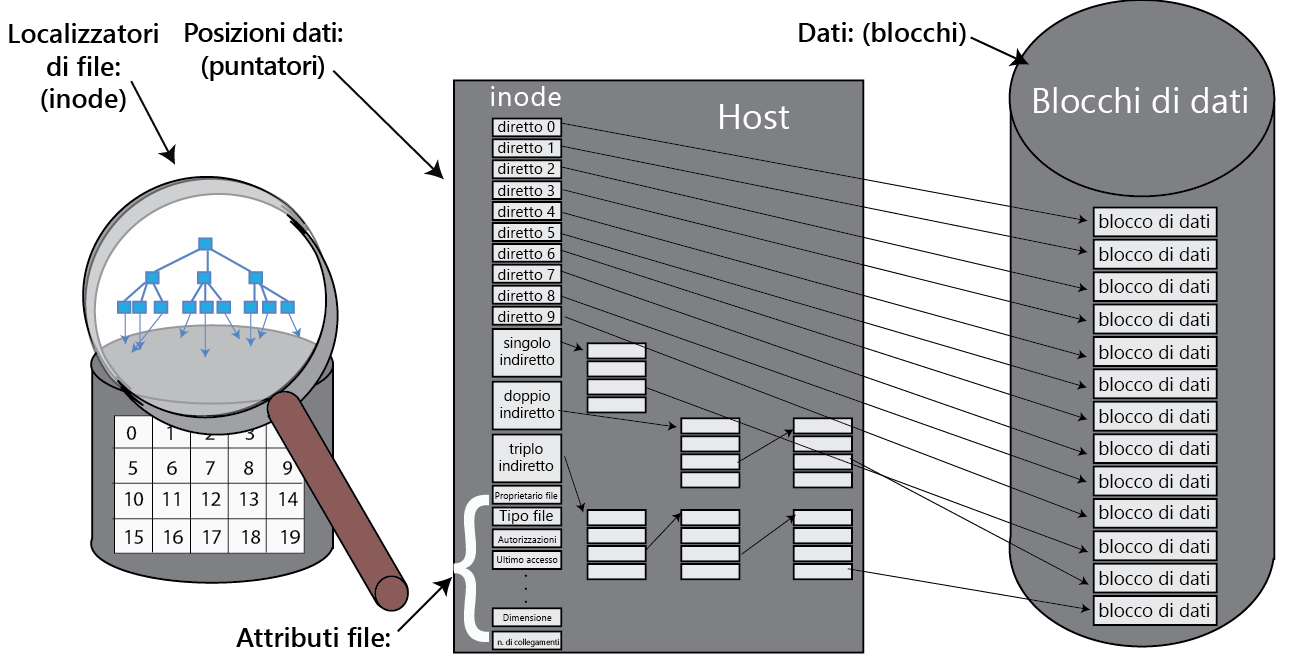
Figura 10: File, inodes e blocchi1
Tra i file system locali ci sono NTFS, FAT ed EXT. È possibile superare i limiti di scalabilità, prestazioni e condivisione dei file system locali usando file system condivisi/di rete.
Standard di I/O POSIX
POSIX (Portable Operating System Interface) è una famiglia di standard che definisce le interfacce del sistema operativo per molti sistemi operativi UNIX e analoghi. Gli standard dei file system POSIX vengono spesso usati per descrivere le funzionalità previste da un file system che è possibile usare in sistemi operativi UNIX e analoghi.
POSIX definisce le operazioni standard seguenti sui file: open, read, write e close. Gli standard POSIX consentono inoltre di montare tali file system direttamente in un sistema operativo UNIX o analogo senza necessità di un processo driver/client con finalità speciali per gestire il file system.
File system a livello di kernel e a livello di utente
I file system a livello di kernel sono file system che contengono un'API a livello di kernel, che significa anche che il codice che interagisce con il file system risiede nel kernel. Nei sistemi operativi UNIX e analoghi, queste API vengono caricate come moduli. I file system a livello di kernel nei sistemi operativi analoghi a UNIX sono in genere conformi a POSIX e limitati ai file system locali.
I file system a livello di utente funzionano nello spazio dell'utente anziché nello spazio del kernel. Le interfacce di tali file system consentono la portabilità di un'API del file system e la sua installazione in un set di client molto più ampio. Molti file system distribuiti e di rete sono progettati per funzionare a livello di utente, con un'eccezione rappresentata da AFS, che usa un driver a livello di kernel in Linux.
Considerazioni sulla progettazione nei file system locali
Per comprendere il modo in cui vengono progettati i file system locali, è importante comprendere il supporto di archiviazione sottostante. In questa discussione si presuppone un disco rotante come supporto di archiviazione.
I file system locali sono progettati per ridurre al minimo i tempi di posizionamento e rotazione dopo l'allocazione della capacità del disco per i file, per migliorare le prestazioni del sistema. I file system locali sono anche in grado di ottimizzare la quantità di dati utili trasferiti dopo i tempi di posizionamento e rotazione. Le prestazioni sono un importante criterio per la progettazione di un file system locale efficace. I supporti di archiviazione, ad esempio dischi e nastri magnetici, non forniscono tempi di accesso uniformi come le risorse di archiviazione primarie (ad esempio, memoria o cache). Di conseguenza, un file system locale deve sfruttare al meglio il supporto di archiviazione sottostante al fine di ottenere prestazioni di sistema accettabili ed evitare inutili sprechi di spazio. Evitare inutili sprechi di spazio è fondamentale, soprattutto nel cloud dove l'utilizzo delle risorse di sistema è di grande importanza.
Prestazioni
Per migliorare le prestazioni, i file system locali possono usare diverse strategie. In primo luogo, i file system locali possono conservare diversi indirizzi di blocchi nell'inode di un file (in particolare, nella relativa mappa del disco). I file system locali possono memorizzare nella cache gli inode per ridurre il numero di accessi al disco necessari per la lettura e la scrittura dei percorsi dei blocchi. In secondo luogo, per ottimizzare la quantità di dati utili trasferiti, i file system locali possono ingrandire le dimensioni dei blocchi. Come terzo aspetto, è possibile sfruttare la località per limitare al minimo il tempo di posizionamento. In particolare, i blocchi a cui è più probabile che si effettuerà l'accesso nell'imminente futuro possono essere mantenuti vicini tra loro sul disco, ovvero i blocchi di ogni file devono essere archiviati il più vicino possibile. Inoltre, poiché l'accesso agli inode avviene insieme a quello ai relativi blocchi di dati, questi due elementi devono essere archiviati vicini tra loro. E poiché gli inode di una directory vengono spesso esaminati tutti contemporaneamente (ad esempio, ls –la), gli inode dei file in una singola directory devono essere mantenuti vicini tra loro. Un quarto punto è che, per ridurre la latenza dovuta alla rotazione, i blocchi di un file in un cilindro (se presenti) devono essere organizzati in modo che, dopo il tempo di posizionamento, possano essere letti senza ulteriori ritardi dovuti alla rotazione. Questa disposizione migliora le prestazioni, soprattutto se i blocchi vengono richiesti in modo sequenziale. Se, tuttavia, i blocchi vengono richiesti in modo casuale, diventa difficile sfruttare tale disposizione dei blocchi in un cilindro per ridurre al minimo la latenza dovuta alla rotazione. Infine, quando un file system locale recupera un blocco richiesto, può contemporaneamente eseguire la pre-lettura dei blocchi a cui è probabile che verrà eseguito l'accesso nell'imminente futuro. In realtà, molti file system locali (ad esempio, Ext2 e versioni successive) usano una strategia di blocchi multipli contemporanei, detta clustering a blocchi, in cui vengono allocati otto blocchi contigui alla volta. I blocchi possono anche essere memorizzati nel buffer o nella cache per consentire al sistema operativo di farvi riferimento in futuro.
Sebbene i file system siano stati tradizionalmente creati per ottimizzare le prestazioni sui dischi rigidi magnetici, molti file system attuali prevedono modalità operative per le unità SSD, che sostituiscono alcune ottimizzazioni destinate ai dischi e introducono nuove funzionalità per migliorare le prestazioni e la gestione dell'usura sulle unità SSD.
Affidabilità
Un altro importante criterio per la progettazione di file system locali efficaci è l'affidabilità. L'affidabilità è importante anche per l'archiviazione nel cloud. I file system locali devono essere affidabili, ovvero i dati archiviati devono essere accessibili ogni volta che è necessario. Di conseguenza, i dati devono tollerare in modo efficace gli arresti anomali di hardware e software. I file system locali devono inoltre garantire che i dati archiviati siano sempre coerenti. La scrittura, la creazione, l'eliminazione e la ridenominazione di un file possono richiedere una serie di operazioni su disco che interessano sia i dati che i metadati. Per assicurarsi che il file system locale sottostante sia a tolleranza di arresto anomalo, è necessario garantire che ognuna di queste operazioni porti il sistema da uno stato coerente a un altro. Se ad esempio si trasferisce un file da una directory a un'altra, con la conseguente esecuzione di operazioni di creazione ed eliminazione, lo stato del file system può diventare incoerente. In particolare, è possibile che si verifichi un arresto anomalo durante lo spostamento del file, causando la scomparsa del file nelle due directory, quella originale e quella prevista. Per evitare questo rischio, il file system locale può prima di tutto creare il file nella directory prevista e successivamente rimuoverlo da quella originale (dopo il commit del file nella nuova directory).
Operazioni sul file system in più passaggi
Alcune operazioni sui file possono richiedere più passaggi di lettura o scrittura e in questo caso si parla di operazioni sul file system in più passaggi. La scrittura di una grande quantità di dati in un file può ad esempio comportare diverse operazioni su disco separate (come avviene comunemente nei cloud). Se si verifica un arresto anomalo prima della scrittura di tutti i dati richiesti, il file system locale avrà uno stato finale in cui solo una parte dell'operazione di scrittura è stata completata. Un approccio comune per gestire le operazioni in più passaggi consiste nell'usare le transazioni atomiche. Con le transazioni atomiche, se il sistema si arresta in modo anomalo durante qualsiasi passaggio di un'operazione in più passaggi (probabilmente dopo alcune operazioni di ripristino) è come se l'intera operazione fosse stata eseguita completamente o non fosse stata eseguita del tutto. Le transazioni sono un concetto standard nei sistemi di database e verranno descritte in modo dettagliato nella sezione relativa ai database.
Uno schema di base per l'implementazione delle transazioni atomiche nei file system locali è detto inserimento nel journal. Con l'inserimento nel journal, i passaggi di una transazione vengono prima di tutto scritti sul disco in un file journal speciale. Una volta che i passaggi sono stati registrati in modo sicuro ed è stato eseguito il commit dell'operazione (ovvero, l'operazione è stata completata del tutto), è possibile applicare i passaggi al file system effettivo. Se si verifica un arresto anomalo durante l'applicazione dei passaggi al file system, è possibile recuperare facilmente i passaggi dal file journal (presupponendo che sia costantemente protetto dagli errori). Questa tecnica è nota come fase di rollforward o inserimento nel journal di un nuovo valore. Anche se si verifica un arresto anomalo del sistema durante l'applicazione dei passaggi al file journal, i passaggi già registrati nel file journal possono essere eliminati e il file system effettivo rimarrà intatto. L'approccio tramite inserimento nel journal garantisce che l'intera operazione venga eseguita completamente o non venga eseguita del tutto.
Espandere un singolo file system su più dischi
Per migliorare l'affidabilità e/o le prestazioni, è possibile usare un file system locale con più unità disco. Questo video illustra le varie tecniche usate per espandere un file system su più dischi:
I tre motivi principali per espandere le unità disco sono i seguenti:
- Ottenere maggiore spazio di archiviazione su disco.
- Archiviare i dati in modo ridondante.
- Suddividere i blocchi tra più unità in modo che sia possibile accedervi in parallelo, migliorando così le prestazioni.
È possibile esporre più dischi al file system locale in modo trasparente usando un gestore logico dei volumi (LVM, Logical Volume Manager). Se si considerano due dischi, uno strumento LVM può presentare uno spazio indirizzi di grandi dimensioni al file system locale e mappare internamente la metà degli indirizzi su un disco e l'altra metà sul secondo disco. Per garantire la ridondanza, lo strumento LVM può archiviare copie identiche di ogni blocco in ognuno dei due dischi. A tale scopo, è necessario passare le operazioni di lettura e scrittura attraverso il gestore logico dei volumi. Per ogni scrittura, il gestore aggiorna le due copie identiche desiderate sui due dischi. Per ogni lettura, la richiesta viene inoltrata al disco meno occupato. È infine possibile eseguire accessi paralleli con più dischi usando una tecnica detta striping dei file. Con lo striping dei file, un file viene suddiviso in più unità, che vengono successivamente distribuite tra i dischi per consentire gli accessi paralleli al file.
I dati possono essere sottoposti a striping in modi diversi a seconda dell'unità di striping (il livello di striping dei dati in più dischi). Con lo striping a livello di blocco, l'unità di striping è un blocco di dati. La dimensione di un blocco di dati, nota come larghezza dello striping, varia in base all'implementazione, ma è sempre almeno uguale alla dimensione del settore del disco. Quando è il momento di leggere questi dati sequenziali, tutti i dischi possono essere letti in parallelo. In un sistema operativo multitasking c'è una probabilità elevata che anche gli accessi non sequenziali ai dischi comportino il funzionamento in parallelo di tutti i dischi. Con lo striping a livello di byte, l'unità di striping è esattamente un byte. Con lo striping a livello di bit, l'unità di striping è esattamente un bit.
RAID
Come illustrato nel modulo relativo ai data center, è possibile combinare più dischi in una singola unità logica usando un'organizzazione RAID. RAID 0 esegue lo striping dei dati a livello di blocco su più dischi senza ridondanza. RAID 1 esegue il mirroring dei dati di un disco in un altro e in genere dimezza la capacità di un array. RAID 2 fornisce lo striping a livello di bit con codici di Hamming archiviati in unità di parità. RAID 3 fornisce lo striping a livello di byte con le informazioni sulla parità archiviate in unità di parità dedicate. RAID 4 fornisce lo striping a livello di blocco con unità di parità dedicate. RAID 5 fornisce lo stesso striping a livello di blocco come RAID 4 e 1, ma le informazioni sulla parità vengono distribuite tra tutte le unità del set. Infine, RAID 6 è identico a RAID 5, ma con i blocchi di parità scritti due volte, quindi può tollerare fino a due errori dei dischi in un set. Sono inoltre possibili configurazioni RAID combinate, ad esempio RAID 1+0 e RAID 0+1, per una combinazione di prestazioni e affidabilità.
Reti di archiviazione
In un ambiente IT aziendale, l'archiviazione viene in genere consolidata in modo da poter essere organizzata in pool e condivisa tra più server. I dispositivi di archiviazione possono essere condivisi tra più server tramite una rete di archiviazione (SAN, Storage Area Network). Una SAN è una rete dedicata che fornisce l'accesso a un archivio dati consolidato a livello di blocco (vedere la figura seguente). L'archivio consolidato a livello di blocco è in genere in forma di array di dischi. È possibile configurare l'array di dischi con una forma di RAID, a seconda delle prestazioni e dell'affidabilità necessarie. I server in genere accedono alla rete SAN usando un protocollo come iSCSI o Fibre Channel. I server che usano una rete SAN vedono un dispositivo a blocchi logico, che può essere formattato con un file system e montato nel server. Il server applicazioni può quindi usare i blocchi logici archiviati esternamente nello stesso modo in cui userebbe i blocchi archiviati localmente. Il posizionamento logico dei dati è quindi diverso da quello fisico.
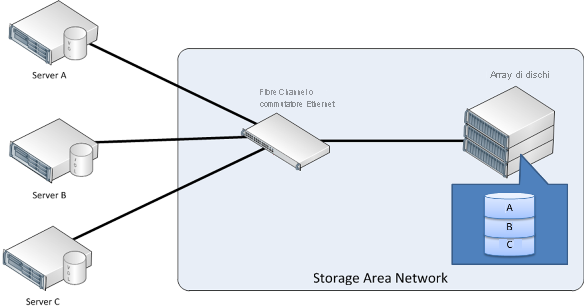
Figura 11: reti di area Archiviazione
Sebbene i server condividano l'array di dischi, non possono condividere fisicamente i dati che si trovano sui dischi. Parti della SAN (identificate come numeri di unità logica o LUN) vengono invece separate e fornite per l'uso esclusivo di ogni server.
Riferimenti
- Thomas Rivera (2012). Esercitazione, The Evolution of File Systems SNIA
- Sanjay Ghemawat, Howard Gobioff e Shun-Tak Leung (2003). The Google File Systems Diciannovesimo simposio ACM sui principi dei sistemi operativi