Progettazione del database: coerenza e teorema CAP
Senza replica, la coerenza non rappresenta un problema. La replica comporta la gestione di più copie (o repliche) degli stessi dati in più computer, mentre la coerenza fornisce una vista o uno stato coerente a livello di sistema delle repliche in più client o processi. Come indicato in precedenza, gli elementi di dati vengono replicati per due motivi principali: prestazioni e affidabilità. Per quanto riguarda le prestazioni, la replica è fondamentale quando il sistema deve essere ridimensionato in base alla quantità di componenti, come avviene principalmente con gli archivi nei cloud privati e pubblici, e alle aree geografiche, come in genere accade con gli archivi nei cloud pubblici. Quando, ad esempio, un numero maggiore di processi deve accedere ai dati gestiti da un singolo server di archiviazione, è possibile migliorare le prestazioni replicando i dati tra più server (invece che averli in un solo server) e suddividendo successivamente il lavoro tra i server. Questa divisione consente di servire le richieste simultaneamente, aumentando così la velocità del sistema. Al contrario, la replica tra le aree geografiche (ad esempio quella applicata da Azure) può essere garantita replicando copie dei dati in prossimità dei processi che eseguono le richieste, per ridurre al minimo i tempi di accesso ai dati. Per quanto riguarda l'affidabilità, la replica consente di fornire una migliore tolleranza di errore in caso di dati danneggiati e persi, un requisito fondamentale per il cloud. In particolare, se una replica viene persa o danneggiata, è possibile accedere in alternativa a un'altra replica valida (se presente).
La replica produce più copie dei dati e la coerenza garantisce che tali repliche rimangano uniformi in modo che i diversi processi possano accedervi, in lettura e in scrittura. In particolare, le repliche in una raccolta sono considerate coerenti quando appaiono identiche ai processi che accedono simultaneamente. La possibilità di gestire le operazioni simultanee sulle repliche mantenendo la coerenza è fondamentale per l'archiviazione distribuita in generale e per l'archiviazione nel cloud in particolare. In questa unità, la coerenza viene discussa nel contesto delle operazioni di lettura e di scrittura eseguite sulle repliche condivise in un archivio dati distribuito (vedere la figura 13). L'archivio dati distribuito può essere un file system DFS, un file system parallelo o un database distribuito. Per ottenere la coerenza, è possibile usare un modello di coerenza. Un modello di coerenza viene definito come un contratto tra i processi e l'archivio dati distribuito. Questa definizione implica che se i processi accettano di rispettare determinate regole, l'archivio dati distribuito garantisce l'applicazione di tali regole. Il video seguente illustra diversi modelli di coerenza.
In questa unità vengono illustrati in dettaglio tre modelli di coerenza: coerenza sequenziale, coerenza causale e coerenza finale.
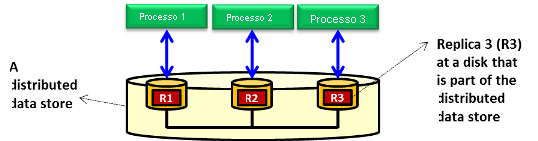
Figura 13: Archivio dati distribuito che può essere un file system distribuito, un file system parallelo o un database distribuito con repliche gestite tra dischi di archiviazione distribuiti
Coerenza sequenziale
La coerenza sequenziale, detta anche coerenza assoluta o rigorosa, comporta la propagazione immediata degli aggiornamenti a tutte le repliche. Questa operazione richiede in genere l'applicazione degli aggiornamenti nelle repliche correlate in una singola transazione o operazione atomica. Nella pratica, l'implementazione dell'atomicità tra repliche che si trovano in varie posizioni in un archivio dati distribuito su larga scala è intrinsecamente complessa, soprattutto se gli aggiornamenti devono essere completati rapidamente. La difficoltà deriva dalle latenze di accesso imprevedibili imposte dalla rete di archiviazione sottostante e dalla mancanza di un orologio globale da usare per ordinare le operazioni in modo rapido e accurato. Per risolvere questo problema, è possibile rendere meno rigoroso il requisito di esecuzione degli aggiornamenti come operazioni atomiche. Se si rendono meno rigorosi i requisiti di coerenza, le repliche non devono essere sempre uguali in tutte le posizioni. La possibilità di applicare una coerenza meno rigorosa dipende dall'applicazione in esecuzione nell'archivio dati distribuito. In particolare, l'allentamento dei requisiti di coerenza dipende dai modelli di accesso in lettura e scrittura dell'applicazione e dallo scopo per cui vengono usate le repliche. Browser e proxy Web, ad esempio, sono spesso configurati per archiviare le pagine Web nelle cache locali (si tratta di un tipo di replica perché vengono mantenute più copie per la stessa pagina Web) per ridurre i tempi di accesso per i riferimenti futuri. In alcune situazioni è accettabile che gli utenti ricevano pagine Web obsolete, purché, alla fine e in modo sufficientemente rapido, le pagine Web vengano aggiornate alle versioni più recenti disponibili sui server Web effettivi. La coerenza finale è un esempio di modello che si adatta a questi scenari.
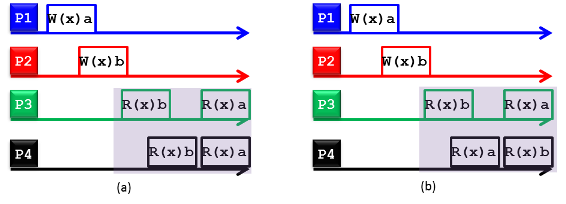
Figura 14: (a) archivio dati distribuito con coerenza sequenziale e (b) archivio dati distribuito non con coerenza sequenziale
Un archivio dati distribuito viene considerato coerente in modo sequenziale se tutti i processi vedono la stessa interfoliazione delle operazioni di lettura e scrittura in caso di accesso simultaneo alle repliche. La figura 14 mostra due archivi dati distribuiti, ovvero un archivio dati con coerenza sequenziale (vedere la figura 14 (a)) e un archivio dati non con coerenza sequenziale (vedere la figura 14 (b)). I simboli W(x)a e R(x)b indicano, rispettivamente, un valore di scrittura (write) a nella replica x e un valore di lettura (read) b dalla replica x. La figura mostra quattro processi che operano sulle repliche corrispondenti all'elemento di dati x. Nella figura 14(a) il processo P1 scrive a in x e successivamente (in tempo assoluto), il processo P2 scrive b in x. Successivamente, i processi P3 e P4 ricevono prima il valore b e quindi il valore a alla lettura di x. Di conseguenza, l'operazione di scrittura eseguita dal processo P2 risulta avvenuta prima di quella di P1 e di quelle di entrambi i processi P3 e P4. Ciononostante, la figura 14(a) rappresenta un archivio dati distribuito con coerenza sequenziale perché i processi P3 e P4 riscontrano la stessa interfoliazione delle operazioni (ovvero leggono prima b e quindi a). I processi P3 e P4 nella figura 14(b) invece vedono un'interfoliazione diversa delle operazioni, violando così la condizione di coerenza sequenziale.
Coerenza causale
Il modello di coerenza causale è una variante più debole del modello di coerenza sequenziale. Per prima cosa, la causalità implica che se l'operazione b è causata o influenzata da un'operazione precedente a, ogni processo che accede all'archivio dati distribuito deve vedere prima a e quindi b. Un archivio dati distribuito con coerenza causale impone la coerenza solo tra le operazioni potenzialmente correlate in modo causale. Le operazioni non potenzialmente correlate in modo causale possono apparire ai processi con qualsiasi interfoliazione e sono identificate come operazioni simultanee. La figura 15 mostra due archivi dati distribuiti con coerenza causale (figure 15(a) e 15(c)) e un archivio dati distribuito non con coerenza causale (figura 15 (b)). Nella figura 15(a), l'operazione W(x)b eseguita dal processo P2 dipende potenzialmente dall'operazione W(x)a eseguita dal processo P1 perché b può essere il risultato di calcoli che comportano la lettura di a da parte del processo P2 (ovvero R(x)a) prima della scrittura di b (ovvero W(x)b). I risultati delle operazioni di scrittura W(x)a e W(x)b eseguite rispettivamente da P1 e P2 devono quindi apparire nello stesso ordine a ogni processo di lettura. Dal momento che i processi P3 e P4 leggono prima a e quindi b, rispettano la condizione di causalità, garantendo così la coerenza causale dell'archivio dati distribuito sottostante. Il processo P3 nella figura 15(b) non rispetta invece la condizione di causalità, ovvero legge prima b e quindi a e non viene pertanto garantita la coerenza causale dell'archivio dati distribuito sottostante. Infine, la figura 15(c) mostra un archivio dati distribuito con coerenza casuale perché W(x)a e W(x)b sono operazioni simultanee, quindi i relativi risultati, ovvero R(x)a e R(x)b, possono apparire in qualsiasi ordine nei processi di lettura, come avviene per i processi P3 e P4.
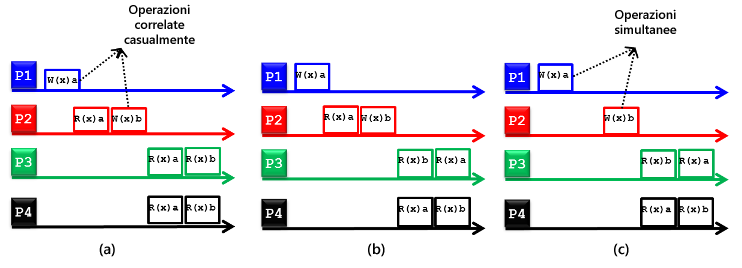
Figura 15: (a) archivio dati distribuito con coerenza causale, (b) archivio dati distribuito non con coerenza causale e (c) archivio dati distribuito con coerenza causale
Coerenza finale
Il modello di coerenza finale è considerato una forma più debole rispetto ai modelli di coerenza sequenziale e causale. La coerenza finale implica che un'operazione di scrittura in una replica non deve essere propagata immediatamente a tutte le altre repliche e può essere ritardata (o talvolta mai propagata), se accettabile per le applicazioni. In particolare, se un processo P accede a una determinata replica, R, $N$ volte al minuto e la replica R viene aggiornata $M$ volte al minuto, se un'applicazione presenta un rapporto basso tra lettura e scrittura (ovvero $N << M$), non verrà mai eseguito l'accesso a numerosi aggiornamenti della replica da parte di P, rendendo quindi superflui tutti gli aggiornamenti e le comunicazioni di rete necessarie. In questo caso, può essere preferibile applicare un modello di coerenza debole, in base a cui l'aggiornamento di R avviene solo quando si verifica l'accesso da parte di P. In altri termini, è più efficiente propagare un aggiornamento differito, con cui un processo di lettura vede l'aggiornamento solo dopo che è trascorso un po' di tempo da quando è stato eseguito (non immediatamente, come nel caso della coerenza assoluta). Se i conflitti derivanti da due operazioni che cercano di scrivere negli stessi dati (ovvero, conflitti di scrittura) si verificano raramente o mai, spesso è accettabile ritardare la propagazione di un aggiornamento. I conflitti si verificano raramente nei sistemi di database, che in genere usano la coerenza finale. I sistemi di database vengono descritti in dettaglio nella sezione successiva. Si noti che è stato presentato solo un aspetto relativo ai modelli di coerenza. Un altro aspetto riguarda il modo in cui vengono implementati tali modelli. Questa unità esamina solo le caratteristiche dei modelli e la loro applicabilità ai sistemi di archiviazione nel cloud. È tuttavia importante sottolineare brevemente che la coerenza sequenziale è difficile da implementare nella pratica e offre scarsa scalabilità. In genere, la coerenza sequenziale richiede l'uso di meccanismi di sincronizzazione come le transazioni e i blocchi. Al contrario, l'implementazione della coerenza causale comporta la creazione di un grafico dipendenze che acquisisce le operazioni correlate in maniera causale e applica tali operazioni tra i processi che eseguono l'accesso. Un modo per implementare un modello di questo tipo consiste nell'usare timestamp vettoriali. La coerenza finale può essere implementata raggruppando le operazioni di lettura e scrittura in sessioni e usando timestamp vettoriali.
Proprietà ACID nei database
I database possono offrire proprietà transazionali. Una transazione è costituita da un'unità di lavoro eseguita in un sistema di gestione di database (o in un sistema simile) su un database. Le transazioni vengono gestite in modo coerente e affidabile indipendentemente dalle altre transazioni. Le transazioni in un ambiente di database hanno due scopi principali:
- Fornire unità di lavoro affidabili che consentano il ripristino dagli errori e mantengano la coerenza di un database, anche in caso di errori di sistema quando l'esecuzione si arresta (completamente o in parte) e molte operazioni in un database rimangono incomplete, con uno stato non chiaro.
- Garantire l'isolamento tra i programmi che accedono simultaneamente a un database. Se questo isolamento non viene fornito, i risultati del programma possono essere errati.
Per comprendere meglio la necessità delle transazioni in un database, considerare la transazione finanziaria seguente eseguita su due conti bancari, A e B. Si supponga che un utente voglia trasferire 100 $ dal conto A al conto B. Questo trasferimento può essere rappresentato in due passaggi:
- Detrarre 100 $ dal conto A.
- Accreditare 100 $ sul conto B.
Si supponga che si verifichi un errore del database tra le operazioni 1 e 2: sono stati detratti 100 $ dal conto A, ma l'accredito sul conto B non è avvenuto. I conti e il database si trovano in uno stato incoerente.
Per risolvere questo problema, è possibile definire le operazioni come una transazione, come indicato di seguito:
- Iniziare la transazione.
- Detrarre 100 $ dal conto A.
- Accreditare 100 $ sul conto B.
- Terminare la transazione.
È ora responsabilità del database garantire l'atomicità di questa transazione, ovvero che la transazione venga eseguita interamente (commit) o non venga eseguita del tutto (rollback). Il database deve essere coerente al termine della transazione, ovvero deve essere in uno stato valido dopo il commit della transazione e tutte le regole definite per i record nel database non devono essere violate (ad esempio, un conto di risparmio non deve avere un saldo negativo). Tutte le transazioni che avvengono simultaneamente nei conti non devono interferire tra loro, garantendo in tal modo l'isolamento . Infine, la transazione deve essere durevole, il che significa che le azioni eseguite nella transazione devono essere mantenute dopo il commit della transazione nel database. Le proprietà di atomicità, coerenza, isolamento e durabilità sono note collettivamente come proprietà ACID delle transazioni e devono essere rispettate dalla maggior parte dei sistemi RDBMS usati per l'elaborazione delle transazioni. Il video seguente offre una panoramica delle proprietà ACID nei database:
- Atomic: la transazione è indivisibile, ovvero tutte le istruzioni nella transazione vengono applicate al database o nessuna.
- Coerente: il database rimane in uno stato coerente prima e dopo l'esecuzione della transazione.
- Isolato: sebbene più transazioni possano essere eseguite contemporaneamente da uno o più utenti, una transazione non dovrebbe visualizzare gli effetti di altre transazioni simultanee.
- Durevole: una volta salvata una transazione nel database (un'azione denominata in linguaggio di programmazione del database come commit), è previsto che le modifiche vengano mantenute.
Perché non si può avere tutto: il teorema CAP
Nel 1999, Brewer1 ha proposto un teorema che descrive le limitazioni dell'archiviazione di dati distribuita, detto teorema CAP. Il teorema CAP stabilisce che qualsiasi sistema di archiviazione distribuito con dati condivisi può avere al massimo due delle tre proprietà desiderate:
- Coerenza: la coerenza è uno stato in cui ogni nodo vede sempre gli stessi dati in qualsiasi momento specifico (coerenza rigorosa).
- Disponibilità: una garanzia che ogni richiesta riceva una risposta sul fatto che abbia avuto esito positivo o negativo sia una garanzia di disponibilità.
- Tolleranza di partizione: una partizione di rete è una condizione in cui i nodi di un sistema distribuito non possono contattarsi tra loro. La tolleranza di partizione significa che il sistema continua a funzionare normalmente nonostante una perdita arbitraria di messaggi o un errore di parte del sistema.
Il video seguente fornisce una panoramica del teorema CAP:
Il modo più semplice per comprendere il teorema CAP consiste nel pensare a due nodi di un sistema di archiviazione distribuito sui lati opposti di una partizione di rete (figura 16). Se si consente ad almeno un nodo di aggiornare lo stato, i nodi diventeranno incoerenti, non rispettando quindi il vincolo di coerenza (C). Analogamente, se si vuole mantenere la coerenza, un lato della partizione deve agire come se non fosse disponibile, non rispettando quindi il vincolo di disponibilità (A). Solo quando i nodi comunicano è possibile mantenere la coerenza e la disponibilità, ma in questo caso non viene rispettato il vincolo di tolleranza di partizione (P).
Si consideri ad esempio il caso di un sistema RDBMS a nodo singolo tradizionale. In questo scenario è possibile garantire la coerenza e la disponibilità, mentre il concetto di tolleranza di partizione non esiste perché il database si trova in un singolo nodo.
Quando le aziende come Microsoft progettano database su larga scala per gestire milioni di clienti, la disponibilità 24 ore su 24, 7 giorni su 7 è fondamentale, perché anche pochi minuti di tempo di inattività comportano la perdita di ricavi. Quando si ridimensionano i sistemi di dati condivisi distribuiti fino a centinaia o migliaia di computer, la probabilità di un errore di uno o più nodi (con la conseguente creazione di una partizione di rete) aumenta significativamente. Quindi, in base al teorema CAP, per avere garanzie rigorose in merito alla disponibilità e alla tolleranza di partizione, in un database distribuito su larga scala e ad alte prestazioni è necessario sacrificare la coerenza assoluta.
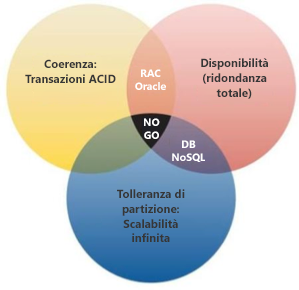
Figura 16: Teorema CAP illustrato
Riferimenti
- Eric Brewer (2000). Towards Robust Distributed Systems Documentazione del simposio ACM annuale sui principi di distributed computing