Classificare i dati
Un'azienda di vendita online presenta diversi tipi di dati. Per ogni tipo di dati potrebbe essere utile una soluzione di archiviazione specifica.
I dati delle applicazioni possono essere classificati in uno di tre modi: strutturati, semistrutturati e non strutturati. In questa unità si apprenderà come classificare i dati in modo da poter scegliere la soluzione di archiviazione appropriata per ogni tipo di dati.
Approcci per l'archiviazione dei dati nel cloud
Il video seguente presenta le opzioni per l'archiviazione dei dati nel cloud:
Dati strutturati
Nei dati strutturati, talvolta denominati dati relazionali, tutti i dati hanno gli stessi campi o proprietà. Tutti i dati hanno la stessa organizzazione e forma o schema. Lo schema condiviso consente di eseguire facilmente ricerche in questo tipo di dati con linguaggi di query come SQL (Structured Query Language). Questa funzionalità rende questo stile di dati perfetto per le applicazioni come i sistemi CRM, le prenotazioni e la gestione dell'inventario.
I dati strutturati vengono spesso archiviati in tabelle di database con righe e colonne. Nella tabella, una colonna chiave indica in che modo una riga di una tabella è in relazione con i dati in un'altra riga di un'altra tabella. Nell'immagine seguente, una tabella con dati relativi ai voti ottiene dati da una tabella di nomi degli studenti e da una tabella di dati della classe usando colonne chiave.
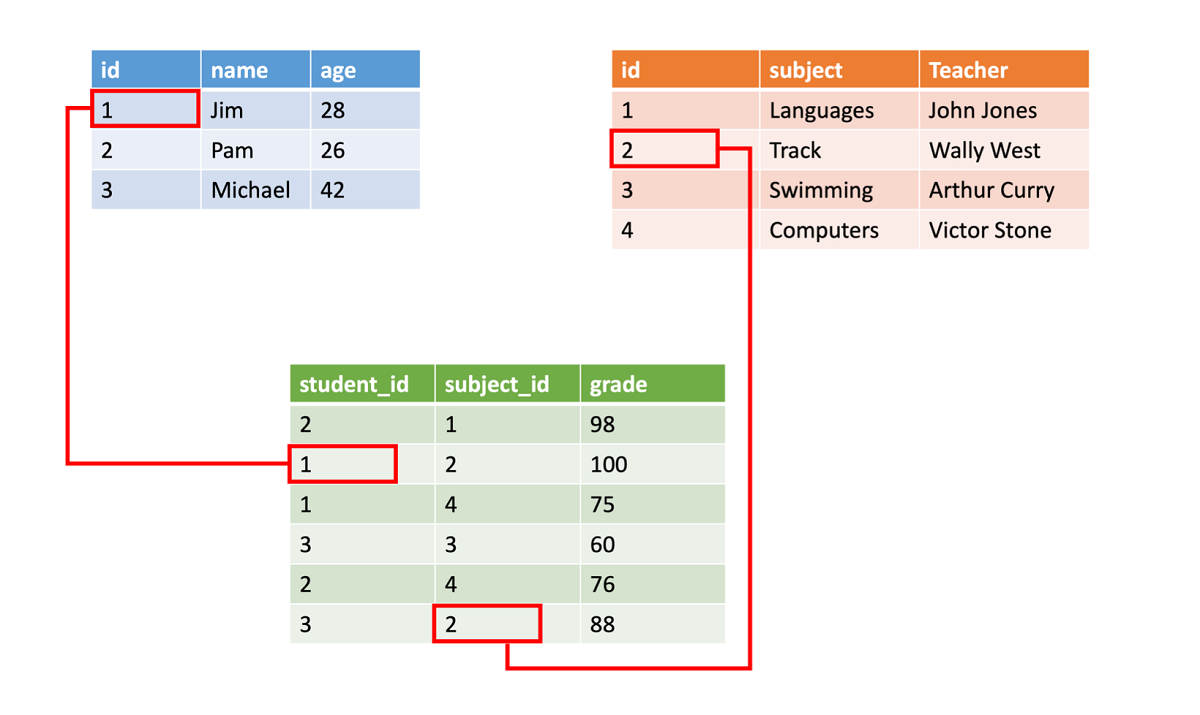
I dati strutturati sono semplici, nel senso che l'immissione, l'esecuzione di query e l'analisi risultano facilitate, Tutti i dati hanno lo stesso formato. Imporre una struttura coerente, tuttavia, significa anche che l'evoluzione dei dati risulta più difficoltosa. Se si aggiungono o rimuovono campi dati, è necessario aggiornare ogni record per conformarlo alla nuova struttura.
Dati semistrutturati
I dati semistrutturati sono meno organizzati rispetto ai dati strutturati. I dati semistrutturati non vengono archiviati in un formato relazionale perché i campi non si adattano bene a tabelle, righe e colonne. I dati semistrutturati contengono tag che ne evidenziano l'organizzazione e la gerarchia. Un esempio sono le coppie chiave/valore. I dati semistrutturati sono anche definiti non relazionali o non solo SQL (NoSQL).
I dati semistrutturati sono definiti da un linguaggio di serializzazione dei dati. Nella classificazione dei dati la serializzazione è il processo di conversione dei dati in un formato che può essere trasmesso o archiviato.
Gli sviluppatori di software usano i linguaggi di serializzazione dei dati per scrivere dati archiviati in memoria in un file, che può quindi essere inviato a un altro sistema, analizzato e letto. Il mittente e il destinatario non devono conoscere i dettagli dell'altro sistema. Fino a quando viene usato lo stesso linguaggio di serializzazione, i dati possono essere compresi da entrambi i sistemi.
Linguaggi di serializzazione comuni
Tre linguaggi di serializzazione comuni sono XML, JSON e YAML.
XML
XML (Extensible Markup Language) è stato uno dei primi linguaggi di dati di ampia diffusione. Essendo basato su testo, è facilmente leggibile dagli utenti e dai computer. I parser XML sono disponibili per quasi tutte le piattaforme di sviluppo più diffuse.
È possibile usare XML per esprimere relazioni. Il linguaggio XML include standard per lo schema, la trasformazione e persino la visualizzazione sul Web.
Di seguito è riportato un esempio di nome, età e hobby di una persona espressi in XML:
<Person Age="23">
<FirstName>Quinn</FirstName>
<LastName>Anderson</LastName>
<Hobbies>
<Hobby Type="Sports">Golf</Hobby>
<Hobby Type="Leisure">Reading</Hobby>
<Hobby Type="Leisure">Guitar</Hobby>
</Hobbies>
</Person>
XML esprime la forma dei dati usando tag definiti all'interno di parentesi graffe. I tag sono disponibili in due formati: elementi, ad esempio <FirstName> e attributi, che possono essere espressi in un testo come Age="23". Gli elementi possono avere elementi figlio per esprimere relazioni. Ad esempio, il tag <Hobbies> esprime una raccolta di elementi Hobby.
Il linguaggio XML è flessibile e può esprimere facilmente dati complessi. In genere è tuttavia piuttosto dettagliato e quindi più voluminoso da archiviare, elaborare e passare in rete. Di conseguenza, altri formati sono diventati più popolari.
JSON
JSON (JavaScript Object Notation) presenta una specifica leggera e usa le parentesi graffe per indicare la struttura dei dati. Rispetto a XML, JSON è meno dettagliato e di più facile lettura per gli umani. Il formato JSON viene spesso usato dai servizi Web per restituire i dati.
Ecco il nome, l'età e gli hobby della stessa persona espressi in formato JSON:
{
"firstName": "Quinn",
"lastName": "Anderson",
"age": "23",
"hobbies": [
{ "type": "Sports", "value": "Golf" },
{ "type": "Leisure", "value": "Reading" },
{ "type": "Leisure", "value": "Guitar" }
]
}
Il formato JSON non è formale come XML. È più simile a un modello di coppie chiave/valore piuttosto che a un'espressione di dati formale. Come si può intuire dal nome, il linguaggio di programmazione JavaScript include il supporto predefinito per questo formato, motivo per cui è molto popolare per lo sviluppo Web. Analogamente a XML, altri linguaggi hanno parser che è possibile usare per lavorare con questo formato di dati. Il lato negativo di JSON è che, essendo in genere più orientato alla programmazione, è più difficile da leggere e modificare per chi non è un tecnico.
YAML
YAML (YAML Ain't Markup Language) è un linguaggio di serializzazione dei dati sviluppato più di recente. Uno dei vantaggi dell'uso di YAML è la maggiore leggibilità per gli esseri umani rispetto ad altri linguaggi. La struttura dei dati viene definita tramite la separazione e il rientro delle righe. Il formato YAML riduce la dipendenza da caratteri strutturali come parentesi, virgole e parentesi graffe.
Ecco gli stessi dati espressi in formato YAML:
firstName: Quinn
lastName: Anderson
age: 23
hobbies:
- type: Sports
value: Golf
- type: Leisure
value: Reading
- type: Leisure
value: Guitar
Questo formato è più leggibile di JSON e viene spesso usato per i file di configurazione che devono essere scritti dagli utenti, ma analizzati dai programmi. YAML è il più recente di questi formati di dati.
Che cosa sono i dati semistrutturati o NoSQL?
Il video seguente descrive le opzioni di archiviazione per i dati semistrutturati e NoSQL:
Dati non strutturati
L'organizzazione dei dati non strutturati è indefinita. I dati non strutturati vengono spesso recapitati in formato file, ad esempio in file fotografici o video. Il file video potrebbe presentare una struttura generale e includere metadati semistrutturati, ma i dati che formano il video sono non strutturati. Di conseguenza, le foto, i video e altri file simili sono classificati come dati non strutturati.
Esempi di dati non strutturati includono:
- File multimediali, come foto, video e file audio
- File di Microsoft 365, ad esempio documenti di Word
- File di testo
- File di registro
Classificazione dei dati: valutare i tipi di dati
I dati possono essere classificati in uno di tre modi: strutturati, semistrutturati e non strutturati. La conoscenza delle differenze per poter classificare i dati consente di scegliere la soluzione di archiviazione corretta.
I dati strutturati sono dati organizzati che si adattano perfettamente a tabelle o colonne di dati. I dati semistrutturati sono comunque organizzati e hanno proprietà e valori ben definiti, ma possono variare. I dati non strutturati non si adattano perfettamente a tabelle o colonne e non hanno uno schema uniforme.
Di seguito verranno esaminati e classificati i set di dati usati in un'azienda di vendita al dettaglio online.
Dati del catalogo prodotti
I dati del catalogo prodotti per un'azienda di vendita al dettaglio online sono semistrutturati per natura. Ogni prodotto ha SKU, descrizione, quantità, prezzo, misure, colori, foto e a volte anche un video. Questi dati sembrano inizialmente relazionali, in quanto hanno tutti la stessa struttura. Man mano che si introducono nuovi prodotti o tipi di prodotti diversi, tuttavia, potrebbe essere necessario aggiungere campi dati. Ad esempio, si potrebbero introdurre nuove scarpe da tennis con una funzionalità Bluetooth per l'inoltro dei dati dei sensori dalla scarpa a un'app di fitness nel telefono dell'utente. Questa funzionalità sembra essere una tendenza sempre più diffusa, quindi si vuole offrire ai clienti l'opzione per filtrare i prodotti e cercare le scarpe con "funzionalità Bluetooth". Si vuole evitare di aggiornare tutti i dati esistenti relativi alle scarpe con questa nuova proprietà, ma ci si vuole limitare ad aggiungerla solo alle nuove scarpe.
Con l'aggiunta della proprietà relativa alla funzionalità Bluetooth, i dati delle scarpe non sono più omogenei. Sono state introdotte differenze nello schema. Se si tratta dell'unica eccezione prevista, è possibile normalizzare i dati esistenti in modo che tutti i prodotti includano un campo relativo alla funzionalità Bluetooth al fine di mantenere un'organizzazione relazionale strutturata. Tuttavia, se questo è solo uno dei molti campi di specializzazione che si prevede di supportare in futuro, questi dati vengono classificati come semistrutturati. I dati sono organizzati in base a tag, ma ogni prodotto nel catalogo può contenere campi univoci.
I dati del catalogo prodotti sono classificati come semistrutturati.
Foto e video
La foto e i video visualizzati nelle pagine dei prodotti sono dati non strutturati. Anche se il file multimediale può contenere metadati, il corpo del file multimediale è non strutturato.
I dati per foto e video sono classificati come non strutturati.
Dati di business
I business analyst desiderano implementare la business intelligence per eseguire valutazioni delle pipeline di inventario e revisioni dei dati di vendita. Per eseguire queste operazioni, è necessario aggregare i dati di più mesi sui quali verranno successivamente eseguite le query. Vista la necessità di aggregare dati simili, questi dati devono essere strutturati, in modo che un mese possa essere confrontato con il successivo.
I dati aziendali sono classificati come strutturati.