Esercizio - Eseguire query in un cluster Spark in HDInsight
In questo esercizio verrà illustrato come creare un dataframe da un file CSV e come eseguire query SQL Spark interattive in un cluster Apache Spark in Azure HDInsight. In Spark un frame di dati è una raccolta distribuita di dati organizzati in colonne denominate. Dal punto di vista concettuale il dataframe equivale a una tabella in un database relazionale o a un frame di dati in R/Python.
In questa esercitazione apprenderai a:
- Creare un frame di dati da un file csv
- Eseguire query sul frame di dati
Creare un frame di dati da un file csv
Il file CSV di esempio seguente contiene informazioni sulla temperatura di un edificio ed è archiviato nel file system del cluster Spark.
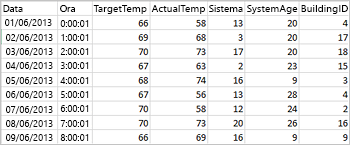
Incollare il codice seguente in una cella vuota del notebook Jupyter e quindi premere MAIUSC+INVIO per eseguire il codice. Il codice importa i tipi necessari per questo scenario
from pyspark.sql import * from pyspark.sql. types import *Quando si esegue una query interattiva in Jupyter, la finestra del Web browser o la didascalia della scheda mostra lo stato (Occupato) insieme al titolo del notebook. È anche visibile un cerchio pieno accanto al testo PySpark nell'angolo in alto a destra. Al termine del processo viene visualizzato un cerchio vuoto.
Eseguire il codice seguente per creare un frame di dati e una tabella temporanea (hvac).
# Create a dataframe and table from sample data csvFile = spark.read.csv ('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write. saveAsTable("hvac")
Eseguire query sul frame di dati
Dopo aver creato la tabella, è possibile eseguire una query interattiva sui dati.
Eseguire il codice seguente in una cella vuota del notebook:
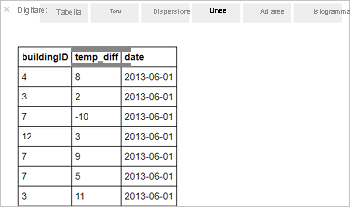
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Viene visualizzato l'output tabulare seguente.
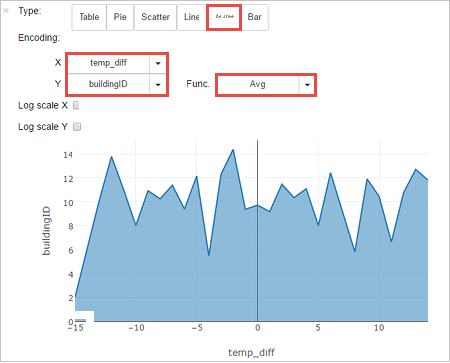
È anche possibile visualizzare i risultati in altri formati. Per visualizzare un grafico ad area per lo stesso output, selezionare Area e quindi impostare altri valori, come illustrato.
Dalla barra dei menu del notebook, passare a File > Salva ed esegui checkpoint.
Arrestare il notebook per rilasciare le risorse del cluster: dalla barra dei menu del notebook, passare a File > Close and Halt (Chiudi e interrompi).