Impostare la baseline delle prestazioni di Apache Spark con il server cronologia Apache Spark in Azure Synapse Analytics
Il server cronologia Apache Spark può essere usato per eseguire il debug e la diagnostica delle applicazioni Apache Spark completate e in esecuzione. È possibile usare l'interfaccia utente Web del server cronologia Apache Spark dall'ambiente di Azure Synapse Studio. Dopo l'avvio, sono disponibili diverse schede che è possibile usare per monitorare l'applicazione Apache Spark:
- Processi
- FASI
- Storage
- Ambiente
- Executors
- SQL
Il server cronologia Apache Spark è l'interfaccia utente Web nota come interfaccia utente Spark e viene usato per visualizzare le applicazioni Apache Spark completate e in esecuzione. Per passare al server cronologia Apache Spark, è possibile passare all'ambiente di Azure Synapse Analytics Studio e accedere alla scheda Monitoraggio, dove è possibile selezionare "Apache Spark Applications" (Applicazioni Apache Spark).

Se si ha familiarità con Apache Spark, è possibile accedere all'interfaccia utente standard del server cronologia Spark selezionando Open Spark UI (Apri interfaccia utente Spark).
Un altro modo per aprire il server cronologia Apache Spark consiste nel passare alla scheda Dati, dove, se si crea un notebook e si legge un dataframe, è possibile scorrere fino alla parte inferiore della pagina e trovare il server cronologia Spark noto come interfaccia utente Spark.
Nel notebook di Azure Synapse Studio selezionare Open Spark UI (Apri interfaccia utente Spark) dalla cella di output dell'esecuzione del processo o dal pannello dello stato nella parte inferiore del documento del notebook.

Selezionare Spark UI (Interfaccia utente Spark) dal pannello scorrevole. Si verrà reindirizzati alla scheda relativa al monitoraggio di Spark da cui si accederà alla scheda Jobs (Processi).

Nella scheda Jobs (Processi) del server cronologia Spark è possibile visualizzare l'ID processo, la descrizione, l'ora di invio del processo, la durata, le fasi e l'attività (per tutte le fasi). Se si seleziona un ID processo, si passa alla descrizione e si seleziona l'URL, si verrà reindirizzati a questa schermata:
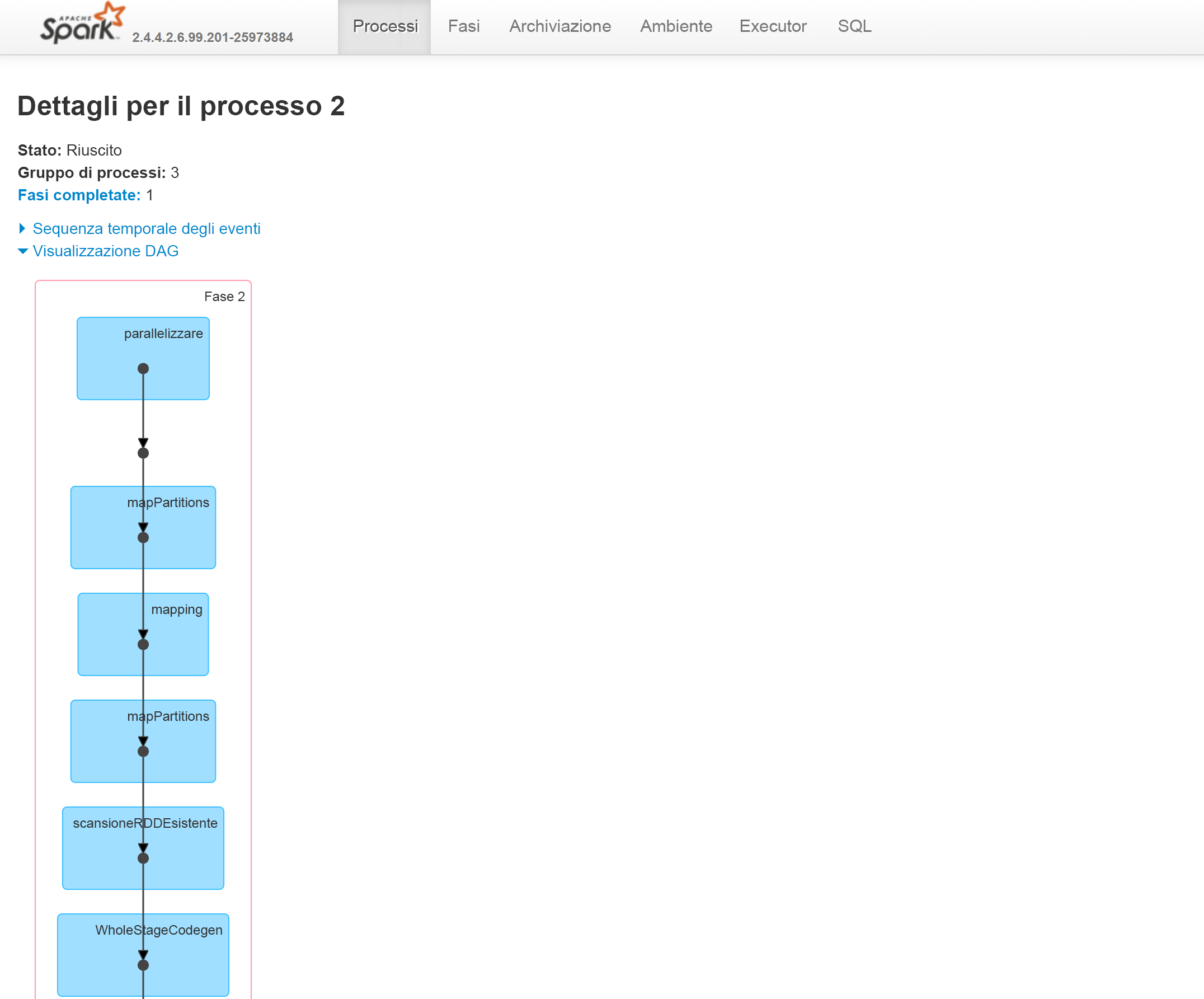
Verrà visualizzato un grafo aciclico diretto della fase.
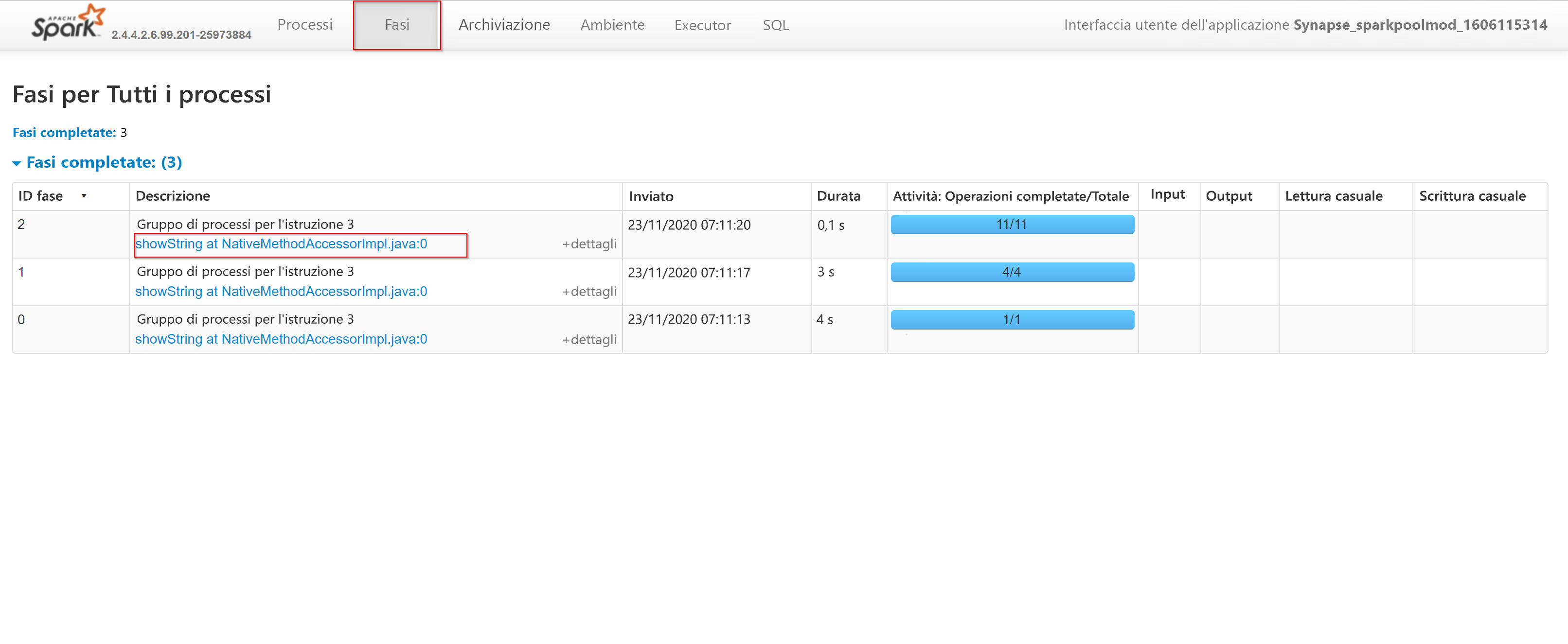
Se si seleziona la scheda Stages (Fasi), saranno visibili tutte le fasi completate. Per approfondire le fasi, è possibile selezionare l'URL della descrizione come illustrato di seguito:
Nella scheda Storage (Archiviazione) i set di dati resilienti distribuiti verranno memorizzati nella cache solo dopo averli valutati. Uno dei modi più comuni per forzare la valutazione e popolare una cache consiste, ad esempio, nel chiamare il comando "count".
demo_df.cache() demo_df.count()
L'immagine mostra il contenuto visualizzato scheda Storage (Archiviazione) dell'interfaccia utente Apache Spark:
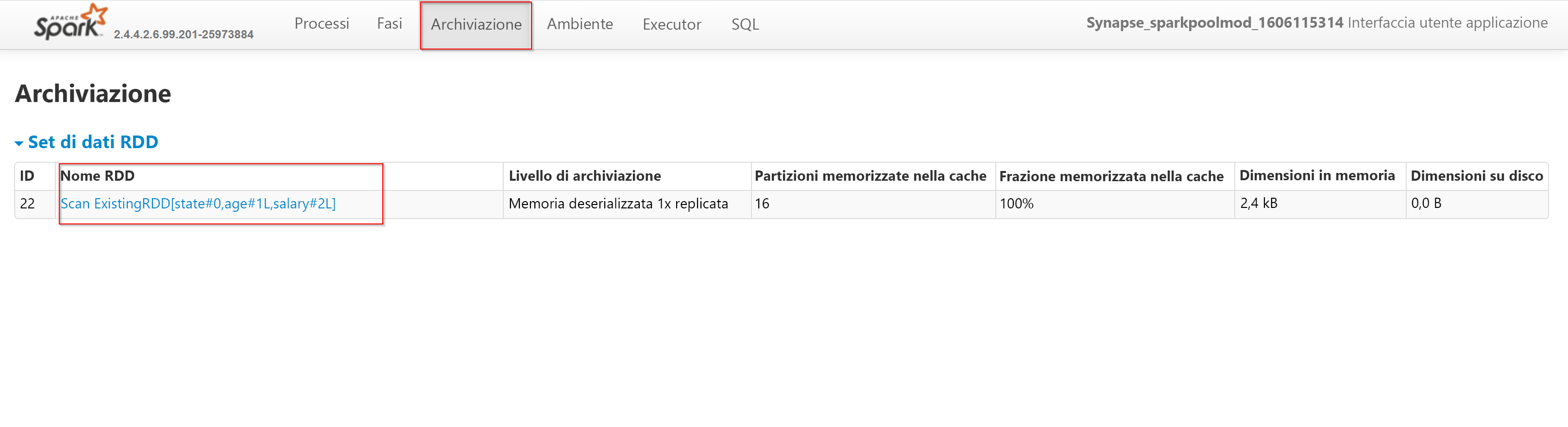
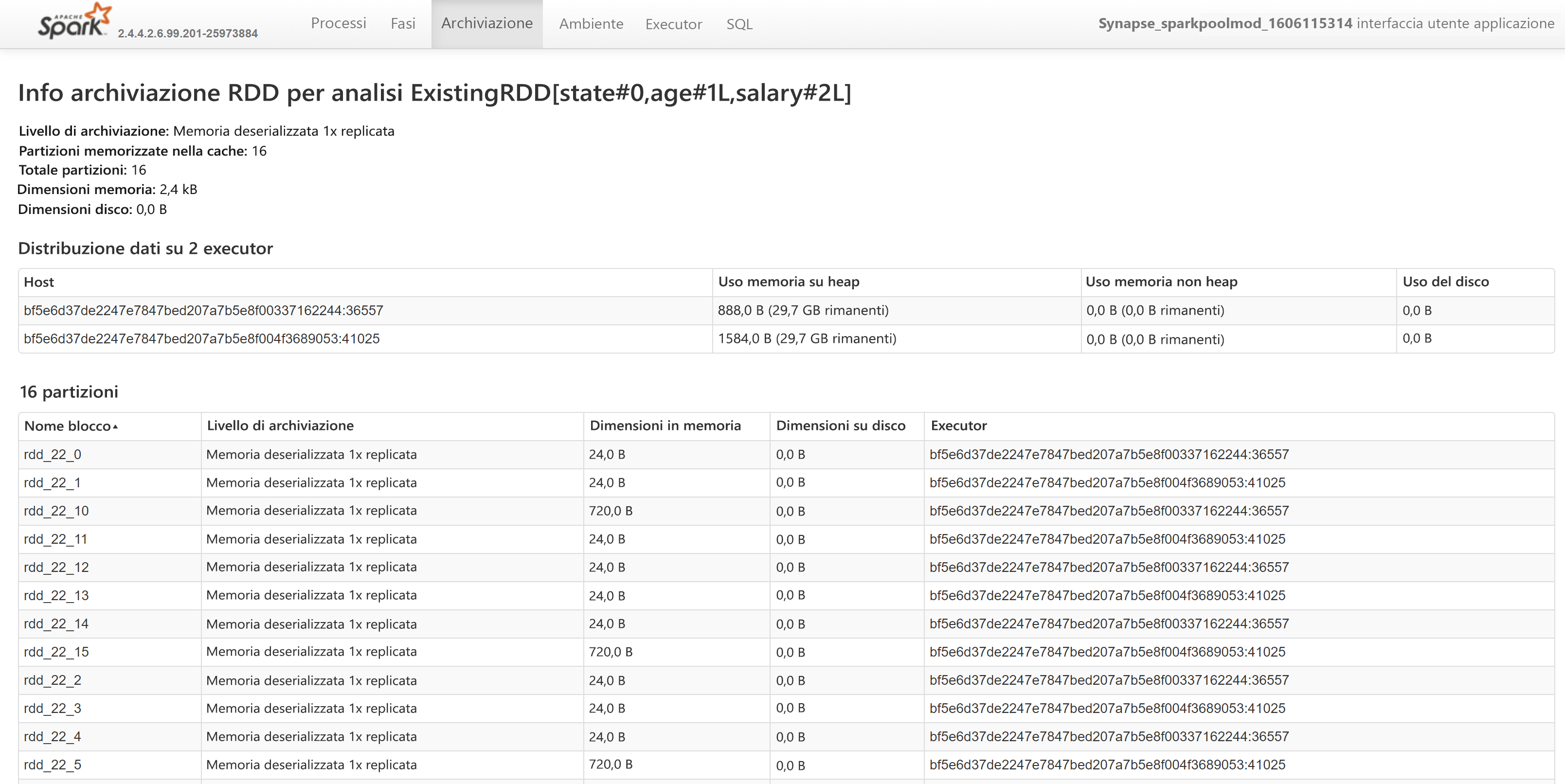
Passando all'URL del nome del set di dati resiliente distribuito, verranno visualizzati questi dettagli aggiuntivi:
Nella scheda Environment (Ambiente) vengono invece visualizzate le informazioni di runtime, le proprietà di Spark, le proprietà di sistema e le voci del percorso della classe.
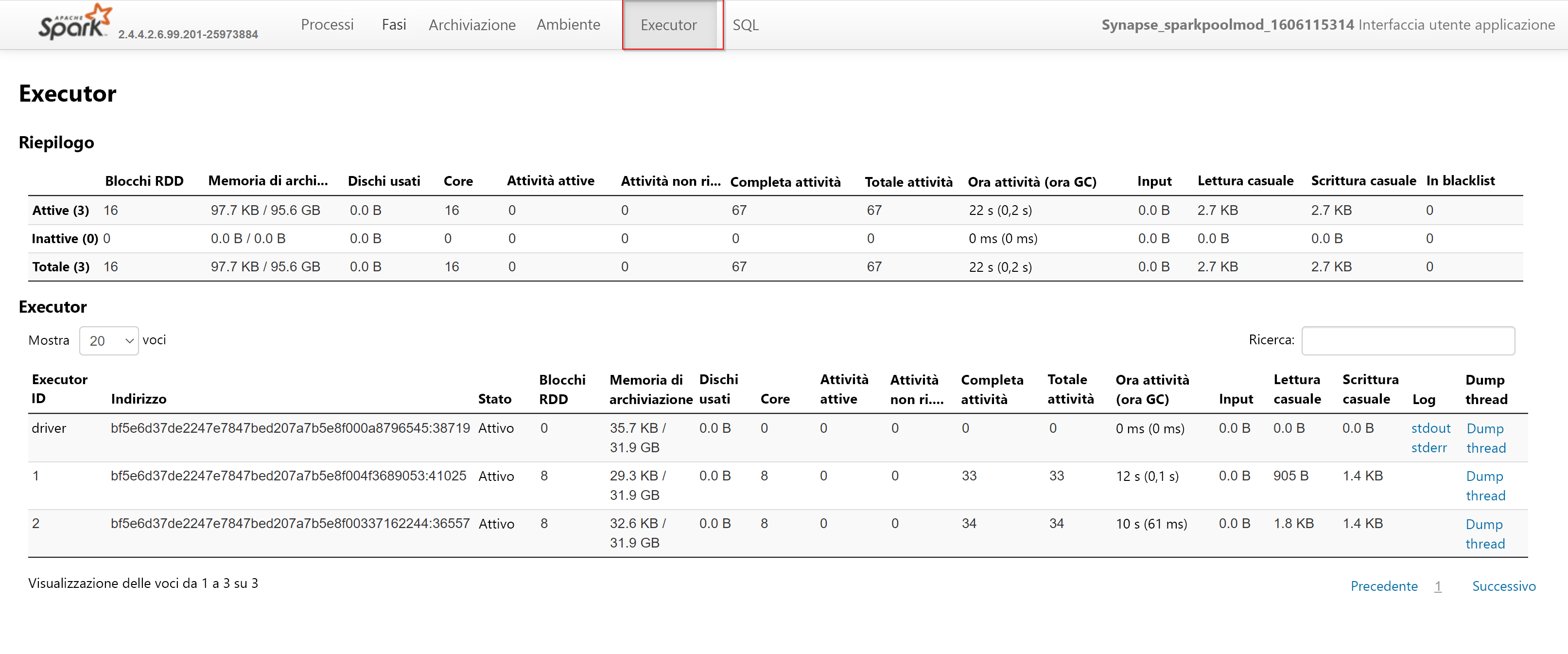
Si esaminerà ora la scheda Executors (Executor), dove è possibile trovare tutte le informazioni sugli executor:
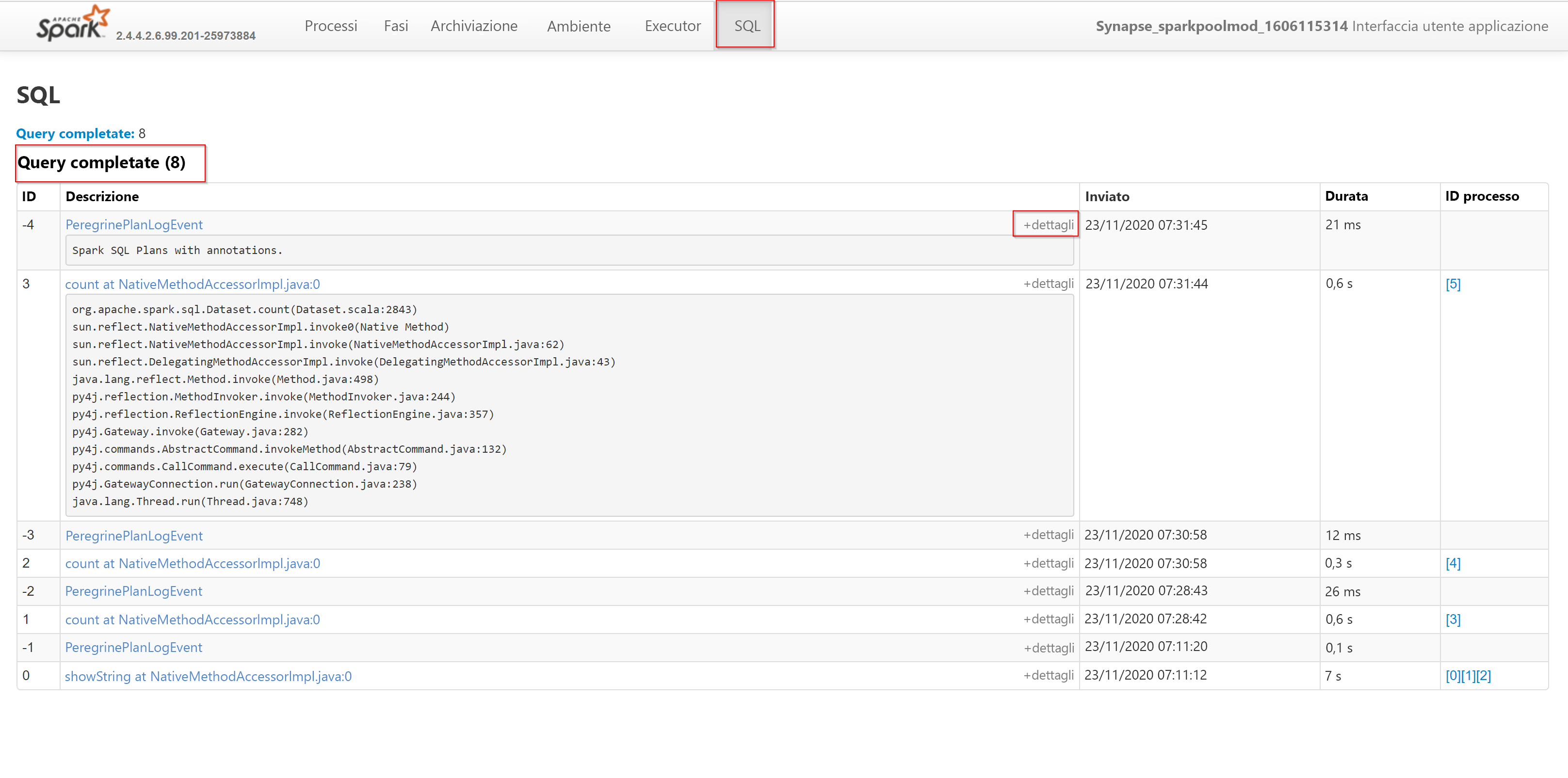
Infine nella scheda SQL è possibile trovare le query completate e i dettagli in corrispondenza degli ID delle query.








Ora che sono state esaminate tutte le schede dell'interfaccia utente Spark, è possibile ottimizzare e impostare la baseline delle prestazioni e delle impostazioni di Apache Spark.