Linee guida per le relazioni uno-a-uno
Questo articolo è destinato a un modello di dati che usa Power BI Desktop. Fornisce indicazioni sull'uso delle relazioni di modello uno-a-uno. È possibile creare una relazione uno-a-uno quando entrambe le tabelle contengono una colonna di valori comuni e univoci.
Nota
Un'introduzione alle relazioni tra modelli non è descritta in questo articolo. Se non si ha familiarità con le relazioni, le relative proprietà o come configurarle, è consigliabile leggere prima l'articolo Relazioni tra modelli in Power BI Desktop .
È anche importante avere una conoscenza della progettazione dello schema star. Per altre informazioni, vedere Informazioni sullo schema star e sull'importanza di Power BI.
Esistono due scenari che coinvolgono relazioni uno-a-uno:
Dimensioni degenerate: è possibile derivare una dimensione degenerata da una tabella di tipo fatto.
I dati di riga si estendono su più tabelle: una singola entità business o oggetto viene caricata come due (o più) tabelle del modello, probabilmente perché i dati vengono originati da archivi dati diversi. Questo scenario può essere comune per le tabelle di tipo dimensione. Ad esempio, i dettagli master del prodotto vengono archiviati in un sistema di vendita operativo e i dettagli supplementari del prodotto vengono archiviati in un'origine diversa.
Tuttavia, è insolito correlare due tabelle di tipo fatto con una relazione uno-a-uno. Poiché entrambe le tabelle di tipo fatto devono avere la stessa dimensionalità e granularità. Inoltre, ogni tabella di tipo fatto richiede colonne univoce per consentire la creazione della relazione del modello.
Dimensioni degenerate
Quando le colonne di una tabella di tipo fatto vengono usate per filtrare o raggruppare, è possibile valutarne la disponibilità in una tabella separata. In questo modo, si separano le colonne usate per filtrare o raggruppare le colonne usate per riepilogare le righe dei fatti. Questa separazione può:
- Ridurre lo spazio di archiviazione
- Semplificare i calcoli dei modelli
- Contribuire a migliorare le prestazioni delle query
- Offrire un'esperienza più intuitiva nel riquadro Campi agli autori di report
Si consideri una tabella di vendita di origine che archivia i dettagli degli ordini di vendita in due colonne.
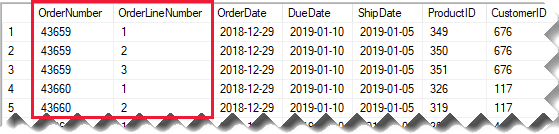
La colonna OrderNumber archivia il numero di ordine e la colonna OrderLineNumber archivia una sequenza di righe all'interno dell'ordine.
Nel diagramma del modello seguente si noti che le colonne numero di ordine e numero di riga dell'ordine non sono state caricate nella tabella Sales . I valori sono stati invece usati per creare una colonna chiave surrogata denominata SalesOrderLineID. Il valore della chiave viene calcolato moltiplicando il numero di ordine per 1000 e quindi aggiungendo il numero di riga dell'ordine.
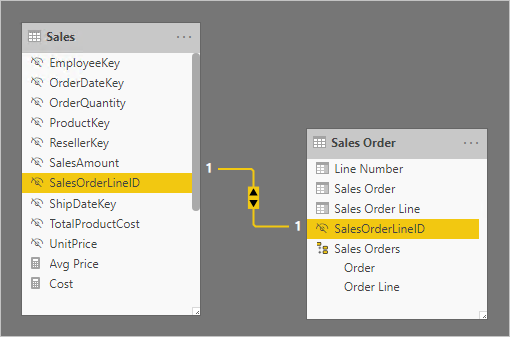
La tabella Sales Order offre un'esperienza avanzata per gli autori di report con tre colonne: Sales Order, Sales Order Line e Line Number. Include anche una gerarchia. Queste risorse di tabella supportano progettazioni di report che devono filtrare, raggruppare o eseguire il drill-down tra ordini e righe di ordine.
Poiché la tabella Sales Order deriva dai dati delle vendite, deve essere presente esattamente lo stesso numero di righe in ogni tabella. Devono inoltre essere presenti valori corrispondenti tra ogni colonna SalesOrderLineID .
I dati di riga si estendono su più tabelle
Si consideri un esempio che include due tabelle relative al tipo di dimensione uno-a-uno: Product e Product Category. Ogni tabella rappresenta i dati importati e ha una colonna SKU (Stock-Keeping Unit) contenente valori univoci.
Di seguito è riportato un diagramma di modello parziale delle due tabelle.
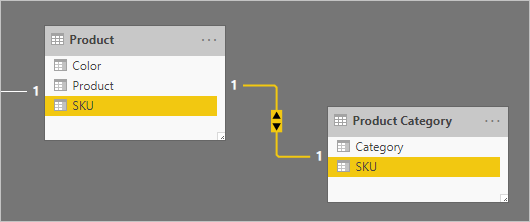
La prima tabella è denominata Product e contiene tre colonne: Color, Product e SKU. La seconda tabella è denominata Product Category e contiene due colonne: Category e SKU. Una relazione uno-a-uno correla le due colonne SKU . La relazione viene filtrata in entrambe le direzioni, che è sempre il caso di relazioni uno-a-uno.
Per descrivere il funzionamento della propagazione del filtro delle relazioni, il diagramma del modello è stato modificato per visualizzare le righe della tabella. Tutti gli esempi in questo articolo sono basati su questi dati.
Nota
Non è possibile visualizzare righe di tabella nel diagramma del modello di Power BI Desktop. Questa operazione viene eseguita in questo articolo per supportare la discussione con esempi chiari.
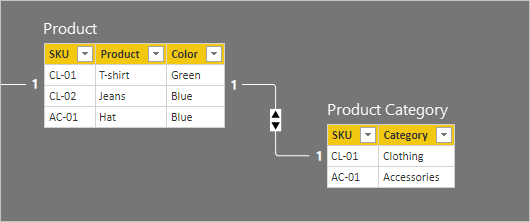
I dettagli della riga per le due tabelle sono descritti nell'elenco puntato seguente:
- La tabella Product include tre righe:
- SKU CL-01, T-shirt prodotto , Colore verde
- SKU CL-02, Product Jeans, Color Blue
- SKU AC-01, Product Hat, Color Blue
- La tabella Product Category contiene due righe:
- SKU CL-01, Category Clothing
- SKU AC-01, Accessori categoria
Si noti che la tabella Product Category non include una riga per lo SKU del prodotto CL-02. Più avanti in questo articolo verranno illustrate le conseguenze di questa riga mancante.
Nel riquadro Campi gli autori di report troveranno i campi correlati al prodotto in due tabelle: Product e Product Category.
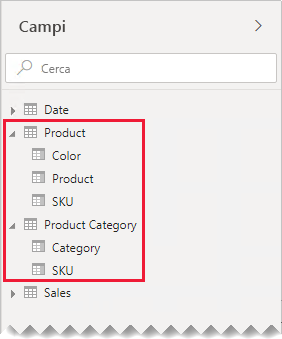
Vediamo cosa accade quando i campi di entrambe le tabelle vengono aggiunti a un oggetto visivo tabella. In questo esempio la colonna SKU viene originata dalla tabella Product .
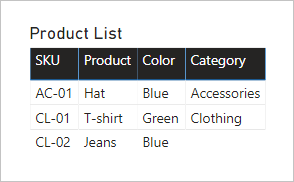
Si noti che il valore Category per product SKU CL-02 è BLANK. Perché non è presente alcuna riga nella tabella Product Category per questo prodotto.
Consigli
Quando possibile, è consigliabile evitare di creare relazioni di modello uno-a-uno quando i dati di riga si estendono su più tabelle del modello. Il motivo è che questo progetto può:
- Contribuire al riquadro Campi disordinato, elencando più tabelle del necessario
- Rendere difficile per gli autori di report trovare i campi correlati, perché vengono distribuiti in più tabelle
- Limitare la possibilità di creare gerarchie, in quanto i relativi livelli devono essere basati su colonne della stessa tabella
- Generare risultati imprevisti quando non è presente una corrispondenza completa delle righe tra le tabelle
Le raccomandazioni specifiche variano a seconda che la relazione uno-a-uno sia all'interno del gruppo di origine o del gruppo tra origini. Per altre informazioni sulla valutazione delle relazioni, vedere Relazioni tra modelli in Power BI Desktop (valutazione delle relazioni).
Relazione uno-a-uno all'interno del gruppo di origine
Quando esiste una relazione tra gruppi di origine uno-a-uno tra tabelle, è consigliabile consolidare i dati in una singola tabella del modello. Questa operazione viene eseguita unendo le query di Power Query.
I passaggi seguenti presentano una metodologia per consolidare e modellare i dati correlati uno a uno:
Merge di query: quando si combinano le due query, tenere conto della completezza dei dati in ogni query. Se una query contiene un set completo di righe ,ad esempio un elenco master, unire l'altra query con essa. Configurare la trasformazione merge per l'uso di un left outer join, ovvero il tipo di join predefinito. Questo tipo di join garantisce di mantenere tutte le righe della prima query e di integrarle con tutte le righe corrispondenti della seconda query. Espandere tutte le colonne necessarie della seconda query nella prima query.
Disabilitare il caricamento delle query: assicurarsi di disabilitare il carico della seconda query. In questo modo, il risultato non verrà caricato come tabella del modello. Questa configurazione riduce le dimensioni di archiviazione del modello di dati e semplifica l'includazione del riquadro Campi .
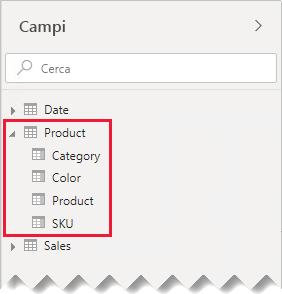
Nell'esempio gli autori di report trovano ora una singola tabella denominata Product nel riquadro Campi . Contiene tutti i campi correlati al prodotto.
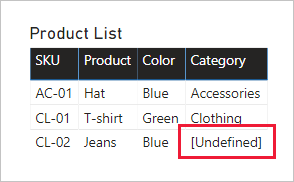
Sostituire i valori mancanti: se la seconda query contiene righe non corrispondenti, i valori NULL verranno visualizzati nelle colonne introdotte. Se appropriato, prendere in considerazione la sostituzione di valori NULL con un valore di token. La sostituzione dei valori mancanti è particolarmente importante quando gli autori di report filtrano o raggruppano in base ai valori di colonna, perché gli oggetti visivi del report possono essere visualizzati negli oggetti visivi del report.
Nell'oggetto visivo tabella seguente si noti che la categoria per lo SKU di prodotto CL-02 ora legge [Undefined]. Nella query le categorie Null sono state sostituite con questo valore di testo del token.
Creare gerarchie: se esistono relazioni tra le colonne della tabella consolidata, è consigliabile creare gerarchie. In questo modo, gli autori di report identificano rapidamente le opportunità per il drill-visivo dei report.
In questo esempio gli autori di report possono ora usare una gerarchia con due livelli: Category e Product.
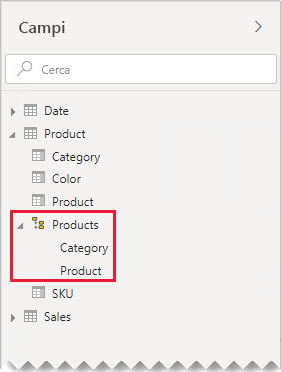
Se si preferisce come le tabelle separate consentono di organizzare i campi, è comunque consigliabile consolidare in una singola tabella. È comunque possibile organizzare i campi, ma usando le cartelle di visualizzazione.
In questo esempio, gli autori di report possono trovare il campo Categoria all'interno della cartella di visualizzazione Marketing .
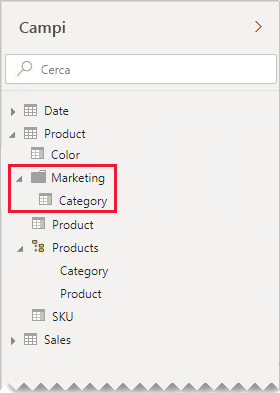
Se si decide comunque di definire relazioni uno-a-uno all'interno del gruppo di origine nel modello, quando possibile, assicurarsi che siano presenti righe corrispondenti nelle tabelle correlate. Poiché una relazione tra gruppi di origine uno-a-uno viene valutata come relazione regolare, i problemi di integrità dei dati potrebbero emergere negli oggetti visivi del report come BLANK. È possibile visualizzare un esempio di raggruppamento BLANK nel primo oggetto visivo tabella presentato in questo articolo.
Relazione uno-a-uno tra gruppi di origine
Quando esiste una relazione tra gruppi di origine uno-a-uno tra tabelle, non esiste alcuna progettazione di modelli alternativi, a meno che non si pre-consolidano i dati nelle origini dati. Power BI valuterà la relazione di modello uno-a-uno come relazione limitata. Di conseguenza, prestare attenzione a assicurarsi che siano presenti righe corrispondenti nelle tabelle correlate, perché le righe non corrispondenti verranno eliminate dai risultati della query.
Si vedrà ora cosa accade quando i campi di entrambe le tabelle vengono aggiunti a un oggetto visivo tabella e tra le tabelle esiste una relazione limitata.
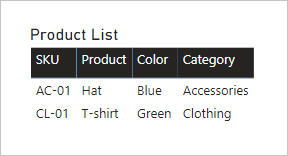
La tabella visualizza solo due righe. Sku prodotto CL-02 mancante perché nella tabella Product Category non è presente alcuna riga corrispondente.
Contenuto correlato
Per altre informazioni relative a questo articolo, vedere le risorse seguenti:
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per