Introduzione alla distribuzione di app in cluster Big Data di SQL Server
Si applica a![]() : SQL Server 2019 (15.x)
: SQL Server 2019 (15.x)
Importante
Il componente aggiuntivo per i cluster Big Data di Microsoft SQL Server 2019 verrà ritirato. Il supporto per i cluster Big Data di SQL Server 2019 terminerà il 28 febbraio 2025. Tutti gli utenti esistenti di SQL Server 2019 con Software Assurance saranno completamente supportati nella piattaforma e fino a quel momento il software continuerà a ricevere aggiornamenti cumulativi di SQL Server. Per altre informazioni, vedere il post di blog relativo all'annuncio e Opzioni per i Big Data nella piattaforma Microsoft SQL Server.
La distribuzione di applicazioni consente di distribuire applicazioni in un cluster Big Data di SQL Server fornendo interfacce per la creazione, la gestione e l'esecuzione di applicazioni. Le applicazioni distribuite in un cluster Big Data traggono vantaggio dalla potenza di calcolo del cluster e possono accedere ai dati disponibili nel cluster. In questo modo, viene aumentata la scalabilità e le prestazioni delle applicazioni nel caso in cui le applicazioni gestite si trovino nella posizione in cui risiedono i dati. I runtime per la distribuzione di applicazioni supportati nei cluster Big Data di SQL Server sono R, Python, dtexec e MLeap.
Le sezioni seguenti descrivono l'architettura e le funzionalità della distribuzione di applicazioni.
Architettura della distribuzione di applicazioni
La distribuzione di applicazioni è costituita da un controller e da gestori di runtime delle app. Quando si crea un'applicazione, viene fornito un file di specifica (spec.yaml). Questo file spec.yaml contiene tutte le informazioni necessarie al controller per distribuire correttamente l'applicazione. Di seguito è riportato un esempio di contenuti per spec.yaml:
#spec.yaml
name: add-app #name of your python script
version: v1 #version of the app
runtime: Python #the language this app uses (R or Python)
src: ./add.py #full path to the location of the app
entrypoint: add #the function that will be called upon execution
replicas: 1 #number of replicas needed
poolsize: 1 #the pool size that you need your app to scale
inputs: #input parameters that the app expects and the type
x: int
y: int
output: #output parameter the app expects and the type
result: int
Il controller esamina il runtime specificato nel file spec.yaml e chiama il gestore di runtime corrispondente. Il gestore di runtime crea quindi l'applicazione. Per prima cosa, viene creato un set di repliche Kubernetes contenente uno o più POD, ognuno dei quali contiene l'applicazione da distribuire. Il numero di POD è definito dal set di parametri replicas nel file spec.yaml per l'applicazione. Ogni pod può includere uno o più pool. Il numero di pool è definito dal set di parametri poolsize nel file spec.yaml.
Queste impostazioni determinano la quantità di richieste che la distribuzione è in grado di gestire in parallelo. Il numero massimo di richieste contemporanee è uguale alla replicas per il numero di poolsize. Se si hanno 5 repliche e 2 pool per replica, quindi, la distribuzione potrà gestire 10 richieste in parallelo. Vedere l'immagine seguente per una rappresentazione grafica di replicas e poolsize:
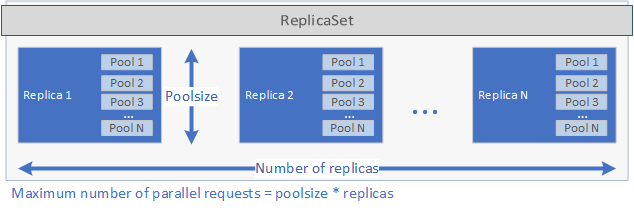
Dopo la creazione del set di repliche e l'avvio dei pod, viene creato un processo cron se nel file schedule è stato impostato un oggetto spec.yaml. Viene creato infine un servizio Kubernetes che può essere usato per gestire ed eseguire l'applicazione (vedere di seguito).
Quando viene eseguita un'applicazione, il servizio Kubernetes dell'applicazione inoltra le richieste a una replica e restituisce i risultati.
Considerazioni sulla sicurezza per la distribuzione di applicazioni in OpenShift
SQL Server 2019 CU5 garantisce il supporto per la distribuzione di cluster Big Data in Red Hat OpenShift e fornisce un modello di sicurezza aggiornato per cluster Big Data in modo che non siano più necessari contenitori con privilegi. Oltre che senza privilegi, per impostazione predefinita i contenitori vengono eseguiti come utente non ROOT per tutte le nuove distribuzioni con SQL Server 2019 CU5.
Al momento della versione CU5, il passaggio di installazione delle applicazioni distribuite con le interfacce app deploy verrà comunque eseguito come utente ROOT. Questo è necessario perché durante la configurazione vengono installati pacchetti aggiuntivi che verranno usati dall'applicazione. Altro codice utente distribuito come parte dell'applicazione verrà eseguito come utente con privilegi limitati.
Inoltre, CAP_AUDIT_WRITE è una funzionalità facoltativa necessaria per consentire la pianificazione di applicazioni SQL Server Integration Services (SSIS) con processi cron. Quando il file di specifiche YAML dell'applicazione indica una pianificazione, l'applicazione viene attivata tramite un processo cron, per cui è necessaria la funzionalità aggiuntiva. In alternativa, l'applicazione può essere attivata su richiesta con azdata app run tramite una chiamata al servizio Web, per la quale non è necessaria la funzionalità CAP_AUDIT_WRITE. Si noti che la funzionalità CAP_AUDIT_WRITE non è più necessaria per cronjob a partire dalla versione SQL Server 2019 CU8.
Nota
Il vincolo del contesto di sicurezza personalizzato nell'articolo relativo alla distribuzione di OpenShift non include questa funzionalità perché non è necessaria per una distribuzione predefinita di un cluster Big Data. Per abilitare questa funzionalità, è necessario prima di tutto aggiornare il vincolo del contesto di sicurezza personalizzato nel relativo file YAML in modo da includere CAP_AUDIT_WRITE.
...
allowedCapabilities:
- SETUID
- SETGID
- CHOWN
- SYS_PTRACE
- AUDIT_WRITE
...
Come usare la distribuzione di app all'interno di un cluster Big Data
Le due interfacce principali per la distribuzione di applicazioni sono:
- Interfaccia della riga di comando Azure Data (
azdata) - Estensione di Visual Studio Code e Azure Data Studio
Un'applicazione può essere eseguita anche mediante un servizio Web RESTful. Per altre informazioni, vedere Utilizzare applicazioni in cluster Big Data.
Scenari di distribuzione di app
La distribuzione di applicazioni consente di distribuire applicazioni in un cluster Big Data di SQL Server fornendo interfacce per la creazione, la gestione e l'esecuzione di applicazioni.
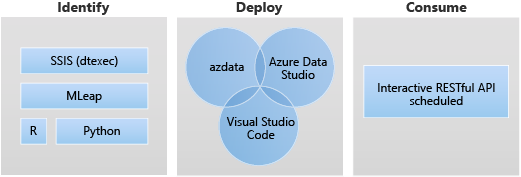
Di seguito sono elencati gli scenari di destinazione per la distribuzione di app:
- Distribuire servizi Web Python o R all'interno del cluster Big Data per gestire diversi casi d'uso, tra cui l'inferenza di Machine Learning, la gestione delle API e così via.
- Creare un endpoint di inferenza di Machine Learning usando il motore MLeap.
- Pianificare ed eseguire pacchetti da file DTSX usando l'utilità dtexec per la trasformazione e lo spostamento dei dati.
Usare il runtime Python per la distribuzione di app
Nella distribuzione di app il runtime Python per i cluster Big Data consente all'applicazione Python all'interno del cluster Big Data di affrontare diversi casi d'uso, tra cui l'inferenza di Machine Learning, la gestione delle API e altro ancora.
Il runtime Python per la distribuzione di app usa Python 3.8 nei cluster Big Data di SQL Server CU10+.
Nella distribuzione di app spec.yaml è il file in cui fornire le informazioni necessarie al controller per distribuire l'applicazione. Di seguito sono elencati i campi che è possibile specificare:
name: nome dell'applicazioneversion: versione dell'applicazione, ad esempiov1runtime: runtime per la distribuzione dell'app, che deve essere specificato comePythonsrc: percorso dell'applicazione Pythonentry point: funzione del punto di ingresso nello script src da eseguire per questa applicazione Python.
Oltre a quanto indicato sopra, è necessario specificare l'input e l'output dell'applicazione Python. In questo modo, viene generato un file spec.yaml simile al seguente:
#spec.yaml
name: add-app
version: v1
runtime: Python
src: ./add.py
entrypoint: add
replicas: 1
poolsize: 1
inputs:
x: int
y: int
output:
result: int
È possibile creare la cartella di base e la struttura di file necessarie per distribuire un'app Python in esecuzione in cluster Big Data:
azdata app init --template python --name hello-py --version v1
Per i passaggi successivi, vedere Come distribuire un'app in cluster Big Data di SQL Server.
Limitazioni del runtime Python per la distribuzione di app
Il runtime Python per la distribuzione di app non supporta lo scenario di pianificazione. Quando l'app Python è stata distribuita ed è in esecuzione nel cluster Big Data, viene configurato un endpoint RESTful per l'ascolto delle richieste in ingresso.
Usare il runtime R per la distribuzione di app
Nella distribuzione di app il runtime Python per cluster Big Data consente all'applicazione R all'interno del cluster Big Data di affrontare diversi casi d'uso, tra cui l'inferenza di Machine Learning, la gestione delle API e altro ancora.
Il runtime R per la distribuzione di app usa Microsoft R Open (MRO) versione 3.5.2 in cluster Big Data di SQL Server CU10+.
Come si usa?
Nella distribuzione di app spec.yaml è il file in cui fornire le informazioni necessarie al controller per distribuire l'applicazione. Di seguito sono elencati i campi che è possibile specificare:
name: nome dell'applicazioneversion: versione dell'applicazione, ad esempiov1runtime: runtime per la distribuzione dell'app, che deve essere specificato comeRsrc: percorso dell'applicazione Rentry point: punto di ingresso per eseguire questa applicazione R
Oltre a quanto indicato sopra, è necessario specificare l'input e l'output dell'applicazione R. In questo modo, viene generato un file spec.yaml simile al seguente:
#spec.yaml
name: roll-dice
version: v1
runtime: R
src: ./roll-dice.R
entrypoint: rollEm
replicas: 1
poolsize: 1
inputs:
x: integer
output:
result: data.fram
È possibile creare la cartella di base e la struttura di file necessarie per distribuire una nuova applicazione R usando il comando seguente:
azdata app init --template r --name hello-r --version v1
Per i passaggi successivi, vedere Come distribuire un'app in cluster Big Data di SQL Server.
Limitazioni del runtime R
Queste limitazioni sono allineate alla rete di applicazioni Microsoft R, ritirata il 1° luglio 2023. Per altre informazioni e soluzioni alternative, vedere Ritiro della rete di applicazioni Microsoft R.
Uso del runtime dtexec per la distribuzione di app
Nella distribuzione di app l'utilità dtexec integrata del runtime per cluster Big Data proviene da SSIS su Linux (mssql-server-is). La distribuzione di app usa l'utilità dtexec per caricare pacchetti da file *.dtsx. Supporta l'esecuzione di pacchetti SSIS in una pianificazione in stile cron o su richiesta tramite richieste di servizi Web.
Questa funzionalità usa /opt/ssis/bin/dtexec /FILE di Integration Services su Linux per SQL Server 2019. Supporta il formato DTSX per Integration Services su Linux per SQL Server 2019 (mssql-server-is 15.0.2). Per altre informazioni sull'utilità dtexec, vedere Utilità dtexec.
Nella distribuzione di app spec.yaml è il file in cui fornire le informazioni necessarie al controller per distribuire l'applicazione. Di seguito sono elencati i campi che è possibile specificare:
name: elementonamedell'applicazioneversion: versione dell'applicazione, ad esempiov1runtime: runtime per la distribuzione dell'app per eseguire l'utilità dtexec, che deve essere specificato comeSSISentrypoint: specificare un punto di ingresso, in genere il file DTSX in questo caso.options: specificare opzioni aggiuntive per/opt/ssis/bin/dtexec /FILE. Ad esempio, per connettersi a un database con una stringa di connessione, verrebbe usato il modello seguente:/REP V /CONN "sqldatabasename"\;"\"Data Source=xx;User ID=xx;Password=xx\""Per informazioni dettagliate sulla sintassi, vedere Utilità dtexec.
schedule: specificare la frequenza di esecuzione del processo. Ad esempio, quando si usa un'espressione cron per fornire questo valore, la frequenza viene specificata come "*/1 * * * *", a indicare che il processo viene eseguito una volta al minuto.
È possibile creare la cartella di base e la struttura di file necessarie per distribuire una nuova applicazione SSIS usando il comando seguente:
azdata app init --name hello-is –version v1 --template ssis
In questo modo, viene generato un file spec.yaml simile al seguente:
#spec.yaml
entrypoint: ./hello.dtsx
name: hello-is
options: /REP V
poolsize: 2
replicas: 2
runtime: SSIS
schedule: '*/2 * * * *'
version: v1
L'esempio crea anche un pacchetto hello.dtsx di esempio.
Tutti i file dell'app si trovano nella stessa directory di spec.yaml. spec.yaml deve trovarsi al livello radice della directory del codice sorgente dell'app che include il file DTSX.
Per i passaggi successivi, vedere Come distribuire un'app in cluster Big Data di SQL Server.
Limitazioni del runtime dell'utilità dtexec
Tutti i problemi noti e le limitazioni per SQL Server Integration Services (SSIS) su Linux sono applicabili ai cluster Big Data di SQL Server. Per altre informazioni, vedere Limitazioni e problemi noti per SSIS su Linux.
Uso del runtime MLeap per la distribuzione di app
Il runtime MLeap per la distribuzione di app supporta MLeap Serving v0.13.0.
Nella distribuzione di app spec.yaml è il file in cui fornire le informazioni necessarie al controller per distribuire l'applicazione. Di seguito sono elencati i campi che è possibile specificare:
name: nome dell'applicazioneversion: versione dell'applicazione, ad esempiov1runtime: runtime per la distribuzione dell'app, che deve essere specificato comeMleap
Oltre a quanto indicato sopra, è necessario specificare l'elemento bundleFileName dell'applicazione MLeap. In questo modo, viene generato un file spec.yaml simile al seguente:
#spec.yaml
name: mleap-census
version: v1
runtime: Mleap
bundleFileName: census-bundle.zip
replicas: 1
È possibile creare la cartella di base e la struttura di file necessarie per distribuire una nuova applicazione MLeap usando il comando seguente:
azdata app init --template mleap --name hello-mleap --version v1
Per i passaggi successivi, vedere Come distribuire un'app in cluster Big Data di SQL Server.
Limitazioni del runtime MLeap
Le limitazioni sono allineate alla visione del progetto open source MLeap Combust in GitHub.
Passaggi successivi
Per altre informazioni su come creare ed eseguire applicazioni in cluster Big Data di SQL Server, vedere gli argomenti seguenti:
- Distribuire applicazioni con azdata
- Distribuire applicazioni usando l'estensione per la distribuzione di app
- Utilizzare applicazioni in cluster Big Data
Per altre informazioni sui cluster Big Data di SQL Server, vedere l'articolo di panoramica seguente:
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per