Distribuire un cluster Big Data di SQL Server con disponibilità elevata
Si applica a![]() : SQL Server 2019 (15.x)
: SQL Server 2019 (15.x)
Importante
Il componente aggiuntivo per i cluster Big Data di Microsoft SQL Server 2019 verrà ritirato. Il supporto per i cluster Big Data di SQL Server 2019 terminerà il 28 febbraio 2025. Tutti gli utenti esistenti di SQL Server 2019 con Software Assurance saranno completamente supportati nella piattaforma e fino a quel momento il software continuerà a ricevere aggiornamenti cumulativi di SQL Server. Per altre informazioni, vedere il post di blog relativo all'annuncio e Opzioni per i Big Data nella piattaforma Microsoft SQL Server.
Poiché i cluster Big Data di SQL Server si trovano in Kubernetes come applicazioni in contenitori e usano funzionalità come i set con stato e l'archiviazione permanente, questa infrastruttura include meccanismi predefiniti di monitoraggio dello stato, rilevamento degli errori e failover sfruttati dai componenti del cluster per mantenere l'integrità del servizio. Per una maggiore affidabilità, è anche possibile configurare l'istanza master di SQL Server e/o il nodo NameNode di HDFS e i servizi condivisi di Spark per la distribuzione con repliche aggiuntive in una configurazione a disponibilità elevata. Il monitoraggio, il rilevamento degli errori e il failover automatico vengono gestiti dal servizio di gestione del cluster Big Data, ovvero il servizio di controllo. Questo servizio opera senza l'intervento dell'utente, dall'impostazione del gruppo di disponibilità, configurando gli endpoint di mirroring dei database per l'aggiunta dei database al gruppo di disponibilità o per il coordinamento del failover e dell'aggiornamento.
La figura seguente mostra il modo in cui un gruppo di disponibilità viene distribuito in un cluster Big Data di SQL Server:
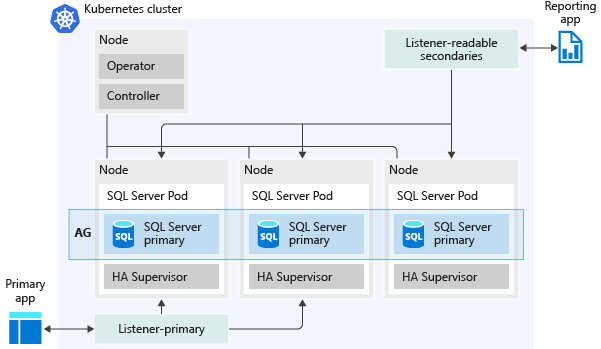
Ecco alcune delle funzionalità offerte dai gruppi di disponibilità:
Se le impostazioni di disponibilità elevata sono specificate nel file di configurazione della distribuzione, viene creato un unico gruppo di disponibilità denominato
containedag. Per impostazione predefinita,containedagè costituito da tre repliche, inclusa quella primaria. Tutte le operazioni CRUD per il gruppo di disponibilità vengono gestite internamente, inclusa la creazione del gruppo di disponibilità o l'aggiunta di repliche al gruppo di disponibilità creato. Non è possibile creare gruppi di disponibilità aggiuntivi nell'istanza master di SQL Server in un cluster Big Data.Tutti i database vengono aggiunti automaticamente al gruppo di disponibilità, inclusi tutti i database utente e di sistema come
masteremsdb. Questa funzionalità offre una vista a singolo sistema di tutte le repliche del gruppo di disponibilità. Vengono usati database modello aggiuntivi,model_replicatedmasteremodel_msdb, per eseguire l'inizializzazione della parte replicata dei database di sistema. Oltre a questi database, sarà possibile osservare i databasecontainedag_masterecontainedag_msdbse ci si connette direttamente all'istanza. I databasecontainedagrappresentano i databasemasteremsdball'interno del gruppo di disponibilità.Importante
I database creati nell'istanza come risultato di un flusso di lavoro, ad esempio il collegamento di un database, non vengono aggiunti automaticamente al gruppo di disponibilità. Gli amministratori dei cluster Big Data di SQL Server dovranno eseguire questa operazione manualmente. Per informazioni su come abilitare un endpoint temporaneo per il database master dell'istanza di SQL Server, vedere Connettersi all'istanza di SQL Server. Prima di SQL Server 2019 CU2 i database creati come risultato di un'istruzione RESTORE hanno lo stesso comportamento e i database devono essere aggiunti manualmente al gruppo di disponibilità indipendente.
I database di configurazione PolyBase non sono inclusi nel gruppo di disponibilità perché contengono metadati a livello di istanza specifici di ogni replica.
Viene effettuato il provisioning automatico di un endpoint esterno per la connessione ai database all'interno del gruppo di disponibilità. Questo endpoint
master-svc-externalha il ruolo di listener del gruppo di disponibilità.Viene effettuato il provisioning di un secondo endpoint esterno per le connessioni di sola lettura alle repliche secondarie per aumentare il numero di istanze per i carichi di lavoro di lettura.
Distribuzione
Per distribuire l'istanza master di SQL Server in un gruppo di disponibilità:
- Abilitare la funzionalità
hadr - Specificare il numero di repliche per il gruppo di disponibilità (il valore minimo è 3)
- Configurare i dettagli del secondo endpoint esterno per le connessioni alle repliche secondarie di sola lettura
Per iniziare a personalizzare il cluster Big Data, è possibile usare il profilo di configurazione predefinito aks-dev-test-ha o kubeadm-prod. Questi profili includono le impostazioni necessarie per le risorse per cui è possibile configurare la disponibilità elevata aggiuntiva. Ad esempio, di seguito è riportata una sezione del file di configurazione bdc.json pertinente per l'abilitazione dei gruppi di disponibilità per l'istanza master di SQL Server.
{
...
"spec": {
"type": "Master",
"replicas": 3,
"endpoints": [
{
"name": "Master",
"serviceType": "LoadBalancer",
"port": 31433
},
{
"name": "MasterSecondary",
"serviceType": "LoadBalancer",
"port": 31436
}
],
"settings": {
"sql": {
"hadr.enabled": "true"
}
}
}
...
}
I passaggi seguenti mostrano un esempio di come iniziare dal profilo aks-dev-test-ha e personalizzare la configurazione della distribuzione del cluster Big Data. A una distribuzione in un cluster kubeadm si applicano passaggi simili, ma assicurarsi di usare NodePort per serviceType nella sezione endpoints.
Clonare il profilo di destinazione
azdata bdc config init --source aks-dev-test-ha --target custom-aks-haSe necessario, è possibile apportare qualsiasi modifica al profilo personalizzato.
Iniziare a distribuire il cluster usando il profilo di configurazione del cluster creato sopra
azdata bdc create --config-profile custom-aks-ha --accept-eula yes
Connettersi ai database di SQL Server nel gruppo di disponibilità
A seconda del tipo di carico di lavoro che si vuole eseguire sull'istanza master di SQL Server, è possibile connettersi al database primario per i carichi di lavoro di lettura/scrittura o ai database nelle repliche secondarie per i carichi di lavoro di tipo di sola lettura. Di seguito viene fornita una descrizione a grandi linee di ogni tipo di connessione:
Connessione ai database nella replica primaria
Per le connessioni alla replica primaria, usare l'endpoint sql-server-master. Questo endpoint è anche il listener per il gruppo di disponibilità. Quando si usa questo endpoint, tutte le connessioni avvengono nel contesto dei database all'interno del gruppo di disponibilità. Ad esempio, una connessione predefinita che usa questo endpoint comporterà la connessione al database master all'interno del gruppo di disponibilità, non al database master dell'istanza di SQL Server. Eseguire questo comando per trovare l'endpoint:
azdata bdc endpoint list -e sql-server-master -o table
Description Endpoint Name Protocol
------------------------------------ ------------------- ----------------- ----------
SQL Server Master Instance Front-End 11.11.111.111,11111 sql-server-master tds
Nota
Possono verificarsi eventi di failover durante un'esecuzione di query distribuite che accede ai dati da origini dati remote come HDFS o il pool di dati. Come procedura consigliata, le applicazioni devono essere progettate in modo da includere una logica di ripetizione dei tentativi di connessione in caso di disconnessione causata dal failover.
Connessione ai database nelle repliche secondarie
Per le connessioni di sola lettura ai database nelle repliche secondarie, usare l'endpoint sql-server-master-readonly. Questo endpoint opera come un servizio di bilanciamento del carico su tutte le repliche secondarie. Quando si usa questo endpoint, tutte le connessioni avvengono nel contesto dei database all'interno del gruppo di disponibilità. Ad esempio, una connessione predefinita che usa questo endpoint comporterà la connessione al database master all'interno del gruppo di disponibilità, non al database master dell'istanza di SQL Server.
azdata bdc endpoint list -e sql-server-master-readonly -o table
Description Endpoint Name Protocol
--------------------------------------------- ------------------ -------------------------- ----------
SQL Server Master Readable Secondary Replicas 11.11.111.11,11111 sql-server-master-readonly tds
Connettersi all'istanza di SQL Server
Per alcune operazioni come l'impostazione delle configurazioni a livello di server o l'aggiunta manuale di un database al gruppo di disponibilità, è necessario connettersi all'istanza di SQL Server. Nelle versioni precedenti a SQL Server 2019 CU2 le operazioni come sp_configure, RESTORE DATABASE o qualsiasi DLL dei gruppi di disponibilità richiedono questo tipo di connessione. Per impostazione predefinita, il cluster Big Data non include un endpoint che permette la connessione all'istanza ed è necessario esporre l'endpoint manualmente.
Importante
L'endpoint esposto per le connessioni all'istanza di SQL Server supporta solo l'autenticazione SQL, anche nei cluster in cui è abilitato Active Directory. Per impostazione predefinita, durante la distribuzione di un cluster Big Data l'account di accesso sa è disabilitato e viene effettuato il provisioning di un nuovo account di accesso sysadmin in base ai valori forniti in fase di distribuzione per le variabili di ambiente AZDATA_USERNAME e AZDATA_PASSWORD.
Importante
Il DDL del gruppo di disponibilità contenuto è autogestito in modo esclusivo in BDC. Qualsiasi tentativo (utente esterno) di eliminare la disponibilità contenuta o l'endpoint del mirroring del database non è supportato e può causare uno stato BDC non recuperabile.
Ecco un esempio che mostra come esporre questo endpoint e quindi aggiungere il database creato con un flusso di lavoro di ripristino al gruppo di disponibilità. Si applicano istruzioni simili anche alla configurazione di una connessione all'istanza master di SQL Server quando si vuole modificare le configurazioni del server con sp_configure.
Nota
A partire da SQL Server 2019 CU2 i database creati come risultato di un flusso di lavoro di ripristino vengono aggiunti automaticamente al gruppo di disponibilità incluso.
Determinare il pod che ospita la replica primaria connettendosi all'endpoint
sql-server-mastered eseguire:SELECT @@SERVERNAMEEsporre l'endpoint esterno creando un nuovo servizio Kubernetes
Per un cluster
kubeadmeseguire il comando seguente. SostituirepodNamecon il nome del server restituito nel passaggio precedente,serviceNamecon il nome preferito per il servizio Kubernetes creato enamespaceName* con il nome del cluster Big Data.kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortPer un cluster del servizio Azure Kubernetes eseguire lo stesso comando, ad eccezione del fatto che il tipo del servizio creato sarà
LoadBalancer. Ad esempio:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancerEcco un esempio di questo comando eseguito sul servizio Azure Kubernetes, in cui il pod che ospita la replica primaria è
master-0:kubectl -n mssql-cluster expose pod master-0 --port=1533 --name=master-sql-0 --type=LoadBalancerOttenere l'indirizzo IP del servizio Kubernetes creato:
kubectl get services -n <namespaceName>
Importante
Come procedura consigliata, eseguire la pulizia eliminando il servizio Kubernetes creato in precedenza tramite questo comando:
kubectl delete svc master-sql-0 -n mssql-cluster
Aggiungere il database al gruppo di disponibilità.
Per aggiungerlo al gruppo di disponibilità, il database deve essere eseguito come modello di recupero con registrazione completa ed è necessario acquisire un backup del log. Usare l'indirizzo IP del servizio Kubernetes creato in precedenza e connettersi all'istanza di SQL Server, quindi eseguire le istruzioni T-SQL come mostrato di seguito.
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>L'esempio seguente aggiunge un database denominato
salesche è stato ripristinato nell'istanza:ALTER DATABASE sales SET RECOVERY FULL; BACKUP DATABASE sales TO DISK='/var/opt/mssql/data/sales.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE sales
Limitazioni note
Di seguito sono elencate le limitazioni e i problemi noti relativi ai gruppi di disponibilità contenuti per l'istanza master di SQL Server nel cluster Big Data:
- La configurazione a disponibilità elevata deve essere creata quando viene distribuito il cluster Big Data. Non è possibile abilitare la configurazione a disponibilità elevata con i gruppi di disponibilità dopo la distribuzione. Attualmente l'unica configurazione abilitata è quella per le repliche con commit sincrono.
Avviso
L'aggiornamento della modalità di sincronizzazione al commit asincrono per tutte le repliche nel commit del quorum darà origine a una configurazione non valida per la disponibilità elevata. L'esecuzione in questa configurazione può comportare un rischio di perdita di dati, perché in caso di eventi di errore che interessano la replica primaria non viene attivato un failover automatico e l'utente deve accettare il rischio di perdita di dati al momento dell'emissione del failover manuale.
- Per eseguire correttamente il ripristino di un database abilitato per la funzionalità Transparent Data Encryption da un backup creato in un altro server, è necessario assicurarsi che i certificati richiesti vengano ripristinati sia nell'istanza master di SQL Server che nel master del gruppo di disponibilità contenuto. Vedere qui per un esempio di come eseguire il backup e il ripristino dei certificati.
- Per alcune operazioni come l'esecuzione delle impostazioni di configurazione del server con
sp_configure, è necessaria una connessione al databasemasterdell'istanza di SQL Server, non al databasemasterdel gruppo di disponibilità. Non è possibile usare l'endpoint primario corrispondente. Seguire le istruzioni per esporre un endpoint e connettersi all'istanza di SQL Server ed eseguiresp_configure. È possibile usare l'autenticazione SQL solo quando si espone manualmente l'endpoint per la connessione al databasemasterdell'istanza di SQL Server. - Mentre il database msdb contenuto è incluso nel gruppo di disponibilità e i processi di SQL Agent vengono replicati, i processi vengono eseguiti solo in base alla pianificazione nella replica primaria.
- La funzionalità di replica non è supportata per i gruppi di disponibilità contenuti. La parte delle istanze di SQL Server di un gruppo di disponibilità indipendente non può svolgere la funzione di database di distribuzione o server di pubblicazione, a livello di istanza o a livello di gruppo di disponibilità.
- L'aggiunta di gruppi di file durante la creazione del database non è supportata. Come soluzione alternativa, è possibile creare prima il database e quindi eseguire un'istruzione ALTER DATABASE per aggiungere qualsiasi gruppo di file.
- Nelle versioni precedenti a SQL Server 2019 CU2 i database creati come risultato di flussi di lavoro diversi da
CREATE DATABASEeRESTORE DATABASE, comeCREATE DATABASE FROM SNAPSHOT, non vengono aggiunti automaticamente al gruppo di disponibilità. Connettersi all'istanza e aggiungere manualmente il database al gruppo di disponibilità. - Service Broker e Posta elettronica database non sono attualmente supportati nei cluster Big Data distribuiti con disponibilità elevata.
Passaggi successivi
- Per altre informazioni sull'uso di file di configurazione in distribuzioni di cluster Big Data, vedere Come distribuire cluster Big Data di SQL Server in Kubernetes.
- Per altre informazioni sulla funzionalità Gruppi di disponibilità per SQL Server, vedere Panoramica di Gruppi di disponibilità Always On (SQL Server).
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per