Feature Pack di Azure per Integration Services (SSIS)
Si applica a:![]() SQL Server
SQL Server![]() SSIS Integration Runtime in Azure Data Factory
SSIS Integration Runtime in Azure Data Factory
Il Feature Pack di SQL Server Integration Services (SSIS) per Azure è un'estensione che fornisce i componenti elencati in questa pagina per consentire a SSIS di connettersi ai servizi Azure, trasferire i dati tra Azure e le origini dati locali ed elaborare i dati archiviati in Azure.
 Scaricare il Feature Pack di SSIS per Azure
Scaricare il Feature Pack di SSIS per Azure
- Per SQL Server 2022: Microsoft SQL Server 2022 Integration Services Feature Pack per Azure
- Per SQL Server 2019 - Microsoft SQL Server 2019 Integration Services Feature Pack per Azure
- Per SQL Server 2017 - Microsoft SQL Server 2017 Integration Services Feature Pack per Azure
- Per SQL Server 2016 - Microsoft SQL Server 2016 Integration Services Feature Pack per Azure
- Per SQL Server 2014 - Microsoft SQL Server 2014 Integration Services Feature Pack per Azure
- Per SQL Server 2012 - Microsoft SQL Server 2012 Integration Services Feature Pack per Azure
Le pagine di download includono anche informazioni sui prerequisiti. Assicurarsi di installare SQL Server prima di installare il Feature Pack di Azure in un server. In caso contrario i componenti del Feature Pack potrebbero non essere disponibili quando si distribuiscono pacchetti al database del catalogo SSIS (SSISDB) nel server.
Componenti del Feature Pack
Gestioni connessioni
Attività
Componenti del flusso di dati
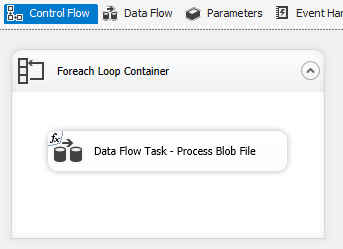
Blob di Azure, Azure Data Lake Store ed Enumeratore file di Data Lake Store Gen2. Vedere Contenitore Ciclo Foreach.
Usare TLS 1.2
La versione di TLS usata dal Feature Pack di Azure dipende dalle impostazioni di sistema di .NET Framework.
Per usare TLS 1.2, aggiungere un valore REG_DWORD denominato SchUseStrongCrypto con dati 1 nelle due chiavi del Registro di sistema seguenti.
HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Microsoft\.NETFramework\v4.0.30319HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\.NETFramework\v4.0.30319
Dipendenza da Java
Java è necessario per usare i formati di file ORC/Parquet con i connettori di File flessibili/Azure Data Lake Store.
L'architettura (a 32 o a 64 bit) della build di Java deve corrispondere a quella del runtime di SSIS da usare.
Sono state sottoposte a test le build di Java seguenti.
Configurare OpenJDK di Zulu
- Scaricare ed estrarre il pacchetto di installazione con estensione zip.
- Dal prompt dei comandi, eseguire
sysdm.cpl. - Nella scheda Avanzate selezionare Variabili di ambiente.
- Nella sezione Variabili di sistema selezionare Nuova.
- Immettere
JAVA_HOMEin Nome variabile. - Selezionare Sfoglia directory, passare alla cartella estratta e selezionare la sottocartella
jre. Selezionare quindi OK e Valore variabile verrà popolato automaticamente. - Selezionare OK per chiudere la finestra di dialogo Nuova variabile di sistema.
- Selezionare OK per chiudere la finestra di dialogo Variabili di ambiente.
- Selezionare OK per chiudere la finestra di dialogo Proprietà del sistema.
Suggerimento
Se si usa il formato Parquet e si verifica l'errore "An error occurred when invoking java, message: java.lang.OutOfMemoryError:Java heap space" (Errore durante la chiamata di Java, messaggio: java.lang.OutOfMemoryError: spazio dell'heap di Java), è possibile aggiungere una variabile di ambiente _JAVA_OPTIONS per modificare le dimensioni dell'heap min/max per JVM.
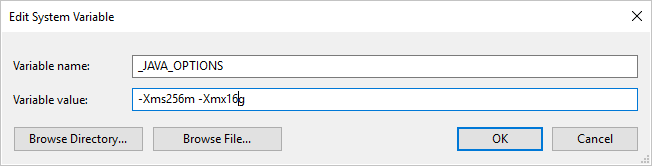
Esempio: impostare la variabile _JAVA_OPTIONS con il valore -Xms256m -Xmx16g. Il flag Xms specifica il pool di allocazione della memoria iniziale per Java Virtual Machine (JVM), mentre Xmx specifica il pool di allocazione della memoria massima. JVM verrà quindi avviato con una quantità di memoria pari a Xms e potrà usare una quantità massima di memoria pari a Xmx. Per impostazione predefinita, viene usata una quantità di memoria minima pari a 64 MB e una quantità di memoria massima pari a 1 GB.
Configurare OpenJDK di Zulu in Azure-SSIS Integration Runtime
Questa operazione deve essere eseguita tramite l'interfaccia di configurazione personalizzata per Azure-SSIS Integration Runtime.
Si supponga di usare zulu8.33.0.1-jdk8.0.192-win_x64.zip.
Il contenitore BLOB può essere organizzato come indicato di seguito.
main.cmd
install_openjdk.ps1
zulu8.33.0.1-jdk8.0.192-win_x64.zip
Come punto di ingresso, main.cmd attiva l'esecuzione dello script di PowerShell install_openjdk.ps1 che a sua volta estrae zulu8.33.0.1-jdk8.0.192-win_x64.zip e imposta JAVA_HOME di conseguenza.
main.cmd
powershell.exe -file install_openjdk.ps1
Suggerimento
Se si usa il formato Parquet e si verifica l'errore "An error occurred when invoking java, message: java.lang.OutOfMemoryError:Java heap space" (Errore durante la chiamata di Java, messaggio: java.lang.OutOfMemoryError: spazio dell'heap di Java), è possibile aggiungere comando in main.cmd per modificare le dimensioni dell'heap min/max per JVM. Esempio:
setx /M _JAVA_OPTIONS "-Xms256m -Xmx16g"
Il flag Xms specifica il pool di allocazione della memoria iniziale per Java Virtual Machine (JVM), mentre Xmx specifica il pool di allocazione della memoria massima. JVM verrà quindi avviato con una quantità di memoria pari a Xms e potrà usare una quantità massima di memoria pari a Xmx. Per impostazione predefinita, viene usata una quantità di memoria minima pari a 64 MB e una quantità di memoria massima pari a 1 GB.
install_openjdk.ps1
Expand-Archive zulu8.33.0.1-jdk8.0.192-win_x64.zip -DestinationPath C:\
[Environment]::SetEnvironmentVariable("JAVA_HOME", "C:\zulu8.33.0.1-jdk8.0.192-win_x64\jre", "Machine")
Configurare Oracle Java SE Runtime Environment
- Scaricare ed eseguire il programma di installazione con estensione exe.
- Seguire le istruzioni del programma di installazione per completare l'installazione.
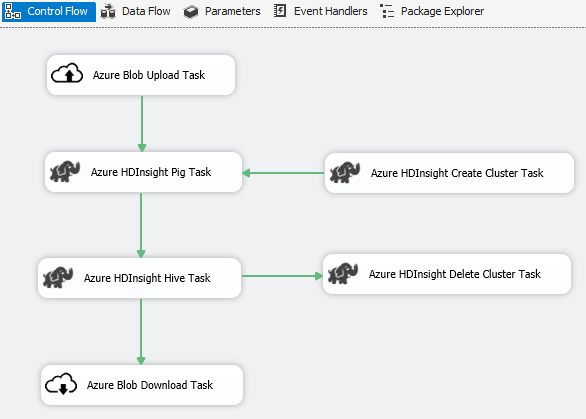
Scenario: Elaborazione di Big data
Usare il connettore di Azure per completare l'elaborazione di Big Data:
Usare l'attività di caricamento BLOB di Azure per caricare i dati di input nell'archivio BLOB di Azure.
Usare l'attività di creazione cluster di Azure HDInsight per creare un cluster di Azure HDInsight. Questo passaggio è facoltativo se si vuole usare un cluster personale.
Usare l'attività Hive o Pig di Azure HDInsight per richiamare un processo Pig o Hive nel cluster di Azure HDInsight.
Usare l'attività di eliminazione cluster di Azure HDInsight per eliminare il cluster di HDInsight dopo l'uso se è stato creato un cluster di HDInsight su richiesta nel passaggio 2.
Usare l'attività di download BLOB di Azure HDInsight per scaricare i dati di output Pig/Hive dall'archivio BLOB di Azure.
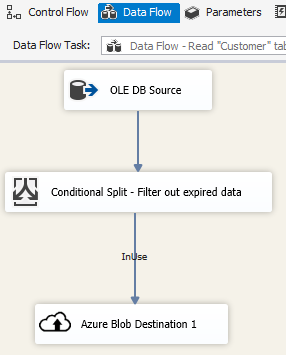
Scenario: Gestione di dati nel cloud
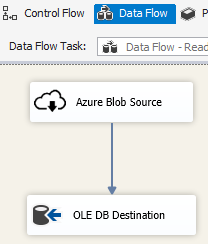
Usare la destinazione BLOB di Azure in un pacchetto SSIS per scrivere i dati di output in un archivio BLOB di Azure oppure usare l'origine BLOB di Azure per leggere i dati da un archivio BLOB di Azure.
Usare il contenitore Ciclo Foreach con l'enumeratore BLOB di Azure per elaborare i dati in più file BLOB.
Note sulla versione
Versione 1.21.0
Miglioramenti
- Log4j aggiornato dalla versione 1.2.17 alla versione 2.17.1.
Versione 1.20.0
Miglioramenti
- Aggiornamento della versione di .NET Framework da 4.6 a 4.7.2.
- "Attività di caricamento Azure SQL DW" rinominata in "Attività Azure Synapse Analytics".
Correzioni di bug
- Quando si accede all'archiviazione BLOB di Azure e il computer che esegue SSIS si trova in impostazioni locali non en-US, l'esecuzione del pacchetto avrà esito negativo con il messaggio di errore "Stringa non riconosciuta come valore DateTime valido".
- Per la gestione connessione di Archiviazione di Azure il segreto è obbligatorio (e inutilizzato) anche quando l'identità gestita di Data Factory viene usata per l'autenticazione.
Versione 1.19.0
Miglioramenti
- Aggiunta del supporto per l'autenticazione della firma di accesso condiviso alla gestione connessione di Archiviazione di Azure.
Versione 1.18.0
Miglioramenti
- Per l'attività File flessibile, sono stati aggiunti tre miglioramenti: (1) supporto dei caratteri jolly per le operazioni di copia/eliminazione; (2) l'utente può abilitare o disabilitare la ricerca ricorsiva per l'operazione di eliminazione; e (3) il nome file della destinazione per l'operazione di copia può essere vuoto per mantenere il nome del file di origine.
Versione 1.17.0
Si tratta di una versione di hotfix rilasciata solo per SQL Server 2019.
Correzioni di bug
- Quando si esegue in Visual Studio 2019 con destinazione SQL Server 2019, l'attività dei file flessibili/origine/destinazione potrebbe non riuscire con il messaggio di errore
Attempted to access an element as a type incompatible with the array. - Quando si esegue in Visual Studio 2019 con destinazione SQL Server 2019, origine/destinazione file flessibili con il formato ORC/Parquet potrebbe non riuscire con il messaggio di errore
Microsoft.DataTransfer.Common.Shared.HybridDeliveryException: An unknown error occurred. JNI.JavaExceptionCheckException.
Versione 1.16.0
Correzioni di bug
- In determinati casi, l'esecuzione del pacchetto riporta "Errore: Non è stato possibile caricare il file o l'assembly 'Newtonsoft.Json, Version=11.0.0.0, Culture=neutral, PublicKeyToken=30ad4fe6b2a6aeed' o una delle relative dipendenze."
Versione 1.15.0
Miglioramenti
- Aggiunta dell'operazione di eliminazione cartella/file ad Attività File flessibili
- Aggiunta della funzione di conversione di un tipo di dati esterno/output in Origine di File flessibili
Correzioni di bug
- In alcuni casi, la connessione di test per Data Lake Storage Gen2 non funziona con il messaggio di errore "Tentativo di accedere a un elemento come tipo incompatibile con la matrice"
- Ripristino del supporto per l'emulatore di archiviazione di Azure
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per