Gruppi di disponibilità per SQL Server in Linux
Si applica a:![]() SQL Server - Linux
SQL Server - Linux
Questo articolo descrive le caratteristiche dei gruppi di disponibilità nelle installazioni di SQL Server basate su Linux. Illustra inoltre le differenze tra i gruppi di disponibilità basati su WSFC (Windows Server Failover Cluster) e quelli basati su Linux. Per le nozioni di base sui gruppi di disponibilità, vedere la documentazione relativa a Windows, poiché tali gruppi funzionano allo stesso modo in Windows e Linux, fatta eccezione per il cluster WSFC.
Nota
Nei gruppi di disponibilità che non usano Windows Server Failover Clustering (WSFC), ad esempio gruppi di disponibilità con scalabilità in lettura o gruppi di disponibilità in Linux, le colonne nelle DMV dei gruppi di disponibilità correlate al cluster potrebbero visualizzare i dati relativi a un cluster predefinito interno. Queste colonne sono solo per uso interno e possono essere ignorate.
Da un punto di vista di alto livello, i gruppi di disponibilità di SQL Server in Linux sono equivalenti a quelli usati nelle implementazioni basate su WSFC. In altre parole, non vi sono differenze in termini di limitazioni e funzionalità, con alcune eccezioni. Di seguito sono elencate le principali differenze:
- Microsoft Distributed Transaction Coordinator (DTC) è supportato in Linux a partire da SQL Server 2017 CU16. Tuttavia, DTC non è ancora supportato nei gruppi di disponibilità in Linux. Se le applicazioni richiedono l'uso di transazioni distribuite ed è necessario un gruppo di disponibilità, distribuire SQL Server in Windows.
- Le distribuzioni basate su Linux che richiedono disponibilità elevata usano Pacemaker per il clustering anziché un cluster WSFC.
- Diversamente dalla maggior parte delle configurazioni per i gruppi di disponibilità in Windows, ad eccezione dello scenario di un cluster di gruppi di lavoro, Pacemaker non richiede mai Active Directory Domain Services (AD DS).
- La modalità di failover di un gruppo di disponibilità da un nodo a un altro in Linux è diversa rispetto a quella adottata in Windows.
- In Linux determinate impostazioni, come
required_synchronized_secondaries_to_commit, possono essere modificate solo tramite Pacemaker, mentre un'installazione basata su WSFC usa Transact-SQL.
Numero di repliche e nodi del cluster
Nell’edizione SQL Server Standard, un gruppo di disponibilità può avere in totale due repliche, una primaria e una secondaria, che possono essere usate solo a scopo di disponibilità. Non è possibile usarle per altri scopi, ad esempio per le query leggibili. Nell’edizione SQL Server Enterprise, un gruppo di disponibilità può avere in totale un massimo di nove repliche, una primaria e fino a otto secondarie, di cui tre al massimo (inclusa quella primaria) possono essere sincrone. Se si usa un cluster sottostante, possono essere presenti al massimo 16 nodi in totale, quando viene usato Corosync. Un gruppo di disponibilità può estendersi su al massimo nove dei 16 nodi con l’edizione SQL Server Enterprise e su due nodi con l’edizione SQL Server Standard.
Per una configurazione a due repliche in cui è richiesta la possibilità di eseguire automaticamente il failover in un'altra replica, è necessario usare una replica di sola configurazione, come descritto in Replica di sola configurazione e quorum. Le repliche di sola configurazione sono state introdotte nell'aggiornamento cumulativo 1 (CU 1) di SQL Server 2017 (14.x), che pertanto deve essere la versione minima distribuita per questa configurazione.
Se usato, Pacemaker deve essere configurato correttamente in modo da rimanere attivo. Ciò significa che è necessario implementare il quorum e STONITH in modo appropriato dalla prospettiva di Pacemaker, oltre a soddisfare gli eventuali requisiti di SQL Server, come la replica di sola configurazione.
Le repliche secondarie leggibili sono supportate solo con l’edizione SQL Server Enterprise.
Tipo di cluster e modalità di failover
Tra le novità di SQL Server 2017 (14.x) è stato introdotto un tipo di cluster per i gruppi di disponibilità. Per Linux, i valori validi sono due: External e None. Se il tipo di cluster è External, significa che Pacemaker verrà usato come cluster sottostante al gruppo di disponibilità. Quando il tipo di cluster è impostato su External, anche la modalità di failover deve essere External (anche questa una novità di SQL Server 2017 (14.x)). Il failover automatico è supportato, ma a differenza di un cluster WSFC, con Pacemaker la modalità di failover è impostata come External e non è automatica. Diversamente da quanto avviene per un cluster WSFC, la parte Pacemaker del gruppo di disponibilità viene creata dopo la configurazione del gruppo.
Se il tipo di cluster è None, significa che Pacemaker non è necessario e non verrà usato dal gruppo di disponibilità. Anche nei server in cui è configurato Pacemaker, se un gruppo di disponibilità è configurato con un tipo di cluster None, Pacemaker non potrà né vedere né gestire tale gruppo. Un tipo di cluster None supporta solo il failover manuale da una replica primaria a una secondaria. Un gruppo di disponibilità creato con Nessuno è destinato principalmente agli aggiornamenti e alla scalabilità in lettura. Anche se può funzionare in scenari come il ripristino di emergenza o la disponibilità locale in cui non è necessario alcun failover automatico, non è consigliabile. Senza Pacemaker la questione del listener è anche più complessa.
Il tipo di cluster viene archiviato nella DMV SQL Server sys.availability_groups, nelle colonne cluster_type e cluster_type_desc.
required_synchronized_secondaries_to_commit
Una novità di SQL Server 2017 (14.x) è un'impostazione usata dai gruppi di disponibilità denominati required_synchronized_secondaries_to_commit. Questa impostazione indica al gruppo di disponibilità il numero di repliche secondarie che devono essere in sincronia con la replica primaria. Ciò consente di eseguire operazioni come il failover automatico, solo se integrato con Pacemaker con un tipo di cluster External, e controlla il comportamento di determinate funzionalità, come la disponibilità della replica primaria se il numero corretto di repliche secondarie è online oppure offline. Per comprendere questa modalità di funzionamento, vedere Disponibilità elevata e protezione dei dati per le configurazioni del gruppo di disponibilità. Il valore required_synchronized_secondaries_to_commit viene configurato per impostazione predefinita e gestito da Pacemaker/SQL Server. È possibile eseguire l'override di questo valore manualmente.
La combinazione di required_synchronized_secondaries_to_commit e del nuovo numero di sequenza (archiviato in sys.availability_groups) informa Pacemaker e SQL Server che, ad esempio, può verificarsi un failover automatico. In tal caso, una replica secondaria ha lo stesso numero di sequenza di quella primaria e pertanto è aggiornata con tutte le informazioni di configurazione più recenti.
Per required_synchronized_secondaries_to_commit è possibile impostare tre valori, ovvero 0, 1 o 2. Questi valori controllano il comportamento di ciò che accade quando una replica diventa non disponibile. I numeri corrispondono al numero di repliche secondarie che devono essere sincronizzate con la replica primaria. In Linux si verifica il comportamento seguente:
- 0: non è necessario che le repliche secondarie siano sincronizzate con la replica primaria. Se tuttavia le repliche secondarie non sono sincronizzate, non verrà eseguito il failover automatico.
- 1: una replica secondaria deve essere sincronizzata con la replica primaria. Il failover automatico è possibile. Il database primario non è disponibile finché non lo è una replica secondaria sincrona.
- 2: entrambe le repliche secondarie in una configurazione del gruppo di disponibilità a tre o più nodi devono essere sincronizzate con la replica primaria. Il failover automatico è possibile.
required_synchronized_secondaries_to_commit controlla non solo il comportamento dei failover con le repliche sincrone, ma anche la perdita di dati. Con un valore 1 o 2, una replica secondaria deve essere sempre sincronizzata e pertanto vi sarà sempre ridondanza dei dati. Ciò significa che non si verificherà alcuna perdita di dati.
Per modificare il valore di required_synchronized_secondaries_to_commit, usare la sintassi seguente:
Nota
Se si modifica il valore, la risorsa viene riavviata. Questo comporta una breve interruzione. L'unico modo per evitare questo problema è quello di impostare la risorsa in modo che non venga gestita temporaneamente dal cluster.
Red Hat Enterprise Linux (RHEL) e Ubuntu
sudo pcs resource update <AGResourceName> required_synchronized_secondaries_to_commit=<Value>
SUSE Linux Enterprise Server (SLES)
sudo crm resource param ms-<AGResourceName> set required_synchronized_secondaries_to_commit <value>
dove AGResourceName è il nome della risorsa configurata per il gruppo di disponibilità e Value è 0, 1 o 2. Per ripristinare l'impostazione predefinita in base alla quale Pacemaker gestisce il parametro, eseguire la stessa istruzione senza alcun valore.
Il failover automatico di un gruppo di disponibilità è possibile quando sono soddisfatte le condizioni seguenti:
- Per la replica primaria e quella secondaria è impostato lo spostamento dei dati sincrono.
- Lo stato della replica secondaria è sincronizzato (non in fase di sincronizzazione). Ciò significa che le due repliche si trovano nello stesso punto dati.
- Il tipo di cluster è impostato su External. Il failover automatico non è possibile con un tipo di cluster None.
- Il valore di
sequence_numberdella replica secondaria che diventerà primaria è quello più alto. In altre parole, il valore disequence_numberdella replica secondaria corrisponde a quello della replica primaria originale.
Se queste condizioni sono soddisfatte e si verifica un errore del server che ospita la replica primaria, la proprietà del gruppo di disponibilità passerà a una replica sincrona. Il comportamento per le repliche sincrone (che possono essere tre in totale: una primaria e due secondarie) può essere ulteriormente controllato da required_synchronized_secondaries_to_commit. Questo è possibile per i gruppi di disponibilità sia in Windows che in Linux, ma la configurazione è diversa. In Linux il valore viene configurato automaticamente dal cluster nella risorsa del gruppo di disponibilità.
Replica di sola configurazione e quorum
Un'altra novità di SQL Server 2017 (14.x), disponibile a partire dall'aggiornamento cumulativo 1, è una replica di sola configurazione. Poiché Pacemaker è diverso da un cluster WSFC, soprattutto in termini di quorum e abilitazione di STONITH, una semplice configurazione a due nodi non è applicabile nel caso di un gruppo di disponibilità. Per un'istanza del cluster di failover, i meccanismi di quorum forniti da Pacemaker possono essere adeguati, perché tutto l'arbitraggio del failover dell'istanza viene eseguito a livello di cluster. Per un gruppo di disponibilità, l'arbitraggio in Linux viene eseguito in SQL Server, dove sono archiviati tutti i metadati. A questo punto entra in gioco la replica di sola configurazione.
Se non vi fosse altro, sarebbero necessari un terzo nodo e almeno una replica sincronizzata. La replica di sola configurazione archivia la configurazione del gruppo di disponibilità nel database master, come le altre repliche nella configurazione del gruppo di disponibilità. Con la replica di sola configurazione, i database utente non partecipano al gruppo di disponibilità. I dati di configurazione vengono inviati in modo sincrono dalla replica primaria. Questi dati di configurazione vengono quindi usati durante i failover, indipendentemente dal fatto che siano automatici o manuali.
Per mantenere il quorum e abilitare i failover automatici con un tipo di cluster External, un gruppo di disponibilità deve avere:
- Tre repliche sincrone (solo edizione SQL Server Enterprise); o
- Due repliche (primaria e secondaria) e una replica di sola configurazione.
I failover manuali possono verificarsi se per le configurazioni del gruppo di disponibilità vengono usati tipi di cluster External o None. Anche se una replica di sola configurazione può essere configurata con un gruppo di disponibilità con tipo di cluster None, questa configurazione non è consigliata perché ha l'effetto di complicare la distribuzione. Per le configurazioni di questo tipo, modificare required_synchronized_secondaries_to_commit manualmente impostando almeno un valore 1, in modo che almeno una replica venga sincronizzata.
Una replica di sola configurazione può essere ospitata in qualsiasi edizione di SQL Server, incluso SQL Server Express. Questo consente di ridurre al minimo i costi di gestione delle licenze e garantisce l'interoperabilità con i gruppi di disponibilità nell’edizione SQL Server Standard. In altre parole, è sufficiente che il terzo server richiesto soddisfi le specifiche minime per SQL Server, poiché non riceve il traffico delle transazioni utente per il gruppo di disponibilità.
Quando viene usata una replica di sola configurazione, si verifica il comportamento seguente:
- Per impostazione predefinita, il valore di
required_synchronized_secondaries_to_commitè 0. Questa impostazione può essere modificata manualmente su 1, se lo si desidera. - Se si verifica un errore nella replica primaria e il valore di
required_synchronized_secondaries_to_commitè 0, la replica secondaria diventerà primaria e sarà disponibile sia per la lettura che per la scrittura. Se il valore è 1, verrà eseguito il failover automatico, ma non saranno accettate nuove transazioni finché l'altra replica non sarà online. - Se si verifica un errore nella replica secondaria e il valore di
required_synchronized_secondaries_to_commitè 0, la replica primaria accetterà comunque le transazioni. Se però a questo punto si verifica un errore anche nella replica primaria, non sarà disponibile alcuna protezione per i dati e non potrà essere eseguito nemmeno il failover (manuale o automatico), poiché non sarà disponibile una replica secondaria. - Se si verifica un errore nella replica di sola configurazione, il gruppo di disponibilità funzionerà normalmente, ma il failover automatico non sarà possibile.
- Se si verifica un errore sia in una replica secondaria sincrona che nella replica di sola configurazione, quella primaria non potrà accettare transazioni e non sarà disponibile alcuna replica per il failover.
Nell'aggiornamento cumulativo 1 è stato rilevato un bug relativo alla registrazione dei dati nel file corosync.log generato tramite mssql-server-ha. Se una replica secondaria non può diventare primaria a causa del numero di repliche richieste disponibili, viene visualizzato un messaggio per segnalare che era previsto 1 numero di sequenza, ma ne sono stati ricevuti solo 2, e che pertanto non è disponibile online un numero di repliche sufficiente per promuovere in modo sicuro la replica locale. I numeri dovrebbero essere invertiti e il messaggio dovrebbe segnalare che erano previsti 2 numeri di sequenza, ma ne è stato ricevuto solo 1, e che pertanto non è disponibile online un numero di repliche sufficiente per promuovere in modo sicuro la replica locale.
Gruppi di disponibilità multipli
È possibile creare più gruppi di disponibilità per ogni set di server o cluster Pacemaker. L'unica limitazione è rappresentata dalle risorse di sistema. La proprietà del gruppo di disponibilità viene visualizzata dal master. Gruppi di disponibilità diversi possono essere di proprietà di nodi diversi. Non devono essere eseguiti tutti nello stesso nodo.
Posizione di unità e cartelle per i database
Come per i gruppi di disponibilità basati su Windows, la struttura di unità e cartelle per i database utente che partecipano a un gruppo di disponibilità deve essere identica. Se, ad esempio, i database utente si trovano in /var/opt/mssql/userdata sul server A, la stessa cartella deve essere presente sul server B. L'unica eccezione è indicata nella sezione Interoperabilità con repliche e gruppi di disponibilità basati su Windows.
Il listener in Linux
Il listener è una funzionalità facoltativa per un gruppo di disponibilità. Offre un singolo punto di ingresso per tutte le connessioni (di lettura/scrittura nella replica primaria e/o di sola lettura nelle repliche secondarie). In questo modo, non è necessario che le applicazioni e gli utenti finali conoscano il server che ospita i dati. In un cluster WSFC, si tratta della combinazione di una risorsa nome di rete e di una risorsa IP, che viene quindi registrata in AD DS (se necessario) e in DNS. In combinazione con la risorsa del gruppo di disponibilità, il listener fornisce tale astrazione. Per altre informazioni, vedere Listener del gruppo di disponibilità, connettività client e failover dell'applicazione.
Il listener in Linux è configurato in modo diverso, ma offre la stessa funzionalità. Non esiste un concetto di risorsa nome di rete in Pacemaker e non è nemmeno presente un oggetto creato in AD DS. In Pacemaker viene semplicemente creata una risorsa indirizzo IP che può essere eseguita su uno qualsiasi dei nodi. È necessario creare una voce associata alla risorsa IP per il listener in DNS con un nome descrittivo. La risorsa IP per il listener sarà attiva solo sul server che ospita la replica primaria per il gruppo di disponibilità.
Se si usa Pacemaker e viene creata una risorsa indirizzo IP associata al listener, si verifica una breve interruzione perché l'indirizzo IP si arresta su un server e viene avviato sull'altro, indipendentemente dal fatto che si tratti di un failover automatico o manuale. Anche se ciò offre un'astrazione tramite la combinazione di un nome e di un indirizzo IP singoli, l'interruzione non viene mascherata. Un'applicazione deve essere in grado di gestire la disconnessione presentando alcune funzionalità per rilevare l'interruzione e riconnettersi.
La combinazione del nome DNS e dell'indirizzo IP non è tuttavia sufficiente per fornire tutte le funzionalità di un listener in un cluster WSFC, ad esempio il routing di sola lettura per le repliche secondarie. Quando si configura un gruppo di disponibilità, il listener deve ancora essere configurato in SQL Server. Questo può essere osservato nella procedura guidata e nella sintassi Transact-SQL. Per fare in modo che il listener funzioni come in Windows è possibile configurarlo in due modi:
- Per un gruppo di disponibilità con un tipo di cluster External, l'indirizzo IP associato al listener creato in SQL Server deve quello della risorsa creata in Pacemaker.
- Per un gruppo di disponibilità creato con un tipo di cluster None, usare l'indirizzo IP associato alla replica primaria.
L'istanza associata all'indirizzo IP fornito assume quindi il ruolo di coordinatore per azioni come le richieste di routing di sola lettura provenienti dalle applicazioni.
Interoperabilità con repliche e gruppi di disponibilità basati su Windows
Un gruppo di disponibilità con un tipo di cluster External o con un cluster WSFC non può avere repliche su più piattaforme. Questo vale se il gruppo di disponibilità è l’edizione SQL Server Standard o l’edizione SQL Server Enterprise. In altre parole, in una configurazione tradizionale del gruppo di disponibilità con un cluster sottostante, una replica non può trovarsi in un cluster WSFC se l'altra è in Linux con Pacemaker.
In un gruppo di disponibilità con un tipo di cluster NONE le repliche possono trovarsi su diversi sistemi operativi e pertanto, nello stesso gruppo di disponibilità, possono essere presenti repliche basate sia su Linux che su Windows. Di seguito è riportato un esempio in cui la replica primaria è basata su Windows, mentre quella secondaria si trova in una delle distribuzioni Linux.

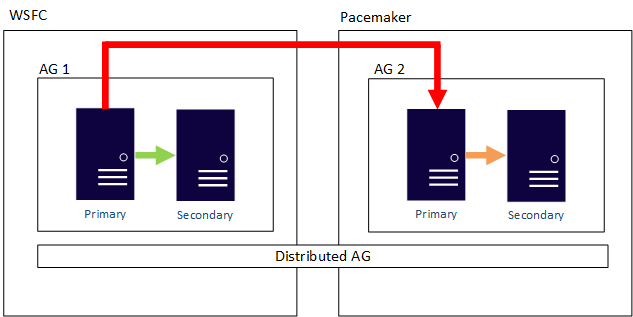
Anche un gruppo di disponibilità distribuito può essere basato su più sistemi operativi. I gruppi di disponibilità sottostanti sono vincolati dalle regole definite per la configurazione. Ad esempio, un gruppo può essere configurato con un tipo di cluster External solo Linux, mentre il gruppo a cui viene aggiunto può essere configurato con un cluster WSFC. Si consideri l'esempio seguente:
Contenuto correlato
- Configurare un gruppo di disponibilità per SQL Server in Linux
- Configurare un gruppo di disponibilità con scalabilità in lettura per SQL Server in Linux
- Aggiungere una risorsa cluster per un gruppo di disponibilità in RHEL
- Aggiungere una risorsa cluster per un gruppo di disponibilità in SLES
- Aggiungere una risorsa cluster per un gruppo di disponibilità in Ubuntu
- Configurare un gruppo di disponibilità multipiattaforma
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per