Configurare PolyBase per l'accesso a dati esterni in Hadoop
Si applica a:![]() SQL Server - Solo Windows
SQL Server - Solo Windows ![]() Istanza gestita di SQL di Azure
Istanza gestita di SQL di Azure
L'articolo illustra come usare PolyBase in un'istanza di SQL Server per eseguire query sui dati esterni in Hadoop.
Nota
A partire da SQL Server 2022 (16.x), Hadoop non è più supportato in PolyBase.
Prerequisiti
- Se PolyBase non è stato installato, vedere Installazione di PolyBase. Nell'articolo sull'installazione vengono illustrati i prerequisiti.
- A partire da SQL Server 2019 (15.x), è anche necessario abilitare la funzionalità PolyBase.
- PolyBase supporta due provider di Hadoop, Hortonworks Data Platform (HDP) e Cloudera Distributed Hadoop (CDH). Hadoop segue il modello "principale.secondaria.versione" per le nuove versioni e sono supportate tutte le versioni all'interno di una versione principale e secondaria supportata. Per informazioni sulle versioni supportate di Hortonworks Data Platform (HDP) e Cloudera Distributed Hadoop (CDH), vedere Configurazione della connettività PolyBase.
Nota
PolyBase supporta le zone di crittografia Hadoop a partire da SQL Server 2016 SP1 CU7 e SQL Server 2017 CU3. Se si usano i gruppi con scalabilità orizzontale PolyBase, anche tutti i nodi di calcolo devono essere in una build che include il supporto per le zone di crittografia Hadoop.
Configurare la connettività Hadoop
Configurare prima di tutto SQL Server PolyBase per usare il provider di Hadoop specifico.
Eseguire sp_configure con 'hadoop connectivity' e impostare un valore appropriato per il provider. Per trovare il valore per il provider, vedere Configurazione della connettività di PolyBase.
-- Values map to various external data sources. -- Example: value 7 stands for Hortonworks HDP 2.1 to 2.6 on Linux, -- 2.1 to 2.3 on Windows Server, and Azure Blob Storage sp_configure @configname = 'hadoop connectivity', @configvalue = 7; GO RECONFIGURE GOÈ necessario riavviare SQL Server mediante services.msc. Il riavvio di SQL Server comporta il riavvio di questi servizi:
- Servizio spostamento dati di PolyBase per SQL Server
- Motore di PolyBase per SQL Server

Abilitare il calcolo con distribuzione
Per migliorare le prestazioni delle query, abilitare il calcolo con distribuzione nel cluster Hadoop:
Trovare il file yarn-site.xml nel percorso di installazione di SQL Server. In genere il percorso è:
C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Binn\PolyBase\Hadoop\conf\Nel computer Hadoop trovare il file analogo nella directory di configurazione Hadoop. Nel file trovare e copiare il valore della chiave di configurazione yarn.application.classpath.
Nel computer SQL Server individuare la proprietà yarn.application.classpath nel file yarn.site.xml. Incollare il valore dal computer Hadoop nell'elemento valore.
Per tutte le versioni di CDH 5.X sarà necessario aggiungere i parametri di configurazione mapreduce.application.classpath alla fine del file yarn-site.xml o nel file mapred-site.xml. HortonWorks include queste configurazioni all'interno delle configurazioni yarn.application.classpath. Vedere Configurazione di PolyBase per alcuni esempi.
Importante
Per usare la funzionalità di distribuzione di calcolo con Hadoop, il cluster Hadoop di destinazione deve disporre dei componenti principali di HDFS, YARN e MapReduce con il server della cronologia processo abilitato. PolyBase invia la query di distribuzione tramite MapReduce e recupera lo stato dal server della cronologia processo. Senza uno dei due componenti la query ha esito negativo.
Configurare una tabella esterna
Per eseguire query sui dati nell'origine dati Hadoop, è necessario definire una tabella esterna da usare in query Transact-SQL. Le procedure seguenti descrivono come configurare la tabella esterna.
Creare una chiave master nel database, se non esiste già. Questo passaggio è necessario per crittografare il segreto delle credenziali.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';Argomenti
PASSWORD ='password'
Password utilizzata per crittografare la chiave master nel database. password deve soddisfare i requisiti per i criteri password di Windows del computer che esegue l'hosting dell'istanza di SQL Server.
Creare credenziali con ambito database per i cluster Hadoop con protezione Kerberos.
-- IDENTITY: the Kerberos user name. -- SECRET: the Kerberos password CREATE DATABASE SCOPED CREDENTIAL HadoopUser1 WITH IDENTITY = '<hadoop_user_name>', Secret = '<hadoop_password>';Creare un'origine dati esterna con CREATE EXTERNAL DATA SOURCE.
-- LOCATION (Required) : Hadoop Name Node IP address and port. -- RESOURCE MANAGER LOCATION (Optional): Hadoop Resource Manager location to enable pushdown computation. -- CREDENTIAL (Optional): the database scoped credential, created above. CREATE EXTERNAL DATA SOURCE MyHadoopCluster WITH ( TYPE = HADOOP, LOCATION ='hdfs://10.xxx.xx.xxx:xxxx', RESOURCE_MANAGER_LOCATION = '10.xxx.xx.xxx:xxxx', CREDENTIAL = HadoopUser1 );Creare un formato di file esterno con CREATE EXTERNAL FILE FORMAT.
-- FORMAT TYPE: Type of format in Hadoop (DELIMITEDTEXT, RCFILE, ORC, PARQUET). CREATE EXTERNAL FILE FORMAT TextFileFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS (FIELD_TERMINATOR ='|', USE_TYPE_DEFAULT = TRUE))Creare una tabella esterna che punta ai dati archiviati in Hadoop con CREATE EXTERNAL TABLE. In questo esempio i dati esterni contengono dati di sensori di auto.
-- LOCATION: path to file or directory that contains the data (relative to HDFS root). CREATE EXTERNAL TABLE [dbo].[CarSensor_Data] ( [SensorKey] int NOT NULL, [CustomerKey] int NOT NULL, [GeographyKey] int NULL, [Speed] float NOT NULL, [YearMeasured] int NOT NULL ) WITH (LOCATION='/Demo/', DATA_SOURCE = MyHadoopCluster, FILE_FORMAT = TextFileFormat );Creare statistiche per una tabella esterna.
CREATE STATISTICS StatsForSensors on CarSensor_Data(CustomerKey, Speed)
Query PolyBase
PolyBase è adatto per assolvere a una triplice funzione:
- Esecuzione di query ad hoc su tabelle esterne.
- Importazione di dati.
- Esportazione di dati.
Le query seguenti forniscono esempi con dati fittizi di sensori di auto.
Query ad hoc
La query ad-hoc seguente crea un join relazionale con dati Hadoop. Seleziona i clienti che guidano a velocità superiori a 35 miglia/h, unendo in join i dati dei clienti strutturati archiviati in SQL Server con i dati dei sensori di auto archiviati in Hadoop.
SELECT DISTINCT Insured_Customers.FirstName,Insured_Customers.LastName,
Insured_Customers. YearlyIncome, CarSensor_Data.Speed
FROM Insured_Customers, CarSensor_Data
WHERE Insured_Customers.CustomerKey = CarSensor_Data.CustomerKey and CarSensor_Data.Speed > 35
ORDER BY CarSensor_Data.Speed DESC
OPTION (FORCE EXTERNALPUSHDOWN); -- or OPTION (DISABLE EXTERNALPUSHDOWN)
Importare i dati
La query seguente importa dati esterni in SQL Server. Questo esempio importa i dati relativi agli autisti che guidano veloce in SQL Server per eseguire un'analisi più dettagliata. Per migliorare le prestazioni, l'esempio usa un indice columnstore.
SELECT DISTINCT
Insured_Customers.FirstName, Insured_Customers.LastName,
Insured_Customers.YearlyIncome, Insured_Customers.MaritalStatus
INTO Fast_Customers from Insured_Customers INNER JOIN
(
SELECT * FROM CarSensor_Data where Speed > 35
) AS SensorD
ON Insured_Customers.CustomerKey = SensorD.CustomerKey
ORDER BY YearlyIncome
CREATE CLUSTERED COLUMNSTORE INDEX CCI_FastCustomers ON Fast_Customers;
Esportazione di dati
La query seguente esporta i dati da SQL Server in Hadoop. A tale scopo, è prima di tutto necessario abilitare l'esportazione di PolyBase. Creare poi una tabella esterna per la destinazione prima dell'esportazione dei dati.
-- Enable INSERT into external table
sp_configure 'allow polybase export', 1;
reconfigure
-- Create an external table.
CREATE EXTERNAL TABLE [dbo].[FastCustomers2009] (
[FirstName] char(25) NOT NULL,
[LastName] char(25) NOT NULL,
[YearlyIncome] float NULL,
[MaritalStatus] char(1) NOT NULL
)
WITH (
LOCATION='/old_data/2009/customerdata',
DATA_SOURCE = HadoopHDP2,
FILE_FORMAT = TextFileFormat,
REJECT_TYPE = VALUE,
REJECT_VALUE = 0
);
-- Export data: Move old data to Hadoop while keeping it query-able via an external table.
INSERT INTO dbo.FastCustomer2009
SELECT T.* FROM Insured_Customers T1 JOIN CarSensor_Data T2
ON (T1.CustomerKey = T2.CustomerKey)
WHERE T2.YearMeasured = 2009 and T2.Speed > 40;
Visualizzare gli oggetti PolyBase in SQL Server Management Studio
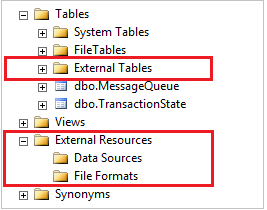
In SQL Server Management Studio, le tabelle esterne vengono visualizzate in una cartella separata Tabelle esterne. Le origini dati esterne e i formati di file esterni si trovano nelle sottocartelle in External Resources.
Passaggi successivi
Per altre esercitazioni sulla creazione di origini dati esterne e tabelle esterne in un'ampia gamma di origini dati, vedere le Informazioni di riferimento su Transact-SQL per PolyBase.
Per esplorare altri modi per usare e monitorare PolyBase, vedere gli articoli seguenti:
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per