Panoramica dell'analisi dell'input penna
Le API InkAnalysis forniscono agli sviluppatori di Tablet PC potenti strumenti per esaminare l'input penna a livello di codice. L'API classifica l'input penna in categorie significative, ad esempio parole, linee, paragrafi e disegni.
È possibile usare ogni classificazione in diversi modi, tra cui il miglioramento dei risultati di riconoscimento per la grafia.
Nozioni di base di analisi dell'input penna
Questa sezione presenta la tecnologia di analisi dell'input penna di Tablet PC Platform e spiega quando e come usarlo.
Le API InkAnalysis combinano in modo efficace due tecnologie distinte ma gratuite: riconoscimento della grafia e classificazione del layout. La combinazione di queste due tecnologie offre risultati decisamente maggiori rispetto alle parti prese da sole.
Il riconoscimento della grafia è l'analisi computazionale dell'input penna scritto a mano per restituire un'interpretazione basata su caratteri in un determinato linguaggio. Ovvero, il riconoscimento della grafia è il modo in cui il computer "legge" la grafia di una persona.
L'analisi dell'input penna può essere ulteriormente suddivisa in classificazione input penna e analisi del layout. La classificazione input penna è la divisione computazionale dell'input penna in unità semanticamente significative, ad esempio paragrafi, linee, parole e disegni. L'analisi del layout è l'esame computazionale dell'input penna per determinare la posizione dell'input penna sulla superficie di input penna e il modo in cui i tratti sono correlati tra loro in modo spaziale e anche semantico. Ad esempio, l'analisi del layout può indicare che una particolare parte di input penna è un'annotazione o un callout.
Riconoscimento
Un esempio di come la combinazione di riconoscimento con l'analisi dell'input penna nell'API InkAnalysis consente allo sviluppatore di migliorare i risultati del riconoscimento. I motori di riconoscimento della grafia del TABLET PC sono stati progettati principalmente per riconoscere una singola linea orizzontale di input penna. Tuttavia, le persone tendono a scrivere più righe quando prendono appunti e tali righe non sono necessariamente orizzontali in relazione alla pagina. Con l'API InkAnalysis, l'input penna viene pre-elaborato dall'analizzatore input penna prima di essere inviato al riconoscitore. L'input penna analizzato viene trasformato in orizzontale prima di essere riconosciuto, migliorando i risultati del riconoscimento.
Altri vantaggi per il riconoscimento sono derivati dalla presenza dell'analizzatore input penna di correggere le informazioni sull'ordine dei tratti non corretti prima di inviare l'input penna al riconoscitore. Inoltre, i risultati del riconoscimento sono ora disponibili in modo selettivo. Ovvero, lo sviluppatore può recuperare rapidamente i risultati del riconoscimento per una singola parola, riga o paragrafo in una sola chiamata.
Classificazione input penna
Naturalmente, esistono diversi scenari in cui è possibile mantenere intatti i dati dell'input penna, anziché convertirli immediatamente in testo. Anche l'analisi dell'input penna offre vantaggi. In particolare, le API InkAnalysis offrono la possibilità di dividere i tratti input penna in base alla scrittura o ai disegni. I tratti input penna classificati come scrittura sono quelli che costituiscono una parola o caratteri. Tutti gli altri tratti sono disegni. In questo modo è possibile accedere ai dati dell'input penna, abilitando nuovi scenari utente. Ad esempio, è possibile implementare la selezione in modo che sia diversa in base al tipo di tratto su cui l'utente tocca; se un utente tocca un tratto di scrittura, l'applicazione seleziona l'intero set di tratti che compongono la parola, se l'utente tocca uno stoke di disegno, l'applicazione seleziona solo tale tratto.
Analisi del layout
L'analisi del layout utile va in realtà ben oltre la suddivisione relativamente semplice dell'input penna in componenti di scrittura e disegno.
L'analisi dell'input penna include anche una suddivisione più dettagliata dei tratti di scrittura e disegno. Come esempio molto semplice, prendere un BLOB di input penna come illustrato nella figura seguente.

Dopo aver analizzato questi tratti, la piattaforma restituisce una rappresentazione ad albero di questi tratti, come illustrato nella figura seguente. Per questo semplice caso, l'albero contiene solo informazioni di paragrafo, riga e parola, ma la ricchezza di questo albero aumenta man mano che aumenta la complessità del documento input penna.
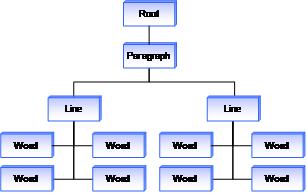
Poiché queste informazioni sono ora separate in unità gestibili, è ora possibile creare funzionalità più potenti. Ad esempio, l'applicazione può estendere la funzionalità in cui l'utente tocca per selezionare una parola in una funzionalità in cui l'utente tocca una volta per selezionare la parola, tocca due volte per selezionare l'intera riga e tocca tre volte per selezionare l'intero paragrafo. Sfruttando la struttura ad albero restituita dall'operazione di analisi, l'applicazione può correlare l'area toccata di nuovo a un tratto nell'albero. Dopo che l'applicazione trova un tratto, può camminare verso l'alto per determinare come e quali tratti adiacenti selezionare.
La selezione di un'intera linea è un esempio semplicistico dei vantaggi dell'analisi dell'input penna, ma le possibilità diventano eccezionali quando si considerano i diversi tipi di strutture gerarchiche che l'analizzatore input penna è in grado di rilevare:
- Elenchi ordinati e non ordinati
- Forme
- Commenti annotativi scritti inline con il testo
I tipi di funzionalità variano dall'applicazione all'applicazione e si basano sui requisiti e sui motori di analisi e riconoscimento dell'input penna disponibili.
Funzionalità principali di analisi dell'input penna
Le funzionalità principali dell'API InkAnalysis includono le funzionalità seguenti:
- Analisi incrementale
- Persistenza
- Proxy dati
- Riconciliazione
- Estendibilità
Analisi incrementale
Quando gli utenti finali lavorano con l'input penna, in genere lo considerano come la grafia. L'input penna è continuamente soggetto a operazioni di modifica, ad esempio l'aggiunta di un nuovo input penna, l'eliminazione dell'input penna esistente e la modifica delle proprietà dell'input penna, tutte eseguite nello stesso modo in cui la grafia viene continuamente modificata. Queste operazioni di modifica influiscono sui risultati dell'analisi. Quando si verificano modifiche, in genere possono essere isolate in sezioni del documento in momenti specifici. Si supponga, ad esempio, che un utente scriva cinque righe di input penna. Il modo standard in cui le applicazioni analizzano l'input penna è attendere che l'utente abbia finito di scrivere tutte e cinque le righe di input penna, ad esempio un paragrafo, e quindi analizzare i risultati, in modo sincrono o asincrono.
È possibile ottimizzare il tempo complessivo impiegato per analizzare queste cinque righe isolando le aree analizzate durante la scrittura e quindi rielaborando solo le parti dei risultati che sono state modificate. Dopo l'analisi della prima riga, non verrà mai più riconosciuta a meno che non venga modificata dall'utente finale. Il riconoscimento della seconda riga viene considerato come un'operazione di riconoscimento indipendente.
Questo approccio incrementale funziona correttamente a livello di riga per le operazioni di riconoscimento, ma deve funzionare a un livello superiore per l'operazione di analisi dell'input penna. Poiché l'analizzatore input penna può rilevare classificazioni di livello superiore diverse per queste cinque righe di input penna (ad esempio, potrebbe trattarsi di un paragrafo standard o di cinque elementi in un elenco), l'approccio incrementale per l'analizzatore dell'input penna è che deve analizzare queste strutture superiori. Vale a dire, dopo che l'analizzatore input penna classifica la prima riga di input penna come riga, verifica che sia ancora una riga quando classifica la seconda riga. Tuttavia, l'analizzatore input penna isola questo doppio controllo al paragrafo e ignora il primo paragrafo durante l'analisi di un secondo paragrafo, trattando il secondo paragrafo come un'operazione dell'analizzatore dell'input penna indipendente. Questo approccio incrementale all'analisi consente di risparmiare notevolmente tempo di elaborazione quando nell'applicazione esistono già grandi quantità di input penna.
Persistenza
L'analisi incrementale funziona correttamente all'interno di una determinata sessione o istanza di un oggetto InkAnalyzer . Tuttavia, le API Tablet PC Platform di prima generazione non possono eseguire analisi incrementali dopo che l'input penna è persistente su disco. L'API InkAnalysis consente di salvare l'input penna su disco insieme a una forma persistente dei risultati dell'analisi. I risultati dell'analisi possono essere caricati quando l'input penna viene caricato e possono essere inseriti in una nuova istanza di InkAnalyzer. Una nuova istanza dell'oggetto InkAnalyzer ha quindi lo stesso stato dei risultati che aveva in precedenza e può ora accettare eventuali modifiche come modifiche incrementali allo stato esistente, invece di analizzare di nuovo tutto.
Proxy dati
Molte applicazioni hanno già una sorta di struttura di documenti esistente nelle loro applicazioni; ad esempio un grafo o un database. InkAnalyzer presenta anche i risultati in una forma strutturata, in un albero di oggetti ContextNode. La struttura InkAnalyzer e la struttura esistente dell'applicazione devono interagire in due direzioni: i risultati vengono estratti da InkAnalyzer nell'applicazione e lo stato viene inserito dall'applicazione in InkAnalyzer.
Se il pull dei risultati da InkAnalyzer nella struttura dell'applicazione era tutto ciò che era necessario, sarebbe relativamente semplice. Le applicazioni eseguono l'iterazione dell'albero dei risultati e copiano (integrare) tutti i risultati necessari nella struttura dei dati esistente. Tuttavia, poiché molte applicazioni orizzontali richiedono l'analisi incrementale e la persistenza su disco, il problema diventa bidirezionale. Lo stato (risultati precedenti) deve essere estratto dalla struttura dell'applicazione e inserito in InkAnalyzer.
Per soddisfare questo requisito, InkAnalyzer contiene una serie di eventi generati al momento appropriato durante un'operazione di analisi per consentire alle applicazioni di delegare la richiesta di dati alle strutture esistenti. Questi eventi vengono generati solo per gli oggetti ContextNode richiesti dall'operazione incrementale.
Riconciliazione
La maggior parte delle applicazioni vuole analizzare l'input penna in background per mantenere al minimo le interruzioni dell'interfaccia utente. L'analisi dell'input penna in background causa problemi, tuttavia, se l'utente modifica l'input penna (o l'input penna adiacente) analizzato. Ad esempio, se l'utente elimina l'input penna durante l'operazione in background, la struttura risultante riflette lo stato del documento all'avvio dell'operazione in background, anziché al completamento.
Per facilitare le applicazioni, InkAnalyzer riconcilia le differenze nello stato del documento tra l'inizio e la fine dell'operazione di analisi. Le modifiche apportate dall'utente o dall'applicazione mentre l'analisi è in esecuzione in background eseguono sempre l'override dei risultati calcolati in background. Dopo la riconciliazione, vengono segnalate solo le parti della struttura dei risultati che non sono in conflitto con le modifiche al documento e i tratti in conflitto vengono contrassegnati per l'analisi futura. Alla successiva esecuzione dell'operazione di analisi in background, i risultati vengono ricalcolati in base al nuovo stato.
Il diagramma seguente mostra questo processo. Il tempo viene espresso in modo lineare dall'alto verso il basso nel diagramma.
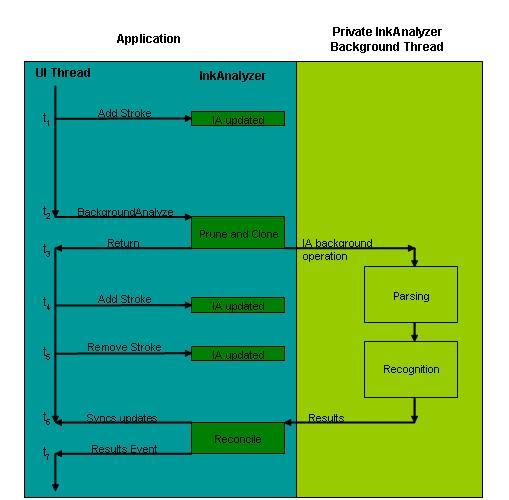
- Al momento 1 (t1), l'applicazione raccoglie l'input penna dall'utente finale, incluso qualsiasi tipo di modifica dell'input penna, ad esempio l'aggiunta, la rimozione o la modifica.
- In t2, l'applicazione richiama l'operazione di analisi in background. InkAnalyzer determina l'input penna che non ha risultati e quale input penna deve essere controllato doppio. Copia i dati dell'input penna necessari per consentire l'esecuzione indipendente del thread in background.
- In t3, InkAnalyzer restituisce l'esecuzione del thread dell'interfaccia utente all'applicazione. InkAnalyzer crea un secondo thread, il thread di analisi in background e i motori di analisi e riconoscimento input penna analizzano i dati dell'input penna copiati.
- Mentre si verifica l'operazione di analisi nel secondo thread in background, l'utente finale continua a modificare il documento, aggiungendo e rimuovendo i dati del tratto, in t4 e t5. Queste modifiche possono essere in conflitto con il lavoro in corso di elaborazione.
- A t6, il thread in background ha completato l'operazione di analisi e i risultati sono pronti. Prima che InkAnalyzer comunichi i risultati all'applicazione, esegue un algoritmo di riconciliazione per determinare se le modifiche apportate dall'utente durante il calcolo dell'operazione di analisi (t4 e t5) sono in conflitto con i risultati. Se vengono rilevate collisioni, i tratti in colli vengono contrassegnati per la ri-analisi, che si verifica la successiva volta che l'applicazione richiama l'operazione di analisi in background.
- Infine, a t7, con tutte le collisioni rilevate, InkAnalyzer presenta i risultati all'applicazione.
Estendibilità
Le API InkAnalysis consentono l'uso di nuovi tipi di motori di analisi da parte delle applicazioni, in modo da impedire all'applicazione di riscrivere tutti i vantaggi dell'API InkAnalysis, tra cui riconciliazione, proxy di dati, persistenza e analisi incrementale.
Argomenti correlati
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per