Python スクリプトの実行
重要
Machine Learning Studio (クラシック) のサポートは、2024 年 8 月 31 日に終了します。 その日までに、Azure Machine Learning に切り替えすることをお勧めします。
2021 年 12 月 1 日以降、新しい Machine Learning Studio (クラシック) リソースは作成できません。 2024 年 8 月 31 日まで、既存の Machine Learning Studio (クラシック) リソースを引き続き使用できます。
- ML Studio (クラシック) から Azure Machine Learning への機械学習プロジェクトの移動に関する情報を参照してください。
- Azure Machine Learning についての詳細を参照してください。
ML Studio (クラシック) のドキュメントは廃止予定であり、今後更新されない可能性があります。
Machine Learning実験から Python スクリプトを実行する
カテゴリ: Python 言語モジュール
注意
適用対象: Machine Learning Studio (クラシック) のみ
類似のドラッグ アンド ドロップ モジュールは Azure Machine Learning デザイナーで使用できます。
モジュールの概要
この記事では、Machine Learning Studio (クラシック) で Python スクリプトの実行モジュールを使用して Python コードを実行する方法について説明します。 Studio (クラシック) での Python のアーキテクチャと設計の原則の詳細については、次の記事を参照してください。
Python では、次のような既存の Studio (クラシック) モジュールで現在サポートされていないタスクを実行できます。
matplotlibを使用してデータを可視化する- Python ライブラリを使用してワークスペース内のデータセットとモデルを列挙する
- データのインポート モジュールではサポートされていないソースからデータを読み取り、読み込み、操作する
Machine Learning Studio (クラシック) は Python の Anaconda ディストリビューションを使用します。これには、データ処理用の一般的なユーティリティが多数含まれています。
Python スクリプトの実行を使用する方法
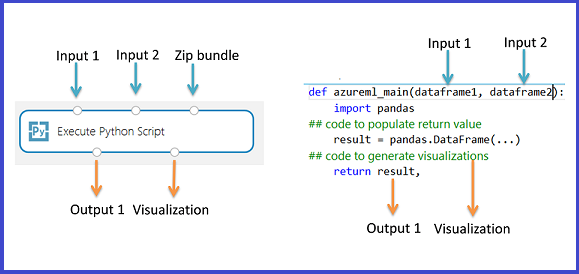
Python スクリプトの実行モジュールには、出発点として利用できるサンプル Python コードが含まれています。 Python スクリプトの実行モジュールを構成するには、実行する Python コードと一連の入力を [Python スクリプト] ボックスに指定します。
Python スクリプトの実行モジュールを実験に追加します。
[プロパティ] ウィンドウの下部までスクロールし、[Python バージョン] で、スクリプトで使用する Python ライブラリとランタイムのバージョンを選択します。
- Python 2.7.7 用 Anaconda 2.0 ディストリビューション
- Python 2.7.11 用 Anaconda 4.0 ディストリビューション
- Python 3.5 用 Anaconda 4.0 ディストリビューション (既定)
新しいコードを入力する前にバージョンを設定することをお勧めします。 後でバージョンを変更すると、変更の確認を求めるメッセージが表示されます。
重要
実験で Python スクリプトの実行 モジュールの複数のインスタンスを使用する場合は、実験内のすべてのモジュールに対して 1 つのバージョンの Python を選択する必要があります。
入力に使用する Studio (クラシック) のデータセットを Dataset1 に追加して接続します。 Python スクリプトでは、このデータセットを DataFrame1 として参照します。
Python を使用してデータを生成したい場合や、Python コードを使用してデータを直接モジュールにインポートしたい場合、必ずしもデータセットを使用する必要はありません。
このモジュールでは、 Dataset2 に 2 つ目の Studio (クラシック) データセットを追加できます。 Python スクリプトでは、第 2 のデータセットを DataFrame2 として参照します。
Studio (クラシック) に格納されているデータセットは、このモジュールを読み込むと、 pandas data.frames に自動的に変換されます。
新しい Python パッケージまたはコードをインクルードするには、それらのカスタム リソースを含む ZIP ファイルをスクリプト バンドルで追加します。 スクリプト バンドルへの入力は、あらかじめワークスペースにアップロードされた ZIP ファイルであることが必要です。 これらのリソースを準備してアップロードする方法の詳細については、「 Zip 形式のデータをアンパックする」を参照してください。
アップロード済みの ZIP アーカイブに格納されていれば、どのファイルでも実験の実行中に使用できます。 アーカイブにディレクトリ構造が含まれていても、その構造は維持されます。ただしその場合は、src というディレクトリをパスの先頭に追加する必要があります。
[Python スクリプト] ボックスに、有効な Python スクリプトを入力するか貼り付けます。
[Python スクリプト] ボックスには、データへのアクセスと出力に使用するサンプル コードと共に、いくつかの指示がコメントとして事前に入力されています。 このコードを編集するか置き換える必要があります。 大文字と小文字の区別およびインデントに関する Python の規則に必ず従ってください。
- スクリプトには、このモジュールのエントリ ポイントとして、
azureml_mainという名前の関数が含まれている必要があります。 - エントリ ポイント関数には、最大 2 つの入力引数を含めることができます (
Param<dataframe1>およびParam<dataframe2>)。 - 第 3 の入力ポートに接続された ZIP ファイルは解凍されて
.\Script Bundleディレクトリに格納されます。Python のsys.pathには、このディレクトリも追加されます。
そのため、ZIP ファイルに
mymodule.pyが含まれている場合は、import mymoduleを使用してインポートすることになります。- 単一のデータセットを Studio (クラシック) に返すことができます。これは一連の型
pandas.DataFrameである必要があります。 Python コードで他の出力を作成し、Azure Storage に直接書き込んだり、 Python デバイスを使用して視覚化を作成したりできます。
- スクリプトには、このモジュールのエントリ ポイントとして、
実験を実行します。Python スクリプトだけを実行する場合は、このモジュールを選択して [Run selected]\(選択項目の実行\) をクリックしてください。
すべてのデータおよびコードが仮想マシンに読み込まれ、指定した Python 環境を使用して実行されます。
結果
モジュールは次の出力を返します。
結果データセット。 埋め込まれた Python コードによって実行されるすべての計算の結果は pandas data.frame として提供する必要があります。これは、実験内の他のモジュールで結果を使用できるように、Machine Learning データセット形式に自動的に変換されます。 モジュールは、出力として 1 つのデータセットに制限されます。 詳細については、「 データ テーブル」を参照してください。
Python デバイス。 この出力は、Python インタープリターを使用する PNG グラフィックスのコンソール出力と表示の両方をサポートします。
スクリプト リソースをアタッチする方法
Python スクリプトの実行モジュールでは、任意の Python スクリプト ファイルが事前に準備され、.ZIP ファイルの一部としてワークスペースにアップロードされていれば、入力としてサポートされます。
Python コードを含む ZIP ファイルをワークスペースにアップロードする
Machine Learning Studio (クラシック) の実験領域で、[データセット] をクリックし、[新規] をクリックします。
[ ローカル ファイルから] オプションを選択します。
[新しいデータセットのアップロード] ダイアログ ボックスで、[新しいデータセットの種類を選択] のドロップダウン リストをクリックし、[Zip ファイル (.zip)] オプションを選択します。
[ 参照 ] をクリックして圧縮されたファイルを見つけます。
ワークスペースで使用する新しい名前を入力します。 データセットに割り当てる名前は、含まれるファイルが抽出されるワークスペース内のフォルダーの名前になります。
zip パッケージを Studio (クラシック) にアップロードした後、圧縮されたファイルが [保存されたデータセット] 一覧で使用可能であることを確認し、データセットを スクリプト バンドル 入力ポートに接続します。
ZIP ファイルに含まれるすべてのファイルは、実行時に使用できます (サンプル データ、スクリプト、新しい Python パッケージなど)。
zip ファイルに、Machine Learning Studio (クラシック) にまだインストールされていないライブラリが含まれている場合は、カスタム スクリプトの一部として Python ライブラリ パッケージをインストールする必要があります。
ディレクトリ構造が存在する場合は、保持されます。 ただし、ディレクトリ src をパスの前に追加するようにコードを変更する必要があります。
Python コードのデバッグ
Python スクリプトの実行モジュールは、一連の疎関連の実行可能ステートメントではなく、明確に定義された入力と出力を持つ関数としてコードが要素化されている場合に最適です。
この Python モジュールでは、Intellisense やデバッグなどの機能はサポートされていません。 実行時にモジュールが失敗した場合は、モジュールの出力ログにエラーの詳細を表示できます。 ただし、完全な Python スタック トレースは使用できません。 したがって、ユーザーが別の環境で Python スクリプトを開発してデバッグし、そのコードをモジュールにインポートすることをお勧めします。
検索できる一般的な問題:
戻
azureml_mainるデータ フレーム内のデータ型を確認します。 列に数値型と文字列以外のデータ型が含まれている場合、エラーが発生する可能性があります。Python スクリプトからのエクスポート時に使用して
dataframe.dropna()、データセットから NA 値を削除します。 データを準備する場合は、 Clean Missing Data モジュールを使用します。埋め込みコードでインデントと空白のエラーを確認します。 "IndentError: expected an indented block"というエラーが発生した場合は、次のリソースを参照してガイダンスを参照してください。
既知の制限事項
Python ランタイムはサンドボックス化されており、永続的な方法でネットワークまたはローカル ファイル システムへのアクセスを許可しません。
ローカルに保存されているすべてのファイルは分離され、モジュールが終了すると削除されます。 Python コードは、現在のディレクトリとそのサブディレクトリを除く、実行中のコンピューターのほとんどのディレクトリにアクセスできません。
圧縮されたファイルをリソースとして指定すると、ファイルはワークスペースから実験実行空間にコピーされ、開梱されて使用されます。 リソースをコピーして開梱すると、メモリが消費される可能性があります。
モジュールは、1 つのデータ フレームを出力できます。 トレーニング済みのモデルなどの任意の Python オブジェクトを Studio (クラシック) ランタイムに直接返すことはできません。 ただし、ストレージまたはワークスペースにオブジェクトを書き込むことができます。 もう 1 つのオプションは、複数のオブジェクトをバイト配列にシリアル化し、データ フレーム内の配列を返すために使用
pickleすることです。
例
Python スクリプトと Studio (クラシック) の実験の統合の例については、 Azure AI ギャラリーで次のリソースを参照してください。
- Python スクリプトの実行: Python スクリプトの実行 モジュールを使用して、テキスト トークン化、ステミング、およびその他の自然言語処理を使用します。
- Azure ML のカスタム R スクリプトと Python スクリプト: カスタム コード a (R または Python のいずれか) を追加し、データを処理し、結果を視覚化するプロセスについて説明します。
- Python 3 のサポートを決定するための PyPI データの分析: Python 3 の需要が Python を使用して Python 2.7 の需要を上回る時点を推定します。