Microsoft Sentinel の Kusto 照会言語
Kusto 照会言語は、Microsoft Sentinel でデータを扱う作業や操作を行うために使用する言語です。 ワークスペースに取り込むログは、それを分析して、そのすべてのデータに隠されている重要な情報を入手できなければ、それほど価値がありません。 Kusto 照会言語には、そうした情報を手に入れるための機能と柔軟性だけでなく、それにすばやく着手するのに役立つシンプルさが備わっています。 スクリプト作成やデータベース操作に関する背景知識をお持ちの方は、この記事の内容の多くに、非常に馴染みがあると感じられるでしょう。 そうでなくても心配はいりません。この言語の直感的な性質により、独自のクエリの作成と、組織のための価値向上をすばやく開始できます。
この記事では、Kusto 照会言語の基礎知識を紹介します。最もよく使用される関数と演算子の一部を取り上げますが、これらにより、日常的に記述するクエリの 75% から 80% に対処できるはずです。 さらに深い知識や、より高度なクエリを実行する必要がある場合は、新しい Advanced KQL for Microsoft Sentinel ブックを利用できます (この入門ブログ記事を参照してください)。 Kusto 照会言語の公式ドキュメントと、さまざまなオンライン コース (Pluralsight のものなど) も参照してください。
背景情報 - Kusto 照会言語を選択する理由
Microsoft Sentinel は Azure Monitor サービス上に構築されており、Azure Monitor の Log Analytics ワークスペースを使用してすべてのデータを格納します。 このデータには、以下のどれもが含まれます。
- Microsoft Sentinel データ コネクタを使用して外部ソースから定義済みのテーブルに取り込まれたデータ。
- カスタムで作成されたデータ コネクタと、既存の一部の種類のコネクタを使用して、外部ソースからユーザー定義のカスタム テーブルに取り込まれたデータ。
- Microsoft Sentinel で作成して実行する分析によって得られる、Microsoft Sentinel 自体によって作成されるデータ。アラート、インシデント、UEBA 関連の情報などです。
- 脅威インテリジェンス フィードやウォッチリストなど、検出や分析を支援するために Microsoft Sentinel にアップロードされるデータ。
Kusto 照会言語は、Azure Data Explorer サービスの一部として開発されました。そのため、クラウド環境内のビッグ データ ストアを検索するために最適化されています。 これは、有名な海中探検家ジャック・クストーに着想を得て、データの海を深く掘り下げて、隠れた宝を探るのに役立つ設計となっています。
Kusto 照会言語は、追加の Azure Monitor 機能を含む Azure Monitor (したがって Microsoft Sentinel) で、Log Analytics データ ストア内のデータを取得、視覚化、分析、解析するためにも使用できます。 Microsoft Sentinel では、既存のルールやブック内でも、独自のものを構築する場合でも、データを視覚化して分析し、脅威のハンティングを行おうとしている場合には常に、Kusto 照会言語に基づくツールを使用することになります。
Kusto 照会言語は、Microsoft Sentinel で行うことの、ほぼすべての一部となっているため、それがどのように機能するかを明確に理解することは、はるかに多くの成果を SIEM から得る助けになります。
クエリとは
Kusto 照会言語のクエリは、データを処理して結果を返す読み取り専用の要求であり、いかなるデータも書き込みません。 データベース、テーブル、列から成る、SQL に似た階層に整理されたデータに対して、クエリの操作が行われます。
要求は平易な言語で記述され、構文の読み取り、書き込み、自動化が容易になるように設計されたデータ フロー モデルが使用されます。 この詳細を確認してゆきます。
Kusto 照会言語クエリは、セミコロンで区切られたステートメントで構成されます。 ステートメントには多くの種類がありますが、広く使用されているのは、ここで説明する 2 つの種類のみです。
表形式の式ステートメントは、クエリについて語るときに通常意味されるもので、これらがクエリの実際の本文です。 表形式の式ステートメントについて知る必要がある重要なことは、これらは表形式の入力 (テーブルまたは別の表形式) を受け取り、表形式の出力を生成するという点です。 これらが少なくとも 1 つ必要です。 この記事の残りの部分の大半で、この種のステートメントについて説明します。
let ステートメントを使用すると、クエリの本文の外部で変数と定数を作成および定義できるので、読みやすさや汎用性を高めやすくなります。 これは省略可能で、特定のニーズに依存します。 この種のステートメントについては、記事の最後で説明します。
デモ環境
この記事で取り上げるものを含め、Kusto 照会言語ステートメントは、Azure portal の Log Analytics デモ環境で練習できます。 この練習環境を使用するのに料金はかかりませんが、アクセスするために Azure アカウントは必要です。
デモ環境を試してみてください。 運用環境の Log Analytics と同様に、これはさまざまな方法で使用できます。
クエリの作成対象にするテーブルを選択します。 既定の (左上の赤い四角形で示した) [テーブル] タブで、トピック別にグループ化されたテーブルの一覧 (左下に表示) からテーブルを選択します。 トピックを展開して個々のテーブルを表示します。各テーブルをさらに展開すると、すべてのフィールド (列) を表示できます。 テーブルまたはフィールド名をダブルクリックすると、それがクエリ ウィンドウ内のカーソルの位置に配置されます。 下で指示するように、テーブル名に続けて残りのクエリを入力します。
調べたり変更したりする既存のクエリを検索します。 (左上の赤い四角形で示した) [クエリ] タブを選択して、既定で使用できるクエリの一覧を表示します。 または、右上のボタン バーから [クエリ] を選択します。 Microsoft Sentinel に標準で付属しているクエリを調べてみることができます。 クエリをダブルクリックすると、クエリ ウィンドウ内のカーソルの位置にクエリ全体が配置されます。
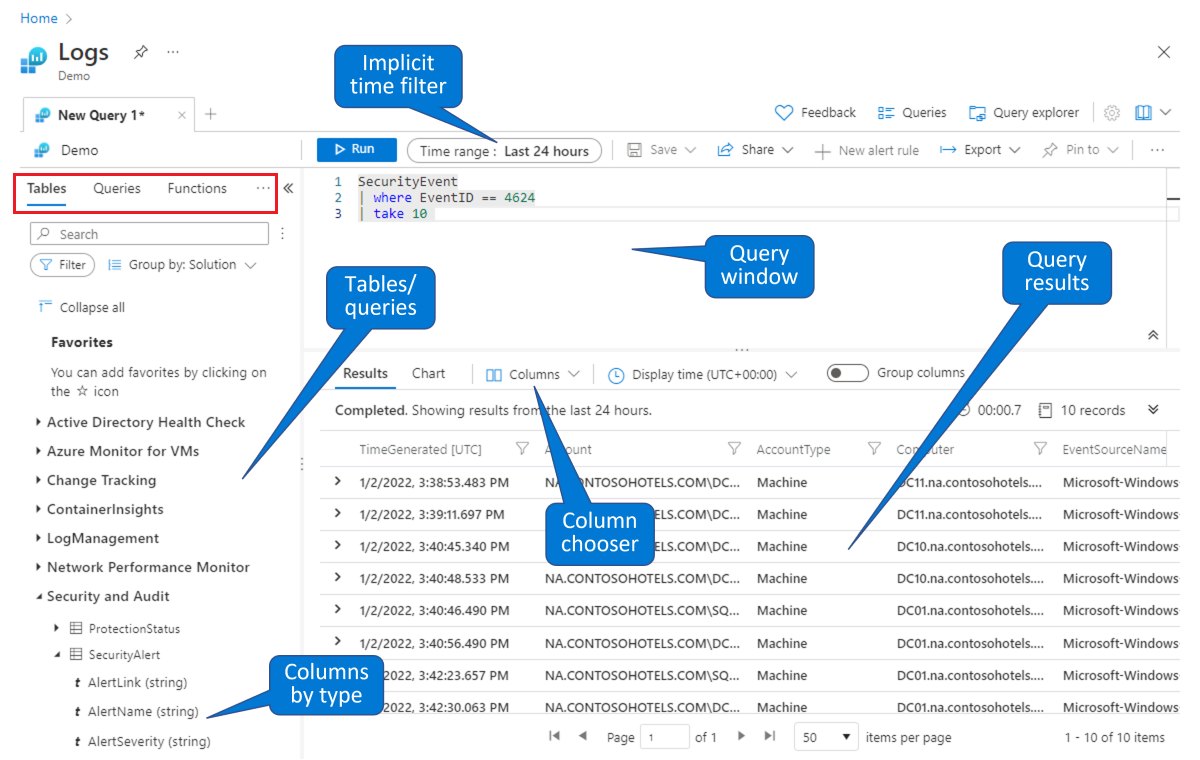
このデモ環境と同様に、Microsoft Sentinel の [ログ] ページで、データのクエリ実行とフィルター処理を行えます。 テーブルを選択してドリルダウンすると、列を表示できます。 [列の選択] を使用して表示される既定の列を変更できます。また、クエリの既定の時間範囲を設定できます。 クエリで時間範囲が明示的に定義されている場合、時間フィルターは使用できなくなります (淡色表示されます)。
クエリ構造
Kusto 照会言語の学習を始めるのに適しているのは、全体的なクエリ構造を理解することです。 Kusto のクエリを見て最初に気付くのは、パイプ記号 (|) の使用です。 Kusto クエリは、最初にデータ ソースからデータを取得してから、そのデータを全体としての "パイプライン" に渡し、各ステップである程度の処理を提供したら、次の手順にデータを渡すという構造になっています。 パイプラインの終わりで、最終的な結果が得られます。 ここで取り上げるパイプラインは、実際には次のようになっています。
Get Data | Filter | Summarize | Sort | Select
パイプラインの下流に向けてデータを渡すというこの概念により、各ステップでのデータをイメージするのが簡単なため、非常に直感的な構造が生み出されています。
これを具体的に確認するため、Microsoft Entra のサインイン ログを調べる次のクエリを見てみましょう。 それぞれの行を読んでゆくと、データに対して何が起きているかを示すキーワードを確認できます。 パイプライン内には、各行のコメントとして、関連するステージを含めてあります。
Note
コメントの前に二重スラッシュ (//) を付けると、クエリ内の任意の行にコメントを追加できます。
SigninLogs // Get data
| evaluate bag_unpack(LocationDetails) // Ignore this line for now; we'll come back to it at the end.
| where RiskLevelDuringSignIn == 'none' // Filter
and TimeGenerated >= ago(7d) // Filter
| summarize Count = count() by city // Summarize
| sort by Count desc // Sort
| take 5 // Select
どのステップの出力も後続のステップの入力として機能するためため、ステップの順序によってクエリの結果が決まり、パフォーマンスに影響が及ぶ可能性があります。 クエリから何を取得しようとするかに従ってステップを並べることが重要です。
ヒント
- 経験則として、関連性のあるデータのみをパイプラインの下流に渡すことになるように、早期にデータをフィルター処理します。 これによって、パフォーマンスが大幅に向上し、集計ステップに誤って関連性のないデータを含めることが確実になくなります。
- この記事では、念頭に置いておく必要のあるその他のベスト プラクティスをいくつか指摘します。 完全な一覧については、クエリのベスト プラクティスに関するページを参照してください。
これで、Kusto 照会言語のクエリの全体的構造を理解できたことでしょう。 ここからは、クエリの作成に使用される実際のクエリ演算子自体を見てゆきましょう。
データ型
クエリ演算子の説明に入る前に、まず、データ型について簡単に確認してみましょう。 ほとんどの言語と同様に、値に対してどのような計算や操作を実行できるかは、データ型によって決まります。 たとえば、string 型の値がある場合、それに対しては、算術計算を実行することはできません。
Kusto 照会言語では、ほとんどのデータ型は標準的な規則に従っており、おそらく前に見たことがある名前が付いています。 次の表に、完全な一覧を示します。
データ型の表
| Type | その他の名前 | 同等の .NET 型 |
|---|---|---|
bool |
Boolean |
System.Boolean |
datetime |
Date |
System.DateTime |
dynamic |
System.Object |
|
guid |
uuid、uniqueid |
System.Guid |
int |
System.Int32 |
|
long |
System.Int64 |
|
real |
Double |
System.Double |
string |
System.String |
|
timespan |
Time |
System.TimeSpan |
decimal |
System.Data.SqlTypes.SqlDecimal |
ほとんどのデータ型は標準的ですが、dynamic、timespan、guid のような型にはあまり馴染みがないかも知れません。
dynamic には JSON とよく似た構造がありますが、1 つ重要な違いがあります。これは、入れ子になった dynamic 値や timespan など、従来の JSON では不可能な Kusto 照会言語固有のデータ型を格納できます。 次に、dynamic 型の例を示します。
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
timespan は、時間、日、秒などの時間の単位を指すデータ型です。 timepan を datetime と混同しないでください。後者は時間の単位ではなく、実際の日付と時刻に評価されます。 次の表に、timespan のサフィックスを示します。
timespan のサフィックス
| 関数 | 説明 |
|---|---|
D |
days |
H |
時間 |
M |
minutes |
S |
seconds |
Ms |
ミリ秒 |
Microsecond |
マイクロ秒 |
Tick |
ナノ秒 |
guid は、標準形式の [8]-[4]-[4]-[4]-[12] に従う 128 ビットのグローバル一意識別子を表すデータ型です。それぞれの [数値] は文字数を表しており、各文字の範囲は 0 ~ 9 または a ~ f です。
Note
Kusto 照会言語には、表形式演算子とスカラー演算子の両方があります。 この記事の残りの部分ではすべて、単に "演算子" という単語がある場合は、他の説明がない限り表形式演算子を意味すると見なすことができます。
データの取得、制限、並べ替え、フィルター処理
Kusto 照会言語の中核となるボキャブラリは、データのフィルター処理、並べ替え、および選択のための演算子のコレクションです。これらが、タスクの圧倒的多数を達成できるようにする基盤となっています。 実行する必要がある残りのタスクでは、実際のより高度なニーズに合わせて、言語の知識を広げることが必要になります。 上の例で使用したコマンドの一部を少し拡張して、take、sort、where について確認してみましょう。
これらの演算子それぞれについて、前の SigninLogs の例でその使い方を調べ、役立つヒントやベスト プラクティスを学びます。
データの取得
基本的なクエリの最初の行では、操作対象にするテーブルを指定します。 Microsoft Sentinel の場合、これはおそらく、SigninLogs、SecurityAlert、CommonSecurityLog などの、ワークスペース内のログの種類の名前になります。 次に例を示します。
SigninLogs
Kusto 照会言語では、ログ名の大文字と小文字は区別されます。そのため、SigninLogs と signinLogs は異なるものと解釈されます。 カスタム ログの名前を選択するときには、識別が容易で、別のログと類似しすぎないものにするように注意してください。
データの制限: take / limit
take 演算子 (および同等の limit 演算子) は、指定された数の行のみを返して結果を限定するために使用されます。 その後に、返す行の数を指定する整数を続けます。 これは一般に、並べ替えの順序を決定した後に、クエリの最後で使用されます。そしてそのような場合に、並べ替えた順序の先頭側にある、指定した行数が返されます。
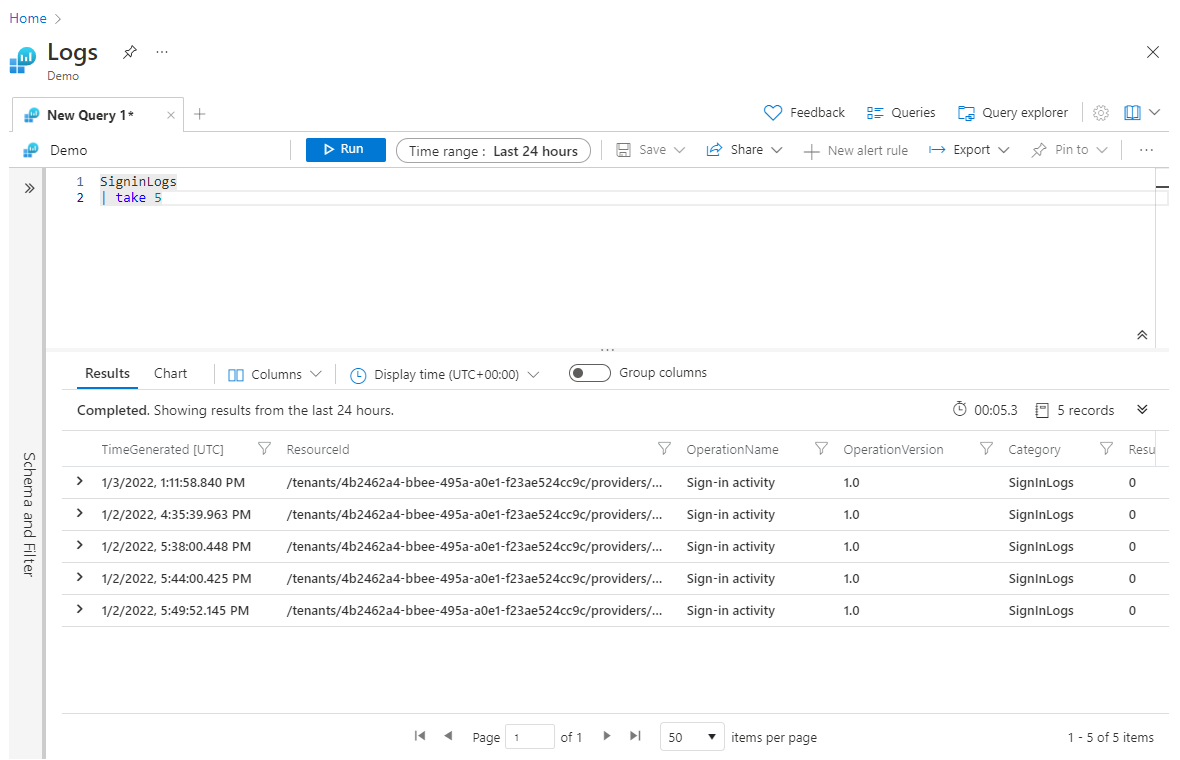
大きなデータセットを返したくないときには、クエリ内の前方で take を使用すると、クエリのテストに便利な場合があります。 ただし、take 操作をいずれかの sort 操作の前に配置すると、take はランダムに選択された行を返します。また、クエリが実行されるたびに異なる行セットが返される可能性があります。 次に、take の使用例を示します。
SigninLogs
| take 5
ヒント
クエリがどのようになるか不明なまったく新しいクエリを扱うときには、先頭に take ステートメントを配置してデータセットを人為的に制限すると、処理や実験の速度を高めるのに便利な場合があります。 クエリ全体に満足できるようになったら、最初の take のステップを削除できます。
並べ替え: sort / order
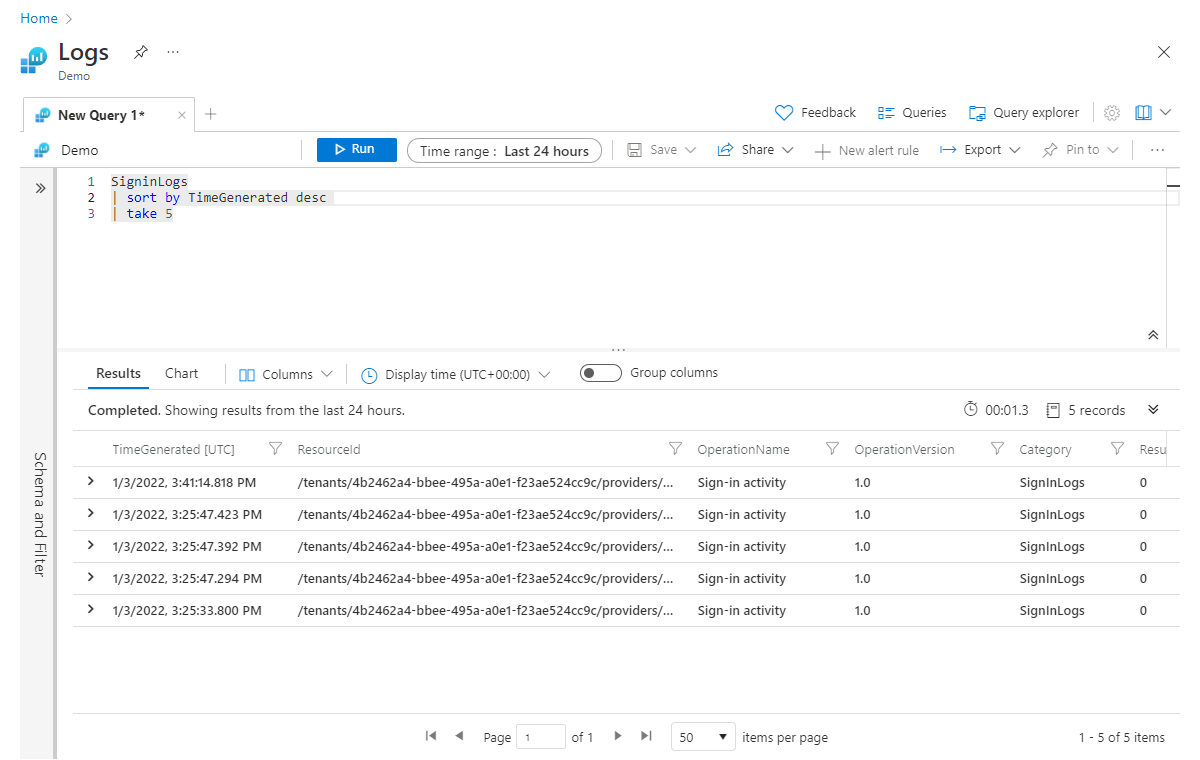
sort 演算子 (および同等の order 演算子) は、指定した列でデータを並べ替えるために使用します。 次の例では、結果を TimeGenerated で並べ替え、desc パラメーターを使用して順序の方向を降順に設定し、最も高い値を先頭に配置しました。昇順の場合は asc を使用します。
Note
並べ替えの既定の方向は降順なので、技術的には、指定する必要があるのは昇順で並べ替える場合のみです。 ただし、どのような場合でも、並べ替えの方向を指定するとクエリが読みやすくなります。
SigninLogs
| sort by TimeGenerated desc
| take 5
前述したように、sort 演算子を take 演算子の前に配置します。 適切な 5 つのレコードを確実に取得するには、最初に並べ替えが必要です。
上位
top 演算子を使用すると、sort と take の操作を 1 つの演算子に結合できます。
SigninLogs
| top 5 by TimeGenerated desc
並べ替えようとしている列内に同じ値のレコードが 2 つ以上ある場合は、並べ替えに使用する列をさらに追加できます。 最初の並べ替え列の後の、並べ替え順序のキーワードの前に配置するコンマ区切りのリストで、追加の並べ替え列を追加します。 次に例を示します。
SigninLogs
| sort by TimeGenerated, Identity desc
| take 5
ここでは、複数のレコード間で TimeGenerated が同じ場合は、Identity 列の値で並べ替えを試みます。
注意
sort と take をいつ使用し、top をいつ使用するか
1 つのフィールドでのみ並べ替える場合は、
topを使用します。sortとtakeの組み合わせよりも、実現されるパフォーマンスが高いためです。(上記の例のように) 複数のフィールドで並べ替える必要がある場合、
topではそれができないので、sortとtakeを使用する必要があります。
データのフィルター処理: where
where 演算子は、おそらく最も重要な演算子です。これは、実際のシナリオに関連性のあるデータのサブセットのみを確実に操作対象とするための鍵であるためです。 クエリ内では、可能な限り早い段階でデータをフィルター処理するために最善を尽くす必要があります。そうすることで、後続のステップで処理する必要があるデータ量が減少し、クエリのパフォーマンスが向上するためです。また、適切なデータに対してのみ計算が実行されることが保証されます。 こちらの例を参照してください。
SigninLogs
| where TimeGenerated >= ago(7d)
| sort by TimeGenerated, Identity desc
| take 5
where 演算子では、変数、比較 ("スカラー") 演算子、および値を指定します。 この例では >= を使用して、TimeGenerated 列の値が 7 日前より大きい (つまり、それより後である) か、等しい必要があることを示しました。
Kusto 照会言語には、文字列と数値の 2 種類の比較演算子があります。 次の表に、数値演算子の完全な一覧を示します。
数値演算子
| 演算子 | 説明 |
|---|---|
+ |
加算 |
- |
減算 |
* |
乗算 |
/ |
除算 |
% |
剰余 |
< |
より小さい |
> |
より大きい |
== |
等しい |
!= |
等しくない |
<= |
以下 |
>= |
以上 |
in |
要素のいずれかに等しい |
!in |
要素のいずれとも等しくない |
文字列演算子の一覧は、大文字と小文字の区別、部分文字列の位置、プレフィックス、サフィックスなどの組み合わせが存在するため、ずっと長いものになります。 == 演算子は数値と文字列の両方の演算子であり、数値とテキストの両方に使用できます。 たとえば、以下のステートメントはどちらも有効な where ステートメントになります。
| where ResultType == 0| where Category == 'SignInLogs'
ヒント
ベスト プラクティス: ほとんどの場合に、おそらく、複数の列でデータをフィルター処理するか、同じ列を複数の方法でフィルター処理することをお勧めできます。 これらの場合に気を付ける必要があるベスト プラクティスが 2 つあります。
キーワードと キーワードを使用すると、複数の where ステートメントを 1 つのステップに結合できます。 たとえば、次のように入力します。
SigninLogs
| where Resource == ResourceGroup
and TimeGenerated >= ago(7d)
上記のように、 キーワードと キーワードを使用して複数のフィルターを 1 つの where ステートメントに結合するときには、単一列のみを参照するフィルターを最初に配置することで、パフォーマンスが向上します。 そのため、上のクエリのより良い記述方法は、次のようになります。
SigninLogs
| where TimeGenerated >= ago(7d)
and Resource == ResourceGroup
この例では、最初のフィルターに記述されるのは単一列 (TimeGenerated) であるのに対して、2 番目では 2 つの列 (Resource と ResourceGroup) を参照しています。
データの集計
Summarize は、Kusto 照会言語で最も重要な表形式演算子の 1 つですが、クエリ言語全般に慣れていない場合には、学習するのがより複雑である演算子の 1 つでもあります。 summarize の仕事は、データのテーブルを取得し、1 つ以上の列で集計された新しいテーブルを出力することです。
summarize ステートメントの構造
summarize ステートメントの基本的構造は次のとおりです。
| summarize <aggregation> by <column>
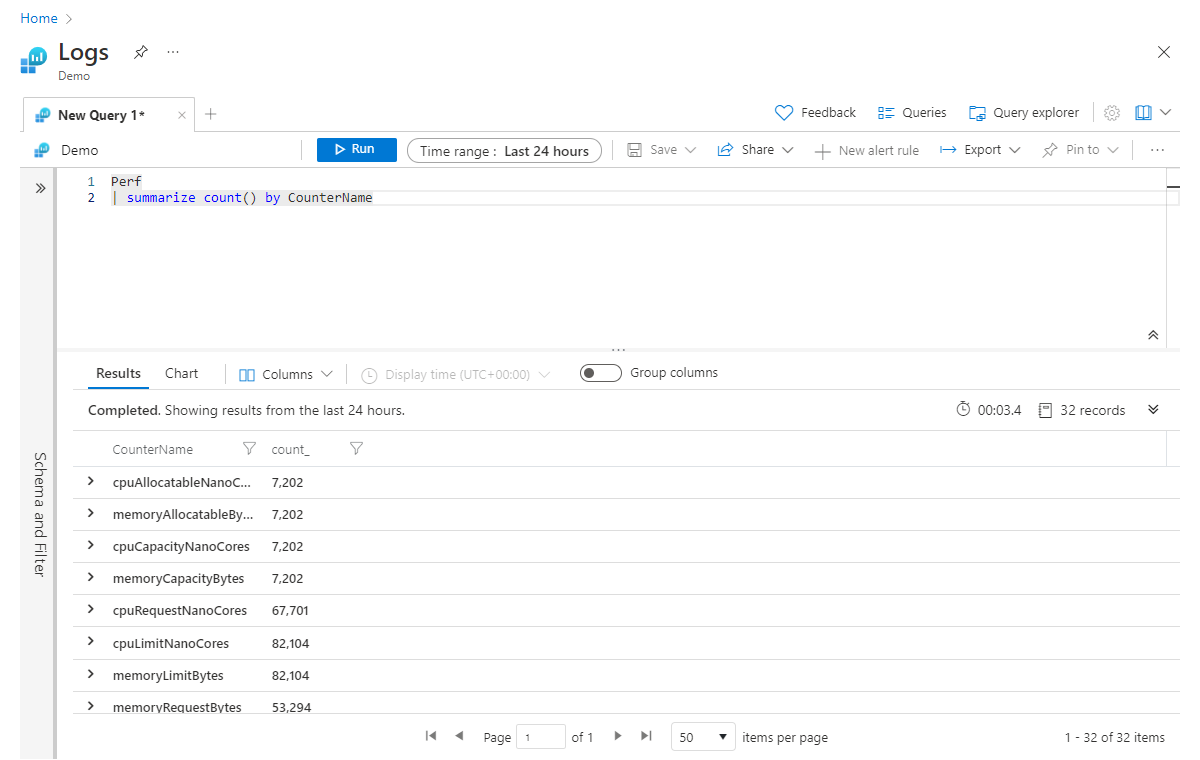
たとえば次からは、Perf テーブル内の CounterName 値ごとにレコードの数が返されます。
Perf
| summarize count() by CounterName
summarize の出力は新しいテーブルなので、summarize ステートメントで明示的に指定されていない列はパイプラインの下流に渡されません。 この概念を説明するため、次の例について考えてみます。
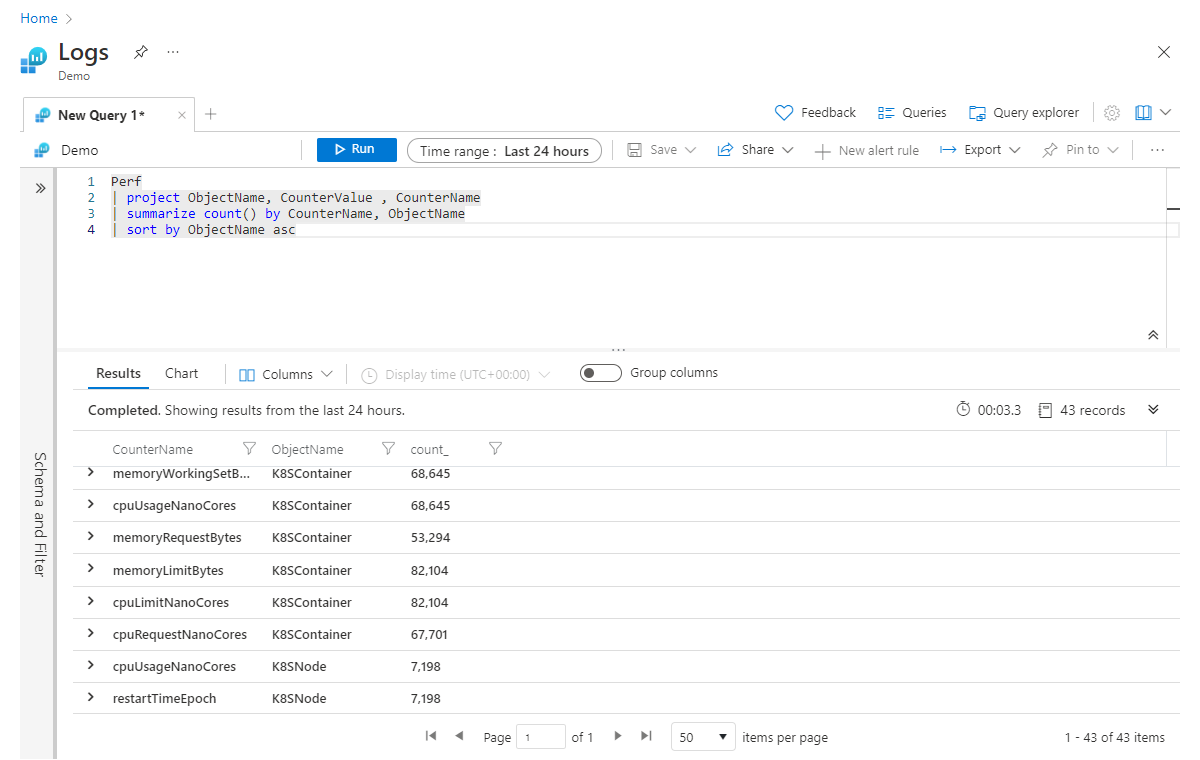
Perf
| project ObjectName, CounterValue, CounterName
| summarize count() by CounterName
| sort by ObjectName asc
2 行目では、ObjectName、CounterValue、CounterName の各列のみが対象であることを指定しています。 次に、CounterName でレコード数を取得するように集計し、最後に ObjectName 列に基づいてデータを昇順に並べ替えようとしています。 残念ながら、このクエリは (ObjectName が不明であることを示す) エラーで失敗します。集計したときに、新しいテーブルには Count 列と CounterName 列だけを含めたためです。 このエラーを回避するには、次のように、summarize ステップの最後に ObjectName を追加します。
Perf
| project ObjectName, CounterValue , CounterName
| summarize count() by CounterName, ObjectName
| sort by ObjectName asc
頭の中での summarize 行の読み方は、"CounterName でレコード数を集計し、ObjectName でグループ化する" となります。 コンマで区切れば、summarize ステートメントの最後にさらに列を追加できます。
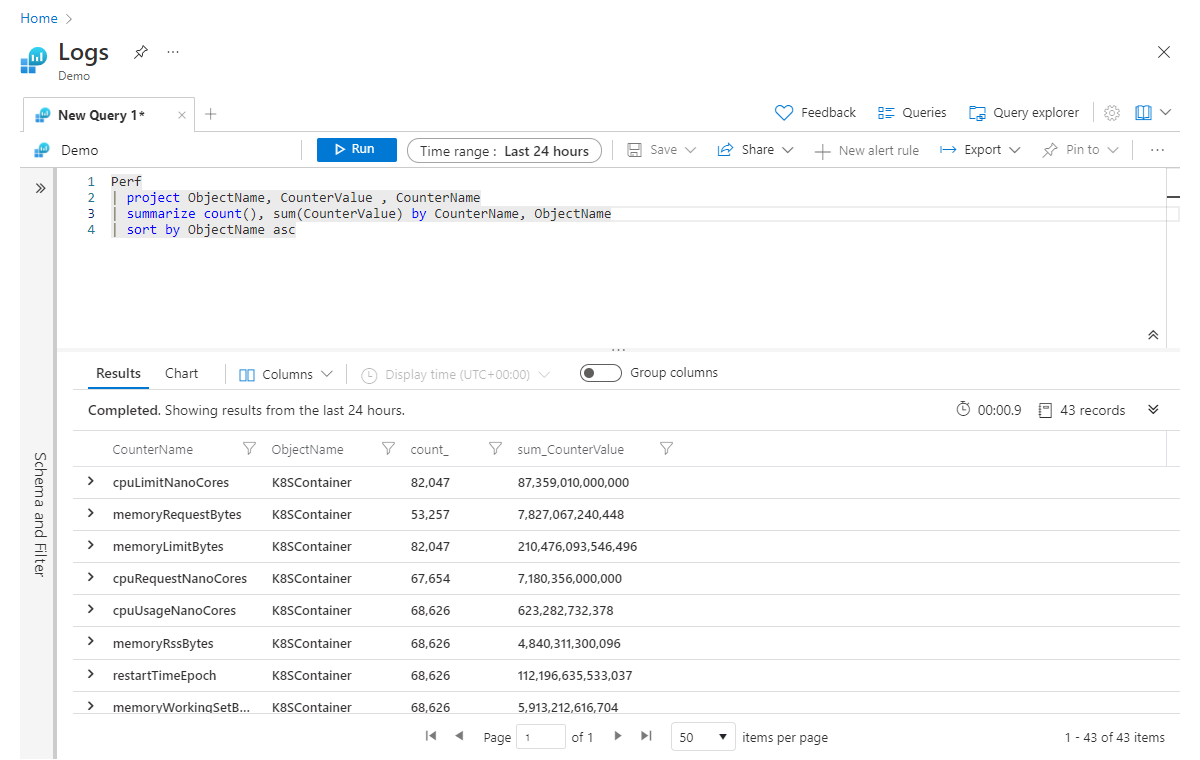
前の例を基にして、複数の列を同時に集計するとします。これは、コンマで区切って summarize 演算子に集計を追加することで実現できます。 次の例では、すべてのレコードの数だけでなく (クエリ内の任意のフィルターと一致する) すべてのレコードにわたって、CounterValue 列の値の合計も取得しようとしています。
Perf
| project ObjectName, CounterValue , CounterName
| summarize count(), sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
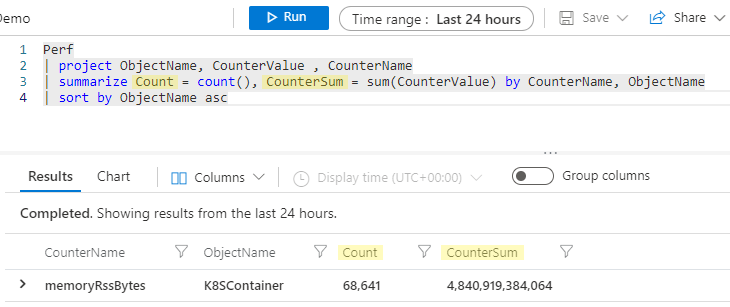
集計列の名前の変更
これは、このような集約列の列名について説明するのに良いタイミングのように思われます。 このセクションの最初に、summarize 演算子はデータのテーブルを取り込んで新しいテーブルを生成し、summarize ステートメントで指定する列だけが引き続きパイプライン下流に進むと説明しました。 したがって、上記の例を実行した場合、この集計の結果の列は count_ と sum_CounterValue になります。
Kusto エンジンでは、ユーザーが明示的に指定しなくても列名が自動的に作成されますが、多くの場合、新しい列には、よりわかりやすい名前を付けることが望まれます。 列の名前は、summarize ステートメントで、新しい名前を指定し、その後に = と集計を指定すれば簡単に変更できます。このようにします。
Perf
| project ObjectName, CounterValue , CounterName
| summarize Count = count(), CounterSum = sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
これで、集計列の名前は Count と CounterSum になります。
summarize 演算子には、ここで説明できることよりもずっと多くの機能がありますが、Microsoft Sentinel データに対してデータ分析を実行する予定であれば、これは重要なコンポーネントなので学習に時間を費やす必要があります。
集計に関するリファレンス
多くの集計関数がありますが、最もよく使用されるものを一部挙げれば、sum()、count()、avg() です。 以下に部分的な一覧を示します (完全な一覧を参照してください)。
集計関数
| 関数 | 説明 |
|---|---|
arg_max() |
引数が最大化されている場合に 1 つ以上の式を返します |
arg_min() |
引数が最小化されている場合に 1 つ以上の式を返します |
avg() |
グループの平均値を返します |
buildschema() |
dynamic 入力のすべての値を受け入れる最小スキーマを返します |
count() |
グループの数を返します |
countif() |
グループの述語を使用して数を返します |
dcount() |
グループ要素の個別の概数を返します |
make_bag() |
グループ内の動的な値のプロパティ バッグを返します |
make_list() |
グループ内のすべての値の一覧を返します |
make_set() |
グループ内の個別の値のセットを返します |
max() |
グループ全体の最大値を返します |
min() |
グループ全体の最小値を返します |
percentiles() |
グループのパーセンタイルの概数を返します |
stdev() |
グループ全体の標準偏差を返します |
sum() |
グループ内の要素の合計を返します |
take_any() |
グループの空でないランダム値を返します |
variance() |
グループ全体の分散を返します |
選択: 列の追加と削除
より多くのクエリを扱い始めると、対象に関して必要以上の情報がある (つまり、テーブル内の列が多すぎる) と判明する場合があります。 また、持っているよりも多くの情報が必要なこともあります (つまり、他の列の分析結果が含まれる新しい列を追加する必要がある)。 列の操作に関する主な演算子をいくつか見てゆきましょう。
project と project-away
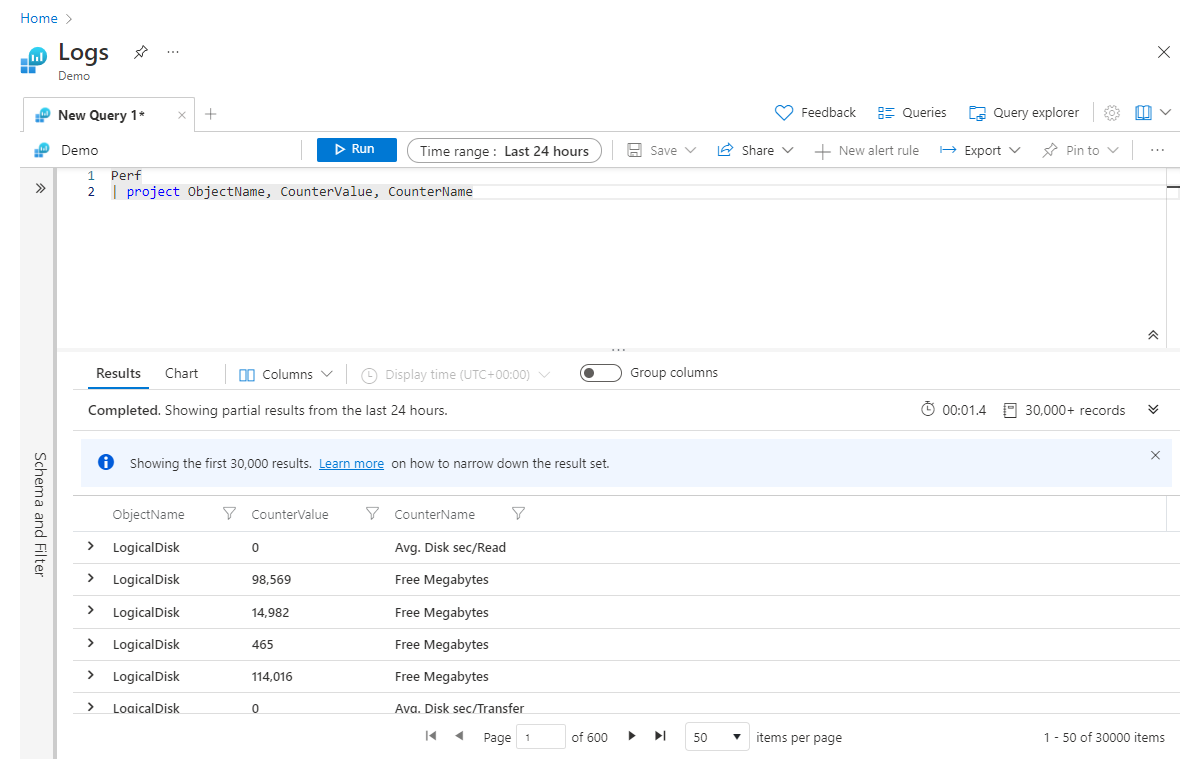
project は、おおよそ、多くの言語の select ステートメントに相当します。 これを使用すると、どの列を保持しておくかを選択できます。 返される列の順序は、次の例に示すように、project ステートメントで列挙する列の順序と同じになります。
Perf
| project ObjectName, CounterValue, CounterName
想像できるように、非常に広範囲にわたるデータセットを操作するときには、保持したい列が多数ある場合があり、それらをすべて名前で指定するには大量の入力が必要になります。 そのような場合は、次のように、保持する列ではなく削除する列を指定できる project-away が用意されています。
Perf
| project-away MG, _ResourceId, Type
ヒント
project は、クエリ内の先頭と末尾の 2 つの場所で使用すると役立つ場合があります。 クエリ内の前方で project を使用すると、パイプラインの下流に渡す必要がない大量のデータを除去することでパフォーマンスを高めることができます。 これを最後にもう一度使用すると、以前のステップで作成されることがあり、最終的な出力では必要ない列を取り除くことができます。
延長
Extend は、新しい計算列を作成するために使用します。 これは、既存の列に対して計算を実行し、すべての行の出力を表示するときに便利な場合があります。 Kbytes という名前の新しい列を計算する簡単な例を見てみましょう。これは、MB 値 (既存の Quantity 列内) に 1,024 を乗算して計算できます。
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| project ResourceUri, MBytes=Quantity, KBytes
project ステートメントの最後の行で、Quantity 列の名前を Mbytes に変更したので、各列に関連する測定単位を簡単に確認できます。
extend は、既に計算されている列でも機能することに注目してください。 たとえば、Kbytes から計算される Bytes という名前の列を 1 つ追加できます。
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| extend Bytes = KBytes * 1024
| project ResourceUri, MBytes=Quantity, KBytes, Bytes
テーブルの結合
Microsoft Sentinel での作業の多くは、1 種類のログを使用して実行できますが、別のデータ セットに対して、データを相互に関連付けたり、検索を実行したりする必要が生じる場合もあります。 ほとんどのクエリ言語と同様に、Kusto 照会言語には、さまざまな種類の結合を実行するために使用される演算子がいくつか用意されています。 このセクションでは、最も使用される演算子である union と join について説明します。
Union (結合)
union では、単純に、複数のテーブルが受け取られて、すべての行が返されます。 次に例を示します。
OfficeActivity
| union SecurityEvent
これにより、OfficeActivity と SecurityEvent の両方のテーブルからすべての行が返されます。 Union には、結合がどのように動作するかを調整するために使用できるパラメーターがいくつか用意されています。 最も役立つのは、withsource と kind の 2 つです。
OfficeActivity
| union withsource = SourceTable kind = inner SecurityEvent
withsource パラメーターでは、指定した行の値が、その行の基になったテーブルの名前になる新しい列の名前を指定できます。 上の例では、列に SourceTable という名前を付けました。これで行に応じて、値は OfficeActivity または SecurityEvent のいずれかになります。
指定した別のパラメーターは kind で、これには inner と outer の 2 つのオプションがあります。 上の例では inner を指定しました。これは、結合時に保持される列は、両方のテーブルに存在する列だけであることを意味します。 または、outer (これが既定値です) を指定した場合は、両方のテーブルのすべての列が返されます。
Join
Join は union と同様に機能しますが、テーブルを結合して新しいテーブルを作成する代わりに、"行" を結合して新しいテーブルを作成します。 ほとんどのデータベース言語と同様に、実行できる join には複数の種類があります。 join の一般的な構文は次のとおりです。
T1
| join kind = <join type>
(
T2
) on $left.<T1Column> == $right.<T2Column>
join 演算子の後に、実行する join の kind を指定し、開いたかっこを続けます。 このかっこ内が、join の対象テーブルと、追加する "その" テーブルに対する他のクエリ ステートメントを指定する場所です。 閉じかっこの後ろで on キーワードを使用し、その後に、= = 演算子で区切って左の列 ($left.<columnName> キーワード) と右の列 ($right.<columnName>) を指定します。 次に、inner join の例を示します。
OfficeActivity
| where TimeGenerated >= ago(1d)
and LogonUserSid != ''
| join kind = inner (
SecurityEvent
| where TimeGenerated >= ago(1d)
and SubjectUserSid != ''
) on $left.LogonUserSid == $right.SubjectUserSid
Note
両方のテーブルで、join を実行しようとしている列に同じ名前が付いている場合は、$left と $right を使用する必要はありません。代わりに列名だけを指定できます。 ただし、$left と $right を使用する方が明示的であり、一般に適切な方法と見なされます。
参考のため、次の表に、使用できる join の種類の一覧を示します。
結合の種類
| 結合の種類 | 説明 |
|---|---|
inner |
両方のテーブルの一致する行の組み合わせごとに 1 つを返します。 |
innerunique |
左側のテーブルから、右側のテーブルに一致するものがあるリンク フィールドに別個の値がある行を返します。 これは未指定の場合の、既定の join の種類です。 |
leftsemi |
左側のテーブルから、右側のテーブルに一致するものがあるすべてのレコードを返します。 左側のテーブルの列だけを返します。 |
rightsemi |
右側のテーブルから、左側のテーブルに一致するものがあるすべてのレコードを返します。 右側のテーブルの列だけを返します。 |
leftanti/leftantisemi |
左側のテーブルから、右側のテーブルに一致するものがないすべてのレコードを返します。 左側のテーブルの列だけを返します。 |
rightanti/rightantisemi |
右側のテーブルから、左側のテーブルに一致するものがないすべてのレコードを返します。 右側のテーブルの列だけを返します。 |
leftouter |
左側のテーブルからすべてのレコードを返します。 右側のテーブルに一致がないレコードについては、セルの値が null になります。 |
rightouter |
右側のテーブルからすべてのレコードを返します。 左側のテーブルに一致がないレコードについては、セルの値が null になります。 |
fullouter |
一致の有無を問わず、左と右の両方のテーブルからすべてのレコードを返します。 一致していない値は null になります。 |
ヒント
ベスト プラクティスは、最も小さいテーブルを左側に置くことです。 実行しようとしている join の種類やテーブルのサイズによっては、場合により、この規則に従うとパフォーマンス面で非常に大きなメリットが得られることがあります。
Evaluate
最初の例には、行の 1 つに evaluate 演算子があったことを思い出してください。 evaluate 演算子の使用頻度は、ここまでに触れた演算子よりも高くありません。 ただし、evaluate 演算子がどのように機能するかを理解することは、時間を費やす価値が十分にあります。 ここで再度、その最初のクエリを示します。2 行目に evaluate があります。
SigninLogs
| evaluate bag_unpack(LocationDetails)
| where RiskLevelDuringSignIn == 'none'
and TimeGenerated >= ago(7d)
| summarize Count = count() by city
| sort by Count desc
| take 5
この演算子を使用すると、使用できるプラグイン (基本的に組み込み関数) を呼び出すことができます。 これらのプラグインの多くは、autocluster、diffpatterns、sequence_detect などのデータ サイエンスに焦点を合わせており、高度な分析の実行や、統計的異常と外れ値の検出が可能になります。
上の例で使用したプラグインは bag_unpack という名前でした。これを使用すると、動的なデータのチャンクを取得して列に変換することが非常に簡単になります。 dynamic 型データは、次の例に示すように、JSON に非常によく似ているデータ型であることを思い出してください。
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
この場合は、データを都市別に集計する必要がありましたが、city は LocationDetails 列内にプロパティとして含まれています。 クエリで city プロパティを使用するには、最初に bag_unpack を使用して、それを列に変換する必要がありました。
最初のパイプラインのステップに戻ると、これが記載されていました。
Get Data | Filter | Summarize | Sort | Select
evaluate 演算子について考えてみたので、これはパイプラインの新しいステージを表していることがわかります。パイプラインはこれで、次のようになります。
Get Data | Parse | Filter | Summarize | Sort | Select
データソースをより読みやすく、操作しやすい形式に解析するために使用できる演算子と関数は、他にも多くの例があります。 それらについてと、Kusto 照会言語のその他の情報については、完全なドキュメントとブックで学習することができます。
let ステートメント
ここまで、主な演算子とデータ型の多くについて説明してきたので、let ステートメントで締めくくりましょう。これは、クエリの読み取り、編集、管理を容易にする優れた方法です。
let を使用すると、変数の作成と設定や、式への名前の割り当てを行うことができます。 この式は、単一値でもかまいませんが、クエリ全体でもかまいません。 簡単な例を次に示します。
let aWeekAgo = ago(7d);
SigninLogs
| where TimeGenerated >= aWeekAgo
ここでは、aWeekAgo という名前を指定し、それは timespan 関数の出力と等しいことを設定しました。これで、datetime 値が返されます。 次に、let ステートメントをセミコロンで終えています。 これで、クエリ内の任意の場所で使用できる aWeekAgo という名前の新しい変数を用意できました。
先ほど触れたように、let ステートメントを使用すると、クエリ全体を受け取って結果に名前を付けることができます。 表形式の式であるクエリ結果は、クエリの入力として使用できるため、この名前付きの結果は、それに対する別のクエリを実行することが目的のテーブルとして扱うことができます。 次に、前の例にわずかな変更を加えたものを示します。
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
この場合、クエリ全体を getSignins という名前の新しい変数にラップする 2 番目の let ステートメントを作成しました。 前と同様に、2 番目の let ステートメントをセミコロンで終えています。 次に、最後の行でこの変数を呼び出します。これにより、クエリが実行されます。 2 番目の let ステートメントで aWeekAgo を使用できたことに注目してください。 これは、それを前の行で指定したためです。getSignins が先になるように let ステートメントを入れ替えたとすると、エラーが発生します。
これで getSignins を (同じウィンドウ内で) 別のクエリの基礎として使用できるようになりました。
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
| where level >= 3
| project IPAddress, UserDisplayName, Level
let ステートメントによって、クエリの整理に役立つより強力な機能と柔軟性が得られます。 let では、スカラー値と表形式の値を定義できるだけでなく、ユーザー定義関数を作成することもできます。 これらは、複数の join を実行することもある、より複雑なクエリを整理するときに非常に役立ちます。
次の手順
この記事では初歩的な内容を説明しただけですが、必要な基盤は得られました。Microsoft Sentinel で作業を行うために最も頻繁に使用することになる部分については、ここで取り上げました。
Microsoft Sentinel 用の Advanced KQL ブック
Microsoft Sentinel 自体の中で、Kusto 照会言語のブックである Microsoft Sentinel 用の Advanced KQL ブックを利用します。 日常のセキュリティ業務中に発生する可能性のある多くの状況について、詳細な手順を含むヘルプや例が用意されています。また、既成のすぐに使用できる、分析ルール、ブック、ハンティング ルール、Kusto クエリを使用するより多くの要素が、多数示されています。 このブックは、Microsoft Sentinel の [ブック] ブレードから起動します。
「高度な KQL フレームワーク ブック - KQL に精通することを支援」は、このブックの使用方法を示している優れたブログ記事です。
その他のリソース
Kusto 照会言語の知識を広げたり深めたりするには、学習、トレーニング、スキルアップ用のリソースである、このコレクションを参照してください。