エンドポイント分析での異常検出
注:
この機能は、Intune アドオンとして使用できます。 詳細については、「 Intune アドオン」を参照してください。
この記事では、エンドポイント分析での異常検出が早期警告システムとしてどのように機能するかを説明します。
異常検出は、構成の変更後のユーザー エクスペリエンスと生産性の低下のために、organization内のデバイスの正常性を監視します。 エラーが発生すると、Anomalies は関連するデプロイ オブジェクトを関連付けて迅速なトラブルシューティングを可能にし、根本原因と修復を提案します。
管理者は、異常検出に依存して、他のチャネルを介して問題に到達する前に、問題に影響を与えるユーザー エクスペリエンスについて学習できます。 異常検出の最初の焦点は、アプリケーションのハング/クラッシュとエラーの再起動の停止です。
概要
異常検出では、システム内の潜在的な問題を検出してから、重大な問題になります。 従来、サポート チームでは潜在的な問題の可視性が制限されています。
多くの場合、サポート チャネルを通じて報告またはエスカレートされた問題のサブセットのみが取得されます。これは、organizationで起こっているすべてのことを本当に表すわけではありません。
ユーザーは、根本原因の特定、トラブルシューティング、カスタム アラートの作成、しきい値の変更、パラメーターの調整を試みるために、カスタム ダッシュボードの確認に数え切れないほどの時間を費やす必要があります。
異常検出は、IT 管理者が重要な情報を使用できるようにすることで、これらの問題に対処することを目的としています。
異常の検出に加えて、デバイスの関連付けグループを表示して、重大度が中程度および高の異常の潜在的な根本原因を調べることができます。 これらのデバイス コーホートを使用すると、デバイス間で識別されたパターンを表示できます。 また、これらのコーホートで "危険にさらされている" デバイスを特定することで、デバイス管理に対してプロアクティブなアプローチを取っています。 これらは、高い信頼度で識別されたパターンに該当するが、これらの異常をまだ見ていないデバイスです。
注:
デバイス コーホートは、重大度が中および高の異常に対してのみ識別されます。
前提条件
ライセンス/サブスクリプション: エンドポイント分析の高度な機能は、Microsoft Intune Suiteの Intune アドオンとして含まれており、Microsoft Intuneを含むライセンス オプションに追加コストが必要です。
アクセス許可: 異常検出では、組み込みのロールのアクセス許可が使用されます
[異常] タブ
Microsoft Intune管理センターにサインインします。
[レポート>エンドポイント分析の概要] を>選択します。
[異常] タブを選択します。[異常] タブには、organizationで検出された異常の概要が表示されます。
この例では、[異常] タブに重大度が中程度の異常が表示されます。 フィルターを追加して、一覧を絞り込むことができます。
![これは、エンドポイント分析の [概要] セクションの [異常] タブのスクリーンショットです](media/anomaly-detection/anomalies-tab.png)
特定の項目の詳細を表示するには、一覧から項目を選択します。 アプリの名前、影響を受けるデバイス、問題が最初に検出されて最後に発生したタイミング、問題の原因となっている可能性のあるデバイス グループなどの詳細を確認できます。
![これは、[異常] タブに表示される異常を選択したときに表示される詳細のスクリーンショットです](media/anomaly-detection/details-of-anomaly.png)
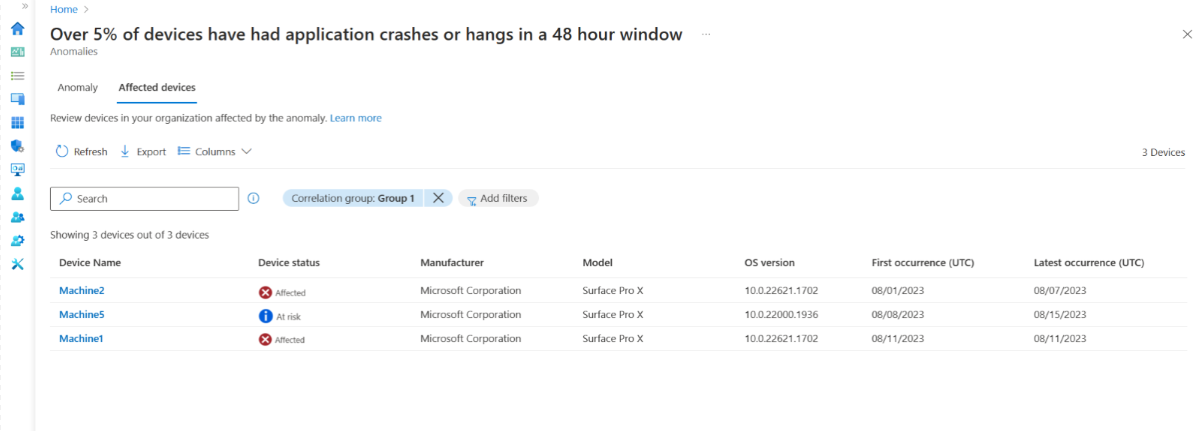
デバイスの一般的な要因の詳細なビューについては、一覧からデバイスの関連付けグループを選択します。 デバイスは、アプリのバージョン、ドライバーの更新プログラム、OS のバージョン、デバイス モデルなどの 1 つ以上の共有属性に基づいて関連付けられます。 現在、異常の影響を受けているデバイスの数と、異常が発生するリスクがあるデバイスを確認できます。 また、普及率は、相関グループのメンバーである異常からの影響を受けるデバイスの割合も示します。

[ 影響を受けるデバイスの表示 ] を選択して、各デバイスに関連するキー属性を持つデバイスの一覧を表示します。 フィルターを適用して、特定の関連付けグループ内のデバイスを表示したり、その異常の影響を受けるすべてのデバイスをorganizationに表示したりできます。 さらに、デバイス タイムラインには、より異常なイベントが表示されます。
![これは、エンドポイント分析の [概要] セクションの [異常] タブのスクリーンショットです](media/anomaly-detection/anomalies-tab.png#lightbox)
![これは、[異常] タブに表示される異常を選択したときに表示される詳細のスクリーンショットです](media/anomaly-detection/details-of-anomaly.png#lightbox)


異常を特定するための統計モデル
構築された分析モデルは、異常なストップ エラーの再起動セットに直面しているデバイス コーホートを検出し、管理者の注意を払って解決する必要があるアプリケーションのハング/クラッシュを検出します。 センサー テレメトリと診断 ログから識別されたパターンによって、これらのデバイス コーホートが決まります
しきい値ベースのヒューリスティック モデル: ヒューリスティック モデルには、アプリケーションハング/クラッシュまたはエラー再起動の停止に対して 1 つ以上のしきい値を設定する必要があります。 上記の設定されたしきい値に違反がある場合、デバイスは異常としてフラグが設定されます。 モデルはシンプルでありながら効果的です。これは、デバイスまたはそのアプリで顕著または静的な問題を表示するのに適しています。 現時点では、しきい値は、カスタマイズするオプションなしで事前に定義されています。
ペアリングされた t 検定モデル: ペアリングされた t 検定は、データセット内の観測値のペアを比較し、その平均間の統計的に有意な距離を検索する数学的手法です。 テストは、何らかの方法で相互に関連する観測で構成されるデータセットで使用されます。 たとえば、ポリシーの変更の前後に同じデバイスからエラーの再起動を停止する回数や、OS (オペレーティング システム) の更新後にデバイスでアプリがクラッシュする回数などです。
母集団 Z スコア モデル: 母集団 Z スコアベースの統計モデルでは、データセットの標準偏差と平均を計算し、それらの値を使用して異常なデータ ポイントを特定します。 標準偏差と平均は、各データ ポイントの Z スコアを計算するために使用されます。これは、平均値から離れた標準偏差の数を表します。 特定の範囲外のデータ ポイントは異常です。 このモデルは、より広いベースラインから外れ値のデバイスまたはアプリを強調表示するのに適していますが、十分に大きなデータセットが正確である必要があります。
時系列 Z スコア モデル: 時系列 Z スコア モデルは、時系列データの異常を検出するために設計された標準 Z スコア モデルのバリエーションです。 時系列データは、Stop Error Restarts の集計など、一定の間隔で収集される一連のデータ ポイントです。 標準偏差と平均は、集計されたメトリックを使用して、スライディング ウィンドウに対して計算されます。 この方法により、モデルはデータ内の一時的なパターンに敏感になり、時間の経過に伴う分布の変化に適応できます。
次の手順
詳細については、以下をご覧ください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示