Azure Analysis Services のスケールアウト
スケールアウトによって、クエリ プール内の複数のクエリ レプリカ間でクライアント クエリを分散して、負荷の高いクエリのワークロードを実行している間の応答時間を短縮できます。 クエリ プールから処理を分離して、クライアント クエリが処理操作の悪影響を受けないようにすることもできます。 スケールアウトを構成するには Azure Portal から行うか、または Analysis Services の REST API を使用します。
スケールアウトは Standard 価格レベルのサーバーで使用できます。 各クエリ レプリカは、お使いのサーバーと同じ料金で課金されます。 すべてのクエリ レプリカは、サーバーと同じリージョンに作成されます。 構成できるクエリ レプリカ数は、サーバーが存在しているリージョンによって制限されます。 詳細については、「リージョンごとの可用性」を参照してください。 スケールアウトでは、サーバーで使用可能なメモリの量は増えません。 メモリを増やすには、プランをアップグレードする必要があります。
スケール アウトする理由
一般的なサーバーのデプロイでは、1 つのサーバーで、処理サーバーとクエリ サーバーの両方の役割を果たします。 サーバー上のモデルに対するクライアント クエリの数が、加入しているサーバー プランのクエリ プロセッシング ユニット (QPU) を超過した場合、またはモデル処理が負荷の高いクエリのワークロードと同時に発生した場合、パフォーマンスが低下することがあります。
スケールアウトでは、さらに最大 7 つまでの追加のクエリ レプリカ リソース ("プライマリ" サーバーを含めて合計 8 つ) を含むクエリ プールを作成できます。 重要な場面では、QPU の需要を満たせるようにクエリ プール内のレプリカの数をスケーリングできます。また、処理サーバーはいつでもクエリ プールから分離できます。
クエリ プール内にあるクエリ レプリカの数に関わらず、ワークロードの処理はクエリ レプリカ間で分散されません。 プライマリ サーバーが処理サーバーとして機能します。 クエリ レプリカは、クエリ プール内のプライマリ サーバーと各レプリカ間で同期されているモデル データベースに対するクエリにのみ機能します。
スケールアウトすると、新しいクエリ レプリカがクエリ プールに増分的に追加されるのに最大 5 分かかることがあります。 すべての新しいクエリ レプリカが稼働すると、新しいクライアント接続はクエリ プール内のリソースに負荷分散されます。 既存のクライアント接続は、現在の接続先のリソースから変更されることはありません。 スケールインすると、クエリ プールから削除されるクエリ プール リソースへの既存のクライアント接続が終了します。 クライアントは、残りのクエリ プールのリソースに再接続できます。
しくみ
スケールアウトを初めて構成すると、プライマリ サーバー上のモデル データベースが新しいクエリ プール内の新しいレプリカと "自動的に" 同期されます。 自動同期は 1 回だけ行われます。 自動同期中に、(暗号化されて BLOB ストレージに保存された) プライマリ サーバーのデータ ファイルが 2 番目の場所にコピーされ、同様に暗号化されて BLOB ストレージに保存されます。 その後、クエリ プール内のレプリカは、ファイルの 2 番目のセットからのデータとともにハイドレートされます。
自動同期は初めてサーバーをスケールアウトする時にしか実行されませんが、手動同期を実行することもできます。 同期により、クエリ プール内のレプリカのデータがプライマリ サーバーのデータと一致することが保証されます。 プライマリ サーバーでモデルを処理 (更新) する場合は、処理操作が完了した後で同期が行われる必要があります。 この同期により、BLOB ストレージ内のプライマリ サーバーのファイルから 2 つ目のファイル セットに、更新されたデータがコピーされます。 その後、クエリ プール内のレプリカは、BLOB ストレージ内の 2 つ目のファイル セットから、更新されたデータとともにハイドレートされます。
その後のスケールアウト操作を実行すると、たとえばクエリ プール内のレプリカの数を 2 つから 5 つに増やすと、新しいレプリカが BLOB ストレージ内のファイル セットからデータとともにハイドレートされます。 同期は行われません。 スケール アウト後に同期を実行すると、クエリ プール内の新しいレプリカは 2 回ハイドレートされ、冗長ハイドレーションになります。 その後のスケールアウト操作を実行するときは、次の点に留意することが重要です。
追加されたレプリカの冗長ハイドレーションを回避するため、スケールアウト操作の前に同期を実行してください。 同時実行同期とスケールアウト操作を同時に実行することはできません。
処理とスケールアウトの操作を両方とも自動化する場合に重要なことは、最初にプライマリ サーバーでデータを処理してから同期を実行し、その後でスケールアウト操作を実行することです。 この順序により、QPU とメモリのリソースに対する影響が最小限に抑えられます。
スケールアウト操作中、クエリ プール内のすべてのサーバー (プライマリ サーバーを含む) が一時的にオフラインになります。
クエリ プールにレプリカがない場合でも、同期は許可されます。 プライマリ サーバーでの処理操作からの新しいデータを使用してゼロから 1 つ以上のレプリカにスケールアウトする場合は、まずクエリ プールにレプリカがない状態で同期を実行してから、スケールアウトします。スケール アウトする前に同期することで、新しく追加されたレプリカの冗長ハイドレーションが回避されます。
モデル データベースをプライマリ サーバーから削除しても、クエリ プール内のレプリカから自動的には削除されません。 そのデータベースのファイルをレプリカの共有 BLOB ストレージの場所から削除してから、クエリ プール内のレプリカ上のモデル データベースを削除する、Sync-AzAnalysisServicesInstance PowerShell コマンドを使用して、同期操作を実行する必要があります。 model データベースがクエリ プール内のレプリカには存在していてプライマリ サーバーには存在していないかどうかを調べるには、[処理中のサーバーと照会中のプールを分けてください] が [はい] に設定されていることを確認します。 その後、SQL Server Management Studio で
:rw修飾子を使ってプライマリ サーバーに接続して、データベースが存在するかどうかを確認します。 次に、:rw修飾子を使わずに接続することでクエリ プール内のレプリカに接続して、同じデータベースがそこにも存在するかどうかを確認します。 データベースがクエリ プール内のレプリカには存在していて、プライマリ サーバーには存在していない場合は、同期操作を実行します。プライマリ サーバー上のデータベースの名前を変更する場合は、データベースがすべてのレプリカに適切に同期されようにするために必要な手順がもう 1 つあります。 名前を変更した後、
-Databaseパラメーターに古いデータベース名を指定して Sync-AzAnalysisServicesInstance コマンドを使用して同期を実行します。 この同期により、古い名前を持つデータベースとファイルがレプリカから削除されます。 その後、新しいデータベース名で-Databaseパラメーターを使用して、もう一度同期を実行します。 2 回目の同期により、新しい名前のデータベースが 2 つ目のファイル セットにコピーされ、レプリカがハイドレートされます。 これらの同期は、ポータルでモデルの同期コマンドを使用して実行することはできません。
同期化モード
既定では、クエリ レプリカは増分ではなく、完全にリハイドレートされます。 リハイドレートは段階的に行われます。 一度に 1 つ以上のレプリカが同時にオンラインになっていることを確認するために (少なくとも 3 つのレプリカがある場合)、一度に 2 つづつデタッチおよびアタッチされます。 場合によっては、このプロセスの実行中に、クライアントがオンライン レプリカの 1 つに再接続する必要になる場合があります。 ReplicaSyncMode 設定を使用して、クエリ レプリカの同期を並列で実行するように指定できるようになりました。 並列同期には、次のような利点があります。
- 同期時間が大幅に短縮されます。
- 同期プロセス中のレプリカ間のデータに一貫性が保たれる可能性が高くなります。
- データベースは、同期処理全体を通してすべてのレプリカでオンラインに維持されるため、クライアントは再接続する必要がありません。
- メモリ内キャッシュは、変更されたデータのみが段階的に更新されます。これは、モデルを完全にリハイドレートするよりも高速です。
ReplicaSyncMode の設定
SSMS を使用して、詳細プロパティで ReplicaSyncMode を設定します。 指定できる値は、
1(既定): 完全なレプリカ データベースのリハイドレート (増分)。2: 並列での同期の最適化。
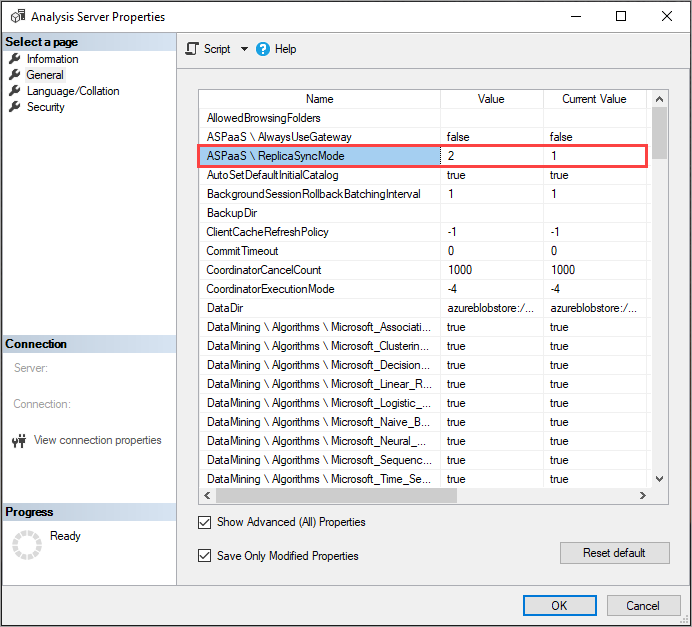
ReplicaSyncMode=2 を設定する場合、更新する必要のあるキャッシュの量によっては、クエリ レプリカによってさらにメモリが消費される可能性があります。 クエリで使用できるようデータベースをオンラインに保つため、変更されたデータの量によっては、古いセグメントと新しいセグメントの両方が同時にメモリに保持されるので、この操作では、レプリカに対して最大 2 倍のメモリが必要になることがあります。 レプリカ ノードのメモリ割り当てはプライマリ ノードと同じであり、通常は更新操作のためにプライマリ ノードには追加のメモリがあります。そのため、レプリカのメモリが不足することは稀です。 また、一般的なシナリオでは、データベースがプライマリ ノードで増分更新されるため、メモリを倍にする必要があることは珍しくありません。 同期操作でメモリ不足エラーが発生した場合は、既定の手法 (一度に 2 つづつアタッチまたはデタッチする手法) を使用して再試行します。
クエリ プールから分離した処理
処理操作とクエリ操作の両方のパフォーマンスを最大限にするために、処理サーバーをクエリ プールから分離することができます。 分離すると、新規のクライアント接続は、クエリ プール内のクエリ レプリカにのみ割り当てられます。 処理操作にそれほど時間がかからない場合は、、処理操作と同期操作を実行している間だけ処理サーバーをクエリ プールから分離し、その後、クエリ プールに戻すこともできます。 クエリ プールから処理サーバーを分離する、またはクエリ プールに追加して戻す操作は、完了するまでに最大で 5 分かかることがあります。
QPU の使用状況を監視する
お使いのサーバーでスケールアウトが必要かどうかを判断するには、Azure portal でサーバーメトリックを監視します。 QPU が頻繁に上限に達するようであれば、モデルに対するクエリの数が、お使いのプランに設定されている QPU の制限を超過していることになります。 クエリ スレッド プール キュー内のキュー数が、利用可能な QPU を超過した場合も、クエリ プールのジョブ キュー長のメトリックは増加します。
注意しておくとよいもう 1 つのメトリックは、ServerResourceType 別の平均 QPU です。 このメトリックは、プライマリ サーバーの平均 QPU とクエリ プールの平均 QPU を比較します。
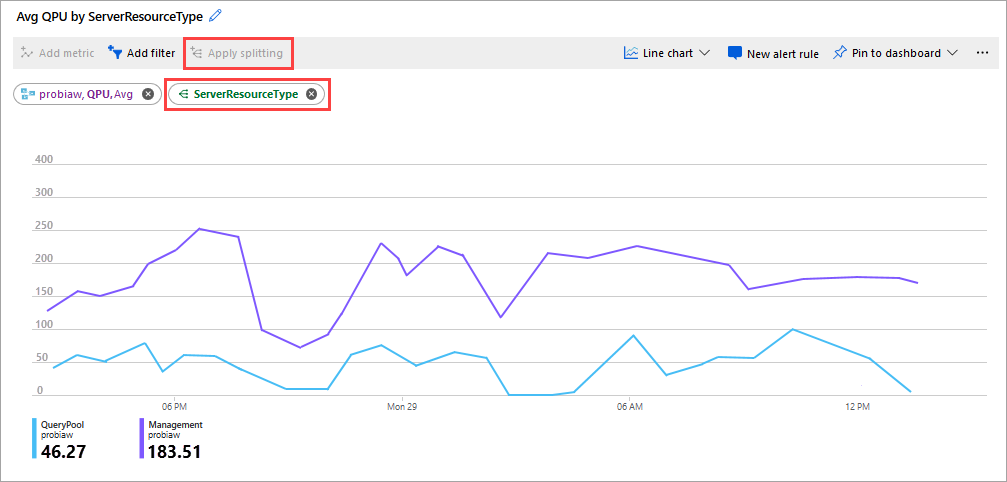
ServerResourceType 別の QPU を構成する
- メトリックの折れ線グラフで、[メトリックの追加] をクリックします。
- [リソース] でサーバーを選択し、[メトリック名前空間] で [Analysis Services standard metrics]\(Analysis Services の標準的なメトリック) を選択します。次に、[メトリック] で [QPU] を選択し、[集計] で [平均] を選択します。
- [Apply Splitting]\(分割の適用) をクリックします。
- [値] で、[ServerResourceType] を選択します。
詳細な診断ログ
スケールアウトされたサーバー リソースのより詳細な診断には、Azure Monitor ログを使用します。 ログに対して Log Analytics クエリを使用して、サーバーおよびレプリカ別に QPU とメモリを分割できます。 詳細については、「Log Analytics ワークスペースのログの分析」を参照してください。 クエリの例については、Kusto クエリの例 に関するセクションを参照してください。
スケールアウトを構成する
Azure Portal の場合
ポータルで、[スケールアウト] をクリックします。スライダーを使用してクエリ レプリカ サーバーの数を選択します。 選択したレプリカの数は既存のサーバーの数に追加されます。
[処理中のサーバーと照会中のプールを分けてください] で、[はい] を選択してクエリ サーバーから処理中のサーバーを除外します。 既定の接続文字列 (
:rwなし) を利用するクライアント接続は、クエリ プールのレプリカにリダイレクトされます。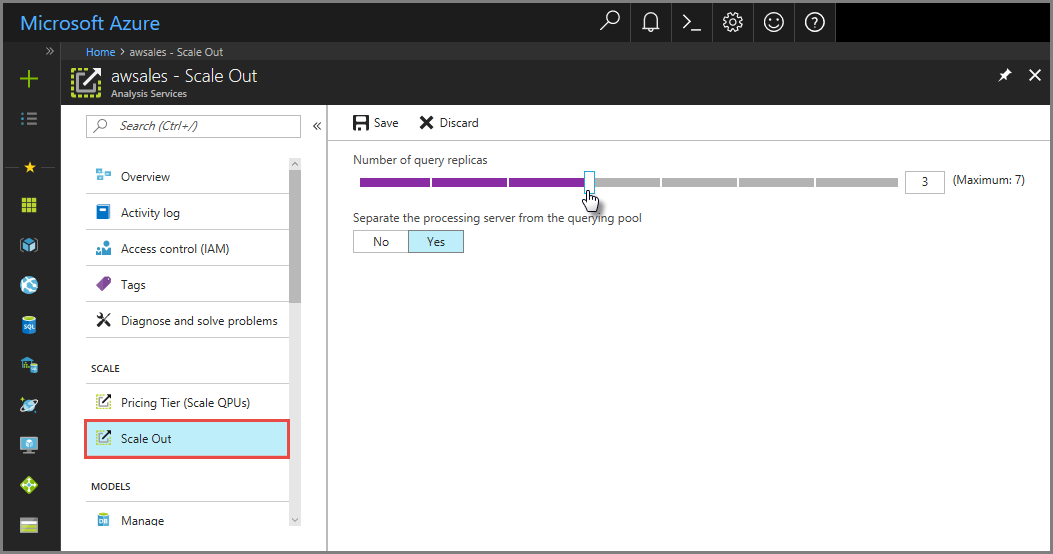
[保存] をクリックして新しいクエリ レプリカ サーバーをプロビジョニングします。
初めてサーバーでスケールアウトを構成すると、プライマリ サーバー上のモデル データベースがクエリ プール内のレプリカと自動的に同期されます。 自動同期は、1 つまたは複数のレプリカへのスケールアウトを初めて構成するときに、1 回だけ行われます。 その後、同じサーバー上のレプリカの数が変更されても、"自動同期はそれ以上トリガーされません"。 サーバーのレプリカを 0 に設定してから、もう一度任意の数のレプリカにスケールアウトしても、自動同期が再度行われることはありません。
Synchronize
同期操作は、手動で実行するか、REST API を使用して実行する必要があります。
Azure Portal の場合
[概要]> 対象のモデル >[Synchronize model]\(モデルの同期\) の順に選択します。
![[同期] アイコン](media/analysis-services-scale-out/aas-scale-out-sync.png)
REST API
sync 操作を使用します。
モデルを同期する
POST https://<region>.asazure.windows.net/servers/<servername>:rw/models/<modelname>/sync
同期状態を取得する
GET https://<region>.asazure.windows.net/servers/<servername>/models/<modelname>/sync
リターン状態コード:
| コード | 説明 |
|---|---|
| -1 | 無効 |
| 0 | レプリケーション中 |
| 1 | リハイドレート中 |
| 2 | 完了しました |
| 3 | Failed |
| 4 | 終了処理中 |
PowerShell
注意
Azure を操作するには、Azure Az PowerShell モジュールを使用することをお勧めします。 作業を開始するには、Azure PowerShell のインストールに関する記事を参照してください。 Az PowerShell モジュールに移行する方法については、「AzureRM から Az への Azure PowerShell の移行」を参照してください。
PowerShell を使用する前に、最新の Azure PowerShell モジュールをインストールまたは更新します。
同期を実行するには、Sync-AzAnalysisServicesInstance を使用します。
クエリ レプリカの数を設定するには、Set-AzAnalysisServicesServer を使用します。 省略可能な -ReadonlyReplicaCount パラメーターを指定します。
処理サーバーをクエリ プールから分離するには、Set-AzAnalysisServicesServer を使用します。 省略可能な -DefaultConnectionMode パラメーターを Readonly を使用するように指定します。
詳しくは、Az.AnalysisServices モジュールでのサービス プリンシパルの使用に関する記事をご覧ください。
つながり
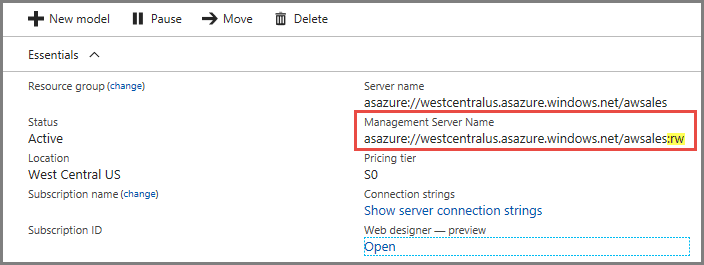
サーバーの [概要] ページに、サーバー名が 2 つ表示されます。 サーバーのスケールアウトをまだ構成していない場合は、両方のサーバー名は同じものとして機能します。 サーバーのスケールアウトを構成したら、接続の種類に応じて適切なサーバー名を指定する必要があります。
Power BI Desktop、Excel、カスタム アプリなどのエンドユーザー クライアントの接続については、[サーバー名] を使用します。
SSMS、Visual Studio、および PowerShell、Azure 関数アプリ、AMO の接続文字列については、[管理サーバー名] を使用します。 管理サーバー名は特殊な :rw (読み取り/書き込み) 修飾子を含みます。 すべての処理操作は (プライマリ) 管理サーバーで発生します。
スケールアップ、スケールダウン対スケールアウト
複数のレプリカを持つサーバーの価格レベルを変更できます。 同じ価格レベルがすべてのレプリカに適用されます。 スケーリング操作では、まずすべてのレプリカが一度に停止され、その後、すべてのレプリカが新しい価格レベルで起動されます。
トラブルシューティング
問題: ユーザーに対し、"Cannot find server '<Name of the server>' instance in connection mode 'ReadOnly'" (接続モード 'ReadOnly' でサーバー '<サーバー名>' インスタンスが見つかりません) というエラーが表示されます。
解決方法:[処理中のサーバーと照会中のプールを分けてください] オプションが選択されているとき、既定の接続文字列 (:rw なし) を利用するクライアント接続は、クエリ プールのレプリカにリダイレクトされます。 同期が完了していないため、クエリ プールのレプリカがオンラインになっていない場合、リダイレクトのクライアント接続は失敗することがあります。 接続の失敗を防ぐには、同期の実行時にクエリ プール内に少なくとも 2 台のサーバーが含まれている必要があります。 各サーバーは、他方のオンライン状態を維持したまま、個別に同期されます。 処理時にクエリ プール内の処理サーバーを使用しないことを選択した場合は、そのサーバーを処理用のプールから削除し、処理が完了した後、同期が行われる前にプールに戻すことができます。 同期の状態を監視するには、メモリと QPU のメトリックを使用します。