ビッグ データ アーキテクチャは、従来のデータベース システムには多すぎる、または複雑すぎるデータのインジェスト、処理、分析を扱うために設計されています。

ビッグ データ ソリューションには、通常は、次の種類のワークロードが 1 つ以上関係しています。
- 保存されているビッグ データ ソースのバッチ処理。
- 動作中のビッグ データのリアルタイム処理。
- ビッグ データの対話型探索。
- 予測分析と機械学習。
大部分のビッグ データ アーキテクチャには、次のコンポーネントの一部またはすべてが含まれています。
データ ソース:すべてのビッグ データ ソリューションは、1 つ以上のデータ ソースから始まります。 たとえば、次のようになります。
- リレーショナル データベースなど、アプリケーション データ ストア。
- Web サーバー ログ ファイルなど、アプリケーションによって生成された静的ファイル。
- IoT デバイスなど、リアルタイムのデータ ソース。
データ ストレージ:バッチ処理操作のためのデータは、通常は、さまざまな形式の大きなファイルを大量に保持できる分散ファイル ストアに保存されます。 この種のストアは、Data Lake とも呼ばれます。 このストレージを実装するための選択肢としては、Azure Data Lake Store、または Azure Storage 内の BLOB コンテナーなどがあります。
バッチ処理:データ セットは非常に大きいため、多くの場合、ビッグ データ ソリューションでは、実行時間の長いバッチ ジョブの使用によってデータ ファイルを処理し、フィルター処理や集計を行うなどして分析用のデータを準備する必要があります。 通常、これらのジョブには、ソース ファイルの読み取り、ソース ファイルの処理、新しいファイルへの出力の書き込みが含まれます。 選択肢には、Azure Data Lake Analytics での U-SQL ジョブの実行、HDInsight Hadoop クラスターでの Hive、Pig、またはカスタム Map/Reduce ジョブの使用、あるいは HDInsight Spark クラスターでの Java、Scala、または Python プログラムの使用などがあります。
リアルタイム メッセージ取り込み:ソリューションにリアルタイム ソースが含まれている場合は、アーキテクチャに、ストリーム処理のためにリアルタイム メッセージを取得して保存する方法が含まれている必要があります。 これは、受信メッセージを処理用のフォルダーにドロップするような、単純なデータ ストアにすることもできます。 ただし、多くのソリューションには、メッセージのためのバッファーとして機能し、スケールアウト処理、信頼性の高い配信、その他のメッセージ キューのセマンティクスをサポートするメッセージ インジェスト ストアが必要です。 選択肢には、Azure Event Hubs、Azure IoT Hubs、Kafka などがあります。
ストリーム処理:このソリューションでは、リアルタイム メッセージを取得した後、分析用にデータをフィルターしたり、集計したり、その他の準備を行ったりして、それらのメッセージを処理する必要があります。 処理されたストリーム データは、その後、出力シンクに書き込まれます。 Azure Stream Analytics では、バインドされていないストリームを操作する SQL クエリの絶え間ない実行に基づいて、管理されたストリーム処理サービスが提供されます。 HDInsight クラスターで、Spark Streaming など、オープン ソースの Apache ストリーミング テクノロジを使用することもできます。
分析データ ストア:多くのビッグ データ ソリューションでは、分析用にデータが準備されてから、処理されたデータが提供されます。このデータは分析ツールを使用して照会可能な、構造化された形式になります。 これらのクエリの処理に使用する分析データ ストアは、従来のほとんどのビジネス インテリジェンス (BI) ソリューションに見られるように、Kimball スタイルのリレーショナル データ ウェアハウスにすることができます。 別の方法としては、HBase などの待機時間の短い NoSQL テクノロジや、分散データ ストア内のデータ ファイル上のメタデータ抽象化を提供する対話型 Hive データベースを通じて、データを利用できます。 Azure Synapse Analytics を使用すると、クラウドベースの大規模なデータ ウェアハウス向けの管理されたサービスが提供されます。 HDInsight では対話型の Hive、HBase、Spark SQL をサポートしており、これらを使用して分析用のデータを処理することもできます。
分析とレポート:ほとんどのビッグ データ ソリューションの目的は、分析とレポートによってデータに関する実用的な情報を提供することにあります。 ユーザーによるデータ分析を支援するために、Azure Analysis Services での多次元 OLAP キューブまたは表形式データ モデルなどのデータ モデリング レイヤーをアーキテクチャに組み込むことができます。 Microsoft Power BI または Microsoft Excel 内のモデリング テクノロジおよび視覚化テクノロジを使用して、セルフサービス BI をサポートすることもできます。 分析とレポートは、データ サイエンティストやデータ アナリストによる対話型のデータ探索の形で行うこともできます。 これらのシナリオでは、多くの Azure サービスで Jupyter などの分析ノートブックがサポートされており、そのユーザーは Python や R に関する既存のスキルを活用できます。大規模なデータ探索の場合は、Microsoft R Server をスタンドアロンでも、Spark と組み合わせても使用できます。
オーケストレーション:ほとんどのビッグ データ ソリューションはデータの反復処理操作で構成されており、ワークフロー内でカプセル化されています。この処理操作では、ソース データの変換や複数のソースとシンクとの間でのデータ移動、処理されたデータの分析データ ストアへの読み込み、レポートまたはダッシュボードへのダイレクトな結果のプッシュが行われます。 これらのワークフローを自動化するために、Azure Data Factory や Apache Oozie および Sqoop などのオーケストレーション テクノロジを使用できます。
Azure には、ビッグ データ アーキテクチャで使用できる数多くのサービスがあります。 それらは、ほぼ次の 2 つのカテゴリに分類されます。
- Azure Data Lake Store、Azure Data Lake Analytics、Azure Synapse Analytics、Azure Stream Analytics、Azure Event Hubs、Azure IoT Hub、Azure Data Factory などの管理サービス。
- HDFS、HBase、Hive、Spark、Oozie、Sqoop、Kafka などの、Apache Hadoop プラットフォームを基盤とするオープン ソース テクノロジ。 これらのテクノロジは、Azure 上の Azure HDInsight サービス内で利用できます。
これらの選択肢は相互に排他的ではなく、多くのソリューションでは、Azure サービスとオープン ソース テクノロジが組み合わされています。
このアーキテクチャを使用する状況
次のことが必要な場合は、このアーキテクチャ スタイルの使用を検討してください。
- 従来のデータベースには多すぎる、大量のデータを保存および処理する。
- 分析とレポートのために非構造化データを変換する。
- リアルタイムで、または短い待機時間で、バインドされていないデータ ストリームを取得、処理、分析する。
- Azure Machine Learning または Azure Cognitive Services を使用する。
メリット
- テクノロジの選択。 HDInsight クラスター内で Azure の管理されたサービスと Apache テクノロジを組み合わせて適合させることで、既存のスキルやテクノロジへの投資を有効に活用できます。
- 並列処理によるパフォーマンス。 ビッグ データ ソリューションでは並列処理の強みを活かして、大量のデータをスケーリングする高パフォーマンスのソリューションを実現できます。
- 柔軟なスケール。 ビッグ データ アーキテクチャ内のすべてのコンポーネントで、スケールアウトのプロビジョニングがサポートされています。このサポートにより、ご自分のソリューションをワークロードの規模に合わせて調整でき、しかも使用した分のリソースにしか料金がかかりません。
- 既存のソリューションとの相互運用性。 ビッグ データ アーキテクチャのコンポーネントは、IoT 処理および企業向けの BI ソリューションにも使用されており、お客様がすべてのデータ ワークロードにわたる統合されたソリューションを作成できるようにします。
課題
- 複雑さ。 ビッグ データ ソリューションは、多数のコンポーネントで複数のデータ ソースからのデータ インジェストを処理するため、非常に複雑になる可能性があります。 ビッグ データ プロセスの構築、テスト、トラブルシューティングは、困難を伴う場合があります。 その上、パフォーマンスを最適化するために使用する構成の設定が、大量かつ複数のシステムにわたって必要になる可能性があります。
- スキルセット。 多くのビッグ データ テクノロジは、非常に専門化されており、より一般的なアプリケーション アーキテクチャではあまり使用されていないフレームワークと言語を使用しています。 一方で、ビッグ データ テクノロジは、確立されたより多くの言語を基に構築された、新しい API を発展させています。 たとえば、Azure Data Lake Analytics での U-SQL 言語は、Transact-SQL と C# の組合せが基盤になっています。 同様に、SQL ベースの API を Hive、HBase、Spark で使用できます。
- テクノロジの成熟度。 ビッグ データで使用されるテクノロジの多くは、進化しています。 Hive や Pig などの主要な Hadoop テクノロジが安定しているのに対して、Spark などの新興テクノロジでは、新たなリリースのたびに大幅な変更と改良が採用されます。 Azure Data Lake Analytics や Azure Data Factory などの管理されたサービスは、他の Azure サービスと比べて比較的新しく、時間と共に進化する可能性があります。
- セキュリティ。 ビッグ データ ソリューションは、通常は、一元化された Data Lake へのすべての静的データの保存に頼っています。 このデータへのアクセスを保護することが課題となる可能性があります。特に、データを複数のアプリケーションとプラットフォームでインジェストして使用される必要がある場合には、それが顕著になります。
ベスト プラクティス
並行処理の活用。 大部分のビッグ データ処理テクノロジでは、複数の処理単位にわたり、ワークロードが分散されます。 このためには、分割可能な形式で静的なデータ ファイルを作成し保存することが必要です。 HDFS などの分散ファイル システムでは、読み取りと書き込みのパフォーマンスを最適化できます。実際の処理は、複数のクラスター ノードで並列的に実行されることで、全体的なジョブの時間は短縮されます。
データのパーティション分割。 バッチ処理は、通常は、定期的なスケジュールで行われます (週次や月次など)。 処理スケジュールに一致するテンポラルの期間に基づいて、データ ファイルや、テーブルなどのデータ構造をパーティション分割します。 これにより、データ インジェストやジョブ スケジューリングが簡略化され、障害のトラブルシューティングが簡単になります。 また、Hive、U-SQL、または SQL クエリで使用されるテーブルをパーティション分割すると、クエリ パフォーマンスが大幅に向上します。
読み取り時のスキーマのセマンティクスの適用。 Data Lake を使用すると、構造化、半構造化、非構造化のいずれかに関わらず、複数形式のファイル用にストレージを結合できます。 データ保存時ではなくデータ処理時にデータにスキーマが投影される、読み取り時のスキーマのセマンティクスを使用します。 このことで、ソリューションに柔軟性が組み込まれ、データ検証と型チェックによって起こる、データ インジェスト中のボトルネックを防ぐことができます。
適所でのデータの処理。 従来の BI ソリューションでは、多くの場合、データ ウェアハウスにデータを移動するのに、抽出、変換、読み込み (ETL) のプロセスが使用されます。 大量のデータとさまざまな種類の形式が使用されるビッグ データ ソリューションでは、一般に、変換、抽出、読み込み (TEL) など、ETL が変化したものが使用されます。 この方法では、データは分散データ ストア内で処理され、必要な構造に変換されてから分析データ ストアに移動されます。
使用率と時間的なコストの均衡化。 バッチ処理ジョブの場合は、コンピューティング ノードの単位あたりのコストと、それらのノードを使用してジョブを完了する 1 分あたりのコストという、2 つの要因を考慮することが重要です。 たとえば、1 つのバッチ ジョブが、4 つのクラスター ノードで 8 時間かけて行われるとします。 ただし、そのジョブでは最初の 2 時間のみ 4 つすべてのノードが使用され、それ以降は、2 つのノードのみが必要になるということがわかったとします。 その場合は、すべてのジョブを 2 つのノードで実行すると、ジョブの合計時間は長くなりますが倍にはならないため、総コストは低くなります。 一部のビジネス シナリオでは、使用率の低いクラスター リソースの使用にかかるコストが高くつくよりも、処理時間が長くなる方が好まれる場合もあります。
クラスター リソースの分離。 HDInsight クラスターをデプロイするときは、通常は、ワークロードの種類ごとに別個のクラスター リソースをプロビジョニングしてパフォーマンスを向上させます。 たとえば、Spark クラスターには Hive が含まれますが、Hive と Spark の両方で大規模な処理を実行する必要がある場合は、Spark および Hadoop 専用のクラスターを別々にデプロイすることを検討する必要があります。 同様に、待機時間の短いストリーム処理に HBase と Storm を、バッチ処理に Hive を使用している場合は、Storm、HBase、Hadoop のために別個のクラスターを使用することを検討してください。
データ インジェストの調整。 場合によっては、既存のビジネス アプリケーションが、バッチ処理のためのデータ ファイルを Azure Storage Blob コンテナーに直接書き込むことができ、そこで、そのデータ ファイルを HDInsight または Azure Data Lake Analytics で使用できます。 ただし、多くの場合、オンプレミスまたは外部のデータ ソースから Data Lake へのデータのインジェストを調整する必要があります。 予測可能な一元的に管理できる方法でこれを実現するには、Azure Data Factory や Oozie でサポートされているようなオーケストレーション ワークフローまたはパイプラインを使用します。
機密性の高いデータの早期の除外。 データ インジェスト ワークフローでは、プロセスの早い段階で機密性の高いデータを除外して、Data Lake に保存しないようにする必要があります。
IoT アーキテクチャ
モノのインターネット (IoT) は、ビッグ データ ソリューションの中の特殊なサブセットです。 次の図は、IoT で考えられる論理アーキテクチャを示しています。 この図では、アーキテクチャのイベント ストリーミング コンポーネントが強調されています。
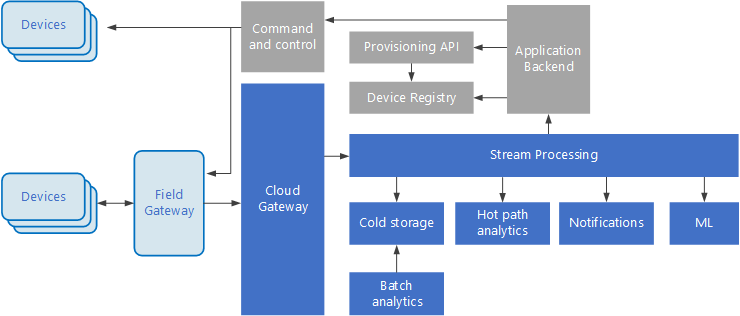
クラウド ゲートウェイが、信頼性の高い低待機時間のメッセージング システムを使用して、クラウドの境界でデバイスのイベントを取り込みます。
デバイスは、クラウド ゲートウェイに直接イベントを送信するか、フィールド ゲートウェイを介して送信します。 フィールド ゲートウェイは特殊なデバイスまたはソフトウェアで、通常はデバイスと共に配置され、イベントを受信してクラウド ゲートウェイに転送します。 フィールド ゲートウェイは、フィルター処理、集計、またはプロトコルの変換などの関数を実行する、ロウ デバイス イベントの前処理を行うこともあります。
取り込み後、イベントは 1 つ以上のストリーム プロセッサを経由します。それらのプロセッサは、データをルーティングしたり (ストレージへのルーティングなど)、分析やその他の処理を実行したりできます。
一般的な処理の種類を次に示します。 (このリストは全てを網羅しているわけではありません。)
アーカイブまたはバッチ分析のための、コールド ストレージへのイベント データの書き込み。
イベント ストリームを (ほぼ) リアルタイムで分析するホット パス分析で異常を検出し、ローリング時間枠でパターンを認識し、ストリームで特定の条件が発生した場合にアラートをトリガーする。
通知やアラームなど、デバイスからの特殊な非テレメトリ メッセージを処理。
機械学習。
網掛けのグレーのボックスに、IoT システムのコンポーネントが表示されています。これらのコンポーネントはイベント ストリーミングに直接関連はありませんが、ここでは完全を期すために盛り込んでいます。
デバイス レジストリはプロビジョニングされたデバイスのデータベースで、デバイス ID と、通常は位置情報などのデバイスのメタデータを含みます。
プロビジョニング API は新しいデバイスをプロビジョニングし登録するための一般的な外部インターフェイスです。
一部の IoT ソリューションでは、コマンドやコントロール メッセージをデバイスに送信できます。
このセクションでは IoT の概要について示しましたが、考慮すべき詳細や課題は多数あります。 さらに詳細な参照アーキテクチャやディスカッションについては、「Microsoft Azure IoT 参照アーキテクチャ」 (PDF のダウンロード) をご覧ください。
次のステップ
- ビッグ データ アーキテクチャの詳細を確認します。
- モノのインターネット (IoT) アーキテクチャ設計の詳細をご覧ください。