ハイパースケール サービス レベル
- [アーティクル]
-
-
適用対象: Azure SQL データベース
Azure SQL データベース
Azure SQL Database は、インフラストラクチャに障害が発生した場合でも高可用性を確保するために、クラウド環境に合わせて調整された SQL Server データベース エンジン アーキテクチャに基づいています。 Azure SQL Database の仮想コア購入モデルには、サービス レベルの選択肢が 3 つあります。
- General Purpose
- Business Critical
- Hyperscale
Hyperscale サービス レベルは、すべてのワークロードの種類に適しています。 そのクラウド ネイティブなアーキテクチャにより、従来および最新のさまざまなアプリケーションをサポートするための、独立してスケーラブルなコンピューティングとストレージが提供されます。 Hyperscale のコンピューティングとストレージのリソースは、General Purpose と Business Critical のレベルで使用可能なリソースを大幅に超えています。
仮想コアベースの購入モデルでの General Purpose サービス レベルと Business Critical サービス レベルの詳細については、General Purpose サービス レベルと Business Critical サービス レベルの記事を参照してください。 仮想コアベースの購入モデルと DTU ベースの購入モデルとの比較については、Azure SQL Database の vCore ベースと DTU ベースの購入モデルとリソースに関する記事をご覧ください。
Hyperscale サービス レベルは現在、Azure SQL Database でのみ使用でき、Azure SQL Managed Instance では使用できません。
Azure SQL Database の Hyperscale サービス レベルでは、次の追加機能が提供されます。
- 迅速なスケールアップ - 大きいワークロードに対応する必要があるときはコンピューティング リソースを一定の時間でスケールアップでき、必要がなくなったらコンピューティング リソースをスケールダウンして戻すことができます。
- 迅速なスケールアウト - 読み取りワークロードのオフロード用と、ホット スタンバイ用に、1 つ以上の読み取り専用レプリカをプロビジョニングできます。
-
サーバーレス コンピューティングでの使用量に基づくコンピューティングの自動スケールアップ、スケールダウンおよび課金。
-
Elastic Pool を使用したさまざまなリソース要求がある Hyperscale データベース グループの価格/パフォーマンスの最適化。
- 最大 128 TB のデータベースまたは 100 TB のエラスティック プール サイズをサポートするストレージの自動スケーリング。
- データ ボリュームに関係なく、高いトランザクション ログ スループットと速いトランザクション コミット時間による、全体的に高いパフォーマンス。
- コンピューティング リソースに I/O の影響を与えない、(ファイル スナップショットに基づく) 高速データベース バックアップ。
- 何時間あるいは何日もかけず、数分間で行う (ファイル スナップショットに基づく) 迅速なデータベース復元またはコピー。
Hyperscale サービス レベルでは、クラウド データベースにおいて従来見られた実質的な制限の多くが取り除かれます。 他のほとんどのデータベースは 1 つのノードで使用可能なリソースによって制限されますが、Hyperscale サービス レベルのデータベースにはそのような制限はありません。 ストレージ アーキテクチャの柔軟性が高く、必要に応じてストレージが拡張されます。 実際、Hyperscale データベースの作成時には最大サイズは定義されません。 Hyperscale データベースは必要に応じて拡大し、割り当てられたストレージ容量に対してのみ課金されます。 読み取り集中型ワークロードでは、Hyperscale サービス レベルにより、読み取りワークロードのオフロード用に必要に応じて追加のレプリカがプロビジョニングされ、迅速なスケールアウトが提供されます。
さらに、データベース バックアップの作成に必要な時間や、スケールアップまたはスケールダウンに必要な時間は、データベース内のデータの量に関連しなくなっています。 Hyperscale データベースはほぼ瞬時にバックアップされます。 プロビジョニングされたコンピューティング レベルで数十テラバイトのデータベースを数分以内にスケールアップまたはスケールダウンしたり、サーバーレスを使ってコンピューティングを自動的にスケーリングしたりすることもできます。 この機能により、初期構成の選択によって縛り付けられることを心配する必要はなくなります。
ハイパースケール サービス レベルのコンピューティング サイズについて詳しくは、「サービス レベルの特性」をご覧ください。
Hyperscale サービス レベルを検討する必要があるユーザー
Hyperscale サービス レベルは、より高いパフォーマンスと可用性、高速のバックアップと復元、高速ストレージとコンピューティングのスケーラビリティを必要とするすべてのお客様を対象としています。 これには、アプリケーションを最新化するためにクラウドに移行中のお客様、および Azure SQL Database の他のサービス レベルを既に使用しているお客様が含まれます。 Hyperscale サービス レベルでは、純粋な OLTP から純粋な分析まで、幅広いデータベース ワークロードがサポートされています。 OLTP および HTAP (ハイブリッド トランザクションおよび分析処理) ワークロード用に最適化されています。
ハイパースケール サービス レベルは仮想コア モデルのみで提供されています。 新しいアーキテクチャに合わせて、価格モデルは General Purpose または Business Critical サービス モデルとは少し異なります。
プロビジョニングされるコンピューティング:
ハイパースケール コンピューティング ユニットの料金はレプリカ単位です。 ユーザーは、可用性およびスケーラビリティの要件に応じて、高可用性セカンダリ レプリカの合計数を 0 から 4 の範囲で調整し、最大 30 個の名前付きレプリカを作成して、さまざまな読み取りスケールアウト ワークロードをサポートすることができます。
サーバーレス コンピューティング:
サーバーレス コンピューティングの課金は使用量に基づきます。 詳細については、「Azure SQL Database のサーバーレス コンピューティング レベル」を参照してください。
ストレージ:
ハイパースケールのデータベースを構成するときに、最大データ サイズを指定する必要はありません。 Hyperscale レベルでは、実際の割り当てに基づいてデータベースのストレージに対して課金されます。 ストレージは、10 GB から 128 TB までの間 (必要に応じて 10 GB 単位で増分) で自動的に割り当てられます。
Hyperscale の価格について詳しくは、「Azure SQL データベースの価格」をご覧ください。
Hyperscale では、クエリ処理エンジンと、データの長期的なストレージと持続性を提供するコンポーネントが分かれています。 このアーキテクチャを使用すると、必要な限り (最大 128 TB) ストレージ容量をスムーズにスケーリングでき、コンピューティング リソースを迅速にスケーリングできます。
次は、機能するハイパースケール アーキテクチャの図です。
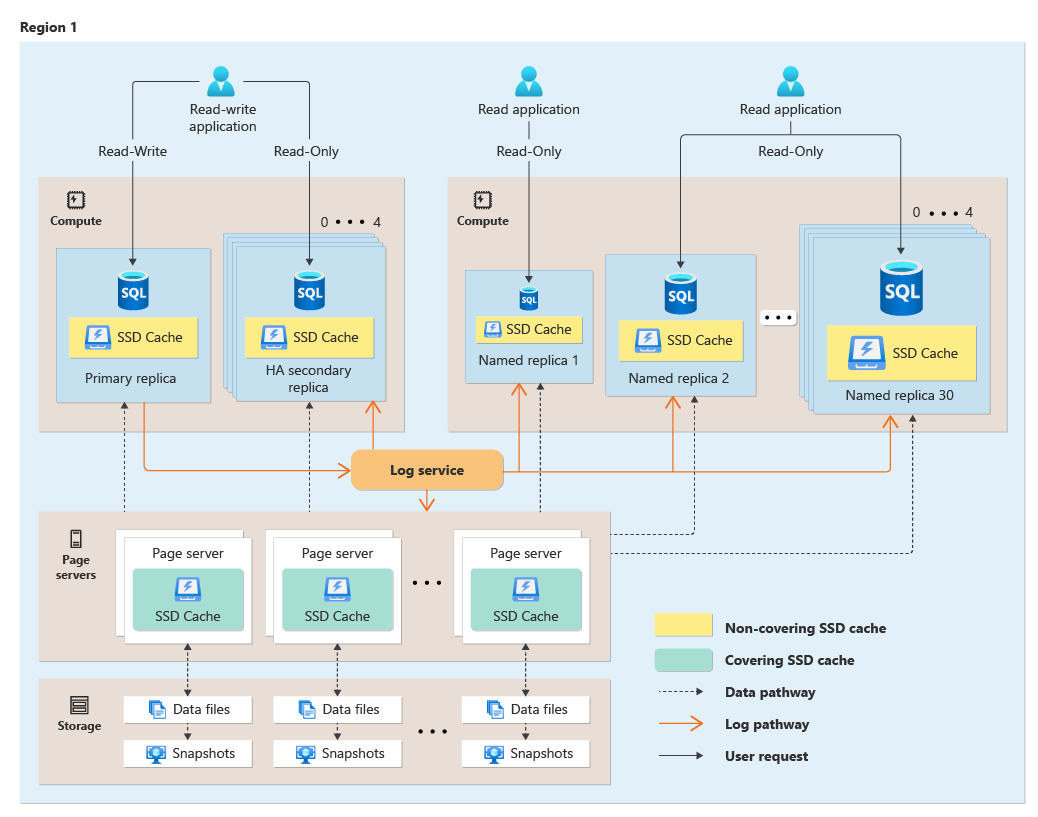
詳しくは、「Hyperscale の分散機能のアーキテクチャ」をご覧ください。
追加の読み取り専用コンピューティング ノードを迅速に起動/停止できるので、Hyperscale アーキテクチャでは、読み取りのスケーリング機能が優れ、より多くの書き込み要求に対応できるようにプライマリ コンピューティング ノードを解放することもできます。 また、Hyperscale アーキテクチャの共有ストレージ アーキテクチャのため、コンピューティング ノードをすばやくスケールアップ/スケールダウンできます。 Hyperscale の読み取り専用コンピューティング ノードは、ワークロードの需要に基づいてコンピューティングを自動的にスケーリングするサーバーレス コンピューティング レベルでも使用できます。
他のすべてのサービス レベルと同様に、Hyperscale は、コンピューティング レプリカの可用性に関係なく、コミットされたトランザクションのデータの持続性を保証します。 プライマリ レプリカが使用できなくなったことによるダウンタイムの期間は、フェールオーバーの種類 (計画的か、計画外か)、ゾーン冗長が構成されているかどうか、少なくとも 1 つの高可用性レプリカが存在することに依存します。 計画フェールオーバー (メンテナンス イベントなど) では、システムによってフェールオーバーの開始前に新しいプライマリ レプリカが作成されるか、または既存の高可用性レプリカがフェールオーバー ターゲットとして使用されます。 計画外のフェールオーバー (プライマリ レプリカでのハードウェア障害など) では、システムによって、高可用性レプリカがフェールオーバー ターゲットとして使用されるか (存在する場合)、または使用可能なコンピューティング容量のプールから新しいプライマリ レプリカが作成されます。 後者の場合、新しいプライマリ レプリカの作成に必要な追加の手順により、ダウンタイムの期間が長くなります。
影響を与えるメンテナンス イベントを予測可能にし、ワークロードの中断を減らすことができるメンテナンス期間を選択できます。
Hyperscale の SLA については、「SLA for Azure SQL Database の SLA」を参照してください。
バッファー プール、回復性があるバッファー プール拡張機能、継続的プライミング
Azure Database Hyperscale では、コンピューティングとストレージの間に明確な分離があります。 ストレージには、1 つのデータベース内のすべてのデータベース ページが含まれており、データベースの拡大に合わせて複数のマシンに割り当てられます。 ただし、計算ノードでは、最近使用されているもののみがキャッシュされます。 コンピューティングで最近使用されたページは、バッファー プール (BP) と呼ばれる構造のメモリ内に保持されます。 また、ローカル SSD (回復性のあるバッファー プール拡張機能 (RBPEX)) にも格納されるため、コンピューティング プロセスが再起動した場合に備えて、データをより高速に取得できます。
クラウド システムでは、コンピューティングは必要に応じて異なるマシンに移動できます。 コンピューティング レイヤーには複数のレプリカを含めることができます。 1 つはプライマリであり、すべての更新を受け取り、その他はセカンダリ レプリカです。 プライマリに障害が発生した場合、高可用性セカンダリ レプリカの 1 つは、フェールオーバーと呼ばれるプロセスですぐにプライマリに昇格できます。 セカンダリ レプリカの BP と RBPEX は、プライマリ ワークロード用に最適化されたキャッシュを持っていない可能性があります。
継続的プライミングは、すべてのコンピューティング レプリカの中で、最近使用されたページに関する情報を収集するプロセスです。 この情報は集計され、高可用性セカンダリ レプリカでは、一般的な顧客ワークロードに対応する最近使用されたページのリストが使用されます。 これにより、BP と RBPEX の両方に、最近使用されたページが継続的に埋め込まれるので、顧客のワークロードの変化に対応できます。
継続的プライミングがないと、BP と RBPEX の両方が新しい高可用性レプリカに継承されず、ユーザー ワークロード中にのみ再構築されます。 継続的プライミングは時間を節約し、キャッシュが再び完全にハイドレートされるまでの待ち時間がないため、パフォーマンスの不整合を防ぎます。 継続的プライミングにより、新しい高可用性セカンダリ レプリカは、BP と RBPEX のプライミングをすぐに開始します。 これにより、フェールオーバーが発生した場合の一貫したパフォーマンスの維持に役立ちます。
継続的プライミングは、高可用性セカンダリ レプリカとプライマリの両方向に機能します。高可用性セカンダリ レプリカでは、プライマリ レプリカで使用されているページをキャッシュし、プライマリでは、セカンダリ レプリカのワークロードを含むページをキャッシュします。
Hyperscale データベースのバックアップと復元操作は、ファイル スナップショットに基づきます。 これにより、これらの操作はほぼ瞬時に実行できます。 Hyperscale アーキテクチャではバックアップと復元にストレージ レイヤーが利用されるため、コンピューティング レプリカに関する処理の負荷とパフォーマンスへの影響が軽減されます。 詳しくは、「Hyperscale のバックアップとストレージの冗長性」をご覧ください。
Hyperscale データベースのディザスター リカバリー
ディザスター リカバリー操作やドリル、再配置などの理由の一環として、Azure SQL Database の Hyperscale データベースを現在ホストされているリージョン以外のリージョンに復元する必要がある場合、主な方法は、データベースの geo リストア を実行することです。 geo リストアは、ストレージの冗長性に geo 冗長ストレージ (RA-GRS) が選ばれている場合にのみ使用できます。
詳しくは、「Hyperscale データベースを別のリージョンに復元する」をご覧ください。
仮想コアベースのサービス レベルは、データベースの可用性、ストレージの種類、パフォーマンス、最大ストレージ サイズに基づいて区別されます。 これらの差異は、次の表のとおりです。
| ㅤ |
汎用 |
Business Critical |
Hyperscale |
|
最適な用途 |
予算重視のバランスの取れたコンピューティングおよびストレージ オプションを提供します。 |
トランザクション レートが高く I/O 待ち時間が低い OLTP アプリケーション。 複数のホット スタンバイのレプリカを使用して、高い耐障害性と高速フェールオーバーを提供しています。 |
最も多様なワークロード。 最大 128 TB のストレージ サイズの自動スケーリング、垂直および水平方向への高速コンピューティング スケーリング、データベースの高速復元。 |
|
コンピューティング サイズ |
2 - 128 の仮想コア |
2 - 128 の仮想コア |
2 - 128 の仮想コア |
|
ストレージの種類 |
Premium リモート ストレージ (インスタンスあたり) |
超高速ローカル SSD ストレージ (インスタンスあたり) |
ローカル SSD キャッシュを使用して切り離されたストレージ (コンピューティング レプリカごと) |
|
ストレージ サイズ |
1 GB – 4 TB |
1 GB – 4 TB |
10 GB から 128 TB |
|
IOPS |
仮想コアあたり 320 IOPS (最大 16,000 IOPS) |
仮想コアあたり 4,000 IOPS (最大 327,680 IOPS) |
最大ローカル SSD で 327,680 IOPS
Hyperscale は、複数のレベルのキャッシュが存在する複数レベル アーキテクチャです。 実際の IOPS はワークロードによって異なります。 |
|
仮想コアあたりのメモリ |
5.1 GB |
5.1 GB |
5.1 GB または 10.2 GB |
|
可用性 |
1 レプリカ、読み取りスケールアウトなし、ゾーン冗長 HA |
3 レプリカ、1 読み取りスケールアウト、ゾーン冗長 HA |
複数のレプリカ、最大 4 つの読み取りスケールアウト、ゾーン冗長 HA |
|
バックアップ |
ローカル冗長 (LRS)、ゾーン冗長 (ZRS)、または geo 冗長 (GRS) のストレージを選択可能
1 から 35 日 (既定では 7 日間) のデータ保有、最大 10 年間の長期保有が可能 |
ローカル冗長 (LRS)、ゾーン冗長 (ZRS)、または geo 冗長 (GRS) のストレージを選択可能
1 から 35 日 (既定では 7 日間) のデータ保有、最大 10 年間の長期保有が可能 |
ローカル冗長 (LRS)、ゾーン冗長 (ZRS)、または geo 冗長 (GRS) のストレージを選択可能
1 から 35 日 (既定では 7 日間) のデータ保有、最大 10 年間の長期保有が可能 |
|
価格/課金 |
仮想コア、予約ストレージ、バックアップ ストレージに対して請求されます。
IOPS は課金されません。 |
仮想コア、予約ストレージ、バックアップ ストレージに対して請求されます。
IOPS は課金されません。 |
レプリカごとの仮想コア、割り当てられたデータ ストレージ、バックアップ ストレージは課金されます。
IOPS は課金されません。 |
|
割引モデル1 |
予約インスタンス
Azure ハイブリッド特典2
Enterprise および開発テスト用の従量課金制プランのサブスクリプション |
予約インスタンス
Azure ハイブリッド特典2
Enterprise および開発テスト用の従量課金制プランのサブスクリプション |
予約インスタンス
Azure ハイブリッド特典2
Enterprise および開発テスト用の従量課金制プランのサブスクリプション |
1 SQL Database Hyperscale の簡略化された価格は、2023 年 12 月に導入されました。 詳細については、Hyperscale の価格に関するブログを参照してください。
2 2023 年 12 月の時点では、Azure ハイブリッド特典は新しい Hyperscale データベースや Dev/Test サブスクリプションに利用できません。 プロビジョニングされたコンピューティングを使用する既存の Hyperscale 単一データベースは、2026 年 12 月まで引き続き Azure ハイブリッド特典を使用してコンピューティング コストを節約できます。 詳細については、「Hyperscale 価格のブログ」を確認してください。
| ハードウェア構成 |
CPU |
メモリ |
| Standard シリーズ (Gen5) |
プロビジョニング済みコンピューティング
- Intel® E5-2673 v4(Broadwell)2.3 GHz、Intel® SP-8160(Skylake)1、Intel® 8272CL(Cascade Lake)2.5 GHz1、Intel® Xeon® Platinum 8370C(Ice Lake)1、AMD EPYC 7763v(Milan)プロセッサ
- 最大 80 個の仮想コアをプロビジョニング (ハイパースレッド)
サーバーレス コンピューティング
- Intel® E5-2673 v4(Broadwell)2.3 GHz、Intel® SP-8160(Skylake)1、Intel® 8272CL(Cascade Lake)2.5 GHz1、Intel® Xeon® Platinum 8370C(Ice Lake)1、AMD EPYC 7763v(Milan)プロセッサ
- 最大 80 個の仮想コアを自動スケーリング (ハイパースレッド)
- メモリと仮想コアの比率は、ワークロードの需要に基づくメモリと CPU の使用率に動的に適合し、仮想コアあたり最大 24 GB まで使用できます。 たとえば、特定の時点で、あるワークロードは 240 GB のメモリおよび 10 個のみの仮想コアを使用して課金される場合があります。 |
プロビジョニング済みコンピューティング
- 仮想コアあたり 5.1 GB
- 最大 625 GB をプロビジョニング
サーバーレス コンピューティング
- 仮想コアあたり最大 24 GB を自動スケーリング
- 最大 240 GB を自動スケーリング |
| Premium シリーズ |
- Intel® Xeon® Platinum 8370C(Ice Lake)、AMD EPYC 7763v (Milan)プロセッサ
- 最大 128 個の仮想コアをプロビジョニング (ハイパースレッド) |
- 仮想コアあたり 5.1 GB |
| Premium シリーズ メモリ最適化 |
- Intel® Xeon® Platinum 8370C(Ice Lake)、AMD EPYC 7763v (Milan)プロセッサ
- 最大 80 個の仮想コアをプロビジョニング (ハイパースレッド) |
- 仮想コアあたり 10.2 GB |
1 “sys.dm_user_db_resource_governance“の動的管理ビューでは、Intel® SP-8160(Skylake)プロセッサを使用するデータベースのハードウェア世代は Gen6、Intel® 8272CL(Cascade Lake)を使用するデータベースのハードウェア世代は Gen7、Intel Xeon® Platinum 8370C(Ice Lake)または AMD® EPYC® 7763v(Milan)を使用するデータベースのハードウェア世代は Gen8 として表示されます。 特定のコンピューティング サイズとハードウェア構成では、リソースの制限は、CPU の種類に関係なく同じです。 詳細については、単一データベースおよびエラスティック プールのリソース制限に関するページをご覧ください。
サーバーレスは、Standard シリーズ (Gen5) のハードウェアでのみサポートされます。
Hyperscale データベースを作成して管理する
Hyperscale データベースは、Azure portal、Transact-SQL、PowerShell、Azure CLI を使って、作成および管理できます。 詳細については、「クイックスタート: Hyperscale データベースを作成する」を参照してください。
以下は、Hyperscale サービス レベルの現在の制限事項です。 これらの制限事項ができるだけなくなるように、積極的に取り組んでいます。
| 問題 |
説明 |
| TDE が無効の場合、縮小がブロックされる |
現時点では、Azure SQL データベース Hyperscale で Transparent Data Encryption (TDE) が無効になっている場合、データベースとファイルの縮小操作はサポートされていません。 |
| 他のサービス レベルからデータベースを復元する |
Hyperscale 以外のデータベースを Hyperscale データベースとして復元することも、Hyperscale データベースを Hyperscale 以外のデータベースとして復元することもできません。
他の Azure SQL Database サービス レベルからハイパースケールに移行されたデータベースの場合、移行前のバックアップは、長期的なリテンション 期間ポリシーを含む、ソース データベースのバックアップ保持期間の間保持されます。 データベースのバックアップ保持期間中の移行前バックアップの復元は、コマンド ラインでサポートされています。 これらのバックアップは、Hyperscape 以外のサービス レベルに復元できます。 |
| インメモリ OLTP オブジェクトを使用したデータベースの移行 |
Hyperscale では、メモリ最適化テーブルの型、テーブル変数、ネイティブ コンパイルされたモジュールなど、インメモリ OLTP オブジェクトのサブセットがサポートされています。 ただし、どのようなインメモリ OLTP オブジェクトでも移行されているデータベースに存在すると、Premium および Business Critical サービス レベルから Hyperscale に移行できません。 このようなデータベースを Hyperscale に移行するには、すべてのインメモリ OLTP オブジェクトとその依存関係を削除する必要があります。 データベースを移行した後は、これらのオブジェクトを再作成できます。 永続的と非永続的なメモリ最適化テーブルは Hyperscale では現在サポートされておらず、ディスク テーブルに変更する必要があります。 |
| データベースの整合性チェック |
DBCC CHECKDB は現在、Hyperscale データベースではサポートされていません。 タブロックを持つ DBCC チェックテーブル('TableName')および タブロックを持つ DBCC CHECKFILEGROUP を回避策として使用できます。 Azure SQL Database におけるデータ整合性管理の詳細については、「Azure SQL Database でのデータ整合性」を参照してください。 |
| エラスティック ジョブ |
Hyperscale データベースをジョブ データベースとして使用することはサポートされていません。 ただし、エラスティック ジョブでは、Azure SQL Database の他のデータベースと同じ方法で、Hyperscale データベースを対象にすることができます。 |
| データ同期 |
Hyperscale データベースをハブまたは同期メタデータ データベースとして使用する機能はサポートされていません。 ただし、Hyperscale データベースは、データ同期トポロジ内のメンバー データベースになることができます。 |
| Hyperscale サービス レベルの Premium シリーズ ハードウェア |
プレミアム シリーズとメモリ最適化プレミアム シリーズのハードウェアでは、現在サーバーレス コンピューティングのティアはサポートされていません。 |
| リージョン別の提供状況 |
Hyperscale サービスレベルの Premium シリーズおよび Premium シリーズのメモリ最適化ハードウェアは、限られた Azure リージョンで利用できます。 一覧については、[Hyperscale Premium シリーズの可用性]を参照してください。 |
