Azure Cosmos DB の要求率が大きすぎる (429) 例外を診断してトラブルシューティングする
適用対象: ![]() NoSQL
NoSQL
この記事には、NoSQL 用 API のさまざまな 429 状態コード エラーの既知の原因と解決策が記載されています。 MongoDB 用 API を使用している場合は、MongoDB 用 API での一般的な問題のトラブルシューティングに関する記事を参照して、状態コード 16500 をデバッグする方法を調べてください。
"要求率が大きすぎる" という例外 (エラー コード 429) は、Azure Cosmos DB に対する要求がレート制限されていることを示します。
プロビジョニングされたスループットを使用する場合は、ワークロードに必要な、1 秒あたりの要求ユニット数 (RU/秒) で測定されるスループットを設定します。 読み取り、書き込み、クエリなどのサービスに対するデータベース操作では、一定量の要求ユニット (RU) が消費されます。 詳細については、要求ユニットに関する記事を参照してください。
ある 1 秒間で、プロビジョニングされた要求ユニット数を超える要求ユニットが操作により消費されると、Azure Cosmos DB から 429 例外が返されます。 1 秒ごとに、使用可能な要求ユニットの数がリセットされます。
RU/秒を変更するアクションを実行する前に、レート制限の根本原因を理解し、根底にある問題を解決することが重要です。
ヒント
この記事のガイダンスは、プロビジョニングされたスループットを使用するデータベースとコンテナー (自動スケーリングと手動スループットの両方) に適用されます。
さまざまな種類の 429 例外に対応するさまざまなエラー メッセージがあります。
- 要求率が大きい。 More Request Units may be needed, so no changes were made. (要求率が大きいです。追加の要求ユニットが必要な場合があります。このため、変更は行われませんでした。)
- The request didn't complete due to a high rate of metadata requests. (メタデータ要求率が高いため、要求が完了しませんでした。)
- The request didn't complete due to a transient service error. (一時的なサービス エラーのために要求が完了しませんでした。)
要求率が大きいです
これは最も一般的なシナリオです。 これは、データに対する操作で使用された要求ユニット数が、プロビジョニングされた RU/秒の数を超えた場合に発生します。 手動スループットを使用している場合は、プロビジョニングされた手動スループットよりも多くの RU/秒を使用した場合に、これが発生します。 自動スケーリングを使用している場合は、プロビジョニングされた最大値より多くの RU/秒を使用した場合に、これが発生します。 たとえば、400 RU/s の手動スループットでリソースをプロビジョニングしている場合は、1 秒間に 400 を超える要求ユニットを使用すると、429 が表示されます。 4000 RU/sの最大自動スケーリング RU/s (400 RU/s - 4000 RU/s の範囲でスケーリング) でリソースをプロビジョニングしている場合は、1 秒間に 4000 を超える要求ユニットを使用すると、429 応答が表示されます。
ヒント
どの操作も、使用されたリソースの数に基づいて課金されます。 これらの料金は要求ユニットで計算されます。 これらの料金には、400、412、449 などのアプリケーション エラーが原因で正常に完了しなかった要求が含まれます。スロットリングまたは使用状況を確認するとき、使用法で何らかのパターンが変更され、その結果、これらの操作が増加したかどうかを調査することをお勧めします。 具体的には、タグ 412 または 449 (実際の競合) を確認します。
プロビジョニングされるスループットについて詳しくは、Azure Cosmos DB でプロビジョニングされるスループットに関するページを参照してください。
手順 1: メトリックを調べて、429 エラーが発生した要求のパーセンテージを確認する
429 エラー メッセージが表示されることは、必ずしもデータベースまたはコンテナーに問題があることを意味しません。 手動と自動スケーリングのどちらのスループットを使用している場合でも、429 応答が表示される割合が小さい場合は正常で、これは、プロビジョニングした RU/s を最大限に使用していることを示します。
調査方法
429 応答が発生したデータベースまたはコンテナーに対する要求のパーセンテージを、成功した要求の総数と比較して特定します。 Azure Cosmos DB アカウントから [分析情報]>[要求]>[状態コードごとの要求の合計数] に移動します。 フィルター処理して、特定のデータベースとコンテナーを表示します。
Azure Cosmos DB クライアント SDK とデータ インポート ツール (Azure Data Factory、バルク エグゼキューター ライブラリなど) は、429 が発生すると、既定では要求を自動的に再試行します。 通常は、9 回まで再試行します。 このため、メトリックで 429 応答が表示されている一方で、これらのエラーがアプリケーションに返されていない場合もあります。
![429 および 2xx 要求の数を示す [状態コードごとの要求の合計数] グラフ。](media/troubleshoot-request-rate-too-large/insights-429-requests.png)
推奨される解決策
一般的に、運用ワークロードで、要求の 1 から 5% で 429 応答が発生し、エンド ツー エンドの待機時間が許容範囲内である場合、これは RU/s が完全に利用されているという正常な兆候です。 必要な操作はありません。 それ以外の場合は、次のトラブルシューティング手順に進みます。
重要
この 1 から 5% の範囲は、アカウント パーティションが均等に分散されていることを前提としています。 パーティションが均等に分散されていない場合、問題のあるパーティションで大量の 429 エラーが返され、全体的な割合は低くなる可能性があります。
自動スケーリングを使用している場合は、RU/s が最大 RU/s までスケーリングされていなくても、データベースまたはコンテナーに 429 応答が表示される可能性があります。 説明については、「自動スケーリングで要求率が高い」セクションを参照してください。
よくある質問の 1 つは、"Azure Monitor メトリックには 429 応答が表示されるが、自分のアプリケーションの監視では表示されないのはなぜか" です。Azure Monitor メトリクスで 429 応答が表示されるが、自分のアプリケーションには表示されない場合、その理由は、Azure Cosmos DB クライアント SDK automatically retried internally on the 429 responses と要求が、後続の再試行に既定で引き継がれることです。 その結果、429 状態コードがアプリケーションに返されません。 このような場合は、全体の割合が 1 から 5% であり、エンドツーエンドの待機時間がアプリケーションの許容範囲内であると仮定すると、通常、429 応答の全体的な割合は極小なので、無視しても安全です。
手順 2: ホット パーティションが発生しているかどうかを特定する
ホット パーティションが発生するのは、要求量の多さが原因で、1 つ以上の論理パーティション キーによって消費される RU/秒の合計量が不均衡な場合です。 この原因として考えられるのは、要求を均等に分散させないパーティション キーの設計です。 この結果、多くの要求が論理 (物理を意味する) パーティションの小規模なサブセットに送信され、それらが "ホット" になります。論理パーティションのすべてのデータは 1 つの物理パーティションに存在し、それらの物理パーティション間で RU/s の合計量が均等に分配されます。このため、ホット パーティションで 429 応答が発生し、スループットが非効率的に使用されることになります。
ホット パーティションの原因となるパーティション分割戦略の例を次に示します。
- 書き込みが多いワークロード用の IoT デバイス データを保存する、
dateでパーティション分割されたコンテナーがあります。 1 つの日付のすべてのデータが、同じ論理および物理パーティションに存在します。 毎日書き込まれるすべてのデータが同じ日付であるため、毎日ホット パーティションが発生します。- 代わりに、このシナリオでは、
id(GUID またはデバイス ID) などのパーティション キー、またはidとdateを組み合わせた合成パーティション キーを使用すると、値のカーディナリティが高まり、要求量がより適切に分配されます。
- 代わりに、このシナリオでは、
tenantIdによってパーティション分割されたコンテナーを使用するマルチテナント シナリオがあります。 1 つのテナントが他のテナントよりもはるかにアクティブな場合は、ホット パーティションが発生します。 たとえば、最大のテナントのユーザー数が 100,000 人で、ほとんどのテナントのユーザー数が 10 人未満の場合、tenantIDでパーティション分割すると、ホット パーティションが発生します。- この前述のシナリオでは、
UserIdなどのより詳細なプロパティによってパーティション分割された、最大テナント用の専用コンテナーを使用することを検討します。
- この前述のシナリオでは、
ホット パーティションを識別する方法
ホット パーティションがあるかどうかを確認するには、[分析情報]>[スループット]>[Normalized RU Consumption (%) By PartitionKeyRangeID](PartitionKeyRangeID ごとの正規化された RU 消費量 (%)) に移動します。 フィルター処理して、特定のデータベースとコンテナーを表示します。
各 PartitionKeyRangeId は、1 つの物理パーティションにマップされます。 ある PartitionKeyRangeId の正規化された RU 消費量が、他の RU 消費量よりもはるかに高い (1 つが常に 100% で、それ以外が 30% 以下、など) 場合は、ホット パーティションの兆候である可能性があります。 正規化された RU 消費量メトリックの詳細については、こちらを参照してください。
![ホット パーティションが含まれる [PartitionKeyRangeID ごとの正規化された RU 消費量] グラフ。](media/troubleshoot-request-rate-too-large/split-norm-utilization-by-pkrange-hot-partition.png)
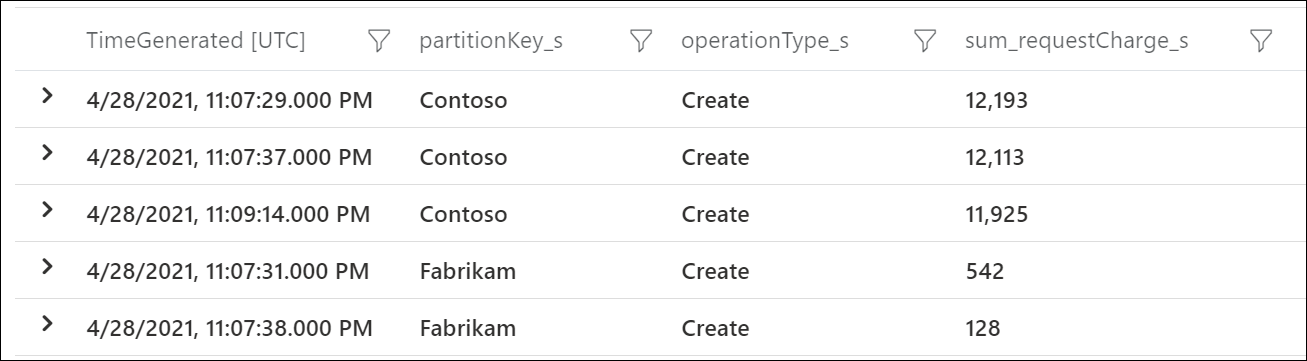
最も RU/秒を消費している論理パーティション キーを確認するには、Azure 診断ログを使用します。 このサンプル クエリでは、各論理パーティション キーで 1 秒間に消費された合計要求ユニット数が合計されます。
重要
診断ログを有効にすると、Log Analytics サービスに対して別途料金が発生します。これは、取り込まれたデータの量に基づいて課金されます。 診断ログは、デバッグのための限られた時間だけ有効にし、不要になったら、無効にすることをお勧めします。 詳細については、価格に関するページをご覧ください。
CDBPartitionKeyRUConsumption
| where TimeGenerated >= ago(24hour)
| where CollectionName == "CollectionName"
| where isnotempty(PartitionKey)
// Sum total request units consumed by logical partition key for each second
| summarize sum(RequestCharge) by PartitionKey, OperationName, bin(TimeGenerated, 1s)
| order by sum_RequestCharge desc
このサンプル出力では、特定の分において、"Contoso" という値の論理パーティション キーで約 12,000 RU/秒が消費された一方で、"Fabrikam" という値の論理パーティション キーでは 600 RU/秒未満が消費されたことが示されています。 レート制限が発生した期間中にこのパターンが一貫して見られる場合、これはホット パーティションを示します。
ヒント
どのワークロードでも、論理パーティション間で要求量は自然に変化します。 ホット パーティションの原因が、パーティション キーの選択による根本的な歪みであるか (この場合、キーの変更が必要になることがあります)、またはワークロード パターンの自然な変動による一時的な急増であるか特定する必要があります。
推奨される解決策
適切なパーティション キーを選択する方法に関するガイダンスを確認します。
レート制限された要求のパーセンテージが高く、ホット パーティションがない場合:
- クライアント SDK、Azure portal、PowerShell、CLI、または ARM テンプレートを使用して、データベースまたはコンテナーで RU/秒を増やすことができます。 「プロビジョニングされたスループットのスケーリングに関するベスト プラクティス」に従って、設定する適切な RU/s を決定します。
レート制限された要求のパーセンテージが高く、根底にホット パーティションがある場合:
- 長期的には、最適なコストとパフォーマンスのために、パーティション キーの変更を検討します。 パーティション キーは更新できないため、この場合、異なるパーティション キーを持つ新しいコンテナーにデータを移行する必要があります。 Azure Cosmos DB では、この目的のためにライブ データ移行ツールがサポートされています。
- 短期的には、リソースの全体的な RU/秒を一時的に増やして、ホット パーティションのスループットを向上させることができます。 これは、RU/秒のオーバープロビジョニングとコストの増加につながるため、長期的な戦略としては推奨されません。
- 短期的には、パーティション間のスループット再分散機能 (プレビュー) を使用して、ホットな物理パーティションにより多くの RU/秒を割り当てることができます。 これは、ホット物理パーティションが予測可能で、かつ一貫性がある場合にのみ推奨されます。
ヒント
スループットを増やす場合、スケールアップする先の RU/秒の数によって、スケールアップ操作は即座に完了するか、完了まで最大で 5 から 6 時間必要になります。 非同期のスケールアップ操作 (追加の物理パーティションをプロビジョニングするために Azure Cosmos DB が必要になります) をトリガーせずに設定できる RU/秒の最大数を確認するには、個別の PartitionKeyRangeId の数に 100,000 RU/秒を乗算します。 たとえば、30,000 RU/秒がプロビジョニングされ、5 つの物理パーティションがある場合 (物理パーティションごとに 6000 RU/秒が割り当てられている)、即座のスケールアップ操作で 50,000 RU/秒 (物理パーティションあたり 10,000 RU/秒) まで増やすことができます。 >50,000 RU/秒よりも多い数に増やすには、非同期のスケールアップ操作が必要です。 詳細については、プロビジョニングされたスループット (RU/秒) のスケーリングに関するベスト プラクティスに関する記事を参照してください。
手順 3: 429 応答を返す要求を特定する
429 応答が発生する要求を調査する方法
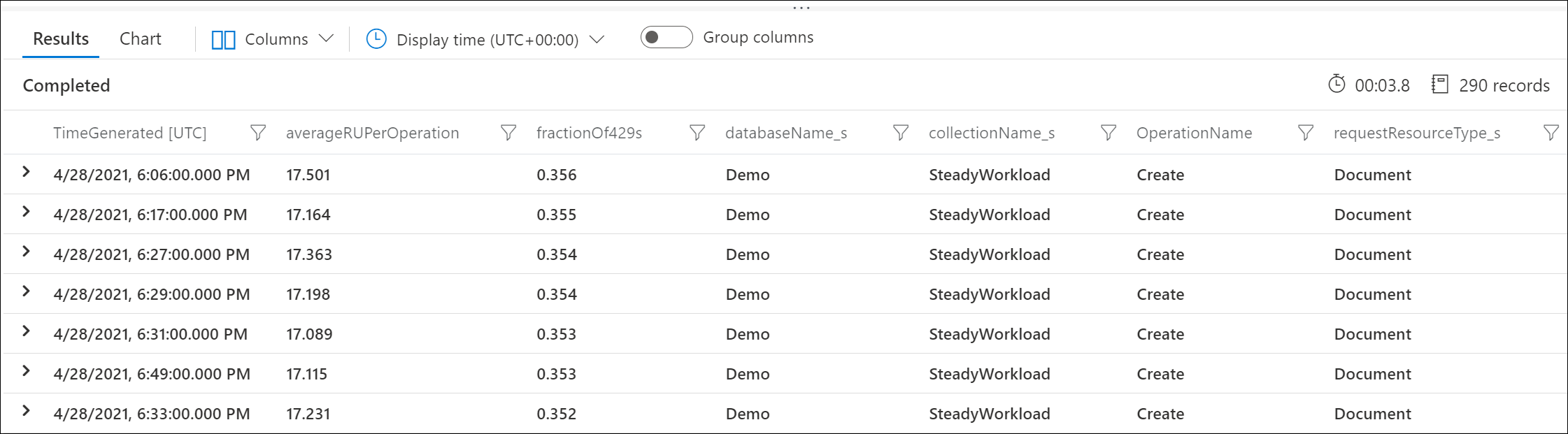
Azure 診断ログを使用して、429 応答を返す要求と、それらによって消費された RU の数を特定します。 このサンプル クエリでは、分レベルで集計されます。
重要
診断ログを有効にすると、Log Analytics サービスに対して別途料金が発生します。これは、取り込まれたデータの量に基づいて課金されます。 診断ログは、デバッグのための限られた時間だけ有効にし、不要になったら無効にすることをお勧めします。 詳細については、価格に関するページをご覧ください。
CDBDataPlaneRequests
| where TimeGenerated >= ago(24h)
| summarize throttledOperations = dcountif(ActivityId, StatusCode == 429), totalOperations = dcount(ActivityId), totalConsumedRUPerMinute = sum(RequestCharge) by DatabaseName, CollectionName, OperationName, RequestResourceType, bin(TimeGenerated, 1min)
| extend averageRUPerOperation = 1.0 * totalConsumedRUPerMinute / totalOperations
| extend fractionOf429s = 1.0 * throttledOperations / totalOperations
| order by fractionOf429s desc
たとえば、このサンプル出力では、各分で、ドキュメント作成要求の 30% がレート制限されており、各要求で平均 17 個の RU が消費されています。
推奨される解決策
Azure Cosmos DB Capacity Planner を使用する
Azure Cosmos DB Capacity Planner を使用して、ワークロード (操作の量と種類、およびドキュメントのサイズ) に基づいて、プロビジョニングされる最高のスループットを把握できます。 サンプル データを提供することで、計算をさらにカスタマイズし、いっそう正確に見積もることができます。
ドキュメントの作成、置換、またはアップサート要求での 429 応答
- NoSQL 用 API の既定では、すべてのプロパティに既定でインデックスが付けられます。 必要なプロパティにのみインデックスを付けるようにインデックス作成ポリシーを調整します。 これにより、ドキュメントの作成操作ごとに必要となる要求ユニットの数が減少し、429 応答が表示される可能性が低くなります。また、プロビジョニングされた同じ量の RU/s に対して、1 秒あたりにより多くの操作を実行できます。
ドキュメントのクエリ要求での 429 応答
- ガイダンスに従って、RU 料金が高い場合のクエリのトラブルシューティングを行います。
ストアド プロシージャの実行での 429 応答
- ストアド プロシージャは、パーティション キー値に対する書き込みトランザクションが必要な操作に適しています。 多くの読み取りまたはクエリ操作では、ストアド プロシージャを使用しないことをお勧めします。 最適なパフォーマンスを実現するために、これらの読み取りまたはクエリ操作は、Azure Cosmos DB SDK を使用してクライアント側で実行する必要があります。
自動スケーリングで要求率が高い
この記事のすべてのガイダンスは、手動と自動スケーリングの両方のスループットに適用されます。
自動スケーリングを使用している場合によくある質問は、"自動スケーリングの場合でも 429 応答が表示されるのか" です。
はい。 これが発生する可能性がある主なシナリオは、次の 2 つです。
シナリオ 1: 消費された RU/秒の全体が、データベースまたはコンテナーの最大 RU/秒を超えると、それに応じてサービスが要求をスロットルします。 これは、手動でプロビジョニングされた、データベースまたはコンテナーのスループット全体を超えることに似ています。
シナリオ 2: ホット パーティションがある、つまり、他のパーティション キー値と比較して要求が過剰に増加する論理パーティション キー値がある場合は、基になる物理パーティションが RU/s の予算を超える可能性があります。 ベスト プラクティスとして、ホット パーティションを回避するには、ストレージとスループットの両方が均等に分散される適切なパーティション キーを選択します。 これは、手動スループットの使用時にホット パーティションが発生している場合と似ています。
たとえば、20,000 RU/秒の最大スループット オプションを選択し、4 つの物理パーティションを含む 200 GB のストレージを使用している場合は、各物理パーティションを 5000 RU/秒まで自動スケーリングできます。 特定の論理パーティション キーにホット パーティションがあった場合は、その場所の、基になる物理パーティションが 5000 RU/s を超える (つまり、100% の正規化された使用率を超える) と、429 応答が表示されます。
これらのシナリオをデバッグするには、手順 1、手順 2、および手順 3 のガイダンスに従います。
もう 1 つの一般的な質問は、正規化された RU 消費量が 100% であるのに、なぜ、自動スケーリングで最大 RU/秒にスケーリングされなかったのか" です。
これは、通常、一時的または断続的に使用量が急増するワークロードで発生します。 自動スケーリングを使用すると、5 秒間隔で、継続して連続した期間だけ、正規化された RU 消費量が 100% になる場合に、Azure Cosmos DB で RU/s が最大スループットにスケーリングされます。 これは、ユーザーにとってコスト効率の高いスケーリング ロジックとなるように行われます。これによって、瞬間的な 1 回の急増による、不要なスケーリングの実行と、コストの増加が防止されるためです。 瞬間的な急増が発生した場合は、通常、以前にスケーリングされた RU/秒より大きく、最大 RU/秒より小さい値にスケールアップされます。 自動スケーリングを使用して正規化 された RU 消費量メトリックを解釈する方法を詳しく調べてください。
メタデータ要求に対するレート制限
メタデータのレート制限は、データベース、コンテナー、またはその両方で大量のメタデータ操作を実行すると発生する可能性があります。 メタデータ操作には、以下が含まれます。
- コンテナーまたはデータベースの作成、読み取り、更新、または削除
- Azure Cosmos DB アカウントのデータベースまたはコンテナーを一覧表示する
- 現在プロビジョニングされているスループットを確認するためのオファーに対するクエリ
これらの操作には、システムで予約されている RU 制限があるため、データベースまたはコンテナーの RU/秒をプロビジョニングして増やしても、影響はありません。したがって、これは推奨されません。 コントロール プレーン サービスの制限に関するページを参照してください。
調査方法
[分析情報]>[システム]>[状態コードごとのメタデータ要求数] に移動します。 必要に応じて、フィルター処理して特定のデータベースとコンテナーを表示します。
![[分析情報] 内の [状態コードごとのメタデータ要求数] グラフ。](media/troubleshoot-request-rate-too-large/metadata-throttling-insights.png)
推奨される解決策
アプリケーションでメタデータ操作を実行する必要がある場合、これらの要求を低いレートで送信するために、バックオフ ポリシーを実装することを検討します。
静的な Azure Cosmos DB クライアント インスタンスを使用します。 DocumentClient または CosmosClient が初期化されると、Azure Cosmos DB SDK により、整合性レベル、データベース、コンテナー、パーティション、オファーに関する情報など、アカウントに関するメタデータがフェッチされます。 この初期化では多数の RU が消費される可能性があるため、頻繁には実行しないでください。 単一 DocumentClient インスタンスを、お使いのアプリケーションの有効期間中に使用します。
データベースとコンテナーの名前をキャッシュします。 構成からデータベースとコンテナーの名前を取得するか、開始時にそれらをキャッシュします。 ReadDatabaseAsync/ReadDocumentCollectionAsync や CreateDatabaseQuery/CreateDocumentCollectionQuery などの呼び出しでは、サービスに対するメタデータ呼び出しが行われ、システムで予約されている RU 制限から消費されます。 これらの操作は、頻繁には実行しないでください。
一時的なサービス エラーによるレート制限
この 429 エラーは、要求で一時的なサービス エラーが発生した場合に返されます。 データベースまたはコンテナーに対して RU/秒を増やしても影響はありません。したがって、これは推奨されません。
推奨される解決策
要求をやり直してください。 エラーが数分間続く場合は、Azure portal からサポート チケットを提出してください。
次の手順
- データベースまたはコンテナーの正規化された RU/秒の消費を監視する。
- Azure Cosmos DB .NET SDK 使用時の問題を診断してトラブルシューティングする。
- .NET v3 と .NET v2 のパフォーマンス ガイドラインを確認する。
- Azure Cosmos DB Java v4 SDK 使用時の問題を診断してトラブルシューティングする。
- Java v4 SDK のパフォーマンス ガイドラインを確認する。