マッピング データ フローの条件分割変換
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
データ フローは、Azure Data Factory および Azure Synapse Pipelines の両方で使用できます。 この記事は、マッピング データ フローに適用されます。 変換を初めて使用する場合は、概要の記事「マッピング データ フローを使用してデータを変換する」を参照してください。
条件分割変換では、データ行を、一致条件に応じて異なるストリームにルーティングします。 条件分割変換は、プログラミング言語の CASE 決定構造と似ています。 この変換では式を評価し、その結果に基づいて、データ行を指定されたストリームに送ります。
構成
[分割] 設定により、データの行の送り先が、最初に一致したストリームと、一致した全ストリームのどちらになるかが決まります。
データ フローの式ビルダーを使用して、分割条件の式を入力します。 新しい条件を追加する場合は、既存の行にあるプラス記号アイコンをクリックします。 いずれの条件にも一致しない行用に、既定のストリームを追加することもできます。
データ フローのスクリプト
構文
<incomingStream>
split(
<conditionalExpression1>
<conditionalExpression2>
...
disjoint: {true | false}
) ~> <splitTx>@(stream1, stream2, ..., <defaultStream>)
例
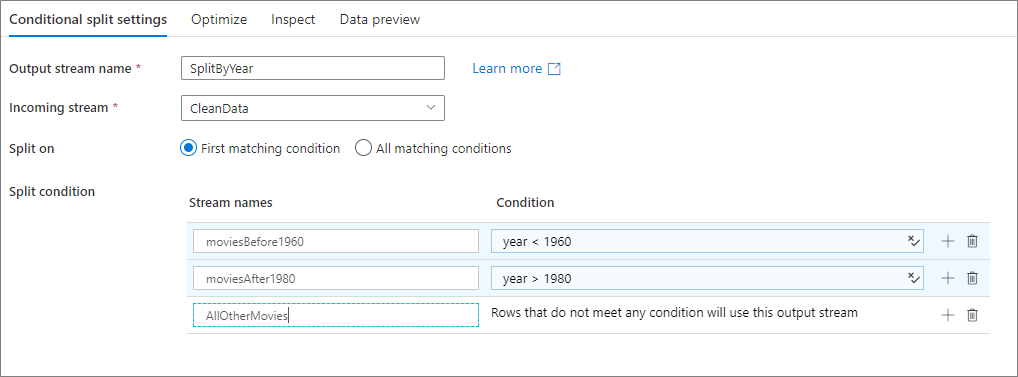
以下の例は、受信ストリーム CleanData を受け取る SplitByYear という名前の条件分割変換です。 この変換では、year < 1960 と year > 1980 という 2 つの分割条件が設定されています。 すべての条件に一致するのではなく、最初に一致した条件にデータを送るので、disjoint は false に設定しています。 最初の条件に一致した行はすべて、出力ストリーム moviesBefore1960 に送られます。 残りの行のうち 2 番目の条件に一致したものはすべて、出力ストリーム moviesAFter1980 に送られます。 その他のすべての行は、既定のストリーム AllOtherMovies に送られます。
サービスの UI では、この変換は下の画像のように表示されます。
この変換のデータ フロー スクリプトは、次のスニペットに含まれています。
CleanData
split(
year < 1960,
year > 1980,
disjoint: false
) ~> SplitByYear@(moviesBefore1960, moviesAfter1980, AllOtherMovies)