マッピング データ フローを使用してデータを変換する
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
Azure Data Factory を初めて使用する場合は、「Azure Data Factory の概要」を参照してください。
このチュートリアルでは、Azure Data Factory ユーザー インターフェイス (UX) を使い、マッピング データ フローを使用して Azure Data Lake Storage (ADLS) Gen2 ソースから ADLS Gen2 シンクにデータをコピーして変換するパイプラインを作成します。 このチュートリアルの構成パターンは、マッピング データ フローを使用してデータを変換するときに拡張することができます
Note
このチュートリアルでは、一般にデータ フローをマップすることを目的としています。 データ フローは、Azure Data Factory および Synapse パイプラインの両方で使用できます。 Azure Synapse パイプラインのデータ フローを初めて使用する場合は、Azure Synapse パイプラインを使用したデータ フローに関するページに従ってください
このチュートリアルでは、次の手順を実行します。
- データ ファクトリを作成します。
- Data Flow アクティビティを含むパイプラインを作成します。
- 4 つの変換を使用して、マッピング データ フローを構築します。
- パイプラインをテスト実行します。
- Data Flow アクティビティを監視します。
前提条件
- Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、開始する前に無料の Azure アカウントを作成してください。
- Azure ストレージ アカウント。 ADLS ストレージを、ソースとシンクのデータ ストアとして使用します。 ストレージ アカウントがない場合の作成手順については、Azure のストレージ アカウントの作成に関するページを参照してください。
このチュートリアルで変換するファイルは MoviesDB です。このファイルは、こちらにあります。 GitHub からファイルを取得するには、コンテンツを任意のテキスト エディターにコピーして、.csv ファイルとしてローカルに保存します。 ファイルをご自分のストレージ アカウントにアップロードするには、Azure portal を使用した BLOB のアップロードに関するページを参照してください。 例では、'sample-data' という名前のコンテナーを参照しています。
Data Factory の作成
この手順では、データ ファクトリを作成し、Data Factory UX を開いて、データ ファクトリにパイプラインを作成します。
Microsoft Edge または Google Chrome を開きます。 現在、Data Factory の UI がサポートされる Web ブラウザーは Microsoft Edge と Google Chrome だけです。
左側のメニューで、 [リソースの作成]>[統合]>[Data Factory] を選択します。
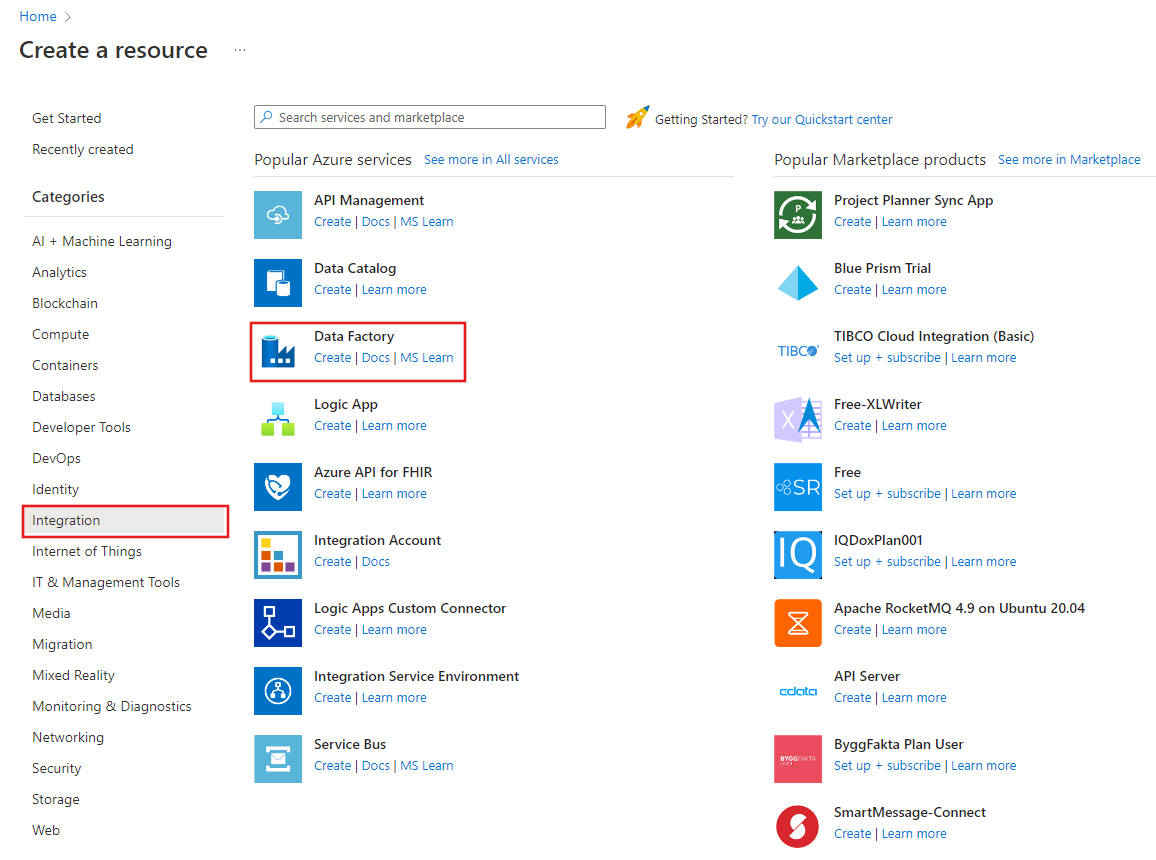
[新しいデータ ファクトリ] ページで、 [名前] に「ADFTutorialDataFactory」と入力します。
Azure データ ファクトリの名前は グローバルに一意にする必要があります。 データ ファクトリの名前の値に関するエラー メッセージが表示された場合は、別の名前を入力してください。 (yournameADFTutorialDataFactory など)。 Data Factory アーティファクトの名前付け規則については、Data Factory の名前付け規則に関するページを参照してください。
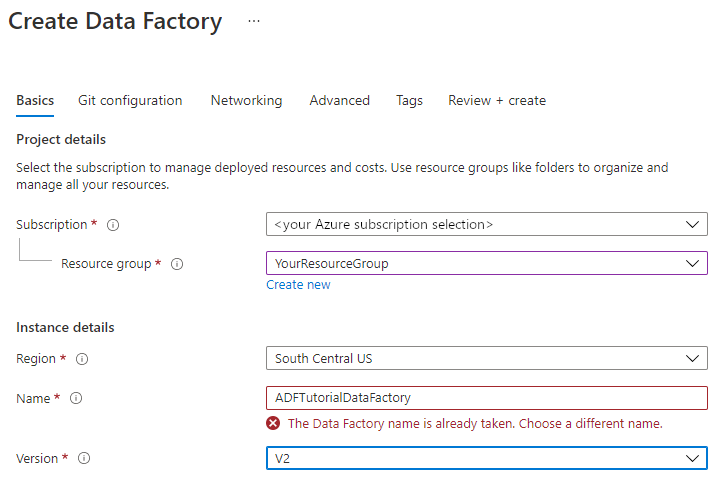
データ ファクトリを作成する Azure サブスクリプションを選択します。
[リソース グループ] で、次の手順のいずれかを行います。
a. [Use existing (既存のものを使用)] を選択し、ドロップダウン リストから既存のリソース グループを選択します。
b. [新規作成] を選択し、リソース グループの名前を入力します。
リソース グループの詳細については、リソース グループを使用した Azure のリソースの管理に関するページを参照してください。
[バージョン] で、 [V2] を選択します。
[場所] で、データ ファクトリの場所を選択します。 サポートされている場所のみがドロップダウン リストに表示されます。 データ ファクトリによって使用されるデータ ストア (Azure Storage、SQL Database など) やコンピューティング (Azure HDInsight など) は、他のリージョンに存在していてもかまいません。
[作成] を選択します
作成が完了すると、その旨が通知センターに表示されます。 [リソースに移動] を選択して、Data factory ページに移動します。
[Author & Monitor]\(作成と監視\) を選択して、別のタブで Data Factory (UI) を起動します。
Data Flow アクティビティを含むパイプラインの作成
この手順では、Data Flow アクティビティを含むパイプラインを作成します。
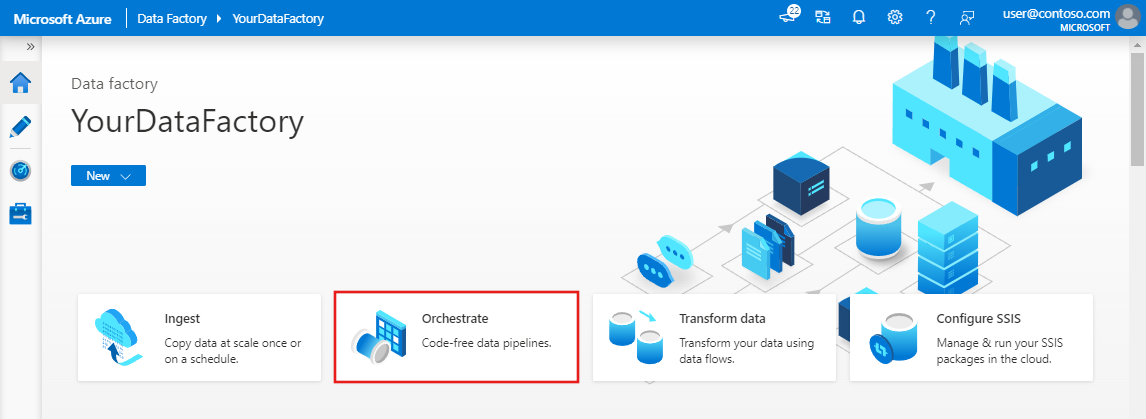
Azure Data Factory のホーム ページで、 [Orchestrate](調整) を選択します。
パイプラインの [全般] タブで、パイプラインの名前として「TransformMovies」と入力します。
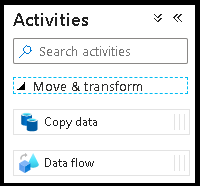
[アクティビティ] ウィンドウで、 [移動と変換] アコーディオンを展開します。 ウィンドウから Data Flow アクティビティをパイプライン キャンバスにドラッグ アンド ドロップします。
[Adding Data Flow](Data Flow の追加) ポップアップで、 [Create new Data Flow](新しい Data Flow の作成) を選択し、データ フローに TransformMovies という名前を付けます。 終了したら、[完了] をクリックします。
パイプライン キャンバスの上部のバーで、 [Data Flow のデバッグ] スライダーをオンにスライドします。 デバッグ モードを使用すると、ライブ Spark クラスターに対する変換ロジックの対話型テストが可能になります。 Data Flow クラスターのウォームアップには 5 から 7 分かかるため、ユーザーが Data Flow の開発を計画している場合は、最初にデバッグを有効にすることをお勧めします。 詳細については、デバッグ モードに関するページを参照してください。

データ フロー キャンバスでの変換ロジックの作成
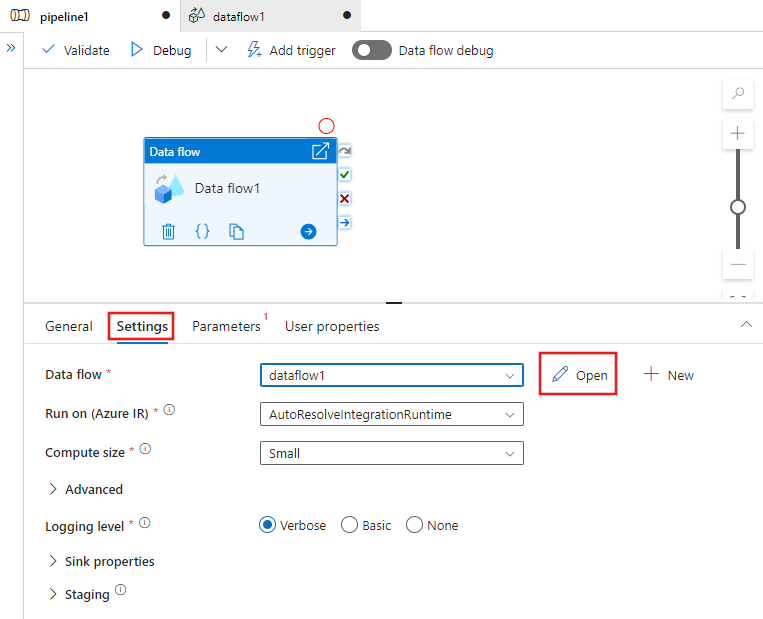
Data Flow を作成すると、データ フロー キャンバスが自動的に表示されます。 データ フロー キャンバスにリダイレクトされない場合は、キャンバスの下のパネルで [設定] に移動し、データ フロー フィールドの横にある [開く] を選択します。 これにより、データフロー キャンバスが開きます。
この手順では、ADLS ストレージ内の moviesDB.csv を取得し、1910 年から 2000 年までのコメディの平均評価を集計するデータ フローを作成します。 次に、このファイルを ADLS ストレージに書き戻します。
データ フロー キャンバスで [Add Source](ソースの追加) ボックスをクリックして、ソースを追加します。
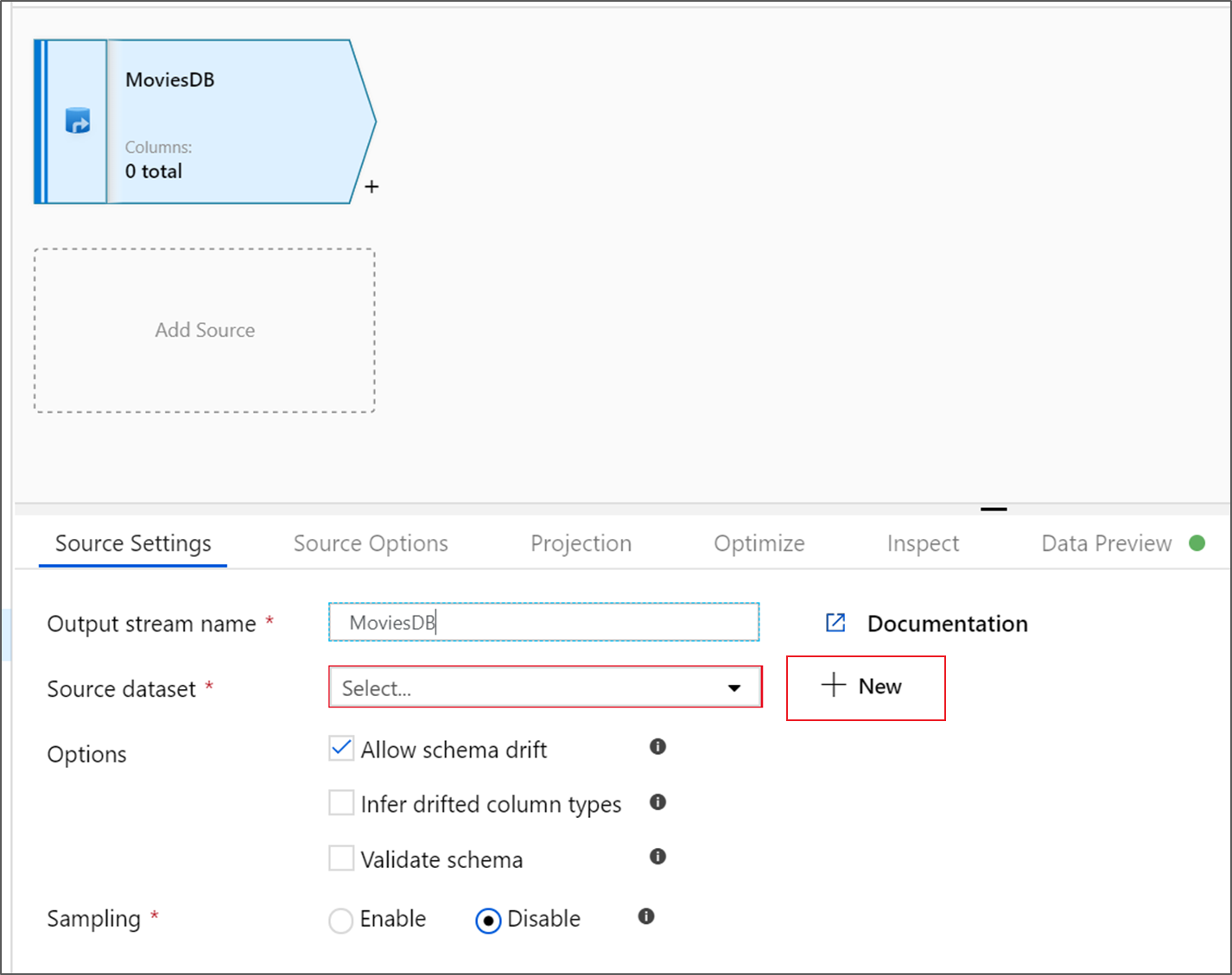
ソースに MoviesDB という名前を付けます。 [新規] をクリックして、新しいソース データセットを作成します。
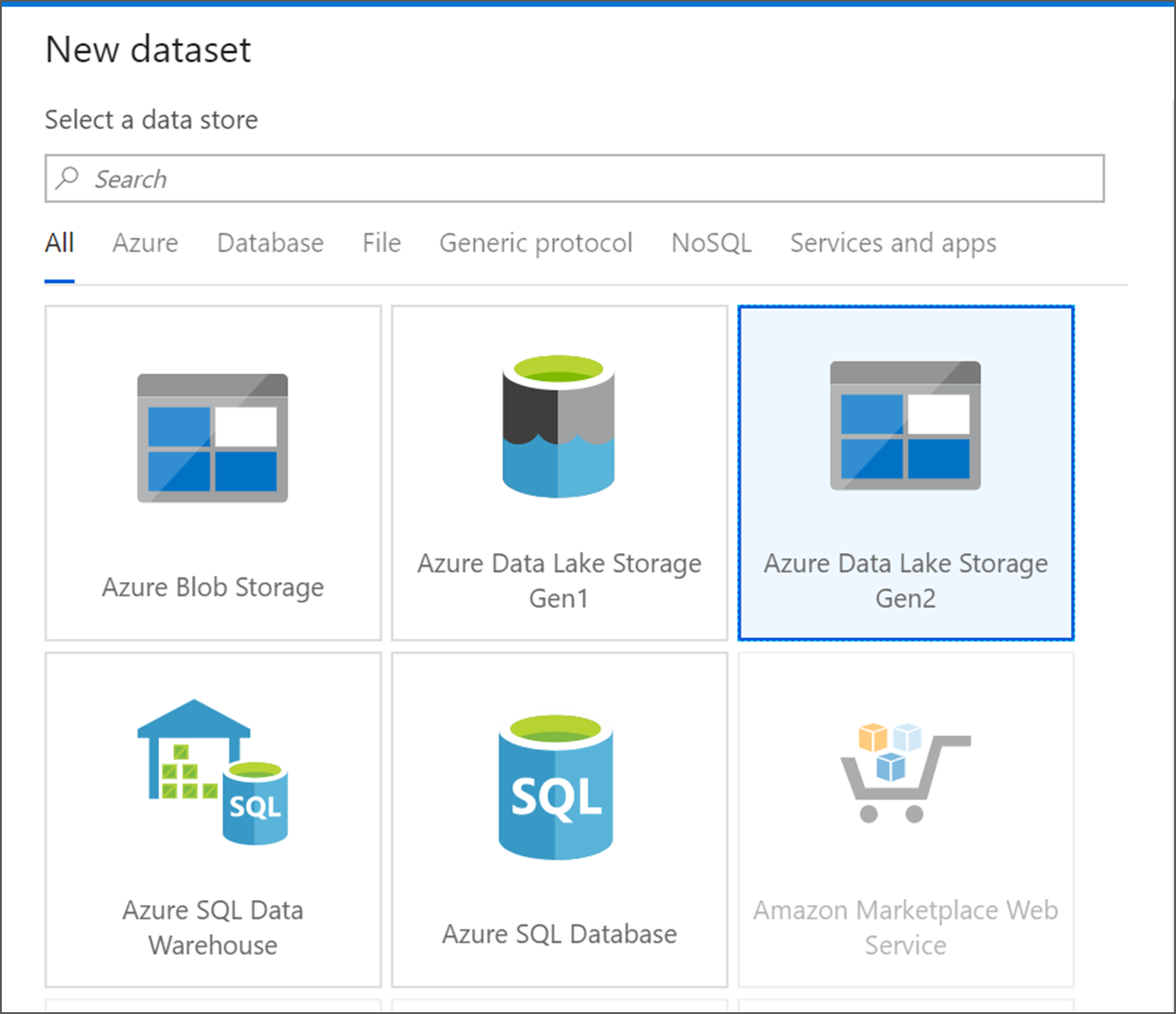
[Azure Data Lake Storage Gen2] を選択します。 [続行] をクリックして続行します。
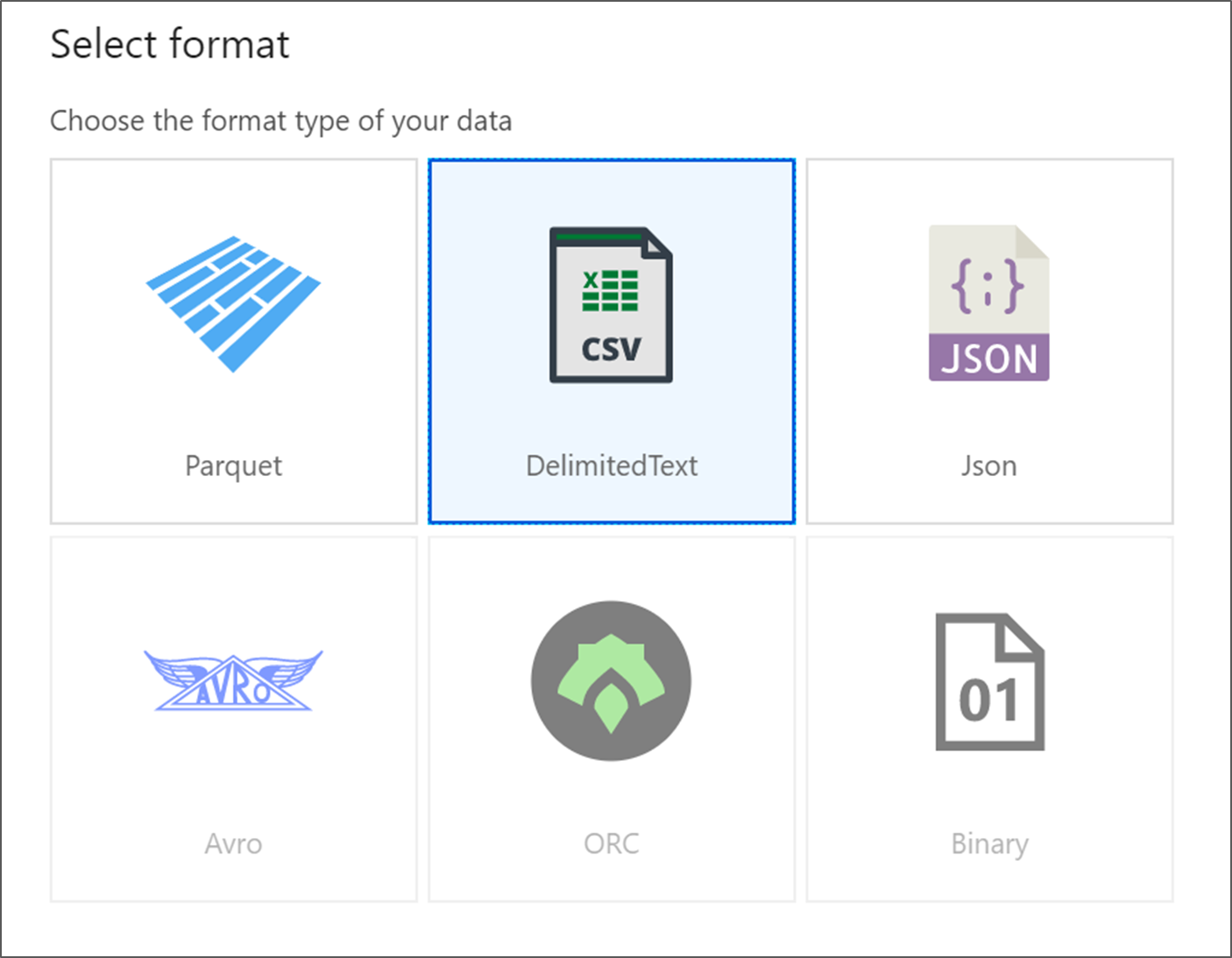
[DelimitedText] を選択します。 [続行] をクリックして続行します。
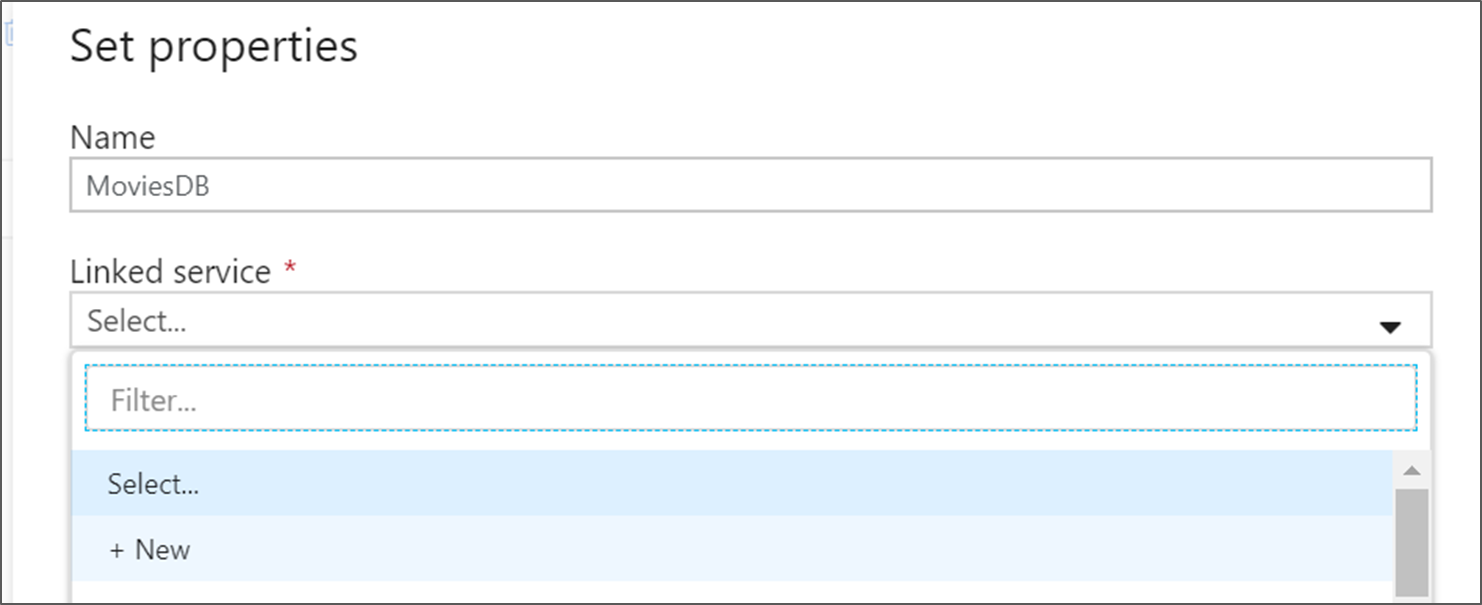
データセットに MoviesDB という名前を付けます。 リンクされたサービスのドロップダウンで、 [新規] を選択します。
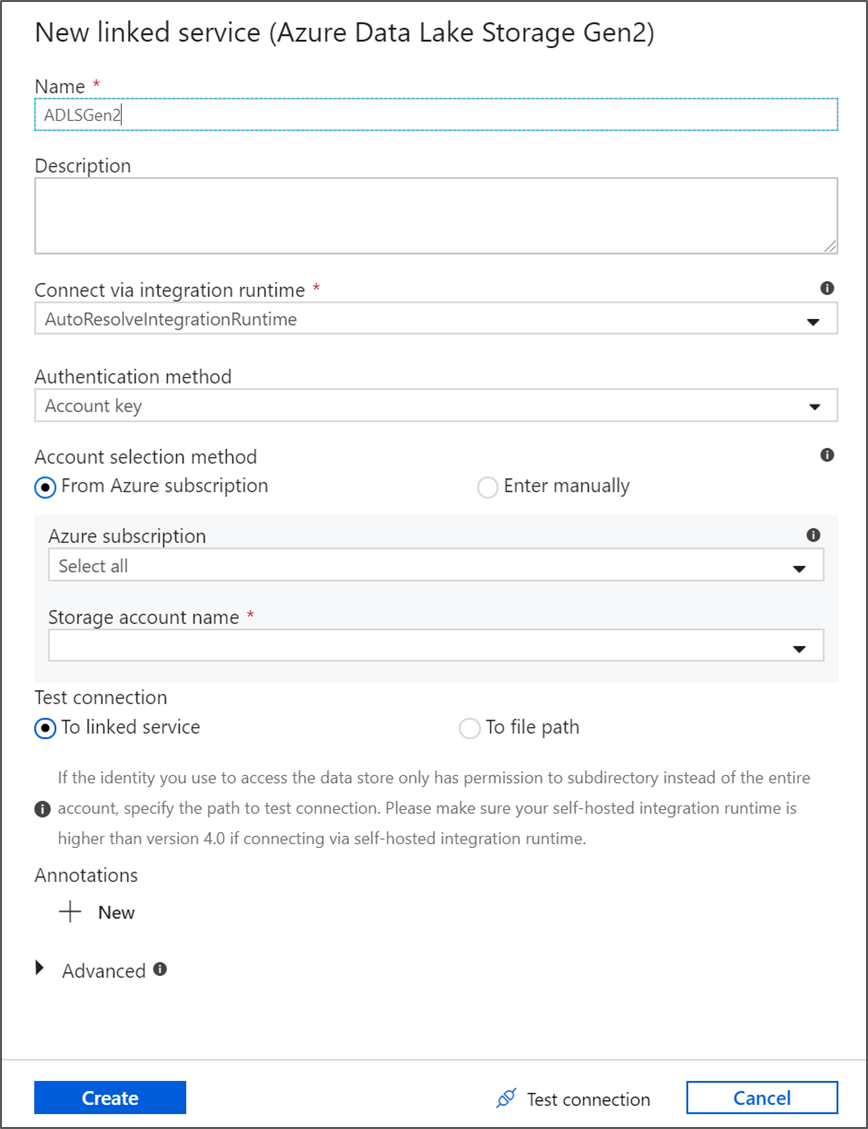
リンクされたサービスの作成画面で、ADLS gen2 のリンクされたサービスに ADLSGen2 という名前を付けて、使用する認証方法を指定します。 次に、接続の資格情報を入力します。 このチュートリアルでは、アカウント キーを使用してストレージ アカウントに接続しています。 [テスト接続] をクリックすると、資格情報が正しく入力されたことを確認できます。 完了したら [作成] をクリックします。
データセットの作成画面に戻ったら、 [ファイル パス] フィールドの下でファイルが配置されている場所を入力します。 このチュートリアルでは、moviesDB.csv ファイルはコンテナー sample-data に配置されています。 ファイルにはヘッダーが含まれているため、 [First row as header](最初の行をヘッダーにする) をオンにします。 ストレージ内のファイルからヘッダー スキーマを直接インポートするには、 [From connection/store](接続/ストアから) を選択します。 完了したら、 [OK] をクリックします。
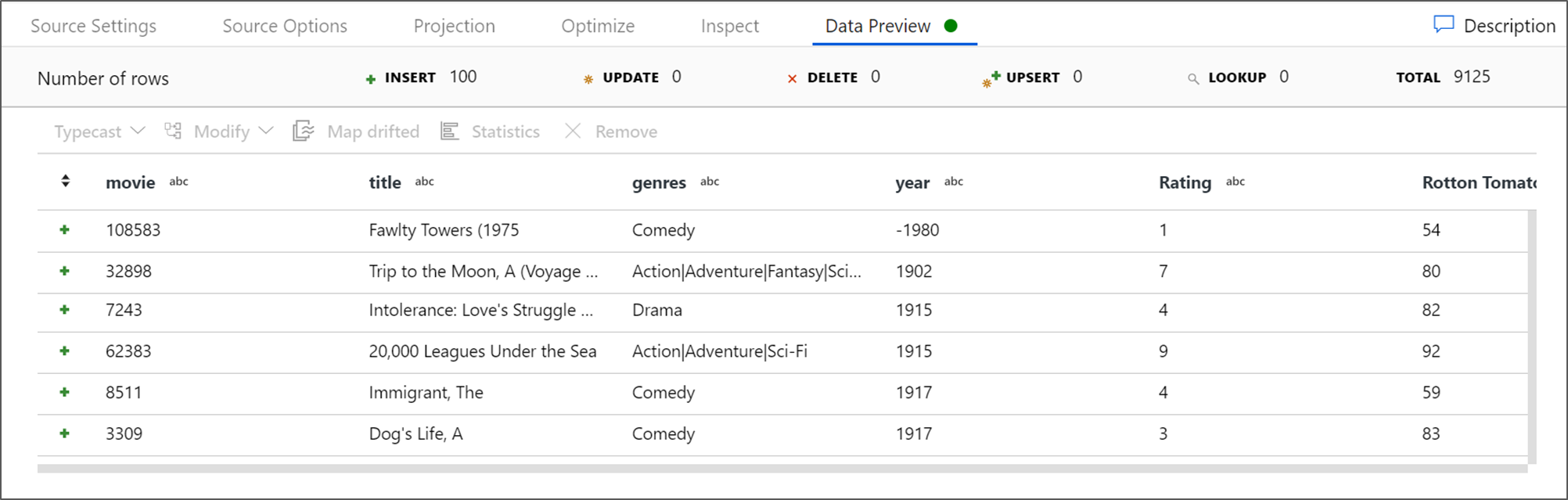
デバッグ クラスターが起動している場合は、ソース変換の [Data Preview](データのプレビュー) タブに移動し、 [更新] をクリックして、データのスナップショットを取得します。 データ プレビューを使用すると、変換が正しく構成されていることを確認できます。
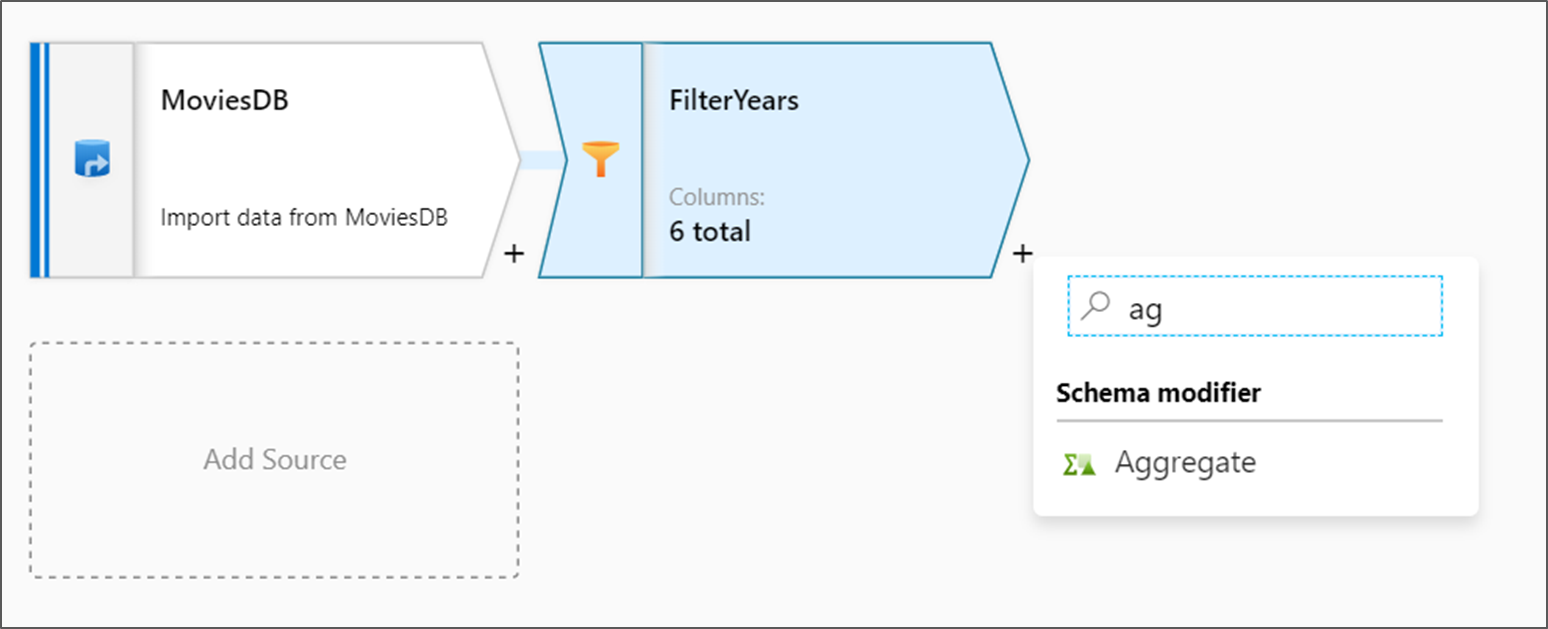
データ フロー キャンバスでソース ノードの横にあるプラス アイコンをクリックして、新しい変換を追加します。 最初に追加する変換は、フィルターです。
フィルター変換に FilterYears という名前を付けます。 [フィルター適用] の横にある式ボックスをクリックして、式ビルダーを開きます。 ここでフィルター条件を指定します。
データ フローの式ビルダーでは、さまざまな変換で使用する式を対話形式で作成できます。 式には、組み込み関数、入力スキーマの列、ユーザー定義のパラメーターを含めることができます。 式の作成方法の詳細については、Data Flow の式ビルダーに関するページを参照してください。
このチュートリアルでは、1910 年から 2000 年の間に公開された、ジャンルがコメディの映画をフィルター処理します。 現在、年は文字列になっているため、
toInteger()関数を使用して整数に変換する必要があります。 以上演算子 (>=) と以下演算子 (<=) を使用して、年のリテラル値 1910 と 2000 に対する比較を行います。 これらの式を and (&&) 演算子を使用して結合します。 式は次のようになります。toInteger(year) >= 1910 && toInteger(year) <= 2000コメディ映画を見つけるには、
rlike()関数を使用して、ジャンル列でパターン 'Comedy' を検索します。rlike式を年の比較と結合すると、次の式が得られます。toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')デバッグ クラスターがアクティブになっている場合は、 [更新] をクリックして使用された入力と比較した式の出力を表示して、ロジックを確認できます。 データ フローの式言語を使用してこのロジックを実現する方法に対する正解は複数あります。
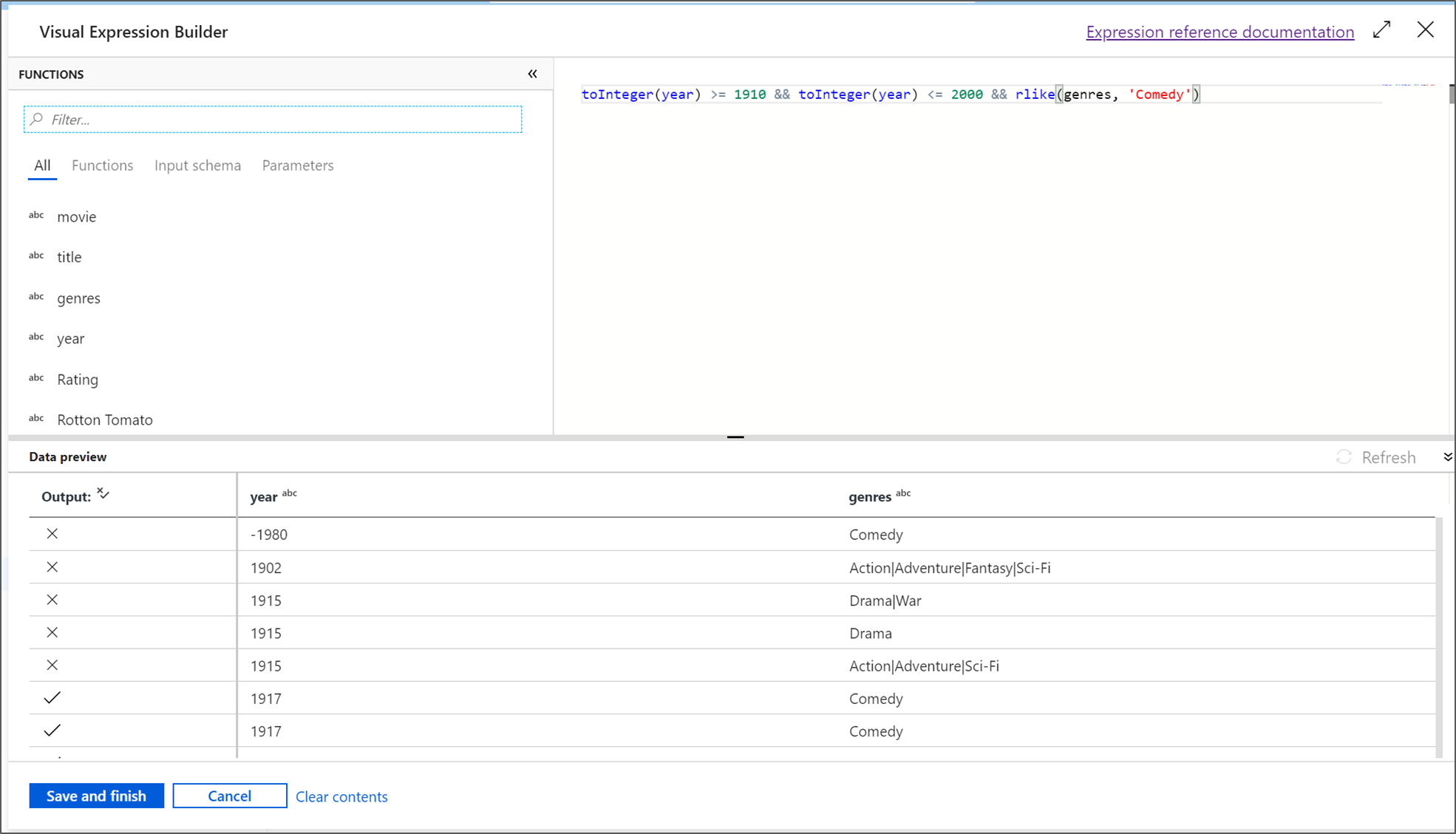
式の操作が完了したら、 [Save and Finish](保存して終了する) をクリックします。
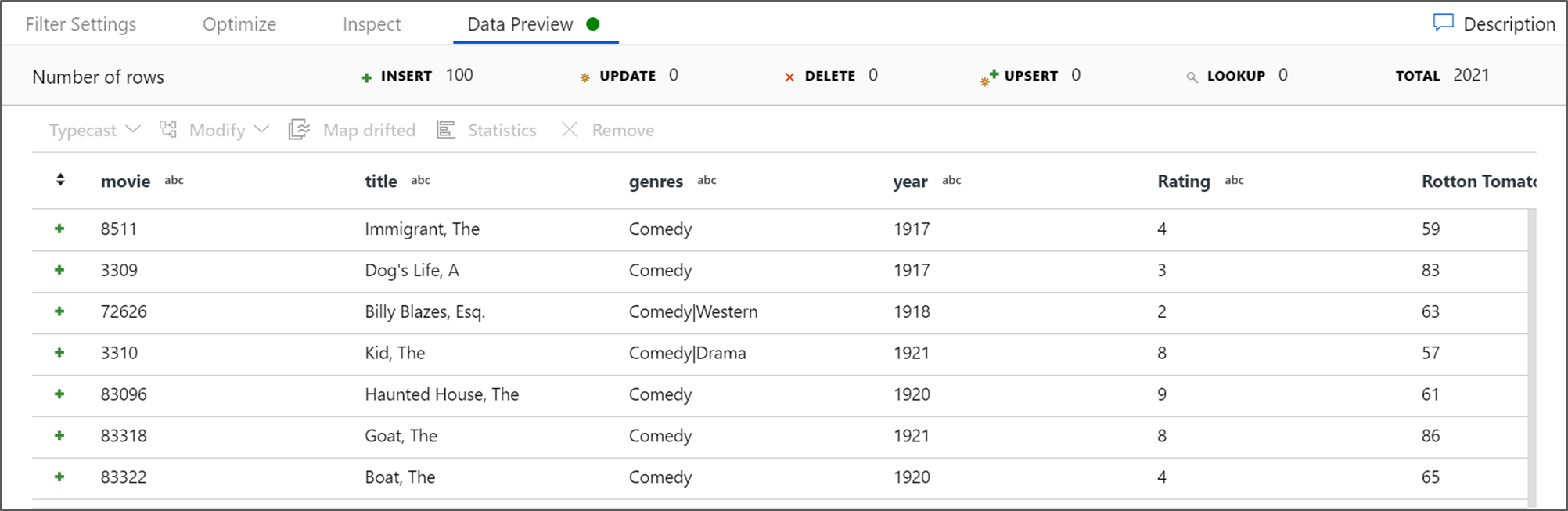
フィルターが正しく機能していることを確認するには、データ プレビューをフェッチします。
次に追加する変換は、 [Schema modifier](スキーマ修飾子) の下にある [集計] 変換です。
集計変換に AggregateComedyRatings という名前を付けます。 [グループ化] タブで、ドロップダウンから [year] を選択し、映画の公開年ごとに集計をグループ化します。
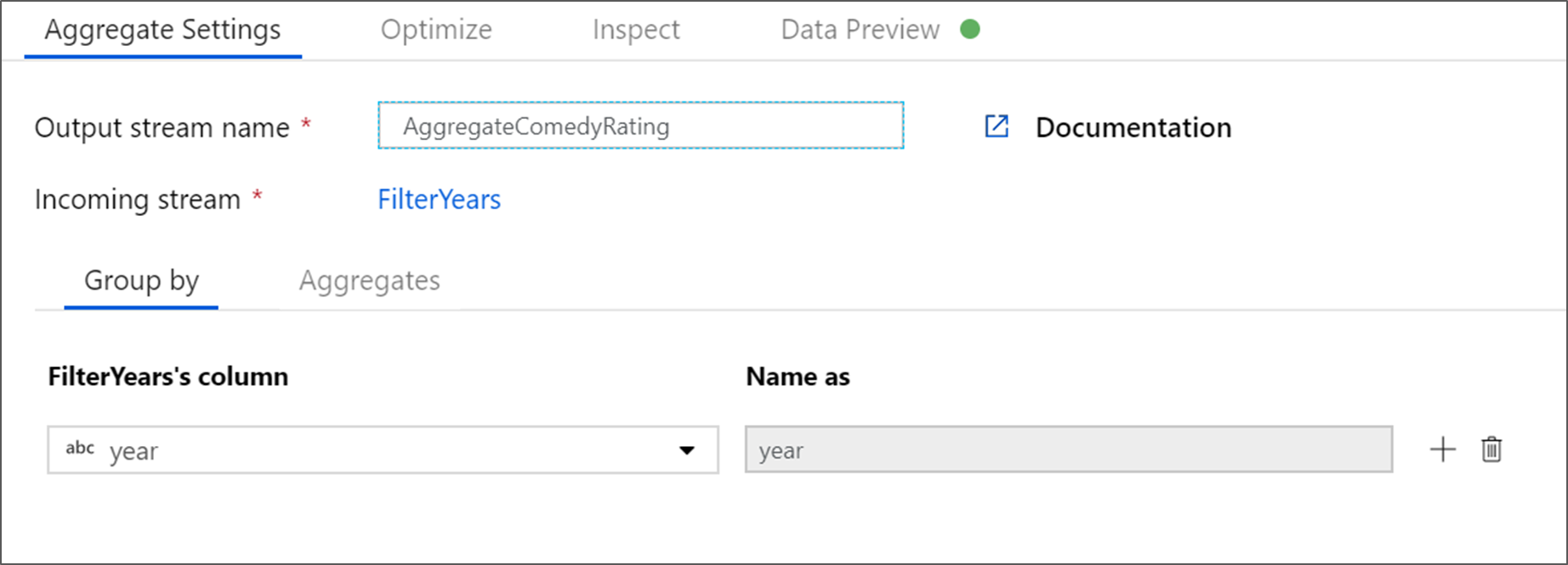
[集計] タブに移動します。左側のテキスト ボックスで、集計列に AverageComedyRating という名前を付けます。 式ビルダーを使用して集計式を入力するには、右側の式ボックスをクリックします。
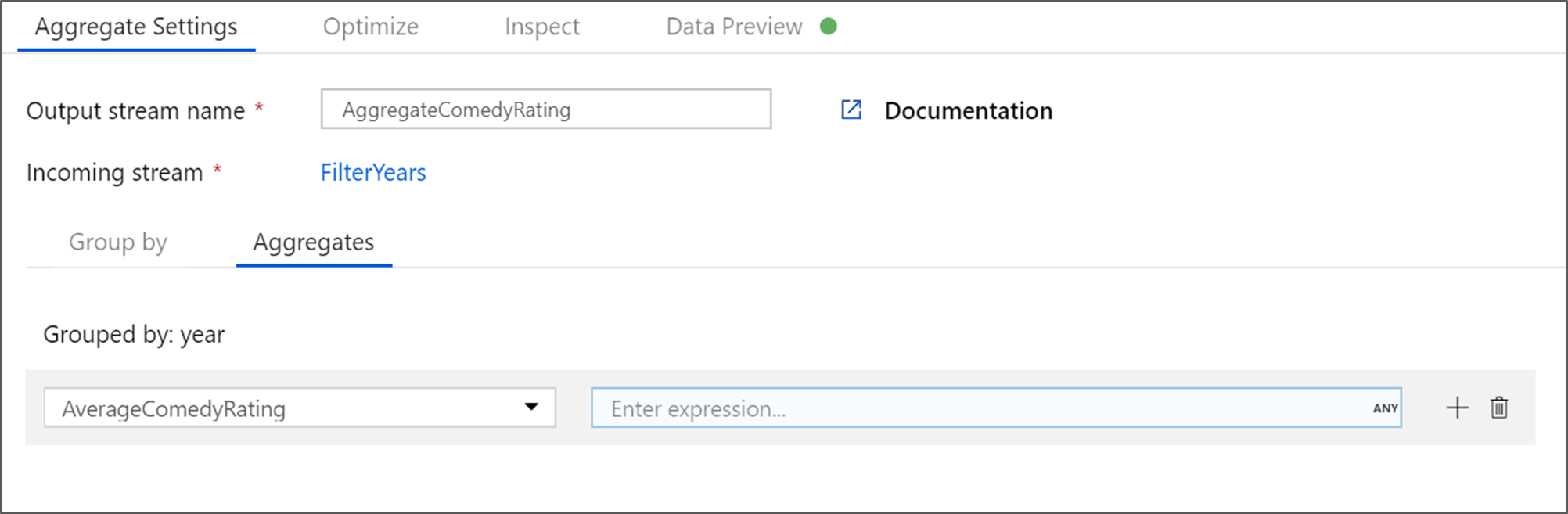
列 [Rating] の平均値を取得するには、
avg()集計関数を使用します。 Rating は文字列で、avg()で受け入れられるのは数値入力なので、toInteger()関数を使用して値を数値に変換する必要があります。 式は次のようになります。avg(toInteger(Rating))完了したら、 [Save and Finish](保存して終了する) をクリックします。

変換出力を表示するには、 [Data Preview](データのプレビュー) タブに移動します。 year と AverageComedyRating の 2 つの列だけがあることに注目してください。
次に、 [Destination](変換先) の下で [シンク] 変換を追加します。
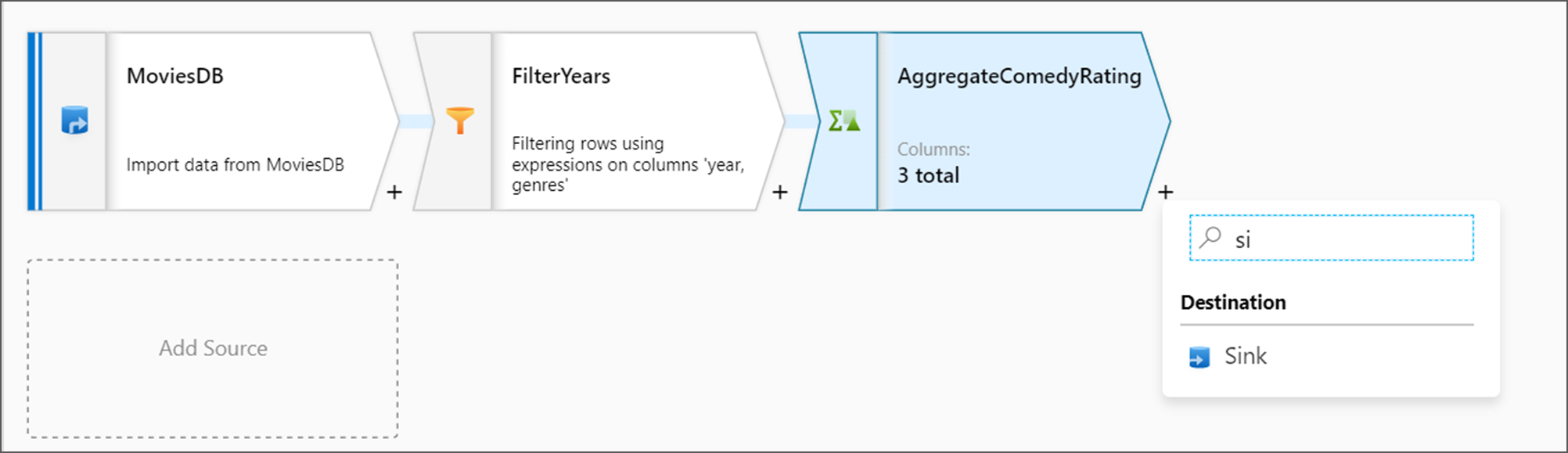
シンクに Sink という名前を付けます。 [新規] をクリックして、シンク データセットを作成します。
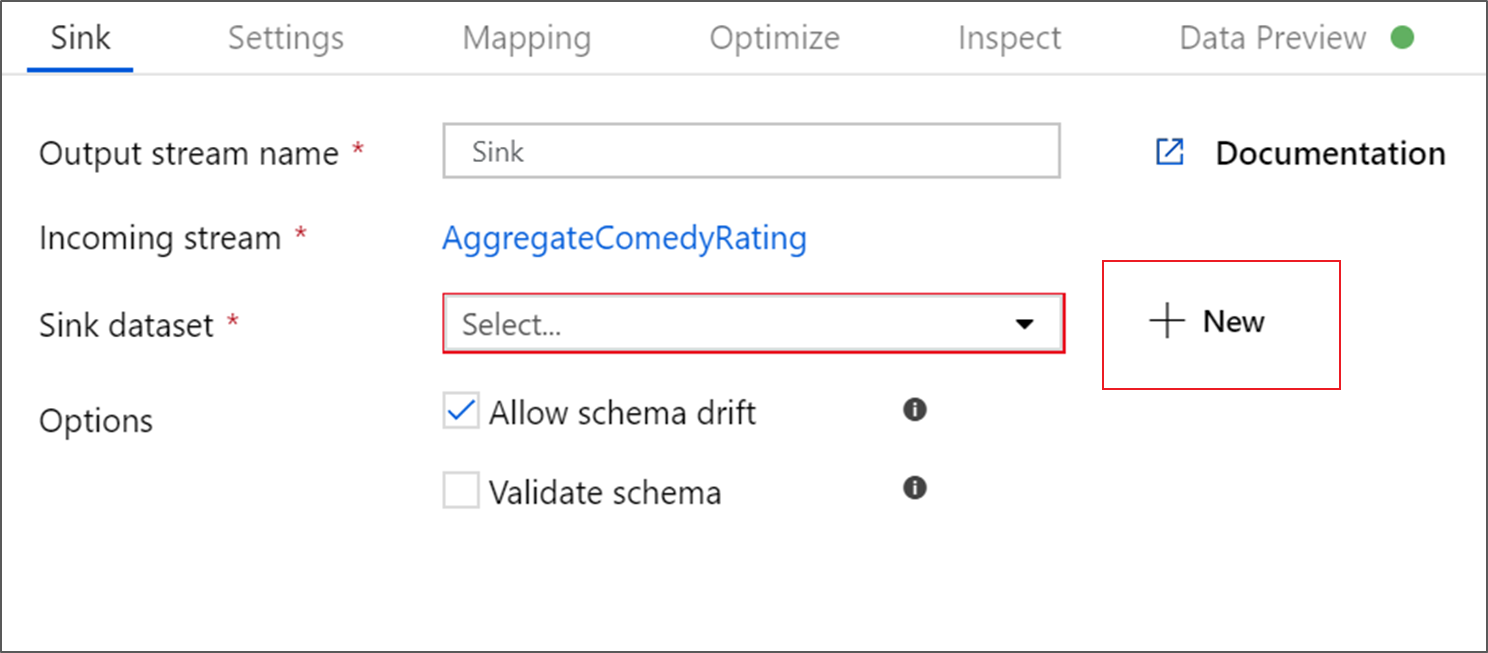
[Azure Data Lake Storage Gen2] を選択します。 [続行] をクリックして続行します。
[DelimitedText] を選択します。 [続行] をクリックして続行します。
シンク データセットに MoviesSink という名前を付けます。 リンクされたサービスの場合、手順 6 で作成した ADLS gen2 のリンクされたサービスを選択します。 データの書き込み先となる出力フォルダーを入力します。 このチュートリアルでは、コンテナー 'sample-data' 内のフォルダー ' output ' に書き込んでいます。 フォルダーは、事前に存在している必要はなく、動的に作成することができます。 [First row as header](最初の行をヘッダーにする) をオンに設定し、 [スキーマのインポート] で [なし] を選択します。 [完了] をクリックします。
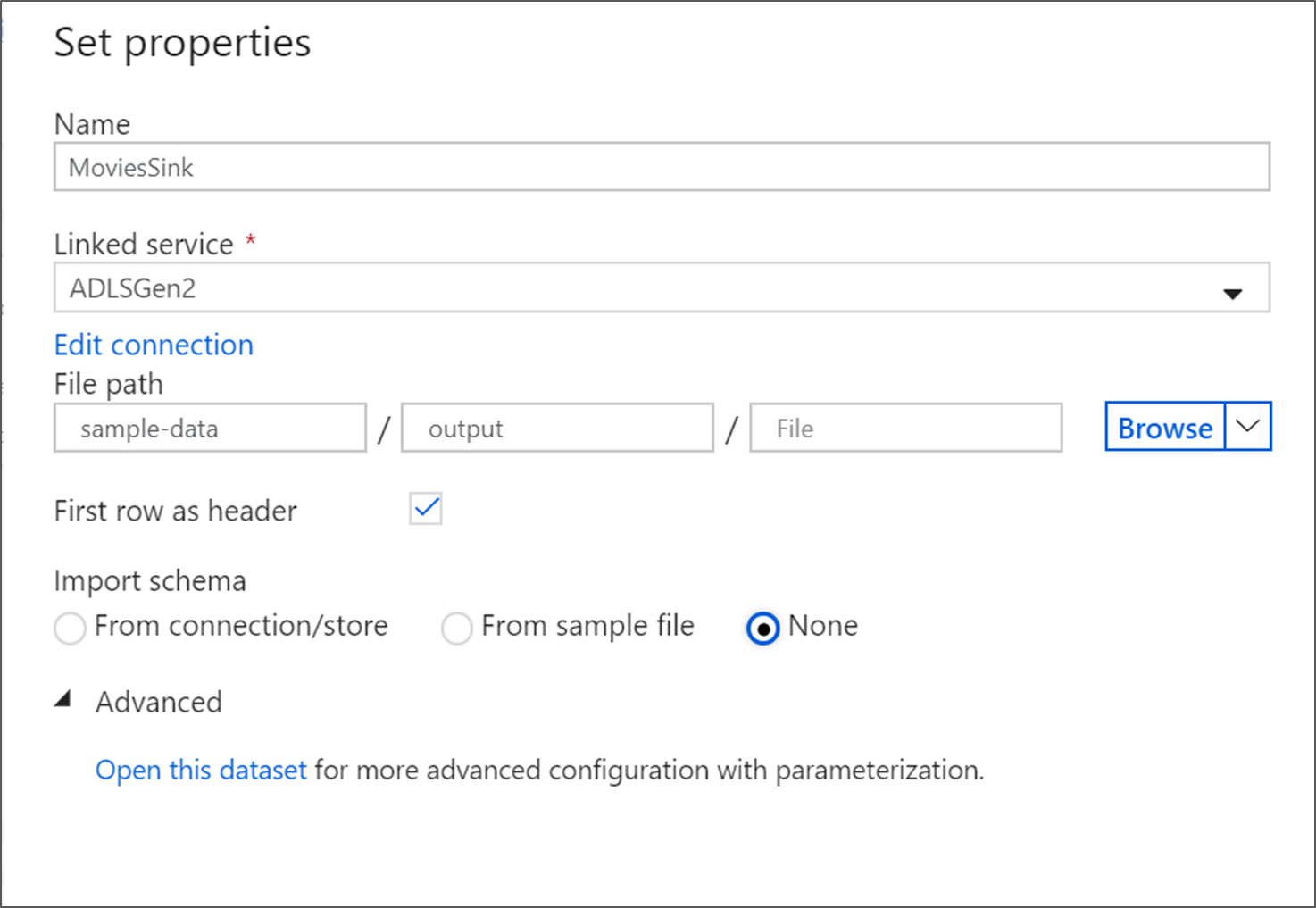
これで、データ フローの構築が完了しました。 これをパイプラインで実行する準備ができました。
Data Flow を実行して監視する
パイプラインを発行する前にデバッグすることができます。 この手順では、データ フロー パイプラインのデバッグ実行をトリガーします。 データのプレビューではデータが書き込まれませんが、デバッグ実行によってシンクの変換先にデータが書き込まれます。
パイプライン キャンバスに移動します。 [デバッグ] をクリックして、デバッグ実行をトリガーします。
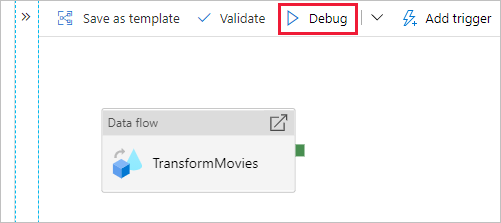
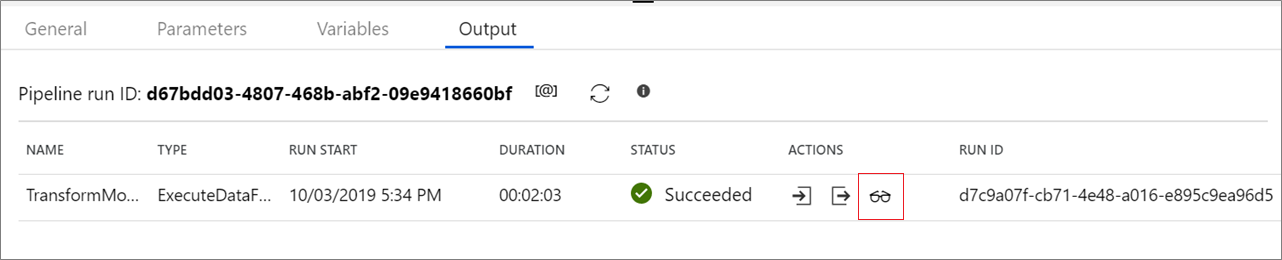
Data Flow アクティビティのパイプライン デバッグでは、アクティブなデバッグ クラスターが使用されますが、それでも初期化には少なくとも 1 分かかります。 進行状況は [出力] タブで追跡することができます。実行が正常に完了したら、眼鏡のアイコンをクリックして [監視] ウィンドウを開きます。
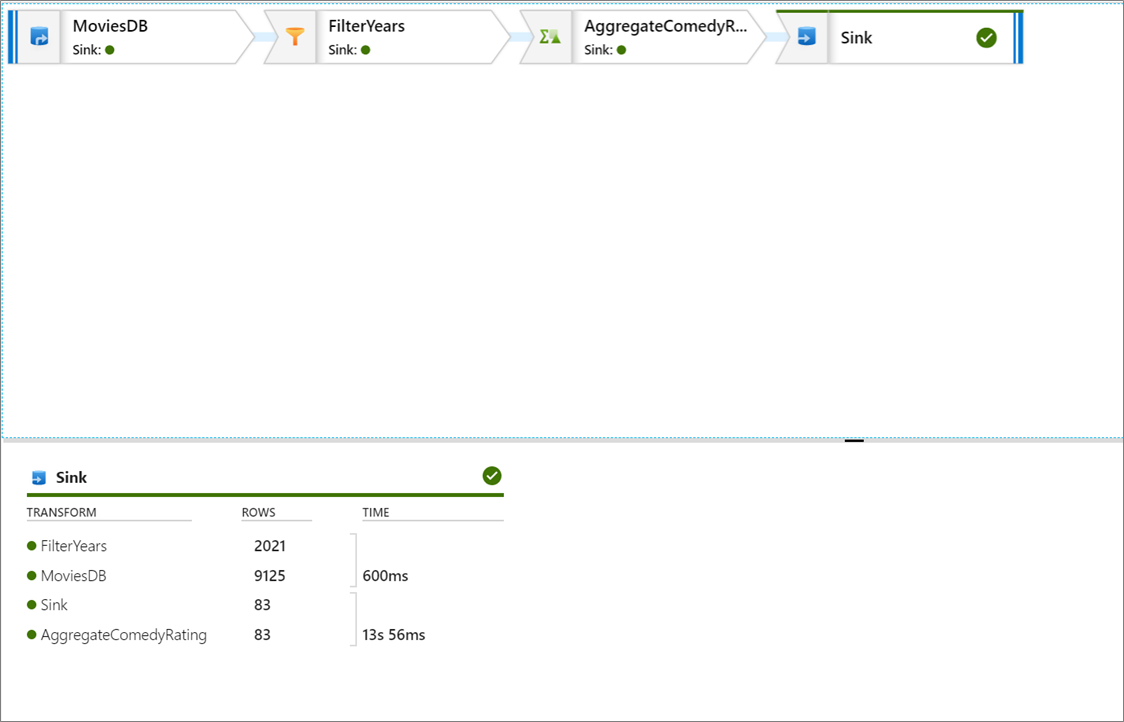
[監視] ウィンドウには、各変換手順で使用した行数と所要時間が表示されます。
変換をクリックすると、データの列とパーティション分割に関する詳細情報が表示されます。
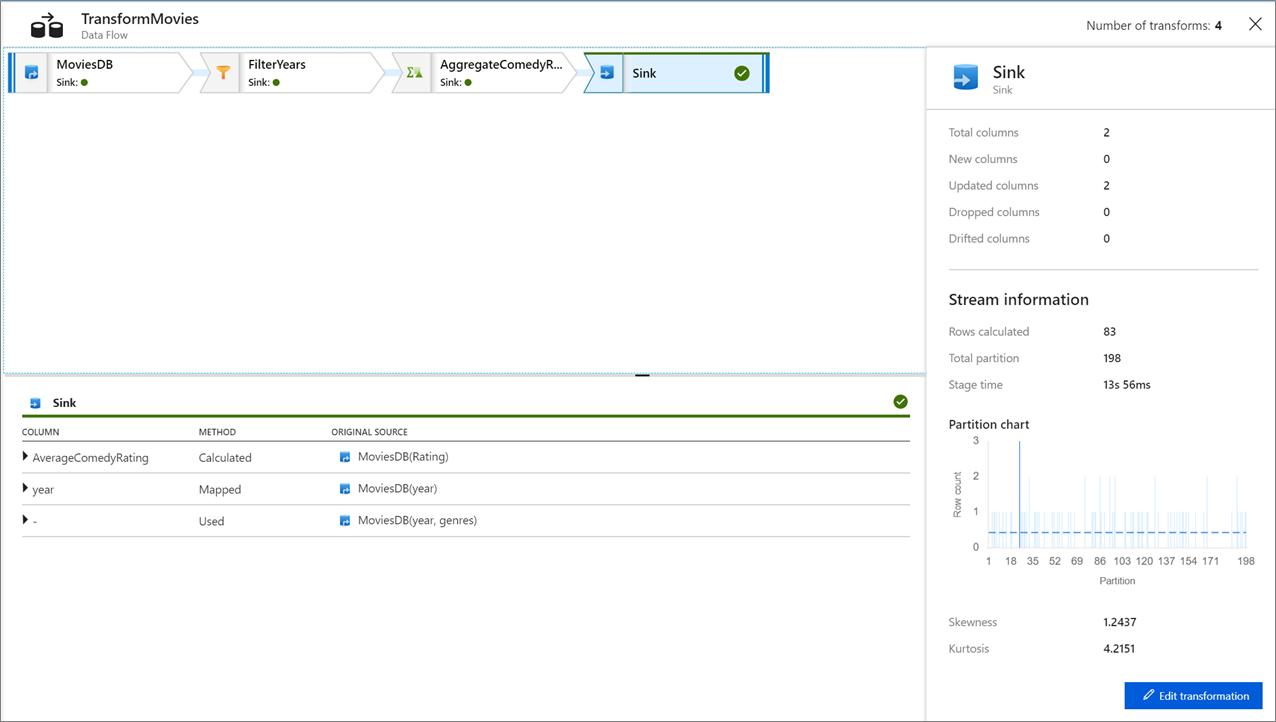
このチュートリアルに正しく従った場合は、シンク フォルダーに 83 行と 2 列が書き込まれているはずです。 BLOB ストレージをチェックすることで、データが正しいことを確認できます。
関連するコンテンツ
このチュートリアルのパイプラインでは、1910 年から 2000 年のコメディの平均評価を集計し、そのデータを ADLS に書き込むデータ フローを実行します。 以下の方法を学習しました。
- データ ファクトリを作成します。
- Data Flow アクティビティを含むパイプラインを作成します。
- 4 つの変換を使用して、マッピング データ フローを構築します。
- パイプラインをテスト実行します。
- Data Flow アクティビティを監視します。
データ フローの式言語の詳細を確認します。