マッピング データ フローの和集合変換
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
データ フローは、Azure Data Factory および Azure Synapse Pipelines の両方で使用できます。 この記事は、マッピング データ フローに適用されます。 変換を初めて使用する場合は、概要の記事「マッピング データ フローを使用してデータを変換する」を参照してください。
和集合では、複数のデータ ストリームの SQL Union を和集合変換からの新しい出力として使用し、これらのストリームを 1 つに結合します。 各入力ストリームのすべてのスキーマは、結合キーを必要とすることなく、データ フロー内で結合されます。
構成された各行の横の「+」アイコンを選択することにより、データ フロー内の既存の変換からのストリームとソース データの両方を含む、設定テーブルの n 個のストリームを結合できます。
以下は、マッピング データ フローにおける和集合変換の短いビデオ チュートリアルです。
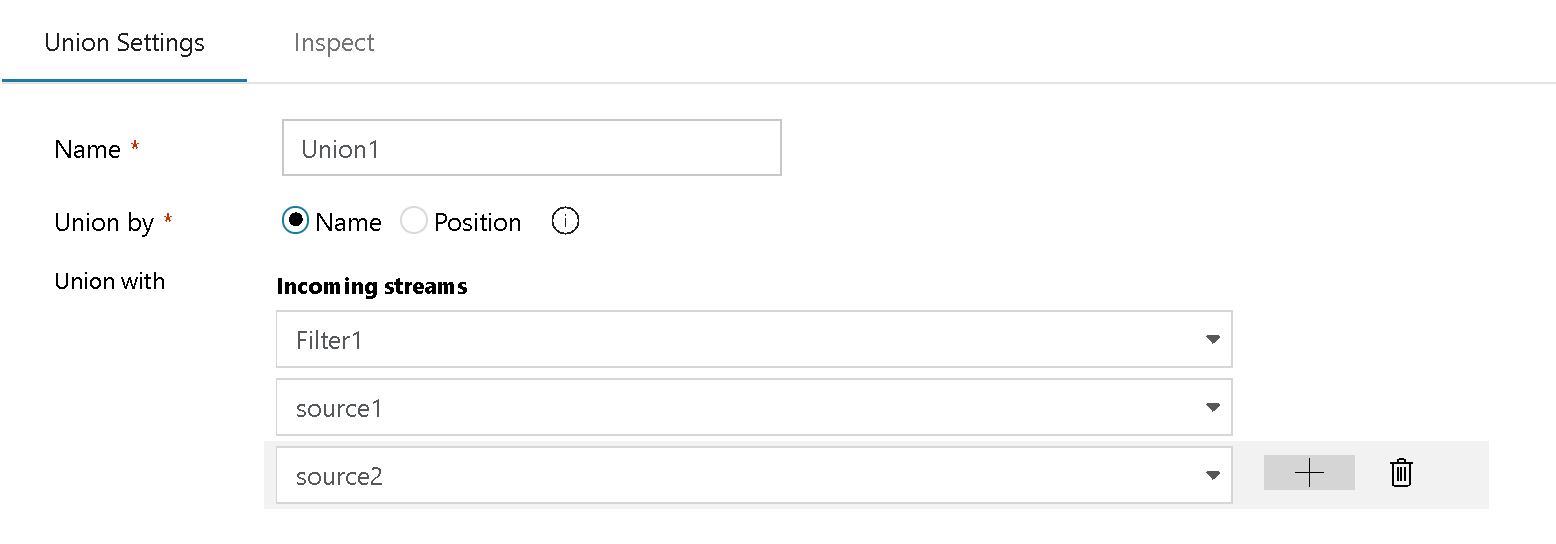
ここでは、複数のソース (この例では、3 つの異なるソース ファイル) の異種のメタデータを結合して、1 つのストリームにまとめることができます。

これを行うには、追加するすべてのソースを含めて、[Union Settings]\(和集合設定\) で行を追加します。 共通の参照や結合キーは必要ありません。
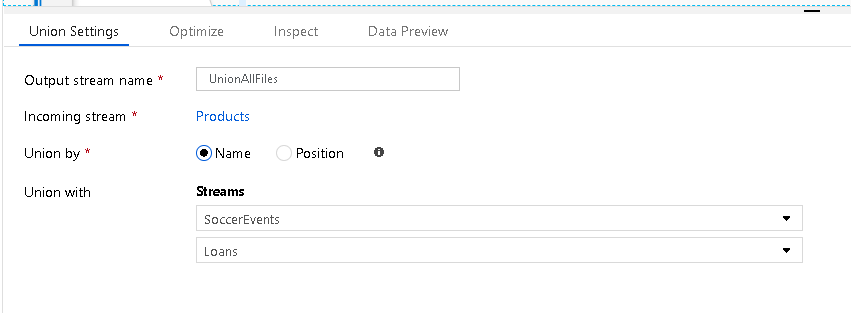
[Select transformation after your Union]\(和集合の後に変換を選択\) を設定すると、重複するフィールド、またはヘッダーのないソースからの名前のないフィールドを名前変更できます。 次の例では、[検査] をクリックして、 3 つの異なるソースからの合計 132 個の列を含む結合されたメタデータを表示します。

名前と位置
"名前による和集合" を選択すると、各列の値は、新しい連結メタデータ スキーマで各ソースの対応する列にドロップされます。
"位置による和集合" を選択すると、各列の値は対応するそれぞれのソースの元の位置にドロップされ、以下に示すように、各ソースのデータが同じストリームに追加されたデータの新しい結合ストリームが生成されます。