Azure portal を使用して、SQL Server にある複数のテーブルから Azure SQL Database のデータベースにデータを増分読み込みする
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
このチュートリアルでは、SQL Server データベース内の複数のテーブルから Azure SQL Database 内のデータベースに差分データを読み込むパイプラインを持つ Azure Data Factory を作成します。
このチュートリアルでは、以下の手順を実行します。
- ソース データ ストアとターゲット データ ストアを準備します。
- データ ファクトリを作成します。
- セルフホステッド統合ランタイムを作成します。
- 統合ランタイムをインストールします。
- リンクされたサービスを作成します。
- ソース データセット、シンク データセット、および基準値データセットを作成します。
- パイプラインを作成、実行、監視します。
- 結果を確認します。
- ソース テーブルのデータを追加または更新します。
- パイプラインを再実行して監視します。
- 最終結果を確認します。
概要
このソリューションを作成するための重要な手順を次に示します。
基準値列を選択する。
ソース データ ストアのテーブルごとに、いずれか 1 つの列を選択します。この列は、実行ごとに新しいレコードまたは更新されたレコードを特定する目的で使用されます。 通常、行が作成または更新されたときに常にデータが増える列を選択します (last_modify_time、ID など)。 この列の最大値が基準値として使用されます。
基準値を格納するためのデータ ストアを準備する。
このチュートリアルでは、SQL データベースに基準値を格納します。
次のアクティビティを含んだパイプラインを作成する。
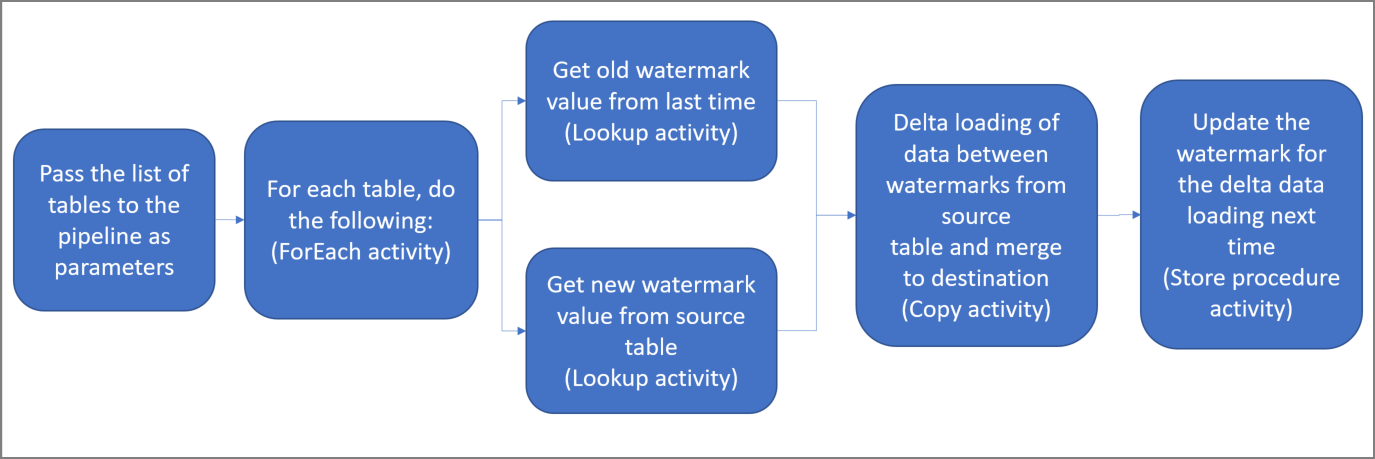
a. パイプラインにパラメーターとして渡された一連のソース テーブル名を反復処理する ForEach アクティビティを作成する。 このアクティビティが、ソース テーブルごとに次のアクティビティを呼び出して各テーブルの差分読み込みを実行します。
b. 2 つのルックアップ アクティビティを作成する。 1 つ目のルックアップ アクティビティは、前回の基準値を取得するために使用します。 2 つ目のルックアップ アクティビティは、新しい基準値を取得するために使用します。 これらの基準値は、コピー アクティビティに渡されます。
c. コピー アクティビティを作成する。これは基準値列の値がかつての基準値より大きく、かつ新しい基準値よりも小さい行をソース データ ストアからコピーするアクティビティです。 その差分データが、ソース データ ストアから新しいファイルとして Azure BLOB ストレージにコピーされます。
d. ストアド プロシージャ― アクティビティを作成する。これはパイプラインの次回実行に備えて基準値を更新するためのアクティビティです。
ソリューションの概略図を次に示します。
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
前提条件
- SQL Server。 このチュートリアルでは、SQL Server データベースをソース データ ストアとして使用します。
- Azure SQL データベース。 シンク データ ストアとして Azure SQL Database のデータベースを使用します。 SQL Database のデータベースがない場合の作成手順については、Azure SQL Database のデータベースの作成に関するページを参照してください。
SQL Server データベースにソース テーブルを作成する
SQL Server Management Studio を開き、SQL Server データベースに接続します。
サーバー エクスプローラーで目的のデータベースを右クリックし、 [新しいクエリ] を選択します。
データベースに対して次の SQL コマンドを実行し、
customer_tableおよびproject_tableという名前のテーブルを作成します。create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
データベースにターゲット テーブルを作成する
SQL Server Management Studio を開き、Azure SQL Database のデータベースに接続します。
サーバー エクスプローラーで目的のデータベースを右クリックし、 [新しいクエリ] を選択します。
データベースに対して次の SQL コマンドを実行し、
customer_tableおよびproject_tableという名前のテーブルを作成します。create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
高基準値の格納用としてもう 1 つテーブルをデータベースに作成する
データベースに対して次の SQL コマンドを実行し、基準値の格納先として
watermarktableという名前のテーブルを作成します。create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );両方のソース テーブルの初期基準値を基準値テーブルに挿入します。
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
データベースにストアド プロシージャを作成する
次のコマンドを実行して、データベースにストアド プロシージャを作成します。 パイプラインの実行後は都度、このストアド プロシージャによって基準値が更新されます。
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
データベースにデータ型と新たなストアド プロシージャを作成する
次のクエリを実行して、2 つのストアド プロシージャと 2 つのデータ型をデータベースに作成します。 それらは、ソース テーブルから宛先テーブルにデータをマージするために使用されます。
作業工程を簡単に始められるように、差分データをテーブル変数を介して渡すこのようなストアド プロシージャを直接使用し、それらを宛先ストアにマージします。 テーブル変数には、"多数" の差分行 (100 を超える行) が格納されることが想定されていない点に注意してください。
多数の差分行を宛先ストアにマージする必要がある場合は、まずコピー アクティビティを使用してすべての差分データを宛先ストアの一時的な "ステージング" テーブルにコピーしてから、テーブル変数を使用せずに独自のストアド プロシージャを構築し、"ステージング" テーブルから "最終的な" テーブルにマージすることをお勧めします。
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
Data Factory の作成
Web ブラウザー (Microsoft Edge または Google Chrome) を起動します。 現在、Data Factory の UI がサポートされる Web ブラウザーは Microsoft Edge と Google Chrome だけです。
左側のメニューで、 [リソースの作成]>[統合]>[Data Factory] を選択します。
[新しいデータ ファクトリ] ページで、 [名前] に「ADFMultiIncCopyTutorialDF」と入力します。
Azure Data Factory の名前は、グローバルに一意にする必要があります。 赤い感嘆符と次のエラーが表示される場合は、データ ファクトリの名前を変更して (yournameADFIncCopyTutorialDF など)、作成し直してください。 Data Factory アーティファクトの名前付け規則については、Data Factory の名前付け規則に関する記事を参照してください。
Data factory name "ADFIncCopyTutorialDF" is not availableデータ ファクトリを作成する Azure サブスクリプションを選択します。
[リソース グループ] について、次の手順のいずれかを行います。
- [Use existing (既存のものを使用)] を選択し、ドロップダウン リストから既存のリソース グループを選択します。
- [新規作成] を選択し、リソース グループの名前を入力します。
リソース グループの詳細については、 リソース グループを使用した Azure のリソースの管理に関するページを参照してください。
バージョンとして [V2] を選択します。
データ ファクトリの 場所 を選択します。 サポートされている場所のみがドロップダウン リストに表示されます。 データ ファクトリで使用するデータ ストア (Azure Storage、Azure SQL Database など) やコンピューティング (HDInsight など) は他のリージョンに配置できます。
Create をクリックしてください。
作成が完了すると、図に示されているような [Data Factory] ページが表示されます。
[Open Azure Data Factory Studio](Azure Data Factory Studio を開く) タイルで [開く] を選択して、別のタブで Azure Data Factory ユーザー インターフェイス (UI) を起動します。
セルフホステッド統合ランタイムを作成する
プライベート ネットワーク (オンプレミス) のデータ ストアから Azure データ ストアにデータを移動するときに、セルフホステッド統合ランタイム (IR) をオンプレミス環境にインストールします。 セルフホステッド IR を使用すると、プライベート ネットワークと Azure との間でデータを移動できます。
Azure Data Factory UI のホーム ページの一番左にあるウィンドウで [管理] タブを選択します。
左ペインの [統合ランタイム] を選択し、 [+ 新規] を選択します。
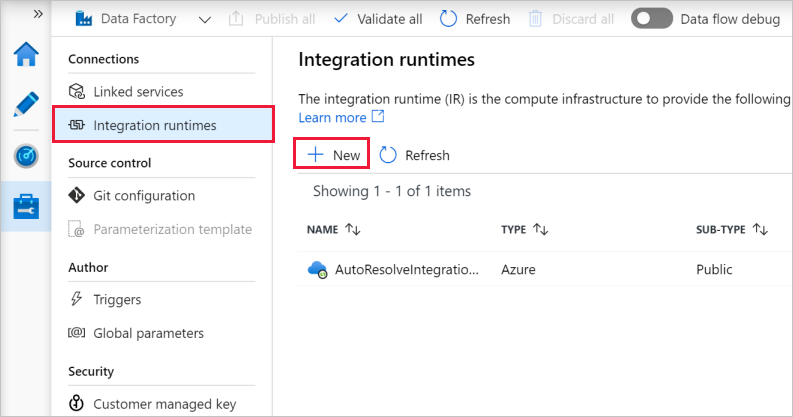
[Integration Runtime Setup](統合ランタイムの設定) ウィンドウで、 [Perform data movement and dispatch activities to external computes](データの移動を実行し、アクティビティを外部コンピューティングにディスパッチする) を選択し、 [続行] をクリックします。
[Self-Hosted](セルフホスト) を選択し、 [続行] をクリックします。
[名前] に「MySelfHostedIR」と入力し、 [作成] をクリックします。
[Option 1: Express setup](オプション 1: 高速セットアップ) セクションの [Click here to launch the express setup for this computer](このコンピューターで高速セットアップを起動するにはここをクリック) をクリックします。
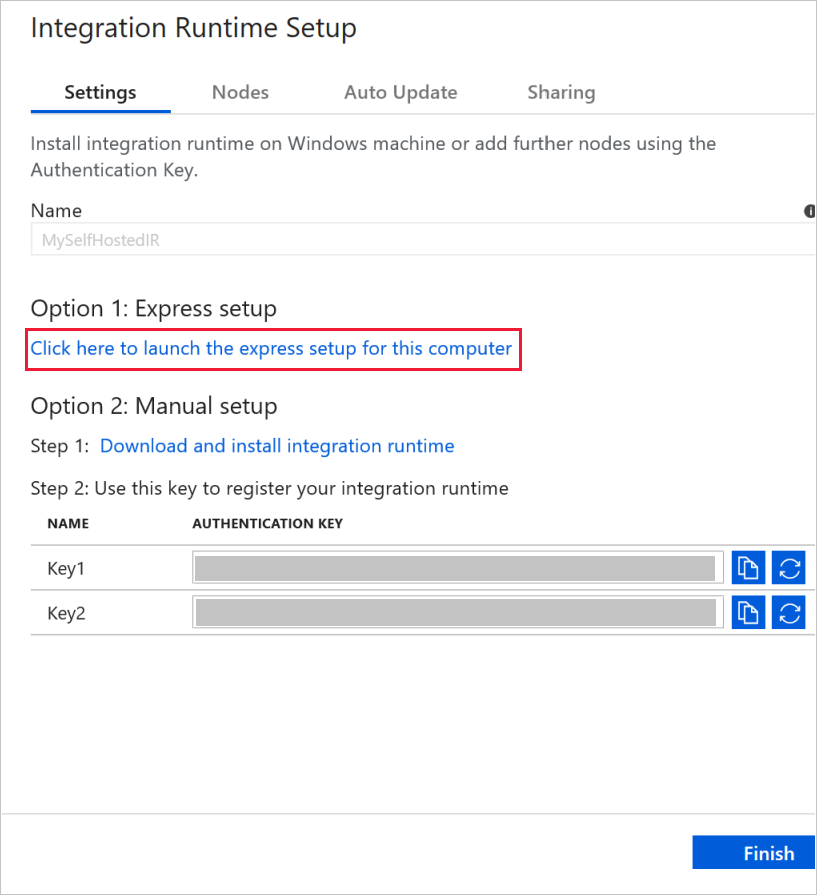
[Integration Runtime (セルフホステッド) 高速セットアップ] ウィンドウで、 [閉じる] をクリックします。
Web ブラウザーの [Integration Runtime Setup](統合ランタイムのセットアップ) ウィンドウで、 [完了] をクリックします。
統合ランタイムの一覧に MySelfHostedIR が含まれていることを確認します。
リンクされたサービスを作成します
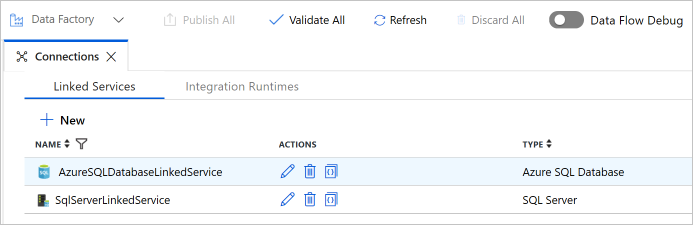
データ ストアおよびコンピューティング サービスをデータ ファクトリにリンクするには、リンクされたサービスをデータ ファクトリに作成します。 このセクションでは、SQL Server データベースと、Azure SQL Database のデータベースに対するリンクされたサービスを作成します。
SQL Server のリンクされたサービスを作成する
この手順では、SQL Server データベースをデータ ファクトリにリンクします。
[接続] ウィンドウで、 [Integration Runtimes](統合ランタイム) タブから [リンクされたサービス] タブに切り替え、 [+ 新規] をクリックします。
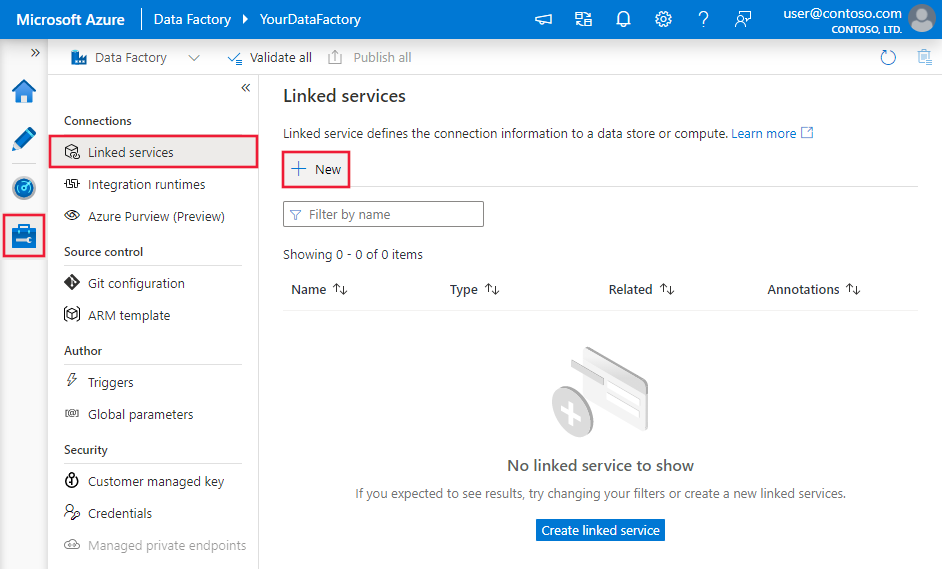
[New Linked Service](新しいリンクされたサービス) ウィンドウで [SQL Server] を選択し、 [続行] をクリックします。
[New Linked Service](新しいリンクされたサービス) ウィンドウで、次の手順を行います。
- [名前] に「SqlServerLinkedService」と入力します。
- [Connect via integration runtime](統合ランタイム経由で接続) で [MySelfHostedIR] を選択します。 これは重要な手順です。 既定の統合ランタイムでは、オンプレミスのデータ ストアに接続できません。 そこで、前に作成したセルフホステッド統合ランタイムを使用します。
- [サーバー名] に、SQL Server データベースを保持するサーバーの名前を入力します。
- [データベース名] に、SQL Server にソース データを含むデータベースの名前を入力します。 テーブルを作成してこのデータベースにデータを挿入する作業は、既に前提条件の一部として行っています。
- [認証の種類] で、データベースへの接続に使用する認証の種類を選択します。
- [ユーザー名] に、SQL Server データベースにアクセスできるユーザーの名前を入力します。 ユーザー アカウントまたはサーバー名にスラッシュ文字 (
\) を使用する必要がある場合は、エスケープ文字 (\) を使用します。 たとえばmydomain\\myuserです。 - [パスワード] に、ユーザーのパスワードを入力します。
- Data Factory が SQL Server データベースに接続できるかどうかをテストするために、 [Test connection](テスト接続) をクリックします。 エラーがあれば修正して、正常に接続できるようにします。
- リンクされたサービスを保存するために、 [完了] をクリックします。
Azure SQL Database のリンクされたサービスを作成する
最後の手順では、ソース SQL Server データベースをデータ ファクトリに接続するためのリンクされたサービスを作成します。 この手順では、ターゲット/シンク データベースをデータ ファクトリにリンクします。
[接続] ウィンドウで、 [Integration Runtimes](統合ランタイム) タブから [リンクされたサービス] タブに切り替え、 [+ 新規] をクリックします。
[New Linked Service](新しいリンクされたサービス) ウィンドウで [Azure SQL Database] を選択し、 [続行] をクリックします。
[New Linked Service](新しいリンクされたサービス) ウィンドウで、次の手順を行います。
- [名前] に「AzureSqlDatabaseLinkedService」と入力します。
- [サーバー名] で、ドロップダウン リストからサーバーの名前を選択します。
- [データベース名] で、前提条件の一部として customer_table と project_table を作成したデータベースを選択します。
- [ユーザー名] に、データベースにアクセスするユーザーの名前を入力します。
- [パスワード] に、ユーザーのパスワードを入力します。
- Data Factory が SQL Server データベースに接続できるかどうかをテストするために、 [Test connection](テスト接続) をクリックします。 エラーがあれば修正して、正常に接続できるようにします。
- リンクされたサービスを保存するために、 [完了] をクリックします。
2 つのリンクされたサービスが一覧に表示されていることを確認します。
データセットを作成する
この手順では、データ ソース、データの宛先、および基準値の格納場所を表すデータセットを作成します。
ソース データセットを作成する
左ウィンドウで [+] (プラス記号) をクリックし、 [データセット] をクリックします。
[新しいデータセット] ウィンドウで、 [SQL Server] を選択し、 [続行] をクリックします。
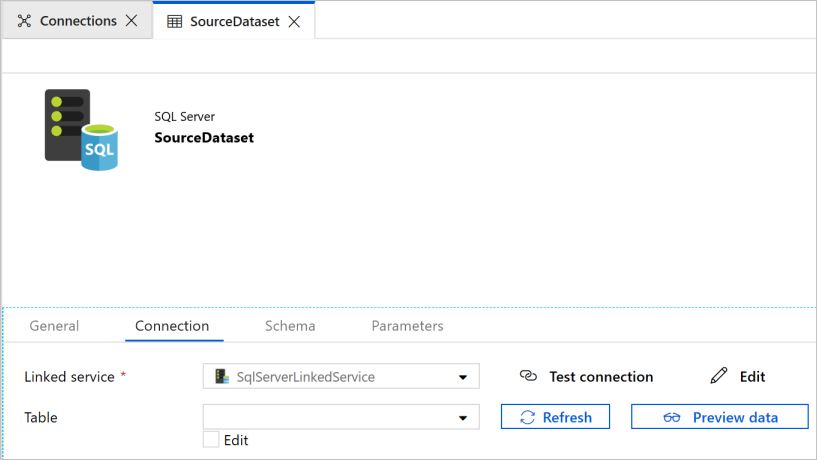
データセットを設定するために、Web ブラウザーで新しいタブが開かれます。 さらに、ツリー ビューにデータセットが表示されます。 下部にあるプロパティ ウィンドウの [全般] タブで、 [名前] に「SourceDataset」と入力します。
プロパティ ウィンドウの [接続] タブに切り替えて、 [リンクされたサービス] で [SqlServerLinkedService] を選択します。 ここではテーブルを選択しません。 このパイプライン内のコピー アクティビティは、テーブル全体を読み込むことはせずに、SQL クエリを使用してデータを読み込みます。
シンク データセットを作成する
左ウィンドウで [+] (プラス記号) をクリックし、 [データセット] をクリックします。
[新しいデータセット] ウィンドウで [Azure SQL Database] を選択し、 [続行] をクリックします。
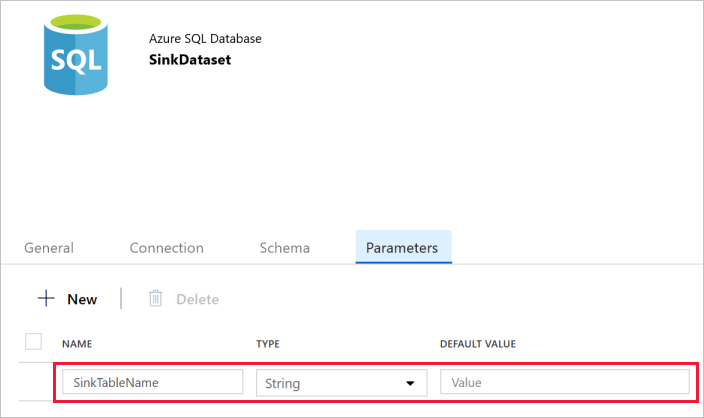
データセットを設定するために、Web ブラウザーで新しいタブが開かれます。 さらに、ツリー ビューにデータセットが表示されます。 下部にあるプロパティ ウィンドウの [全般] タブで、 [名前] に「SinkDataset」と入力します。
プロパティ ウィンドウの [ソース] タブに切り替え、以下の手順を実行します。
[Create/update parameters](パラメーターの作成/更新) セクションで、 [新規] をクリックします。
[名前] に「SinkTableName」と入力し、 [type](型) として [文字列] を指定します。 このデータセットは、SinkTableName をパラメーターとして受け取ります。 SinkTableName パラメーターは、実行時にパイプラインによって動的に設定されます。 パイプライン内の ForEach アクティビティは、一連のテーブル名を反復処理しながら、各イテレーションの中でこのデータセットにテーブル名を渡します。
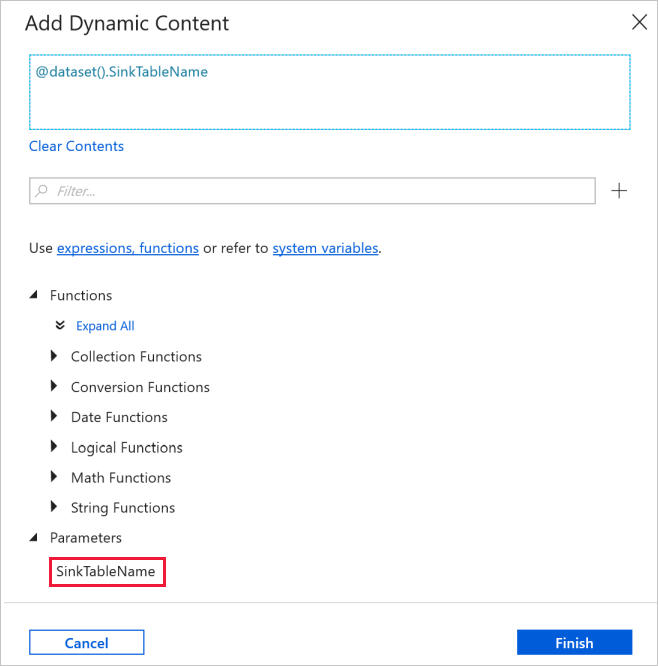
プロパティ ウィンドウの [接続] タブに切り替えて、 [リンクされたサービス] で [AzureSqlDatabaseLinkedService] を選択します。 [テーブル] プロパティで、 [動的なコンテンツの追加] をクリックします。
[動的なコンテンツの追加] ウィンドウの [パラメーター] セクションで [SinkTableName] を選択します。
[完了] をクリックすると、テーブル名として "@dataset().SinkTableName" が表示されます。
基準値用のデータセットを作成する
この手順では、高基準値を格納するためのデータセットを作成します。
左ウィンドウで [+] (プラス記号) をクリックし、 [データセット] をクリックします。
[新しいデータセット] ウィンドウで [Azure SQL Database] を選択し、 [続行] をクリックします。
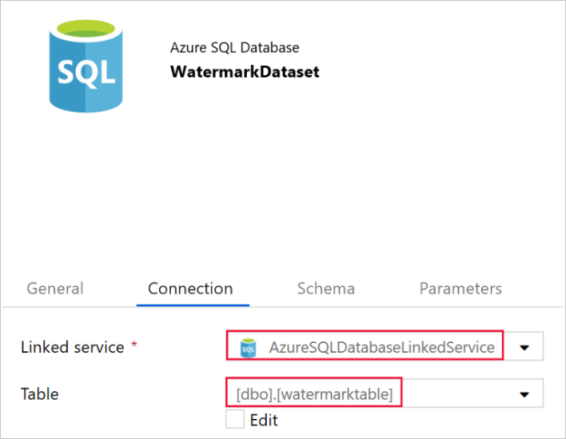
下部にあるプロパティ ウィンドウの [全般] タブで、 [名前] に「WatermarkDataset」と入力します。
[接続] タブに切り替えて、次の手順を実行します。
[リンクされたサービス] で [AzureSqlDatabaseLinkedService] を選択します。
[テーブル] で [dbo].[watermarktable] を選択します。
パイプラインを作成する
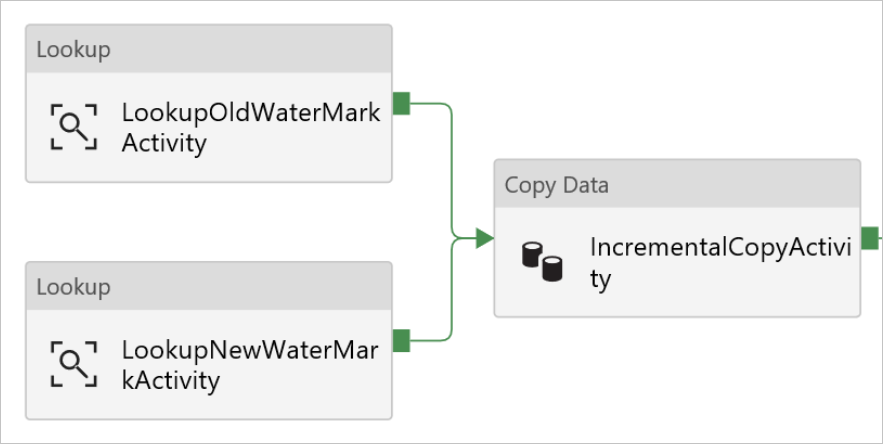
このパイプラインは、一連のテーブル名をパラメーターとして受け取ります。 ForEach アクティビティは、一連のテーブル名を反復処理しながら、次の操作を実行します。
ルックアップ アクティビティを使用して古い基準値 (初期値または前回のイテレーションで使用された値) を取得します。
ルックアップ アクティビティを使用して新しい基準値 (ソース テーブルの基準値列の最大値) を取得します。
コピー アクティビティを使用して、この 2 つの基準値の間に存在するデータをソース データベースからターゲット データベースにコピーします。
ストアド プロシージャ アクティビティを使用して古い基準値を更新します。この値が、次のイテレーションの最初のステップで使用されます。
パイプラインを作成する
左ウィンドウで [+](プラス記号) をクリックし、 [パイプライン] をクリックします。
[全般] パネルの [プロパティ] で、 [名前] に「IncrementalCopyPipeline」を指定します。 次に、右上隅にある [プロパティ] アイコンをクリックしてパネルを折りたたみます。
[パラメーター] タブで、次の手順を実行します。
- [+ 新規] をクリックします。
- [名前] に、パラメーター名として「tableList」と入力します。
- パラメーターの [型] として [配列] を選択します。
[アクティビティ] ツール ボックスで [Iteration & Conditionals]\(繰り返しと条件\) を展開し、パイプライン デザイナー画面に [ForEach] アクティビティをドラッグ アンド ドロップします。 プロパティ ウィンドウの [全般] タブで、「IterateSQLTables」と入力します。
[設定] タブに切り替えて、 [項目] に「
@pipeline().parameters.tableList」と入力します。 ForEach アクティビティは、一連のテーブルを反復処理しながら、増分コピー操作を実行します。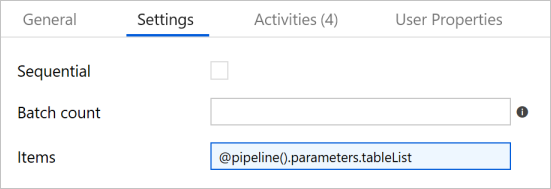
パイプラインの ForEach アクティビティが選択されていない場合はこれを選択します。 [編集] (鉛筆アイコン) ボタンをクリックします。
[アクティビティ] ツールボックスで [General](一般) を展開し、パイプライン デザイナー画面に [検索] アクティビティをドラッグ アンド ドロップし、 [名前] に「LookupOldWaterMarkActivity」を入力します。
プロパティ ウィンドウで [設定] タブに切り替え、以下の手順を実行します。
[Source Dataset](ソース データセット) で [WatermarkDataset] を選択します。
[クエリの使用] で [クエリ] を選択します。
[クエリ] に次の SQL クエリを入力します。
select * from watermarktable where TableName = '@{item().TABLE_NAME}'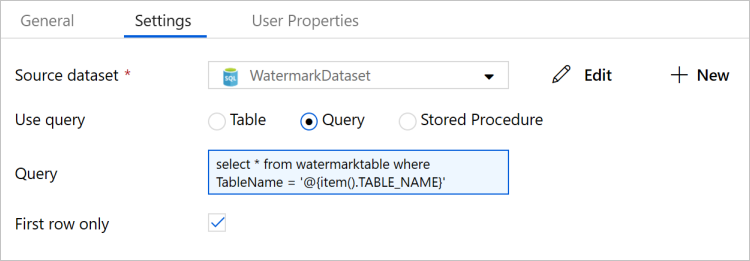
[アクティビティ] ツールボックスから検索アクティビティをドラッグアンドドロップし、 [名前] に「LookupNewWaterMarkActivity」と入力します。
[設定] タブに切り替えます。
[Source Dataset](ソース データセット) で [SourceDataset] を選択します。
[クエリの使用] で [クエリ] を選択します。
[クエリ] に次の SQL クエリを入力します。
select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}
[アクティビティ] ツールボックスからコピー アクティビティをドラッグアンドドロップし、 [名前] に「IncrementalCopyActivity」と入力します。
1 つずつ、検索アクティビティをコピー アクティビティに接続します。 接続するには、検索アクティビティの横の緑のボックスをドラッグしてコピー アクティビティにドロップします。 コピー アクティビティの境界線の色が青に変わったら、マウス ボタンを離します。
パイプラインのコピー アクティビティを選択します。 プロパティ ウィンドウで [ソース] タブに切り替えます。
[Source Dataset](ソース データセット) で [SourceDataset] を選択します。
[クエリの使用] で [クエリ] を選択します。
[クエリ] に次の SQL クエリを入力します。
select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'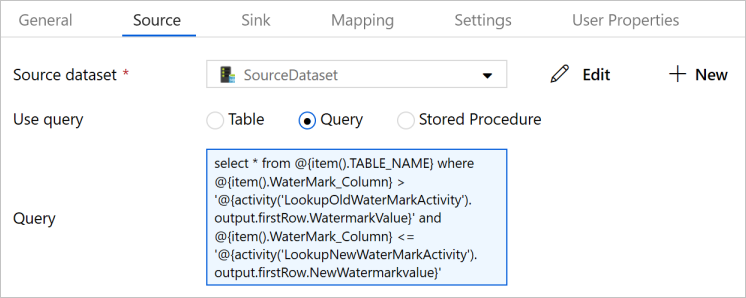
[シンク] タブに切り替えて、 [Sink Dataset](シンク データセット) で [SinkDataset] を選択します。
手順は次のとおりです。
[データセットのプロパティ] で、 [SinkTableName] パラメーターに「
@{item().TABLE_NAME}」と入力します。[ストアド プロシージャ名] プロパティに「
@{item().StoredProcedureNameForMergeOperation}」と入力します。[テーブルの種類] プロパティに「
@{item().TableType}」と入力します。[Table type parameter name](テーブルの種類のパラメーター名) に「
@{item().TABLE_NAME}」と入力します。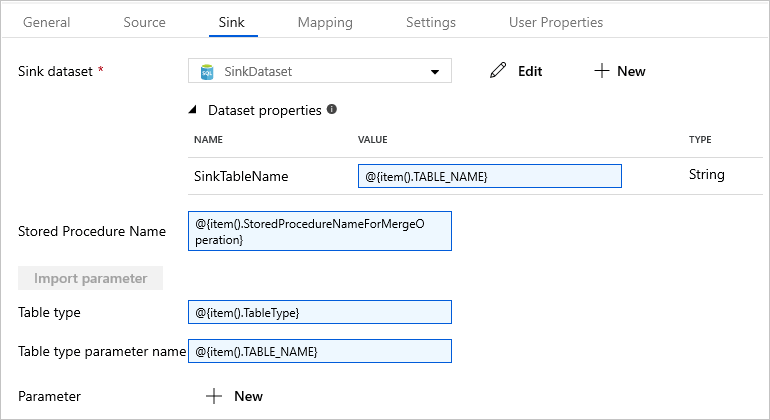
[アクティビティ] ツールボックスからパイプライン デザイナー画面に [ストアド プロシージャ] アクティビティをドラッグ アンド ドロップします。 コピー アクティビティをストアド プロシージャ アクティビティに接続します。
パイプラインの ストアド プロシージャ アクティビティを選択します。プロパティ ウィンドウの [全般] タブで、 [名前] に「StoredProceduretoWriteWatermarkActivity」と入力します。
[SQL アカウント] タブに切り替えて、 [リンクされたサービス] で [AzureSqlDatabaseLinkedService] を選択します。

[ストアド プロシージャ] タブに切り替えて、次の手順を実行します。
[ストアド プロシージャ名] に
[dbo].[usp_write_watermark]を選択します。[Import parameter](インポート パラメーター) を選択します。
各パラメーターの値を次のように指定します。
名前 Type 値 LastModifiedtime DateTime @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}TableName String @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}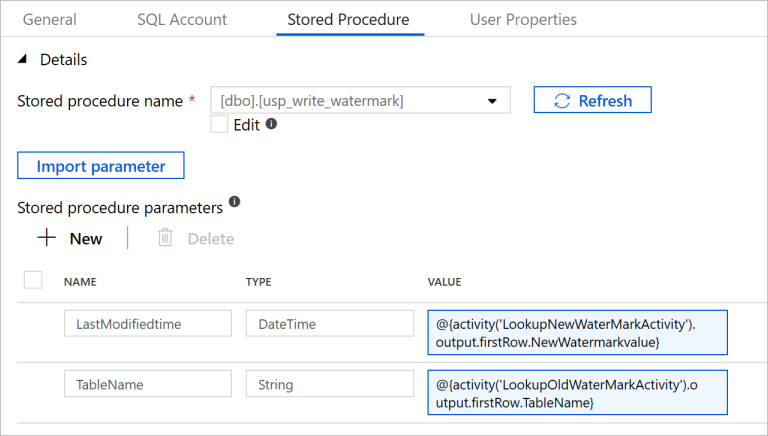
作成したエンティティを Data Factory サービスに発行するには、 [すべて発行] を選択します。
[正常に発行されました] というメッセージが表示されるまで待機します。 通知を表示するには、 [通知の表示] リンクをクリックします。 [X] をクリックして通知ウィンドウを閉じます。
パイプラインを実行する
パイプラインのツール バーの [トリガーの追加] をクリックし、 [Trigger Now](今すぐトリガー) をクリックします。
[Pipeline Run](パイプラインの実行) ウィンドウで、 [tableList] パラメーターに次の値を入力し、 [完了] をクリックします。
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]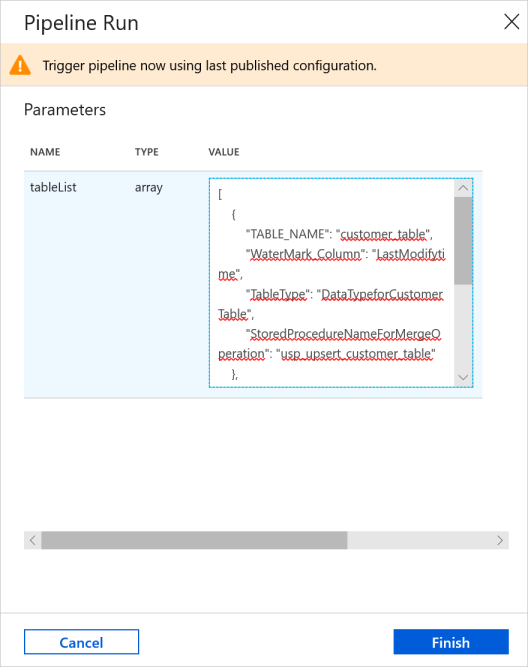
パイプラインの監視
左側で [監視] タブに切り替えます。 手動トリガーによってトリガーされたパイプラインの実行を確認できます。 [パイプライン名] 列のリンクを使用して、アクティビティの詳細を表示したりパイプラインを再実行したりできます。
パイプラインの実行に関連付けられているアクティビティの実行を表示するには、 [パイプライン名] 列のリンクを選択します。 アクティビティの実行の詳細を確認するには、 [ACTIVITY NAME](アクティビティ名) 列の [詳細] リンク (眼鏡アイコン) を選択します。
再度パイプラインの実行ビューに移動するには、一番上にある [すべてのパイプラインの実行] を選択します。 表示を更新するには、 [最新の情報に更新] を選択します。
結果の確認
SQL Server Management Studio からターゲット SQL データベースに対して次のクエリを実行し、ソース テーブルからターゲット テーブルにデータがコピーされていることを確かめます。
クエリ
select * from customer_table
出力
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
クエリ
select * from project_table
出力
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
クエリ
select * from watermarktable
出力
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
2 つのテーブルの基準値が更新されたことがわかります。
ソース テーブルにデータを追加する
コピー元の SQL Server データベースに次のクエリを実行して、customer_table 内の既存の行を更新します。 project_table に新しい行を挿入します。
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
パイプラインを再実行する
Web ブラウザー ウィンドウで、左側の [編集] タブに切り替えます。
パイプラインのツール バーの [トリガーの追加] をクリックし、 [Trigger Now](今すぐトリガー) をクリックします。
[Pipeline Run](パイプラインの実行) ウィンドウで、 [tableList] パラメーターに次の値を入力し、 [完了] をクリックします。
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]
パイプラインを再度監視する
左側で [監視] タブに切り替えます。 手動トリガーによってトリガーされたパイプラインの実行を確認できます。 [パイプライン名] 列のリンクを使用して、アクティビティの詳細を表示したりパイプラインを再実行したりできます。
パイプラインの実行に関連付けられているアクティビティの実行を表示するには、 [パイプライン名] 列のリンクを選択します。 アクティビティの実行の詳細を確認するには、 [ACTIVITY NAME](アクティビティ名) 列の [詳細] リンク (眼鏡アイコン) を選択します。
再度パイプラインの実行ビューに移動するには、一番上にある [すべてのパイプラインの実行] を選択します。 表示を更新するには、 [最新の情報に更新] を選択します。
最終結果を確認する
SQL Server Management Studio からターゲット SQL データベースに対して次のクエリを実行し、更新されたデータや新しいデータがソース テーブルからターゲット テーブルにコピーされていることを確かめます。
クエリ
select * from customer_table
出力
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
PersonID 3 を見ると、Name と LastModifytime が新しい値であることがわかります。
クエリ
select * from project_table
出力
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
project_table に NewProject というエントリが追加されていることがわかります。
クエリ
select * from watermarktable
出力
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
2 つのテーブルの基準値が更新されたことがわかります。
関連するコンテンツ
このチュートリアルでは、以下の手順を実行しました。
- ソース データ ストアとターゲット データ ストアを準備します。
- データ ファクトリを作成します。
- 自己ホスト型統合ランタイム (IR) を作成します。
- 統合ランタイムをインストールします。
- リンクされたサービスを作成します。
- ソース データセット、シンク データセット、および基準値データセットを作成します。
- パイプラインを作成、実行、監視します。
- 結果を確認します。
- ソース テーブルのデータを追加または更新します。
- パイプラインを再実行して監視します。
- 最終結果を確認します。
次のチュートリアルに進み、Azure 上の Spark クラスターを使ってデータを変換する方法について学習しましょう。