Linux ベースの HDInsight で Apache Hadoop YARN アプリケーション ログにアクセスする
Azure HDInsight の Apache Hadoop クラスターで Apache Hadoop YARN (Yet Another Resource Negotiator) アプリケーションのログにアクセスする方法について説明します。
Apache YARN とは
YARN はアプリケーションのスケジュール設定/監視からリソース管理を切り離すことで、複数のプログラミング モデル (Apache Hadoop MapReduce はそのうちの 1 つ) をサポートします。 YARN は、グローバル ResourceManager (RM)、ワーカー ノードごとの NodeManagers (NM)、およびアプリケーションごとの ApplicationMasters (AM) を使用します。 アプリケーションごとの AM は、アプリケーションを実行するためのリソース (CPU、メモリ、ディスク、ネットワーク) を RM と調整します。 RM は NM と連携して、これらのリソースに コンテナーとしての許可を付与します。 AM は、RM によって自身に割り当てられたコンテナーの進行状況を追跡します。 アプリケーションはその性質によって、多くのコンテナーを必要とする場合があります。
各アプリケーションが、複数の "アプリケーション試行" で構成されていることがあります。 アプリケーションが失敗した場合、新しい試行として再試行される場合があります。 各試行は、コンテナーで実行されます。 ある意味で、コンテナーは、YARN アプリケーションによって実行される基本的作業単位のコンテキストを提供します。 コンテナーのコンテキストで行われる作業はすべて、コンテナーが割り当てられた 1 つのワーカー ノードで実行されます。 「Hadoop:YARN アプリケーションの作成」または「Apache Hadoop YARN」を参照してください。
より多くの処理スループットをサポートするようにクラスターをスケーリングするには、自動スケールを使用するか、いくつかの異なる言語を使用してクラスターを手動でスケーリングします。
YARN タイムライン サーバー
Apache Hadoop YARN タイムライン サーバーは、完了したアプリケーションに関する一般的な情報を提供します
YARN タイムライン サーバーには、次の種類のデータが含まれています。
- アプリケーション ID (アプリケーションの一意の識別子)
- アプリケーションを開始したユーザー
- アプリケーションを完了するために実行された試みに関する情報
- 特定のアプリケーションの試行で使用されたコンテナー
YARN アプリケーションとログ
アプリケーションのログ (および関連するコンテナーのログ) は、問題のある Hadoop アプリケーションのデバッグに重要です。 YARN は、ログの集計を使用してアプリケーションのログを収集、集計、格納するための優れたフレームワークを提供します。
ログの集計機能により、アプリケーション ログへのアクセスがさらに確実になります。 この機能により、ワーカー ノード上のすべてのコンテナーのログが集計され、ワーカー ノードごとに 1 つの集計ログとして保存されます。 ログは、アプリケーションの完了後に既定のファイル システムに保存されます。 アプリケーションは数百または数千のコンテナーを使用することがありますが、1 つのワーカー ノードで実行されるすべてのコンテナーのログは常に 1 つのファイルに集計されます。 アプリケーションで使われるワーカー ノードごとに 1 つのログ ファイルが存在します。 ログの集計は、既定で HDInsight クラスター バージョン 3.0 以降で有効になります。 集計されたログは、クラスターの既定のストレージに配置されます。 次のパスは、ログへの HDFS パスです。
/app-logs/<user>/logs/<applicationId>
このパスで、user はアプリケーションを開始したユーザーの名前です。 applicationId は、YARN RM からアプリケーションに割り当てられた一意の識別子です。
集計されたログは、コンテナーによってインデックスが作成されるバイナリ形式の TFile で書かれているため、直接読み取ることはできません。 YARN ResourceManager ログまたは CLI ツールを使用して、対象のアプリケーションまたはコンテナーのログをプレーン テキストとして表示します。
ESP クラスターの Yarn ログ
Ambari のカスタム mapred-site に 2 つの構成を追加する必要があります。
Web ブラウザーから、
https://CLUSTERNAME.azurehdinsight.netに移動します。ここで、CLUSTERNAMEはクラスターの名前です。Ambari UI から [MapReduce2]>[Configs]>[Advanced]>[Custom mapred-site] に移動します。
次のプロパティのセットのいずれかを追加します。
セット 1
mapred.acls.enabled=true mapreduce.job.acl-view-job=*セット 2
mapreduce.job.acl-view-job=<user1>,<user2>,<user3>変更を保存し、影響を受けるすべてのサービスを再起動します。
YARN CLI ツール
ssh コマンドを使用してクラスターに接続します。 次のコマンドを編集して CLUSTERNAME をクラスターの名前に置き換えてから、そのコマンドを入力します。
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.net現在実行しているすべての Yarn アプリケーションのアプリケーション ID を、次のコマンドで一覧表示します。
yarn topログをダウンロードする
APPLICATIONID列のアプリケーション ID をメモしておきます。YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC Server次のいずれかのコマンドを実行することで、これらのログをプレーン テキストとして表示できます。
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>これらのコマンドの実行時には、<applicationId>、<user-who-started-the-application>、<containerId>、<worker-node-address> の情報を指定します。
その他のサンプル コマンド
すべてのアプリケーション マスターの Yarn コンテナー ログをダウンロードするには、次のコマンドを使います。 この手順では、テキスト形式で
amlogs.txtという名前のログ ファイルを作成します。yarn logs -applicationId <application_id> -am ALL > amlogs.txt最新のアプリケーション マスターだけの Yarn コンテナー ログをダウンロードするには、次のコマンドを使います。
yarn logs -applicationId <application_id> -am -1 > latestamlogs.txt最初の 2 つのアプリケーション マスターの Yarn コンテナー ログをダウンロードするには、次のコマンドを使います。
yarn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtすべての Yarn コンテナー ログをダウンロードするには、次のコマンドを使います。
yarn logs -applicationId <application_id> > logs.txt特定のコンテナーの Yarn コンテナー ログをダウンロードするには、次のコマンドを使います。
yarn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txt
YARN ResourceManager UI
YARN ResourceManager UI はクラスターのヘッド ノードで実行されます。 Ambari Web UI を使ってアクセスします。 YARN ログを表示するには、次の手順を使用します。
ご利用の Web ブラウザーで、
https://CLUSTERNAME.azurehdinsight.netに移動します。 CLUSTERNAME を、使用する HDInsight クラスターの名前に置き換えます。左側のサービスの一覧で、 [YARN] を選択します。
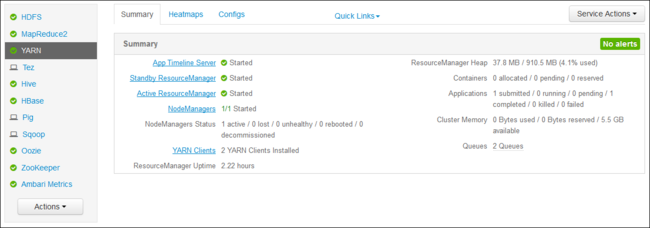
[クイック リンク] ドロップダウンから、いずれかのクラスター ヘッド ノードを選択してから、
ResourceManager Logを選択します。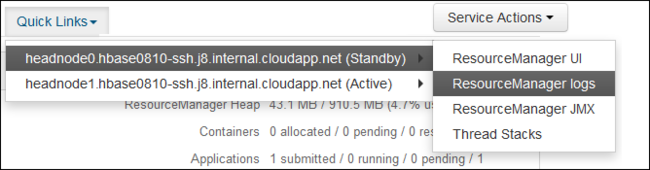
YARN のログへのリンクの一覧が表示されます。