HDInsight クラスターのログを管理する
HDInsight クラスターでは、さまざまなログ ファイルが生成されます。 たとえば、Apache Hadoop とそれに関連する Apache Spark などのサービスは、詳細なジョブ実行ログを生成します。 ログ ファイルの管理は、HDInsight クラスターを正常な状態に維持する作業の一部です。 ログのアーカイブに対しては規制の要件もあります。 ログ ファイルはサイズが大きくて数が多いため、ログのストレージとアーカイブを最適化すると、サービスのコスト管理に役立ちます。
HDInsight クラスターのログの管理には、クラスター環境のあらゆる側面に関する情報の保持が含まれます。 この情報には、関連するすべての Azure サービスのログ、クラスター構成、ジョブの実行に関する情報、エラーの状態、および必要に応じたその他のデータが含まれます。
HDInsight のログ管理の一般的な手順は次のとおりです。
- ステップ 1: ログのリテンション期間ポリシーを決定する
- ステップ 2: クラスター サービスのバージョンの構成ログを管理する
- ステップ 3: クラスターのジョブ実行のログ ファイルを管理する
- ステップ 4: ログ ボリュームのストレージ サイズとコストを予測する
- ステップ 5: ログのアーカイブ ポリシーとプロセスを決定する
ステップ 1: ログのリテンション期間ポリシーを決定する
HDInsight クラスターのログ管理戦略作成の最初のステップでは、ビジネス シナリオおよびジョブ実行履歴ストレージ要件に関する情報を収集します。
クラスターの詳細
ログ管理戦略での情報収集には、次のクラスターの詳細が役立ちます。 この情報は、特定の Azure アカウントで作成したすべての HDInsight クラスターから収集します。
- クラスター名
- クラスターのリージョンと Azure の可用性ゾーン
- クラスターの状態、最後の状態変化の詳細を含む
- マスター、コア、タスクの各ノードに指定されている HDInsight インスタンスの種類と数
この最上位レベルの情報のほとんどは、Azure Portal を使って取得できます。 代わりに、Azure CLI を使用して HDInsight クラスターに関する情報を取得することもできます。
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
また、PowerShell を使ってこの情報を表示できます。 詳細については、「Azure PowerShell を使用して HDInsight の Apache Hadoop クラスターを管理する」を参照してください。
クラスターで実行されているワークロードを理解する
種類ごとの適切なログ戦略を設計するには、HDInsight クラスターで実行されているワークロードの種類を理解しておくことが重要です。
- ワークロードは実験 (開発やテスト) ですか、運用品質ですか。
- 通常、運用品質のワークロードはどのくらいの頻度で実行されますか。
- ワークロードには、リソースの消費量が多いものや、実行時間の長いものが含まれますか。
- ワークロードには、複数の種類のログが生成される Hadoop サービスの複雑なセットを使うものがありますか。
- ワークロードには、規制実行系列要件が関連付けられているものがありますか。
ログ リテンション期間パターンの例と実践
各ログ エントリに識別子を追加するか、他の手法によって、データ系列の追跡を維持することを検討します。 これにより、データと操作の元のソースを追跡し、各ステージのデータをたどって整合性と有効性を把握できます。
1 つまたは複数のクラスターからログを収集する方法を検討し、監査、監視、計画、アラートなどの目的と照合します。 カスタム ソリューションを使用して、ログ ファイルに定期的にアクセスしてダウンロードすることや、それらのログ ファイルを結合および分析してダッシュボードに表示することができます。 また、セキュリティや障害検出の警告用に他の機能を追加することもできます。 PowerShell、HDInsight SDK、または Azure クラシック デプロイ モデルにアクセスするコードを使って、これらのユーティリティを作成できます。
ソリューションまたはサービスを監視することに有用なメリットがあるかどうかを検討します。 Microsoft System Center では、HDInsight 管理パックが提供されています。 また、Apache Chukwa や Ganglia などのサードパーティ製ツールを使って、ログを収集および一元管理することもできます。 たとえば、
Centerity、Compuware APM、Sematext SPM、Zettaset Orchestrator など、多くの企業が Hadoop ベースのビッグ データ ソリューションを監視するためのサービスを提供しています。
ステップ 2: クラスター サービスのバージョンを管理し、ログを表示する
一般的な HDInsight クラスターでは、複数のサービスとオープン ソース ソフトウェア パッケージ (Apache HBase、Apache Spark など) が使われます。 バイオインフォマティクスなどの一部のワークロードでは、ジョブ実行ログに加えてサービス構成ログ履歴の保持を求められる場合があります。
Ambari UI でクラスターの構成設定を表示する
Apache Ambari には Web UI と REST API が用意されており、HDInsight クラスターを簡単に管理、構成、監視できます。 Ambari は Linux ベースの HDInsight クラスターに付属しています。 Azure portal の HDInsight ページで [クラスター ダッシュボード] ウィンドウを選び、[クラスター ダッシュボード] リンク ページを開きます。 次に、[HDInsight クラスター ダッシュボード] ウィンドウを選んで、Ambari UI を開きます。 クラスター ログイン資格情報の入力を求められます。
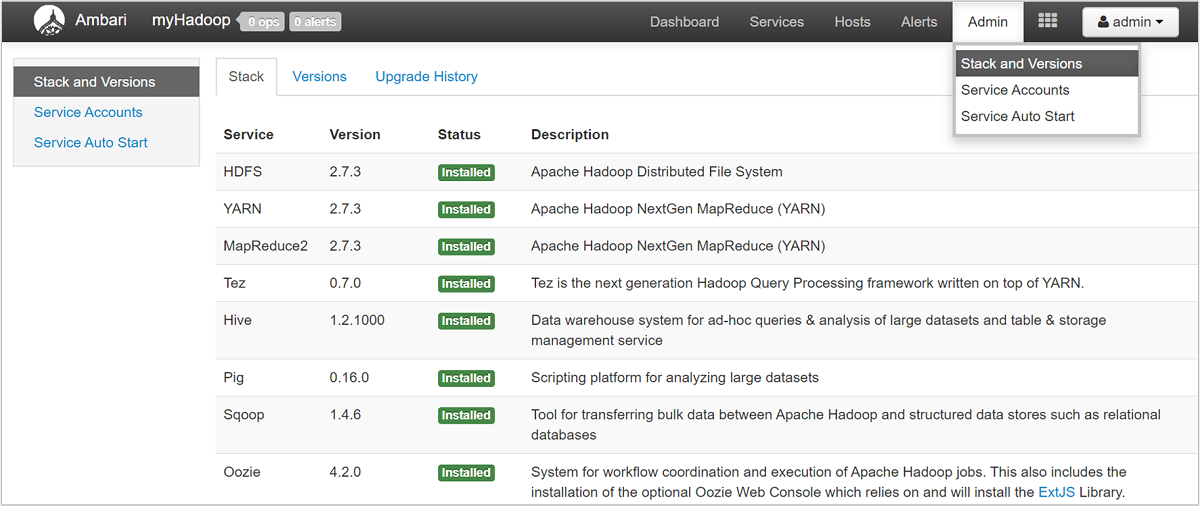
サービス ビューの一覧を開くには、HDInsight の Azure Portal ページで [Ambari Views] ウィンドウを選びます。 この一覧は、インストールされているライブラリによって異なります。 たとえば、YARN Queue Manager、Hive View、Tez View などが表示される場合があります。 構成とサービスの情報を表示するには、サービスのリンクを選びます。 Ambari UI の [Stack and Version](スタックとバージョン) ページには、クラスター サービスの構成とサービスのバージョン履歴に関する情報が表示されます。 Ambari UI のこのセクションに移動するには、[Admin](管理) メニューを選んでから、[Stacks and Versions](スタックとバージョン) を選びます。 サービスのバージョン情報を見るには、[Versions](バージョン) タブを選びます。
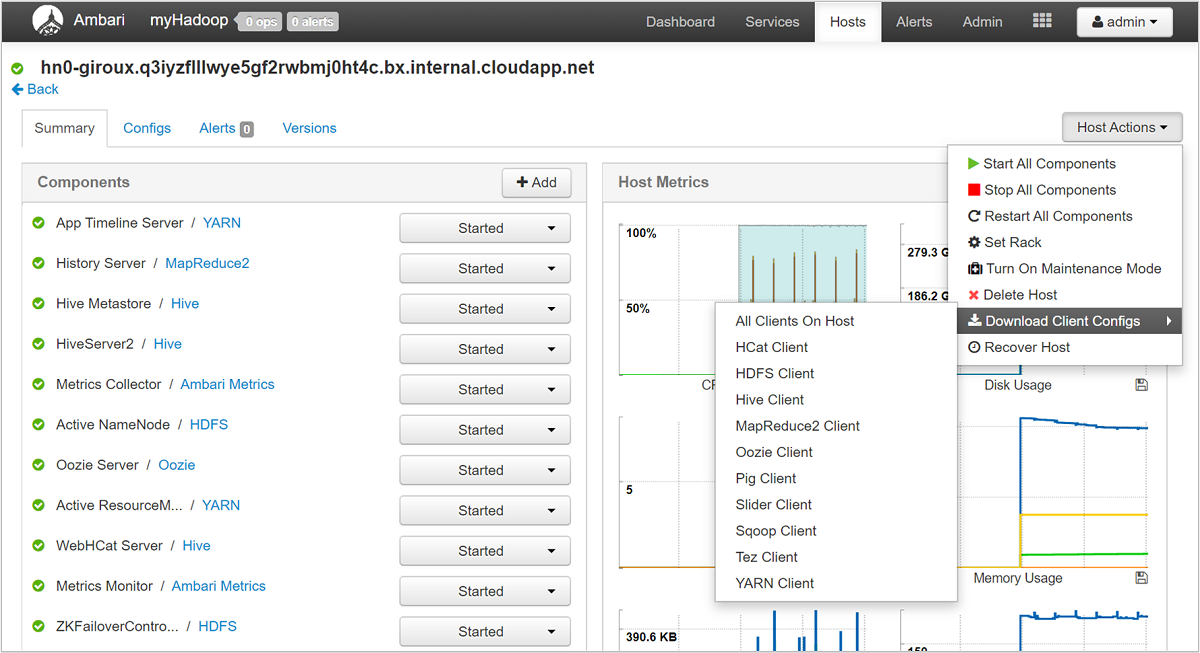
Ambari UI を使って、クラスターの特定のホスト (またはノード) で実行されている任意 (またはすべて) のサービスの構成をダウンロードできます。 [Hosts](ホスト) メニューを選んでから、目的のホストのリンクを選びます。 ホストのページで、[Host Actions](ホスト アクション) ボタンを選んでから、[Download Client Configs](クライアント構成のダウンロード) を選びます。
スクリプト アクション ログを表示する
HDInsight のスクリプト アクションを使うと、手動または日時指定により、クラスターでスクリプトを実行できます。 たとえば、スクリプト アクションを使用して、クラスターに他のソフトウェアをインストールすることや、構成設定を既定値から変更することができます。 スクリプト アクション ログでは、クラスターのセットアップ中に発生したエラーや、クラスターのパフォーマンスと可用性に影響を与える可能性のある構成設定の変更に関する洞察が得られます。 スクリプト アクションの状態を表示するには、Ambari UI の [ops](操作) ボタンを選ぶか、既定のストレージ アカウントで状態ログにアクセスします。 ストレージ ログは、 /STORAGE_ACCOUNT_NAME/DEFAULT_CONTAINER_NAME/custom-scriptaction-logs/CLUSTER_NAME/DATEにあります。
Ambari アラートの状態ログを表示する
Apache Ambari は、アラートの状態の変更を ambari-alerts.log に書き込みます。 完全なパスは /var/log/ambari-server/ambari-alerts.log です。 ログのデバッグを有効にするには、/etc/ambari-server/conf/log4j.properties. のプロパティを変更します。その後、# Log alert state changes の下にあるエントリを次のように変更します。
log4j.logger.alerts=INFO,alerts
to
log4j.logger.alerts=DEBUG,alerts
ステップ 3: クラスターのジョブ実行のログ ファイルを管理する
ここでは、さまざまなサービスのジョブ実行ログ ファイルを確認します。 Apache HBase や Apache Spark など、多くのサービスがあります。 Hadoop クラスターでは多数の詳細ログが生成されるので、役に立つ (役に立たない) ログを判断するには時間がかかることがあります。 ログ ファイル管理の対象を絞り込むには、ログ システムを理解することが重要です。 次の画像は、ログ ファイルの例です。

Hadoop のログ ファイルにアクセスする
HDInsight では、クラスター ファイル システムと Azure Storage の両方にログ ファイルが格納されます。 クラスター内のログ ファイルは、クラスターへの SSH 接続を開いてファイル システムを参照するか、リモート ヘッド ノード サーバー上の Hadoop YARN Status ポータルを使うことで確認できます。 Azure Storage のログ ファイルは、Azure Storage にアクセスしてデータをダウンロードできるツールを使って確認できます。 たとえば、AzCopy、CloudXplorer、Visual Studio サーバー エクスプローラーなどがあります。 また、PowerShell と Azure Storage クライアント ライブラリ、または Azure .NET SDK を使って、Azure Blob Storage 内のデータにアクセスすることもできます。
Hadoop は、クラスターのさまざまなノードでジョブの作業を "タスク試行" として実行します。 HDInsight は、予測タスク試行を開始して、最初に完了していない他のすべてのタスク試行を終了することがあります。 これにより、コントローラー、stderr、syslog のログ ファイルに即座に記録される大量のアクティビティが生成されます。 さらに、複数のタスク試行が同時に実行しますが、ログ ファイルでは結果を順番にしか表示できません。
Azure Blob Storage に書き込まれる HDInsight ログ
HDInsight クラスターは、Azure PowerShell コマンドレットまたは .NET ジョブ送信 API を使って送信されたジョブのタスク ログを Azure Blob Storage アカウントに書き込むように構成されます。 SSH を使ってクラスターにジョブを送信した場合は、実行ログ情報は前のセクションで説明したように Azure テーブルに格納されます。
HDInsight によって生成されるコア ログ ファイルに加えて、YARN などのインストールされているサービスもジョブ実行ログ ファイルを生成します。 ログ ファイルの種類と数は、インストールされているサービスに依存します。 一般的なサービスとしては、Apache HBase、Apache Spark などがあります。 クラスターで利用可能な全体的なログ ファイルを理解するには、各サービスのジョブ ログ実行ファイルを調べます。 各サービスには、固有のログ メソッドとログ ファイル格納場所があります。 例として、次のセクションでは最も一般的なサービス ログ ファイル (YARN) へのアクセスに関して詳しく詳細します。
YARN によって生成される HDInsight ログ
YARN は、ワーカー ノード上のすべてのコンテナーのログを集計して、ワーカー ノードごとに 1 つの集計ログ ファイルとして保存します。 そのログは、アプリケーションの完了後に既定のファイル システムに保存されます。 アプリケーションは数百または数千のコンテナーを使用することがありますが、1 つのワーカー ノードで実行されるすべてのコンテナーのログは常に 1 つのファイルに集計されます。 アプリケーションで使われるワーカー ノードごとに 1 つのログ ファイルが存在します。 ログの集計は、HDInsight クラスター バージョン 3.0 以降では既定で有効になります。 集計されたログは、クラスターの既定のストレージに配置されます。
/app-logs/<user>/logs/<applicationId>
集計されたログは、コンテナーによってインデックスが作成される TFile バイナリ形式で書かれているため、直接読むことはできません。 YARN ResourceManager ログまたは CLI ツールを使用して、対象のアプリケーションまたはコンテナーのログをプレーン テキストとして表示します。
YARN CLI ツール
YARN CLI ツールを使用するには、まず SSH を使用して HDInsight クラスターに接続する必要があります。 これらのコマンドを実行するときは、<applicationId>、<user-who-started-the-application>、<containerId>、<worker-node-address> の各情報を指定します。 次のいずれかのコマンドを使って、これらのログをプレーンテキストとして表示できます。
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application>
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>
YARN Resource Manager UI
YARN ResourceManager UI は、クラスターのヘッド ノードで実行され、Ambari Web UI を使用してアクセスします。 YARN ログを表示するには、次の手順を使用します。
- Web ブラウザーで、
https://CLUSTERNAME.azurehdinsight.netに移動します。 CLUSTERNAME を、使用する HDInsight クラスターの名前に置き換えます。 - 左側のサービスの一覧で、[YARN] を選びます。
- [クイック リンク] ドロップダウンから、いずれかのクラスター ヘッド ノードを選択し、[Resource Manager logs] (ResourceManager ログ) を選択します。 YARN のログへのリンクの一覧が表示されます。
ステップ 4: ログ ボリュームのストレージ サイズとコストを予測する
ここまでの手順を完了すると、HDInsight クラスターが生成するログ ファイルの種類とボリュームがわかっています。
次に、一定の期間にわたって、重要なログ ストレージ場所のログ データのボリュームを分析します。 たとえば、30、60、90 日間にわたりボリュームや増加を分析します。 この情報をスプレッドシートに記録するか、Visual Studio、Azure Storage Explorer、Power Query for Excel などの他のツールを使います。 ```
重要なログのログ管理戦略を作成するのに十分な情報が手に入ります。 スプレッドシート (または選んだツール) を使って、ログ サイズの増加量と、ログ ストレージの Azure サービスのコストを予測します。 調べているログ セットのログ リテンション期間要件も検討します。 削除できるファイル (ある場合) および低コストの Azure Storage に保持してアーカイブする必要のあるログを決定した後、将来のログ ストレージ コストを再予測できます。
ステップ 5: ログのアーカイブ ポリシーとプロセスを決定する
削除できるログ ファイルを決定した後は、さまざまな Hadoop サービスのログ パラメーターを調整して、指定期間後にログ ファイルを自動的に削除できます。
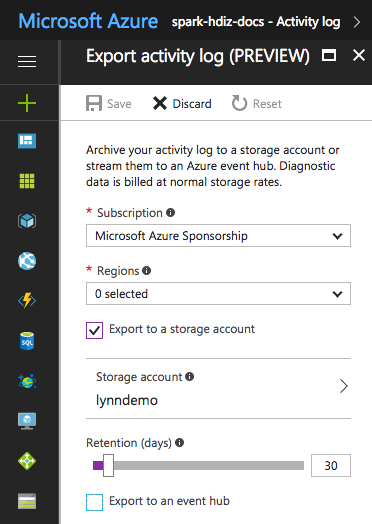
一部のログ ファイルについては、低コストのログ ファイル アーカイブ方法を使うことができます。 Azure Resource Manager のアクティビティ ログの場合、Azure portal を使ってこの方法を調べることができます。 HDInsight インスタンスの Azure portal で [アクティビティ ログ] リンクを選んで、Resource Manager ログのアーカイブを設定します。 アクティビティ ログ検索ページの上部にある [エクスポート] メニュー項目を選んで、[アクティビティ ログのエクスポート] ウィンドウを開きます。 サブスクリプション、リージョン、ストレージ アカウントにエクスポートするかどうか、ログを保持する日数を入力します。 この同じウィンドウで、イベント ハブにエクスポートするかどうかを指定することもできます。
代わりに、PowerShell でログをアーカイブするスクリプトを作成できます。
Azure Storage メトリックへのアクセス
ストレージの操作とアクセスをログに記録するように、Azure Storage を構成できます。 容量の監視と計画、およびストレージへの要求の監査のために、これらの詳細なログを使用できます。 ログに記録される情報には待機時間の詳細が含まれるので、ソリューションのパフォーマンスを監視して微調整できます。 .NET SDK for Hadoop を使うと、HDInsight クラスターのデータを保持する Azure Storage に対して生成されるログ ファイルを調べることができます。
古いログ ファイルのバックアップ インデックスのサイズと数を制御する
保持されるログ ファイルのサイズと数を制御するには、RollingFileAppender の次のプロパティを設定します。
maxFileSizeはファイルのクリティカル サイズで、これを超えるとファイルはロールされます。 既定値は 10 MB です。maxBackupIndexは、作成するバックアップ ファイルの数を指定します。既定値は 1 です。
その他のログ管理手法
ディスク領域不足を回避するために、logrotate などのいくつかの OS ツールを使用して、ログ ファイルの処理を管理できます。 logrotate を構成して毎日実行し、ログ ファイルを圧縮し、古いログ ファイルを削除できます。 方法は、ログ ファイルをローカル ノードに保持する期間などの要件に依存します。
また、1 つ以上のサービスに対して DEBUG ログが有効になっているかどうかも確認できます。有効になっていると、出力ログのサイズが大幅に増加します。
すべてのノードから 1 つの場所にログを収集するには、データ フローを作成できます (Solr へのすべてのログ エントリの取り込みなど)。