HDInsight クラスターでジョブが遅いか失敗する場合のトラブルシューティング
HDInsight クラスターでデータを処理するアプリケーションの実行が遅い場合、またはエラー コードで失敗する場合は、複数のトラブルシューティング オプションがあります。 ジョブの実行時間が予想より長い場合、または一般に応答時間が遅い場合は、クラスターが実行しているサービスなど、クラスターからのアップストリームに障害が存在する可能性があります。 ただし、これらの速度低下の最も一般的な原因は、不十分なスケーリングです。 新しい HDInsight クラスターを作成する際は、適切な仮想マシン サイズを選択してください。
クラスターの速度低下または失敗を診断するには、関連付けられている Azure サービス、クラスターの構成、ジョブの実行情報など、環境のあらゆる側面に関する情報を収集します。 別のクラスターでエラー状態を再現してみると診断に役立ちます。
- ステップ 1: 問題に関するデータを収集する。
- ステップ 2: HDInsight クラスターの環境を検証する。
- ステップ 3: クラスターの正常性を表示する。
- ステップ 4: 環境のスタックとバージョンを確認する。
- ステップ 5: クラスターのログ ファイルを調べる。
- ステップ 6: 構成設定を確認する。
- ステップ 7: 別のクラスターで障害を再現する。
ステップ 1: 問題に関するデータを収集する
HDInsight では、クラスターに関する問題の識別とトラブルシューティングに使うことができる多くのツールが提供されています。 以下の手順では、これらのツールについて説明し、問題の特定に関する推奨事項を示します。
問題を特定する
問題の特定に役立つ以下の質問を検討します。
- どのような結果が想定されていましたか? 代わりにどのようなことが発生しましたか?
- プロセスの実行にはどれくらいの時間がかかりましたか? 本来はどれくらいの時間で実行されるはずでしたか?
- 問題のタスクはこのクラスターで常に実行速度が遅くなりますか? 別のクラスターでは実行速度が速くなりましたか?
- この問題が最初に発生したのはいつですか? それからどのくらいの頻度で発生していますか?
- クラスターの構成を何か変更しましたか?
クラスターの詳細
クラスターの重要な情報は次のとおりです。
- クラスター名。
- クラスターのリージョン - リージョンの停止を確認します。
- HDInsight クラスターの種類とバージョン。
- ヘッド ノードおよびワーカー ノードに指定されている HDInsight インスタンスの種類と数。
Azure Portal は次の情報を提供できます。
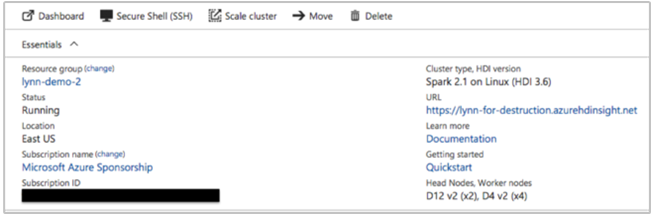
Azure CLI を使うこともできます。
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
もう 1 つのオプションは、PowerShell を使うことです。 詳細については、Azure PowerShell を使用した HDInsight での Apache Hadoop クラスターの管理に関するページを参照してください。
ステップ 2: HDInsight クラスターの環境を検証する
各 HDInsight クラスターは、さまざまな Azure サービスと、Apache HBase や Apache Spark などのオープン ソース ソフトウェアに依存しています。 また、HDInsight クラスターは、Azure Virtual Network などの他の Azure サービスを呼び出すこともできます。 クラスターの障害は、お使いのクラスターで実行しているいずれかのサービスまたは外部サービスが原因で発生している可能性があります。 クラスター サービスの構成の変更により、クラスターで障害が発生することもあります。
サービスの詳細
- オープンソース ライブラリのリリース バージョンを確認します。
- Azure サービスの停止を確認します。
- Azure サービスの使用制限を確認します。
- Azure Virtual Network のサブネット構成を確認します。
Ambari UI でクラスターの構成設定を表示する
Apache Ambari の Web UI と REST API を使って、HDInsight クラスターを管理および監視できます。 Ambari は Linux ベースの HDInsight クラスターに付属しています。 Azure Portal の HDInsight ページで [クラスター ダッシュボード] ウィンドウを選びます。 [HDInsight クラスター ダッシュボード] ペインを選んで Ambari UI を開き、クラスターのログイン資格情報を入力します。
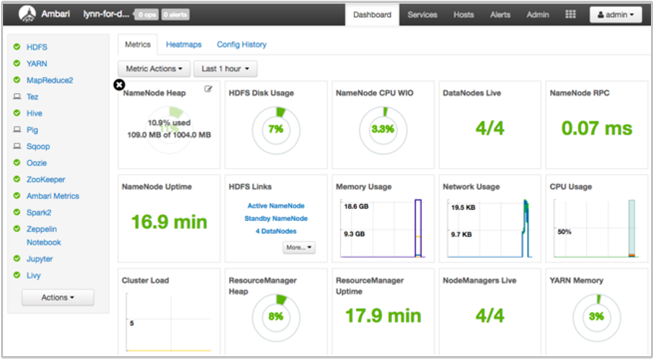
サービス ビューの一覧を開くには、Azure Portal のページで [Ambari Views] を選びます。 この一覧は、インストールされているライブラリに依存します。 たとえば、YARN Queue Manager、Hive View、Tez View などが表示される場合があります。 構成とサービスの情報を表示するには、サービスのリンクを選びます。
Azure サービスの停止を確認する
HDInsight は複数の Azure サービスに依存しています。 Azure HDInsight 上で仮想サーバーを実行し、データとスクリプトを Azure Blob Storage または Azure Data Lake Storage に保存し、Azure Table Storage のログ ファイルにインデックスを作成します。 珍しいことですがこれらのサービスが中断すると、HDInsight で問題が発生する可能性があります。 クラスターで予期しないパフォーマンスの低下や障害が発生した場合は、Azure の状態ダッシュボードを確認します。 各サービスの状態がリージョン別に一覧表示されます。 お使いのクラスターのリージョンだけでなく、関連するサービスのリージョンも確認してください。
Azure サービスの使用制限を確認する
大規模なクラスターを起動している場合、または同時に多数のクラスターを同時に起動した場合、Azure サービスの制限を超えるとクラスターで障害が発生する可能性があります。 サービスの制限は、Azure サブスクリプションによって異なります。 詳細については、「Azure サブスクリプションとサービスの制限、クォータ、制約」をご覧ください。 Resource Manager のコア クォータ増加要求を使って、利用可能な HDInsight リソース (VM コアや VM インスタンスなど) の数を増やすことを Microsoft に要求できます。
リリース バージョンを確認する
クラスターのバージョンと HDInsight の最新リリースを比較します。 HDInsight の各リリースには、新しいアプリケーション、機能、修正プログラム、バグ修正などの機能強化が含まれています。 クラスターに影響を与えている問題が、最新のリリース バージョンで解決されている可能性があります。 可能であれば、最新バージョンの HDInsight と、Apache HBase、Apache Spark などの関連ライブラリを使って、クラスターを実行し直します。
クラスターのサービスを再起動する
クラスターのパフォーマンスが低下している場合は、Ambari UI または Azure クラシック CLI を使ってサービスを再起動することを検討します。 クラスターで一時的なエラーが発生している場合、再起動は環境を安定させる最も簡単な方法であり、パフォーマンスが向上する可能性があります。
ステップ 3: クラスターの正常性を表示する
HDInsight クラスターは、仮想マシンのインスタンスで稼働するさまざまな種類のノードで構成されます。 各ノードで、リソースの枯渇、ネットワーク接続の問題、およびクラスターを遅くする他の問題を監視できます。 すべてのクラスターには 2 つのヘッド ノードが含まれ、ほとんどのクラスターの種類にはワーカー ノードとエッジ ノードの組み合わせが含まれます。
各クラスターの種類で使用されるさまざまなノードの説明については、Apache Hadoop、Apache Spark、Apache Kafka などの HDInsight クラスターのセットアップに関するページを参照してください。
以下のセクションでは、各ノードおよびクラスター全体の正常性を確認する方法について説明します。
Ambari UI ダッシュボードを使ってクラスターの正常性のスナップショットを取得する
Ambari UI ダッシュボード (https://<clustername>.azurehdinsight.net) では、稼働時間、メモリ、ネットワークと CPU の使用率、HDFS ディスクの使用量など、クラスターの正常性の概要が提供されます。 ホスト レベルでリソースを表示するには、Ambari のホスト セクションを使います。 サービスを停止して再起動することもできます。
WebHCat サービスを確認する
Apache Hive、Apache Pig、または Apache Sqoop ジョブが失敗する一般的なシナリオの 1 つは、WebHCat (または Templeton) サービスでの障害です。 WebHCat は、Hive、Pig、Scoop、MapReduce などのリモート ジョブ実行用の REST インターフェイスです。 WebHCat は、ジョブ送信要求を Apache Hadoop YARN アプリケーションに変換し、YARN アプリケーションの状態から抽出された状態を返します。 次のセクションでは、WebHCat HTTP の一般的な状態コードについて説明します。
BadGateway (502 状態コード)
このコードは、ゲートウェイ ノードからの汎用メッセージであり、最も一般的な障害状態コードです。 考えられる原因の 1 つは、アクティブなヘッド ノードで WebHCat サービスがダウンしていることです。 この可能性を確認するには、次の CURL コマンドを使います。
curl -u admin:{HTTP PASSWD} https://{CLUSTERNAME}.azurehdinsight.net/templeton/v1/status?user.name=admin
Ambari では、WebHCat サービスがダウンしているホストを示すアラートが表示されます。 そのホストのサービスを再起動することにより、WebHCat サービスのバックアップを試みることができます。

WebHCat サーバーがまだ回復しない場合は、エラー メッセージの操作ログを確認します。 さらに詳細な情報を得るには、ノードで参照されている stderr および stdout ファイルを確認します。
WebHCat のタイムアウト
HDInsight ゲートウェイは、2 分より長くかかっている応答をタイムアウトさせて、502 BadGateway を返します。 WebHCat が YARN サービスにジョブの状態を照会し、YARN が応答に 2 分以上かかった場合、要求はタイムアウトする可能性があります。
この場合は、/var/log/webhcat ディレクトリで次のログを確認します。
- webhcat.log は、サーバーがログを書き込む log4j ログです
- webhcat-console.log は、起動時のサーバーの stdout です
- webhcat-console-error.log は、サーバー プロセスの stderr です
Note
各 webhcat.log は毎日ロールオーバーされて、webhcat.log.YYYY-MM-DD という名前のファイルが生成されます。 調査している時間範囲の適切なファイルを選択してください。
次のセクションでは、WebHCat のタイムアウトに対して考えられる原因について説明します。
WebHCat レベルのタイムアウト
WebHCat で 10 個より多くのソケットが開かれていて負荷がかかっている場合、新しいソケット接続の確立に時間がかかり、タイムアウトになる可能性があります。 WebHCat との間のネットワーク接続の一覧を表示するには、現在アクティブなヘッド ノードで netstat を使います。
netstat | grep 30111
30111 は、WebHCat がリッスンしているポートです。 開いているソケットの数は 10 未満でなければなりません。
開いているソケットがない場合、前記のコマンドは結果を生成しません。 Templeton が稼働していてポート 30111 でリッスンしているかどうかを確認するには、次のコマンドを使います。
netstat -l | grep 30111
YARN レベルのタイムアウト
Templeton は YARN を呼び出してジョブを実行し、Templeton と YARN の間の通信がタイムアウトの原因になることがあります。
YARN レベルでは、2 種類のタイムアウトがあります。
YARN ジョブの送信に時間がかかりすぎて、タイムアウトが発生することがあります。
/var/log/webhcat/webhcat.logログ ファイルを開き、"queued job" を検索すると、実行時間が異常に長く (2,000 ミリ秒超) 待機時間が徐々に長くなる複数のエントリが見つかる場合があります。新しいジョブが送信される速度の方が、古いジョブが完了する速度より速いため、ジョブがキューに入っている時間は長くなり続けます。 YARN メモリが 100% 使われると、"joblauncher キュー" は "既定のキュー" から容量を借りることができなくなります。 そのため、joblauncher キューはそれ以上新しいジョブを受け付けることができません。 このような動作のため、待機時間はどんどん長くなってタイムアウト エラーが発生し、通常はそれに続いて他にも多くのエラーが発生します。
次の図は、714.4% の過剰使用状態の joblauncher キューを示したものです。 既定のキューに借用可能な空き容量がある限り、これは許容されます。 しかし、クラスターが完全に利用されて、YARN メモリの容量が 100% になると、新しいジョブは待機する必要があり、最終的にタイムアウトが発生します。

この問題を解決するには 2 つの方法があります。新しいジョブを送信する数を減らす方法と、クラスターをスケールアップすることによって古いジョブを処理する速度を上げる方法です。
YARN の処理には長い時間がかかる場合があり、タイムアウトの原因になる可能性があります。
すべてのジョブの一覧取得: これは時間のかかる呼び出しです。 この呼び出しでは、YARN ResourceManager からアプリケーションが列挙され、完了した各アプリケーションについて、YARN JobHistoryServer から状態が取得されます。 ジョブの数が多いと、この呼び出しがタイムアウトになる場合があります。
7 日より古いジョブの一覧取得: HDInsight YARN JobHistoryServer は、完了したジョブの情報を 7 日間保持するように構成されています (
mapreduce.jobhistory.max-age-ms値)。 消去されたジョブを列挙しようとすると、タイムアウトします。
これらの問題を診断するには:
- トラブルシューティングを行う UTC 時間の範囲を決定します
webhcat.logの適切なファイルを選びます- その期間中の WARN メッセージと ERROR メッセージを探します
WebHCat のその他の障害
HTTP 状態コード 500
WebHCat が 500 を返す場合のほとんどで、エラー メッセージにはエラーの詳細が含まれています。 含まれない場合は、
webhcat.logで WARN メッセージと ERROR メッセージを探します。ジョブの失敗
WebHCat とのやり取りに問題がなくても、ジョブが失敗する場合があります。
Templeton はジョブ コンソールの出力を
statusdirにstderrとして収集しており、トラブルシューティングに役立つことがよくあります。stderrには、実際のクエリの YARN アプリケーション識別子が含まれます。
ステップ 4: 環境のスタックとバージョンを確認する
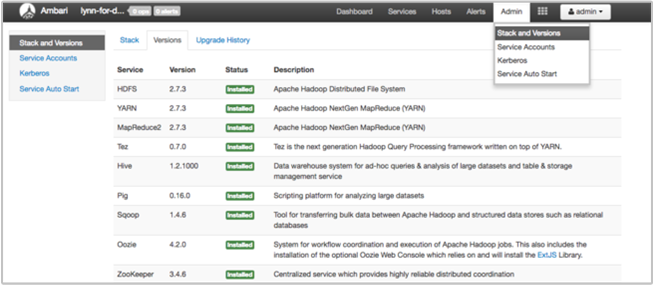
Ambari UI の [Stack and Version]\(スタックとバージョン\) ページには、クラスター サービスの構成とサービスのバージョン履歴に関する情報が表示されます。 Hadoop サービス ライブラリのバージョンが正しくないと、クラスターの障害の原因になる可能性があります。 Ambari UI で [Admin]\(管理\) メニューを選び、[Stacks and Versions]\(スタックとバージョン\) を選びます。 ページの上部で [Versions]\(バージョン\) タブを選び、サービスのバージョン情報を確認します。
ステップ 5: ログ ファイルを調べる
HDInsight クラスターを構成する多くのサービスとコンポーネントから、多くの種類のログが生成されます。 WebHCat ログファイルについては既に説明しました。 以下のセクションでは、クラスターに関する問題の絞り込みの調査で他に役立つ可能性がある他のいくつかのログ ファイルについて説明します。
HDInsight クラスターは複数のノードで構成され、そのほとんどのタスクは送信されたジョブを実行することです。 ジョブは同時に実行されますが、ログ ファイルは結果を順番にしか表示できません。 HDInsight は新しいタスクを実行するとき、最初に完了していない他のタスクを終了します。 このアクティビティはすべて、
stderrファイルとsyslogファイルに記録されます。スクリプト アクション ログ ファイルでは、クラスターの作成プロセス中のエラーまたは予期しない構成変更が表示されます。
Hadoop のステップ ログでは、エラーを含むステップの一部として開始された Hadoop ジョブが示されます。
スクリプト アクション ログを調べる
HDInsight のスクリプト アクションは、手動により、または指定されたときに、クラスターでスクリプトを実行します。 たとえば、スクリプト アクションを使って、クラスターに追加ソフトウェアをインストールしたり、構成設定を既定値から変更したりできます。 スクリプト アクションのログを調べると、クラスターのセットアップと構成の間に発生したエラーに関する分析情報を得られます。 Ambari UI で [ops]\(操作\) ボタンを選ぶか、または既定のストレージ アカウントからログにアクセスすることで、スクリプト アクションの状態を表示できます。
スクリプト アクションのログは、\STORAGE_ACCOUNT_NAME\DEFAULT_CONTAINER_NAME\custom-scriptaction-logs\CLUSTER_NAME\DATE ディレクトリにあります。
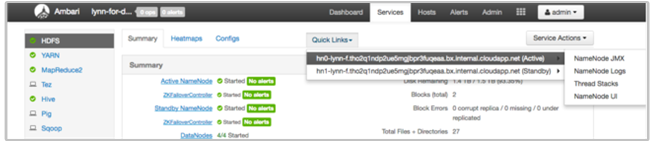
Ambari のクイック リンクを使って HDInsight のログを表示する
HDInsight の Ambari UI には、複数の [Quick Links]\(クイック リンク\) セクションが含まれます。 HDInsight クラスターの特定のサービスのログ リンクにアクセスするには、クラスターの Ambari UI を開き、左側にある一覧からサービス リンクを選びます。 [Quick Links]\(クイック リンク\) ドロップダウンを選び、目的の HDInsight ノードを選んで、関連付けられているログのリンクを選びます。
たとえば、HDFS ログの場合は次のように選びます。
Hadoop で生成されたログ ファイルを表示する
HDInsight クラスターは、Azure テーブルおよび Azure Blob Storage に書き込まれるログを生成します。 YARN は独自の実行ログを作成します。 詳しくは、「HDInsight クラスターのログを管理する」をご覧ください。
ヒープ ダンプを確認する
ヒープ ダンプにはアプリケーションのメモリのスナップショット (その時点での変数の値など) が含まれており、実行時に発生する問題の診断に役立ちます。 詳細については、「Linux ベースの HDInsight で Hadoop サービスのヒープ ダンプを有効にする」を参照してください。
ステップ 6: 構成設定を確認する
HDInsight クラスターは、Hadoop、Hive、HBase などの関連サービスに対する既定の設定であらかじめ構成されています。 クラスターの種類、ハードウェアの構成、ノードの数、実行しているジョブの種類、使っているデータ (および、そのデータの処理方法) によっては、構成の最適化が必要になる場合があります。
多くのシナリオを対象にパフォーマンスの構成を最適化することについての詳細な手順については、Apache Ambari を使用したクラスター構成の最適化に関するページを参照してください。 Spark を使用している場合は、Apache Spark ジョブの最適化によるパフォーマンス向上に関するページを参照してください。
ステップ 7: 別のクラスターで障害を再現する
クラスター エラーの原因の診断に役立てるため、同じ構成で新しいクラスターを起動し、失敗したジョブのステップを 1 つずつ再送信します。 先のステップの結果を確認してから、次のステップを処理します。 この方法では、障害が発生した 1 つのステップを修正して再実行できます。 また、この方法には、入力データを読み込むのが 1 回だけで済むという利点もあります。
- 障害が発生したクラスターと同じ構成で新しいテスト クラスターを作成します。
- 最初のジョブ ステップをテスト クラスターに送信します。
- ステップの処理が完了したら、ステップのログ ファイルでエラーを調べます。 テスト クラスターのマスター ノードに接続し、そこのログ ファイルを表示します。 ステップのログ ファイルは、ステップがしばらく実行して終了または失敗した後でのみ表示されます。
- 最初のステップが成功した場合は、次のステップを実行します。 エラーが発生した場合は、ログ ファイルでエラーを調査します。 コードにエラーがあった場合は、修正をして、ステップを再実行します。
- すべてのステップがエラーなしで実行されるようになるまで続けます。
- テスト クラスターのデバッグが完了したら、クラスターを削除します。