この記事では、Azure HDInsight で Apache Hadoop、Apache Spark、Apache Kafka、Interactive Query、Apache HBase を設定および構成する方法について説明します。 クラスターをドメインに参加させて、クラスターをカスタマイズしたりセキュリティを強化したりする方法についても説明します。
Hadoop クラスターは、タスクの分散処理に使用される複数の仮想マシン (VM、ノードとも呼ばれます) で構成されます。 HDInsight は、個々のノードのインストールと構成の実装の詳細を処理します。 一般的な構成情報のみを指定します。
重要
HDInsight クラスターの課金は、クラスターが作成された後に開始し、クラスターが削除されると停止します。 課金は分単位なので、クラスターを使わなくなったら必ず削除してください。 詳細については、クラスターの削除方法に関するページを参照してください。
複数のクラスターを一緒に使用する場合は、仮想ネットワークを作成します。 Spark クラスターを使用する場合は、Hive Warehouse コネクタも使用する必要があります。 詳細については、「Azure HDInsight 用の仮想ネットワークを計画する」と「Hive Warehouse Connector を使用して Apache Spark と Apache Hive を統合する」を参照してください。
次の表は、HDInsight クラスターのセットアップに使用できる各種の方法を示しています。
この記事では、Azure portal で、HDInsight クラスターを作成するためのセットアップ方法を説明します。
![[HDInsight クラスターの作成] のオプションを示すスクリーンショット。](media/hdinsight-hadoop-provision-linux-clusters/azure-portal-cluster-basics-blank-fs.png)
Azure Resource Manager を使用すると、アプリケーション内の複数のリソースを、Azure リソース グループと呼ばれる 1 つのグループとして使用できます。 アプリケーションのこれらすべてのリソースを、1 回の連携した操作でデプロイ、更新、監視、または削除できます。
クラスターの詳細には、名前、リージョン、種類、バージョンが含まれます。
HDInsight クラスター名には次の制限があります。
-
使用できる文字: a-z、0-9、A-Z
-
最大長: 59
-
予約済みの名前: apps
-
クラスターの名前付け: スコープは、すべてのサブスクリプションにわたる Azure 全体に対して行われます。 クラスター名は世界全域で一意である必要があります。 最初の 6 文字は仮想ネットワーク内で一意である必要があります。
クラスターの場所を明示的に指定する必要はありません。 クラスターは、既定のストレージと同じ場所に存在します。 サポートされているリージョンのリストについては、「HDInsight の価格」の [リージョン] ドロップダウン リストを選択してください。
次の表では、HDInsight では現在、以下の種類のクラスターを提供しています。それぞれのクラスターは特定の機能を提供する一連のコンポーネントを備えています。
重要
HDInsight クラスターには、さまざまな種類があり、それぞれ単一のワークロードまたはテクノロジに対応しています。 1 つのクラスター上の HBase など、複数の型を組み合わせたクラスターを作成する方法はサポートされていません。 複数の種類の HDInsight クラスターにまたがるテクノロジがソリューションに必要な場合は、必要な種類のクラスターを Azure 仮想ネットワーク で接続してください。
| クラスターの種類 |
機能 |
|
Hadoop |
格納されたデータのバッチ クエリとバッチ分析。 |
|
HBase |
大量のスキーマレス NoSQL データの処理。 |
|
Interactive Query |
対話型で高速な Hive クエリのメモリ内キャッシュ。 |
|
Kafka |
リアルタイムのストリーミング データ パイプラインとアプリケーションの構築に使用できる分散ストリーム プラットフォーム。 |
|
Spark |
メモリ内処理、対話型クエリ、マイクロバッチ ストリーム処理。 |
このクラスターの HDInsight のバージョンを選択します。 詳細については、「サポートされる HDInsight のバージョン」を参照してください。
HDInsight クラスターでは、クラスターの作成時に次の 2 つのユーザー アカウントを構成できます。
-
クラスター ログイン ユーザー名: 既定のユーザー名は admin です。Azure Portal の基本的な構成を使用します。
"クラスター ユーザー" または "HTTP ユーザー" とも呼ばれます。
-
Secure Shell (SSH) ユーザー名: SSH を使用してクラスターに接続する際に使用します。 詳細については、HDInsight での SSH の使用に関するページを参照してください。
HTTP ユーザー名には次の制限があります。
-
使用できる特殊文字: _ と @
-
使用できない文字: #;."',:`!*?$(){}[]<><>|&--=+%~^スペース
-
最大長: 20
SSH ユーザー名には次の制限があります。
-
使用できる特殊文字: _ と @
-
使用できない文字: #;."',:`!*?$(){}[]<><>|&--=+%~^スペース
-
最大長: 64
-
予約済みの名前: hadoop、users、oozie、hive、mapred、ambari、zookeeper、tez、hdfs、sqoop、yarn、hcat、ams、hbase、administrator、admin、user、user1、test、user2、test1、user3、admin1、1、123、a、actuser、adm、admin2、aspnet、backup、console、David、guest、John、owner、root、server、sql、support、support_388945a0、sys、test2、test3、user4、user5、spark
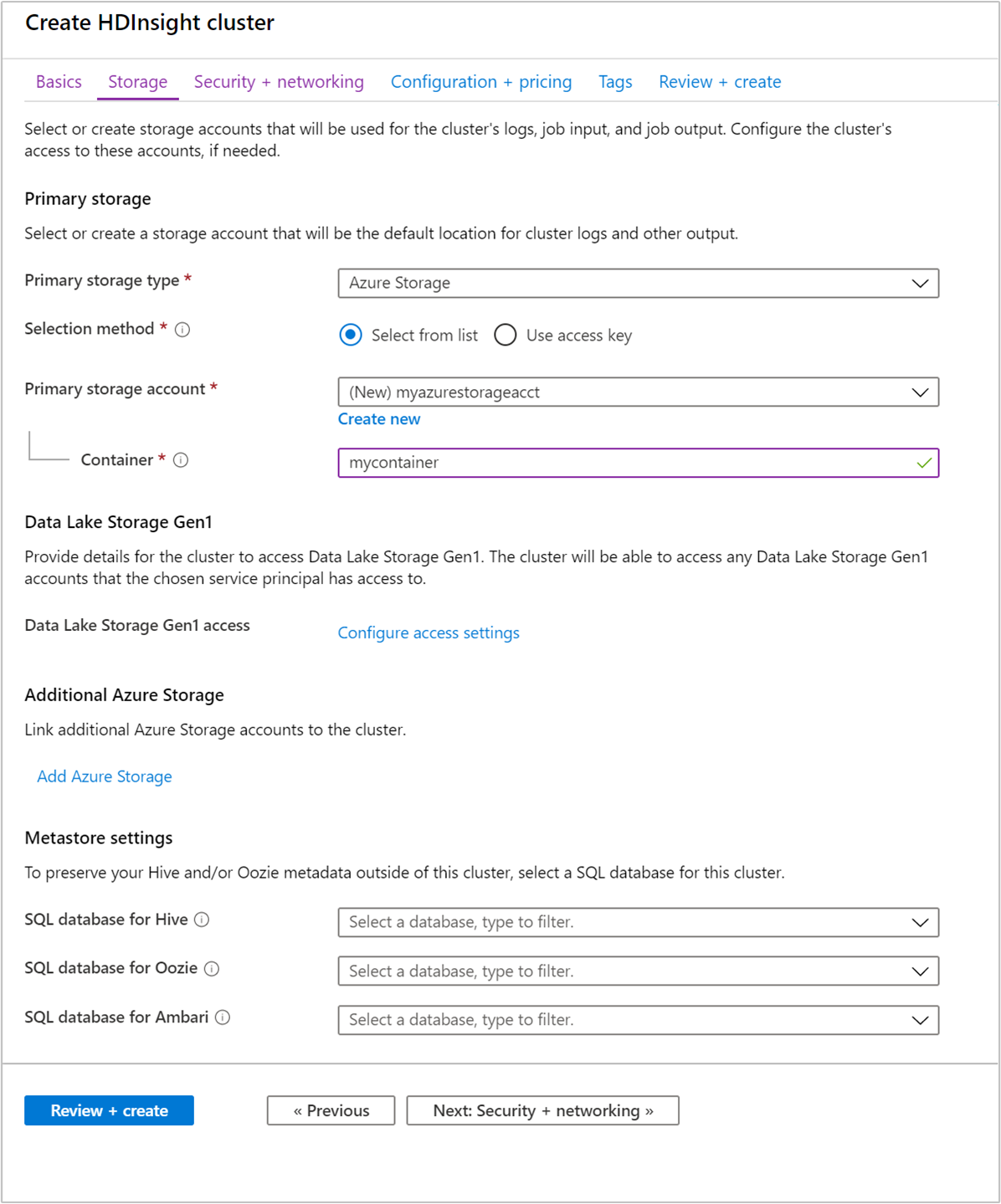
クラスターのストレージには、Hadoop のオンプレミス環境では Hadoop 分散ファイル システム (HDFS) が使用されますが、クラウドでは、クラスターに接続されたストレージ エンドポイントを使用します。 クラウド ストレージを使用すると、データを維持したまま、計算に使用する HDInsight クラスターを安全に削除できます。
HDInsight クラスターでは、次のストレージ オプションを使用できます。
- Azure Data Lake Storage Gen2
- Azure Storage General Purpose v2
- Azure Storage ブロック BLOB (セカンダリ ストレージとしてのみサポート)
HDInsight を使用したストレージ オプションの詳細については、「Azure HDInsight クラスターで使用するストレージ オプションを比較する」を参照してください。
HDInsight クラスター以外の場所で追加のストレージ アカウントを使用することはできません。
構成時、既定のストレージ エンドポイントには、ストレージ アカウントの BLOB コンテナーまたは Data Lake Storage を指定します。 既定のストレージには、アプリケーション ログとシステム ログが格納されます。 必要に応じて、クラスターからアクセスできるリンクされたストレージ アカウントおよび Data Lake Storage アカウントを追加指定できます。 HDInsight クラスターとそのクラスターで使用されるストレージ アカウントは、同じ Azure リージョンに存在している必要があります。
ストレージ アカウントを使用する際にエラーが発生する可能性があるため、クラスターの作成後にセキュリティで保護されたストレージ転送を有効にしないでください。 セキュリティで保護された転送が既に有効になっているストレージ アカウントを使用して新しいクラスターを作成することをお勧めします。
HDInsight では、ストレージに格納されているデータがリージョン間で自動的に転送、移動、コピーされることはありません。
Hive metastore または Apache Oozie metastore を作成できます (任意)。 クラスターの種類によっては metastore がサポートされません。また Azure Synapse Analytics は metastore と互換性がありません。
詳細については、Azure HDInsight での外部メタデータ ストアの使用に関する記事を参照してください。
カスタム metastore を作成するとき、ダッシュ、ハイフン、またはスペースをデータベース名に使用しないでください。 これらの文字が含まれると、クラスター作成プロセスが失敗する可能性があります。
HDInsight クラスターを削除した後も Hive テーブルを保持する場合は、カスタムの metastore を使用することをお勧めします。 その metastore を別の HDInsight クラスターにアタッチすることができます。
あるバージョンの HDInsight クラスター用に作成された HDInsight metastore は、別の HDInsight クラスター バージョン間で共有できません。 HDInsight のバージョンの一覧は、「サポートされる HDInsight のバージョン」をご覧ください。
Hive 用の SQL データベースでの認証にマネージド ID を使用することができます。 詳細については、「HDInsight での SQL Database 認証にマネージド ID を使用する」を参照してください。
既定のメタストアでは、DTU 上限が Basic レベルの 5 (アップグレード不可能) である SQL データベースが提供されます。 基本的なテスト目的に適しています。 より大きなワークロードや運用環境のワークロードの場合は、外部のメタストアに移行することをお勧めします。
Oozie の使用時にパフォーマンスを向上させるには、カスタム メタストアを使用します。 また、metastore を使用すると、クラスターの削除後に、Oozie ジョブ データにアクセスすることができます。
Oozie 用の SQL データベースでの認証にマネージド ID を使用することができます。 詳細については、「HDInsight での SQL Database 認証にマネージド ID を使用する」を参照してください。
Ambari は、HDInsight クラスターの監視、構成の変更、およびクラスター管理情報とジョブ履歴の保存に使用されます。 カスタム Ambari データベース機能を使用すると、新しいクラスターをデプロイし、自分が管理する外部データベースに Ambari を設定できます。 詳細については、カスタムの Ambari データベースに関する記事を参照してください。
Ambari 用の SQL データベースでの認証にマネージド ID を使用することができます。 詳細については、「HDInsight での SQL Database 認証にマネージド ID を使用する」を参照してください。
カスタム Oozie メタストアを再利用することはできません。 カスタム Oozie メタストアを使用するには、HDInsight クラスターの作成時に空の SQL Database を提供する必要があります。
![[エンタープライズ セキュリティ パッケージ] オプションを示すスクリーンショット。](media/hdinsight-hadoop-provision-linux-clusters/azure-portal-cluster-security-networking.png)
クラスターの種類が Hadoop、Spark、HBase、Kafka、および対話型クエリの場合は、エンタープライズ セキュリティ パッケージを有効にすることができます。 このパッケージは、Apache Ranger を使用し、Microsoft Entra と統合することによってより安全なクラスターのセットアップを行うオプションを提供します。 詳細については、「Azure HDInsight のエンタープライズ セキュリティの概要」を参照してください。
エンタープライズ セキュリティ パッケージでは、HDInsight を Microsoft Entra と Apache Ranger と統合することができます。 エンタープライズ セキュリティ パッケージを使用して、複数のユーザーを作成できます。
ドメイン参加済みの HDInsight クラスターの作成の詳細については、ドメイン参加済みの HDInsight サンドボックス環境の作成に関する記事を参照してください。
詳細については、「トランスポート層セキュリティ」を参照してください。
複数の種類の HDInsight クラスターにまたがるテクノロジがソリューションに必要な場合は、必要な種類のクラスターを Azure 仮想ネットワーク で接続してください。 この構成により、クラスターと、それにデプロイするすべてのコードが互いに通信できるようになります。
Azure の仮想ネットワークの HDInsight との併用の詳細については、HDInsight 用の仮想ネットワークの計画に関するページをご覧ください。
Azure の仮想ネットワーク内で 2 つのクラスターの種類を使用した例の詳細については、Apache Kafka を使用した Apache Spark 構造化ストリーミングの使用に関するページを参照してください。 仮想ネットワークの具体的な構成要件など、仮想ネットワークで HDInsight を使用する方法の詳細については、HDInsight 用の仮想ネットワークの計画に関するページをご覧ください。
詳細については、「お客様が管理するキー ディスクの暗号化」を参照してください。
この設定は、Kafka クラスターの種類でのみ使用できます。 詳細については、REST プロキシの使用に関する記事を参照してください。
詳細については、「Azure HDInsight のマネージド ID」を参照してください。
ノードの使用に対する料金は、クラスターが存在する限り発生します。 課金はクラスターが作成されると開始され、クラスターが削除されると停止されます。 クラスターを割り当て解除または保留にすることはできません。
クラスターのノード数、ノードを表す用語、既定の VM サイズは、クラスターの種類によって異なります。 次の表では、各ノードの種類のノード数がリストのかっこ内に示されています。
| Type |
Nodes |
ダイアグラム |
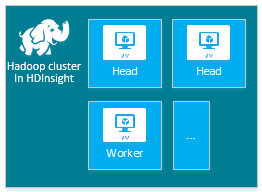
| Hadoop |
ヘッド ノード (2)、ワーカー ノード (1 以上) |
|
| hbase |
ヘッド サーバー (2)、リージョン サーバー (1 以上)、マスター/ZooKeeper ノード (3) |

|
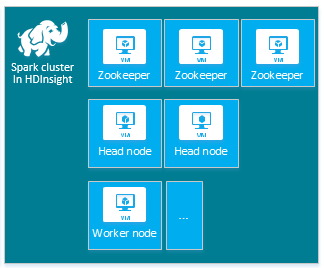
| Spark |
ヘッド ノード (2)、ワーカー ノード (1 以上)、ZooKeeper ノード (3) (A1 ZooKeeper VM サイズでは無料) |
|
詳細については、「クラスターの既定のノード構成と VM サイズ」を参照してください。
HDInsight クラスターのコストは、ノード数とノードの VM のサイズによって決まります。
クラスターの種類によって、ノードの種類、ノード数、ノード サイズが異なります。
HDInsight を試す目的ならば、使用するワーカー ノードは 1 つにすることをお勧めします。 HDInsight の価格の詳細については、「 HDInsight 価格」をご覧ください。
注意
クラスター サイズの制限は、Azure サブスクリプションによって異なります。 制限値を上げるには、Azure の課金サポートにお問い合わせください。
Azure portal を使用してクラスターを構成する際、ノード サイズは [Configuration + pricing](構成と価格) タブで確認できます。また、別のノード サイズに関連するコストをポータルで確認することもできます。
クラスターをデプロイするとき、デプロイ予定のソリューションに応じてコンピューティング リソースを選択します。 HDInsight クラスターには次の VM が使用されます。
各種の SDK または Azure PowerShell を使用してクラスターを作成する際、VM サイズの指定で必要となる値については、HDInsight クラスターに使用する VM サイズに関するページを参照してください。 リンク先の記事に掲載されている表の「サイズ」列の値を使用します。
重要
1 つのクラスターに 32 個を超えるワーカー ノードが必要な場合、コア数が 8 個以上で RAM が 14 GB 以上のサイズのヘッド ノードを選択する必要があります。
詳細については、 VM のサイズに関するページをご覧ください。 さまざまなサイズの価格については、「HDInsight の価格」をご覧ください。
注意
追加されたディスクは、ノード マネージャーのローカル ディレクトリに対してのみ構成され、データノード ディレクトリには構成されません。
HDInsight クラスターには、バージョンに基づいて事前定義されたディスク領域が用意されています。 一部の大きなアプリケーションを実行すると、ディスク領域が不足し、ディスク フル エラー LinkId=221672#ERROR_NOT_ENOUGH_DISK_SPACE とジョブ エラーが発生する可能性があります。
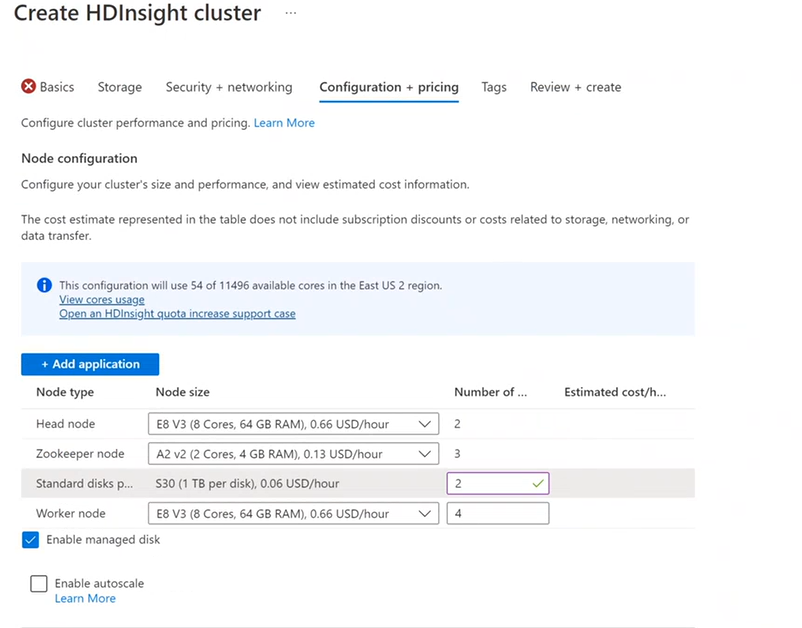
ローカル ディレクトリの新しい機能 NodeManager を使って、クラスターにさらにディスクを追加できます。 Hive と Spark クラスターの作成時に、ディスクの数を選んで、ワーカー ノードに追加できます。 選択したディスクはそれぞれ 1 TB にするほか、NodeManager ローカル ディレクトリの一部にすることができます。
-
[構成と価格] タブで、[マネージド ディスクを有効にする] を選択します。
-
Standard ディスクから、ディスクの数を入力します。
- ワーカー ノードを選択します。
[確認および作成] タブの [クラスターの構成] でディスクの数を確認できます。
HDInsight アプリケーションは、Linux ベースの HDInsight クラスターにインストールできます。 Microsoft やサード パーティから提供されたアプリケーションのほか、独自に開発したアプリケーションを使用することができます。 詳細については、「Azure HDInsight にサードパーティ製 Apache Hadoop アプリケーションをインストールする」を参照してください。
HDInsight のアプリケーションのほとんどは、空のエッジ ノードにインストールされます。 空のエッジ ノードは、ヘッド ノードの場合と同じクライアント ツールがインストールされ、構成された Linux 仮想マシンです。 エッジ ノードは、クラスターへのアクセス、クライアント アプリケーションのテスト、およびクライアント アプリケーションのホストに使用できます。 詳細については、「 Use empty edge nodes in HDInsight」(HDInsight で空のエッジ ノードを使用する) を参照してください。
追加のコンポーネントをインストールするか、作成中にスクリプトを使用してクラスターの構成をカスタマイズできます。 このようなスクリプトは、スクリプト操作を使用して呼び出されます。これは Azure portal、HDInsight Windows PowerShell コマンドレット、HDInsight .NET SDK で使用できる構成オプションです。 詳しくは、「スクリプト アクションを使用して HDInsight クラスターをカスタマイズする」をご覧ください。
Apache Mahout や Cascading などの一部のネイティブ Java コンポーネントは、Java アーカイブ (JAR) ファイルとしてクラスター上で実行できます。 これらの JAR ファイルをストレージに分配し、Hadoop ジョブ送信メカニズムによって HDInsight クラスターに送信できます。 詳しくは、 プログラムによる Apache Hadoop ジョブの送信に関するページをご覧ください。
注意
HDInsight クラスターへの JAR ファイルのデプロイ、または HDInsight クラスターでの JAR ファイルの呼び出しに関する問題がある場合は、 Microsoft サポートにお問い合わせください。
HDInsight はカスケードをサポートしていないため、Microsoft サポートの対象ではありません。 サポートされているコンポーネントの一覧については、HDInsight で提供されるクラスター バージョンの新機能に関する記事をご覧ください。
場合によっては、作成プロセス中に次の構成ファイルを設定する必要があります。
- clusterIdentity.xml
- core-site.xml
- gateway.xml
- hbase-env.xml
- hbase-site.xml
- hdfs-site.xml
- hive-env.xml
- hive-site.xml
- mapred-site
- oozie-site.xml
- oozie-env.xml
- tez-site.xml
- webhcat-site.xml
- yarn-site.xml
詳細については、「 ブートストラップを使って HDInsight クラスターをカスタマイズする」を参照してください。