Azure Blob Storage にデータを移動する
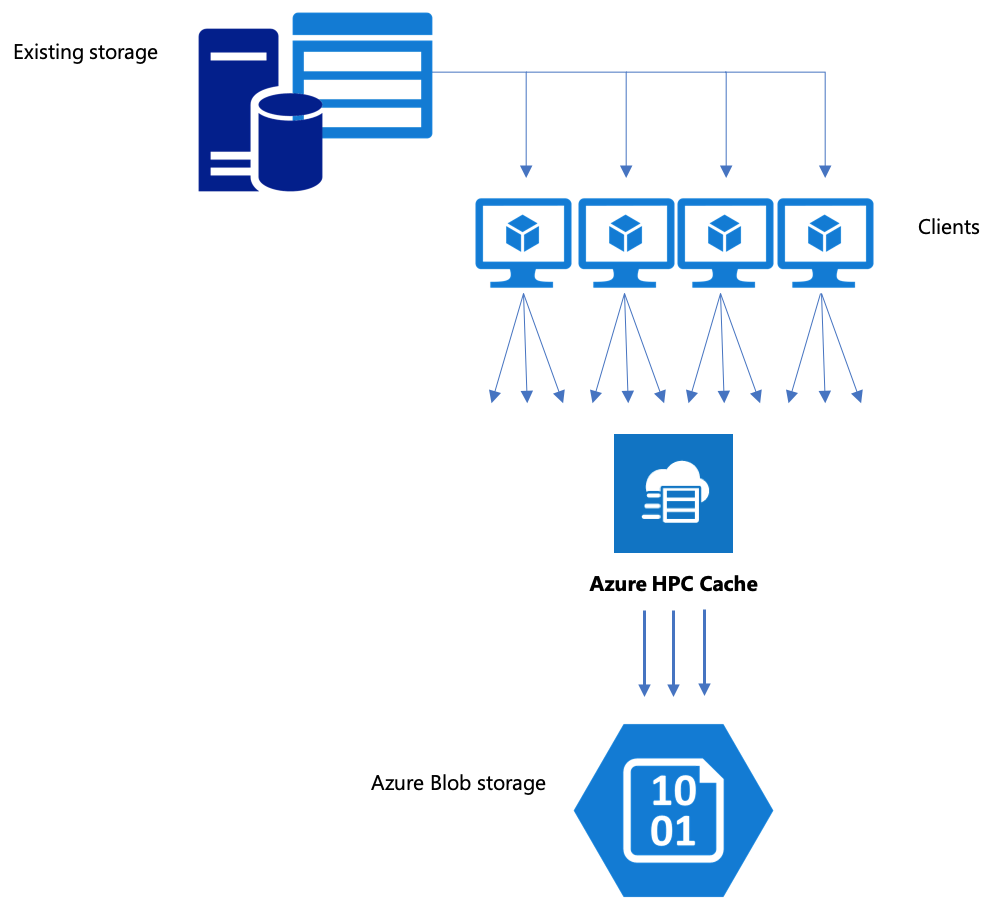
Azure Blob Storage へのデータの移動がワークフローに含まれる場合は、効率的な方法を使用していることを確認してください。 キャッシュを作成し、BLOB コンテナーをストレージ ターゲットとして追加してから、Azure HPC Cache を使用してデータをコピーする必要があります。
この記事では、Azure HPC Cache で使用する BLOB ストレージにデータを移動する最良の方法について説明します。
ヒント
この記事は、NFS でマウントされた BLOB ストレージ (ADLS-NFS ストレージ ターゲット) には適用されません。 HPC Cache に追加する前または後に、任意の NFS ベースの方法を使用して ADLS-NFS BLOB コンテナーにデータを設定できます。 詳細については、NFS プロトコルを使用したデータの事前読み込みに関するページを参照してください。
次の情報に留意してください。
Azure HPC Cache では、BLOB ストレージ内のデータを整理するために、専用のストレージ形式が使用されます。 このため、BLOB ストレージ ターゲットは、新しい空のコンテナーか、それまで Azure HPC Cache データに使用されていた BLOB コンテナーのいずれかにする必要があります。
バックエンドのストレージ ターゲットに Azure HPC Cache 経由でデータをコピーするのが最善の選択肢となるのは、複数のクライアントおよび並列操作を使用するときです。 1 つのクライアントからの単純なコピー コマンドでは、データの移動が低速になります。
この記事で説明する戦略は、空の BLOB コンテナーにデータを設定したり、以前に使用したストレージ ターゲットにファイルを追加したりする場合に有効です。
Azure HPC Cache 経由でデータをコピーする
Azure HPC Cache は、複数のクライアントからの要求を同時に処理するように設計されています。したがって、キャッシュ経由でデータをコピーするには、複数クライアントからの並列書き込みを使用する必要があります。
ストレージ システム間でデータを転送するためによく使われる cp または copy コマンドは、一度に 1 つのファイルだけをコピーするシングルスレッドのプロセスです。 つまり、一度に 1 つのファイルしかファイル サーバーに取り込まれません。これでは、キャッシュのリソースを浪費してしまいます。
このセクションでは、Azure HPC Cache の BLOB ストレージにデータを移動するための、マルチクライアント、マルチスレッドのファイル コピー システムを作成する方法について説明します。 複数のクライアントとシンプルなコピー コマンドを使ってデータを効率よくコピーするために使用できる、ファイル転送の概念と決定点について説明します。
便利なユーティリティについても説明します。 msrsync ユーティリティを使用すると、データセットを複数のバケットに分割したうえで rsync コマンドを使用するというプロセスを部分的に自動化できます。 もう 1 つ、parallelcp スクリプトというユーティリティがあります。これはソース ディレクトリを読み取り、自動的にコピー コマンドを発行するユーティリティです。
戦略的計画
データを並列コピーするための戦略を作成するときは、ファイルのサイズ、ファイルの数、ディレクトリの深さにおけるトレードオフを理解する必要があります。
- ファイルが小さいとき、注目すべきメトリックは 1 秒あたりのファイル数です。
- ファイルが大きい場合 (10 MiBi 以上)、注目すべきメトリックは 1 秒あたりのバイト数です。
コピー プロセスごとにスループット率とファイル転送された率が示されます。これらは、コピー コマンドの長さのタイミングを計り、ファイル サイズとファイル数を考慮することによって、測定できます。 それらの測定方法についての説明は、このドキュメントの範囲外ですが、小さいファイルを処理するのか、大きいファイルを処理するのかを把握することが不可欠です。
Azure HPC Cache を使用した並列データ取り込みには、次の方法があります。
手動コピー - クライアント上で、マルチスレッドのコピーを手動で作成できます。そのためには、定義済みのファイル セットまたはパスのセットに対して、一度に複数のコピー コマンドをバックグラウンドで実行します。 詳細については、Azure HPC Cache のデータ取り込み (手動でコピーする方法) に関するページを参照してください。
msrsyncを使用して部分的に自動化されたコピー -msrsyncは、複数の並列rsyncプロセスを実行するラッパー ユーティリティです。 詳細については、「Azure HPC Cache のデータ取り込み - msrsync を使用した方法」を参照してください。コピー スクリプト (
parallelcp) の使用 - 並列コピー スクリプトの作成と実行の方法については、「Azure HPC Cache のデータ取り込み - 並列コピー スクリプトを使用した方法」を参照してください。
次のステップ
ストレージのセットアップ後にクライアントからキャッシュをマウントする方法を確認しましょう。