チュートリアル 1: 信用リスクの予測 - Machine Learning Studio (クラシック)
適用対象: Machine Learning スタジオ (クラシック)
Machine Learning スタジオ (クラシック)  Azure Machine Learning
Azure Machine Learning
重要
Machine Learning Studio (クラシック) のサポートは、2024 年 8 月 31 日に終了します。 その日までに、Azure Machine Learning に切り替えすることをお勧めします。
2021 年 12 月 1 日以降、新しい Machine Learning Studio (クラシック) リソースは作成できません。 2024 年 8 月 31 日まで、既存の Machine Learning Studio (クラシック) リソースを引き続き使用できます。
- ML Studio (クラシック) から Azure Machine Learning への機械学習プロジェクトの移動に関する情報を参照してください。
- Azure Machine Learning についての詳細を参照してください
ML Studio (クラシック) のドキュメントは廃止予定であり、今後更新されない可能性があります。
このチュートリアルでは、予測分析ソリューションを開発するプロセスについて詳しく説明します。 Machine Learning Studio (クラシック) で単純なモデルを開発します。 その後、そのモデルを Machine Learning Web サービスとしてデプロイします。 このデプロイ モデルは、新しいデータを使用して予測を行うことができます。 このチュートリアルは、3 部構成のチュートリアル シリーズの第 1 部です。
クレジットの申請書に記入する情報に基づいて個人のクレジット リスクを予測する必要があるとします。
信用リスクの評価は複雑な問題ですが、このチュートリアルでは、それを少し簡略化してみます。 Machine Learning Studio (クラシック) を使用して予測分析ソリューションを作成する方法の例として使用してください。 このソリューションでは、Machine Learning Studio (クラシック) と Machine Learning Web サービスを使用します。
この 3 部構成のチュートリアルでは、まず、公表されている信用リスク データを使用します。 その後、予測モデルを開発してトレーニングします。 最後にそのモデルを Web サービスとしてデプロイします。
チュートリアルのこのパートでは、次のことを行います。
- Machine Learning Studio (クラシック) ワークスペースを作成する
- 既存のデータのアップロード
- 実験の作成
その後、この実験を使用してモデルをトレーニング (第 2部) し、それらをデプロイ (第 3 部) することができます。
前提条件
このチュートリアルでは、これまでに少なくとも 1 回は Machine Learning Studio (クラシック) を使用したことがあり、機械学習の概念をある程度理解していることを前提としています。 いずれにしても専門家ではないことを想定しています。
Machine Learning Studio (クラシック) をまだ使用したことがない場合は、クイックスタート: 「 Machine Learning Studio (クラシック) で初めてのデータ サイエンス実験を作成する」から始めることをお勧めします。 そのクイック スタートでは、Machine Learning Studio (クラシック) を初めて使用する場合の手順を示しながら、 実験にモジュールをドラッグ アンド ドロップして互いに結び付け、実験を実行して結果を確認する方法の基本について説明します。
ヒント
Azure AI Gallery には、このチュートリアルで開発する実験の作業コピーがあります。 「 チュートリアル - 信用リスクの予測 」にアクセスし、 [Studio で開く] をクリックして Machine Learning Studio (クラシック) ワークスペースに実験のコピーをダウンロードしてください。
Machine Learning Studio (クラシック) ワークスペースを作成する
Machine Learning Studio (クラシック) を使用するには、Machine Learning Studio (クラシック) ワークスペースが必要です。 このワークスペースには、実験を管理および公開するのに必要なツールが用意されています。
ワークスペースを作成するには、「Machine Learning Studio (クラシック) ワークスペースを作成して共有する」を参照してください。
ワークスペースが作成された後、Machine Learning Studio (クラシック) (https://studio.azureml.net/Home) を開きます。 ワークスペースが複数ある場合は、ウィンドウの右上隅のツールバーでワークスペースを選択できます。
ヒント
自分がワークスペースの所有者になっている場合は、自分以外のユーザーをワークスペースに招待することで、作業中の実験を共有することができます。 これは、Machine Learning Studio (クラシック) の [設定] ページから実行できます。 必要な情報は各ユーザーの Microsoft アカウントまたは組織アカウントだけです。
[設定] ページで [ユーザー] をクリックします。次に、ウィンドウの下部にある [INVITE MORE USERS] をクリックします。
既存のデータのアップロード
信用リスクの予測モデルを作成するには、トレーニングとその後のモデルのテストに使用できるデータが必要です。 このチュートリアルでは、UC Irvine Machine Learning Repository の "UCI Statlog (German Credit Data) Data Set" (UCI Statlog (ドイツの信用貸付データ) データ セット) を使用します。 詳細についてはこちらを参照してください:
https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)
german.data という名前のファイルを使用します。 このファイルをローカル ハード ドライブにダウンロードします。
この german.data データセットの行には、信用貸付の過去 1,000 人の申請者に関する 20 の変数が含まれています。 これらの 20 の変数は、データセットの特徴セット (特徴ベクトル) を表し、それぞれの信用貸付申請者を識別する特徴を提供します。 各行の追加の列は、申請者について計算された信用リスクを表し、700 人の申請者が低リスクとして、300 人が高リスクとして識別されています。
UCI Web サイトは、このデータの特徴ベクトルの属性についての詳細を提供します。 このデータには、財務情報、クレジット履歴、雇用状況、個人情報が含まれます。 各申請者について、申請者の信用リスクの高低を示す二項評価が与えられています。
このデータを使用して、予測分析モデルをトレーニングします。 完了したら、このモデルで新しい個人の特徴ベクトルを受け入れて、信用リスクの高低を予測できるようになります。
ここで興味深い展開になります。
UCI Web サイト上のデータセットの説明では、個人の信用リスクを誤って分類した場合のコストについて触れています。 モデルが実際には信用リスクが低い人を信用リスクが高いと予測すると、誤分類をしたことになります。
しかし逆の誤分類、つまり、モデルが実際には信用リスクが高い人を信用リスクが低いと予測する場合は、金融機関に 5 倍のコストがかかります。
そこで、モデルをトレーニングして、後者の場合の誤分類コストがもう一方の誤分類に比べて 5 倍になるようにします。
実験でモデルをトレーニングするときにこれを実行する簡単な方法の 1 つは、信用リスクが高い人を示すエントリを重複 (5 回) させることです。
そうすれば、実際には信用リスクが高い人を信用リスクが低い人としてモデルが誤分類を行うと、重複エントリごとに同じ誤分類が 5 回発生することになります。 これにより、トレーニング結果でこのエラーのコストが増加します。
データセットの形式の変換
元のデータセットは、空白で区切られた形式を使用しています。 Machine Learning Studio (クラシック) で使用するにはコンマ区切り値 (CSV) ファイルの方が適しているため、空白をコンマに置き換えてデータセットを変換します。
このデータを変換する方法は多数存在します。 1 つは、次の Windows PowerShell コマンドを使用する方法です。
cat german.data | %{$_ -replace " ",","} | sc german.csv
他に、次の Unix の sed コマンドを使用する方法もあります。
sed 's/ /,/g' german.data > german.csv
いずれの場合も、コンマ区切りに変換されたデータが、german.csv という名前のファイルに作成されます。このファイルは実験で使用できます。
Machine Learning Studio (クラシック) にデータセットをアップロードする
データを CSV 形式に変換したら、それを Machine Learning Studio (クラシック) にアップロードする必要があります。
Machine Learning Studio (クラシック) のホーム ページ (https://studio.azureml.net) を開きます。
ウィンドウの左上隅にあるメニュー
 をクリックします。 Azure Machine Learning をクリックし、Studio を選択してサインインします。
をクリックします。 Azure Machine Learning をクリックし、Studio を選択してサインインします。ウィンドウの下部にある [+新規] をクリックします。
[データセット] を選択します。
[ローカル ファイルから] を選択します。

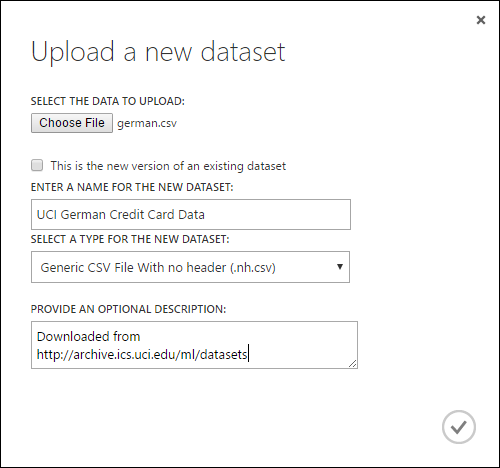
[新しいデータセットをアップロードする] ダイアログで、[参照] をクリックし、作成した german.csv ファイルを検索します。
データセットの名前を入力します。 このチュートリアルでは、「UCI German Credit Card Data」とします。
データ型として、 [ヘッダーなしの汎用 CSV ファイル (.nh.csv)] を選択します。
必要に応じて説明を追加します。
OK チェック マークをクリックします。
これにより、データは、実験で使用できるデータセット モジュールにアップロードされます。
Studio (クラシック) にアップロードしたデータセットは、Studio (クラシック) ウィンドウの左側にある [データセット] タブをクリックすることで管理できます。
その他の種類のデータの実験へのインポートの詳細については、Machine Learning Studio (クラシック) へのトレーニング データのインポートに関するページを参照してください。
実験の作成
このチュートリアルでの次の手順では、アップロードしたデータセットを使用する実験を Machine Learning Studio (クラシック) で作成します。
Studio (クラシック) で、ウィンドウの下部にある [+新規] をクリックします。
[実験] を選択して、[空の実験] を選択します。

キャンバスの上部にある既定の実験名を選択し、わかりやすい名前に変更します。

ヒント
実験のため、 [プロパティ] ウィンドウの [概要] と [説明] に入力することをお勧めします。 これらのプロパティを指定しておくと、実験を文書に残すことができるので、誰でも後から見て目標と手法を理解できます。

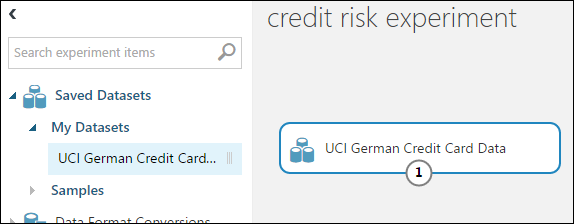
実験キャンバスの左側にあるモジュール パレットの [保存されたデータセット] を展開します。
作成したデータセットを [マイ データセット] から見つけて、キャンバスにドラッグします。 パレットの上にある [検索] ボックスに名前を入力してデータセットを見つけることもできます。
データを準備する
データの最初の 100 行とデータセット全体の統計情報を表示できます。データセットの出力ポート (下部の小さな円) をクリックし、 [視覚化] を選択します。
データ ファイルには列見出しがないため、Studio (クラシック) では汎用の見出し (Col1、Col2 "など") が付けられます。 適切な見出しはモデルを作成するために絶対に必要なものではありませんが、実験のデータを操作する際に便利です。 また、最終的にこのモデルを Web サービスに発行する際に、見出しは、サービスのユーザーが列を特定するのに役立ちます。
メタデータの編集モジュールを使用して、列見出しを追加できます。
メタデータの編集モジュールを使用して、データセットに関連付けられたメタデータを変更します。 この場合は、それを使用して、列見出しによりわかりやすい名前を付けます。
メタデータの編集を使用するには、まず変更する列 (ここではすべての列) を指定します。次に、それらの列に対して実行するアクション (このケースでは列見出しの変更) を指定します。
モジュール パレットの [検索] ボックスに「メタデータ」と入力します。 モジュールの一覧に、メタデータの編集が表示されます。
メタデータの編集モジュールをクリックしてキャンバスにドラッグし、先ほど追加したデータセットの下にドロップします。
データセットをメタデータの編集に接続します。データセットの出力ポート (データセット下部の小さな円) をクリックし、メタデータの編集の入力ポート (モジュール上部の小さな円) の上にドラッグしてからマウス ボタンを放します。 これで、マウスをキャンバス上でどこに移動しても、データセットとモジュールが接続されたままになります。
実験は以下のようになっているはずです。

赤色の感嘆符は、このモジュールのプロパティがまだ設定されていないことを示します。 これは次に行います。
ヒント
モジュールをダブルクリックして、テキストを入力すると、モジュールにコメントを追加できます。 これで、実験でモジュールがどのような処理をするのかがひとめでわかります。 ここでは、メタデータの編集モジュールをダブルクリックし、「列見出しの追加」というコメントを入力します。 テキスト ボックスを閉じるには、キャンバスの任意の場所をクリックします。 コメントを表示するには、モジュールの下向き矢印をクリックします。
メタデータの編集を選択し、キャンバスの右側にある [プロパティ] ウィンドウで [列セレクターの起動] をクリックします。
[列の選択] ダイアログで、[使用可能な列] のすべての列を選択して [>] をクリックし、[選択した列] に移します。 ダイアログは次のようになります。

OK チェック マークをクリックします。
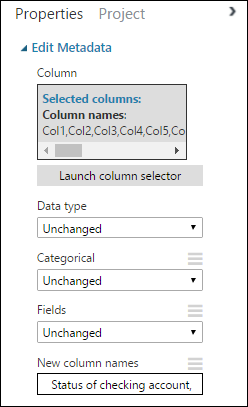
[プロパティ] ウィンドウに戻り、 [新しい列名] パラメーターを探します。 このフィールドには、コンマ区切りで列の順番どおりに、データセットの 21 列分の名前を入力します。 列名は、UCI Web サイトのデータセットに関するドキュメントから入手できます。または、次の一覧をコピーして貼り付けることができます。
Status of checking account, Duration in months, Credit history, Purpose, Credit amount, Savings account/bond, Present employment since, Installment rate in percentage of disposable income, Personal status and sex, Other debtors, Present residence since, Property, Age in years, Other installment plans, Housing, Number of existing credits, Job, Number of people providing maintenance for, Telephone, Foreign worker, Credit risk[プロパティ] ウィンドウは次のようになります。
トレーニング用およびテスト用のデータセットを作成する
モデルのトレーニング用とテスト用にデータが必要です。 そのため、実験の次の手順では、データセットを 2 つの別々のデータセットに分割します。1 つはモデルのトレーニング用、もう 1 つはテスト用です。
これを行うには、データの分割モジュールを使用します。
既定では、分割比が 0.5 で、 [ランダム分割] パラメーターが設定されます。 これは、データの半分がランダムに抽出されてデータの分割モジュールの 1 つのポートから出力され、残りの半分がもう 1 つのポートから出力されることを意味します。 これらのパラメーターと [ランダム シード] パラメーターを調整して、トレーニング データとテスト データの分割比を変更できます。 この例では、これらをそのままにしておきます。
ヒント
左の出力ポートから出力されるデータの量は、 [Fraction of rows in the first output dataset] (最初の出力データセットにおける列の割合) プロパティによって決まります。 たとえば、比率を 0.7 に設定すると、データの 70% が左側のポートから、30% が右側のポートから出力されます。
データの分割モジュールをダブルクリックし、「トレーニング/テスト データの分割 50%」とコメントを入力します。
データの分割モジュールの出力の用途は自由ですが、ここでは左側の出力をトレーニング データ、右側の出力をテスト データとして使用します。
前の手順での説明のとおり、高い信用リスクを誤って低リスクと分類すると、低い信用リスクを誤って高リスクと分類した場合の 5 倍のコストが発生します。 これに対応するため、このコストの特徴を反映した新しいデータセットを生成します。 この新しいデータセットでは、高リスクの例を 5 回重複させ、低リスクの例は重複させません。
この重複は、R コードを使用して実行できます。
R スクリプトの実行モジュールを見つけ、実験キャンバスにドラッグします。
データの分割モジュールの左側の出力ポートを R スクリプトの実行モジュールの 1 つ目の入力ポート ("Dataset1") に接続します。
R スクリプトの実行モジュールをダブルクリックし、「コスト調整の設定」というコメントを入力します。
[プロパティ] ウィンドウの [R スクリプト] パラメーターの既定の文字列を削除し、以下のスクリプトを入力します。
dataset1 <- maml.mapInputPort(1) data.set<-dataset1[dataset1[,21]==1,] pos<-dataset1[dataset1[,21]==2,] for (i in 1:5) data.set<-rbind(data.set,pos) maml.mapOutputPort("data.set")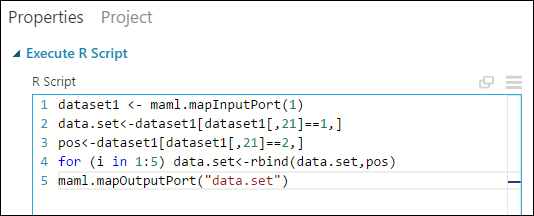
データの分割モジュールの各出力について同様の重複操作を設定する必要があります。これによって、トレーニング データとテスト データのコスト調整が等しくなります。 これを実行する最も簡単方法は、作成したばかりの R スクリプトの実行モジュールを複製して、データの分割モジュールのもう 1 つの出力ポートに接続することです。
R スクリプトの実行モジュールを右クリックし、 [コピー] を選択します。
実験キャンバスを右クリックして [貼り付け] を選択します。
新しいモジュールを適切な位置にドラッグし、データの分割モジュールの右側の出力ポートを、この新しい R スクリプトの実行モジュールの 1 つ目の入力ポートに接続します。
キャンバスの下部で、 [実行] をクリックします。
ヒント
R スクリプトの実行モジュールのコピーには、元のモジュールと同じスクリプトが格納されています。 モジュールをコピーしてキャンバスに貼り付けた場合、モジュールのコピーには元のモジュールのすべてのプロパティが保持されています。
現在、実験は以下のようになっているはずです。

実験での R スクリプトの使用に関する詳細については、「R を使用した実験の拡張」をご覧ください。
リソースをクリーンアップする
この記事を使用して作成したリソースが不要になった場合は、料金の発生を避けるために削除してください。 方法については、製品内ユーザー データのエクスポートと削除に関するページを参照してください。
次のステップ
このチュートリアルでは、次の手順を完了しました。
- Machine Learning Studio (クラシック) ワークスペースを作成する
- ワークスペースへの既存のデータのアップロード
- 実験の作成
これで、このデータのモデルをトレーニングして評価する準備が整いました。