クイックスタート: 垂直統合 (プレビュー)
重要
[データのインポートとベクトル化] ウィザードは、追加使用条件の下でパブリック プレビューの段階にあります。 対象は、2023-10-01-Preview REST API です。
Azure portal の [データのインポートとベクトル化] ウィザードを使って、垂直統合 (プレビュー) を開始します。 このウィザードは、インデックス作成中とクエリのためにコンテンツをベクトル化するために、Azure OpenAI テキスト埋め込みモデルを呼び出します。
このプレビュー バージョンのウィザードでは、次の操作を行います。
ソース データは BLOB のみであり、既定の解析モード (BLOB ごとに 1 つの検索ドキュメント) を使用します。
インデックス スキーマは構成できません。 ソース フィールドには、
content(チャンクおよびベクトル化)、タイトルのmetadata_storage_name、インデックスのparent_idとして入力されるドキュメント キーのmetadata_storage_pathが含まれます。ベクトル化は Azure OpenAI のみ (text-embedding-ada-002) であり、HNSW アルゴリズムを既定値で使います。
チャンクは構成できません。 有効な設定は次のとおりです。
textSplitMode: "pages", maximumPageLength: 2000, pageOverlapLength: 500
前提条件
Azure サブスクリプション。 無料で作成できます。
任意のリージョンおよび任意のレベルの Azure AI Search。 既存のサービスのほとんどではベクトル検索がサポートされています。 2019 年 1 月より前に作成されたサービスの小さなサブセットでは、ベクトル フィールドを含むインデックスの作成に失敗します。 このような場合は、新しいサービスを作成する必要があります。
Azure OpenAI エンドポイントに加え、text-embedding-ada-002 のデプロイ、データをアップロードするための API キーまたは Cognitive Services OpenAI ユーザー権限。 このプレビューでは 1 つのベクトル化のみを選択でき、そのベクトル化は Azure OpenAI である必要があります。
Azure Storage アカウント、標準パフォーマンス (汎用 v2)、ホット アクセス層、クール アクセス層。
テキスト コンテンツ、非構造化ドキュメントのみ、およびメタデータを提供する BLOB。 このプレビューでは、データ ソースは Azure BLOB である必要があります。
Azure Storage での読み取りアクセス許可。 アクセス キーを含むストレージ接続文字列は、ストレージ コンテンツへの読み取りアクセスが許可されます。 代わりに、Microsoft Entra ログインとロールを使用している場合は、検索サービスのマネージド ID にストレージ BLOB データ閲覧者のアクセス許可があることを確認してください。
ポータル ノードがアクセスできるようにするには、すべてのコンポーネント (データ ソースと埋め込みエンドポイント) でパブリック アクセスが有効になっている必要があります。 そうでないと、ウィザードは失敗します。 ウィザードの実行後、さまざまな統合コンポーネントでファイアウォールとプライベート エンドポイントを有効にしてセキュリティを確保することができます。 プライベート エンドポイントが既に存在し、無効にできない場合は、プライベート エンドポイントと同じ VNET 内の仮想マシンから、スクリプトまたはプログラムのそれぞれのエンド ツー エンド フローを実行することもできます。 垂直統合の Python コード サンプルを次に示します。 同じ GitHub リポジトリには、他のプログラミング言語のサンプルがあります。
領域の確認
多くのユーザーが最初に利用するのは、無料版のサービスです。 Free レベルでは、インデックス、データ ソース、スキルセット、インデクサーがそれぞれ 3 つに制限されています。 十分な空き領域があることを確認してから開始してください。 このクイックスタートでは、各オブジェクトを 1 つずつ作成します。
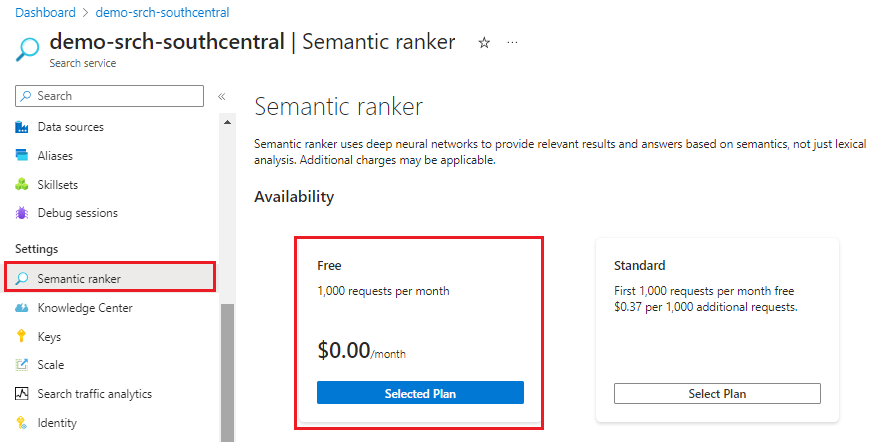
セマンティック ランク付けを確認する
Basic レベル以上であり、さらにセマンティック ランク付けが既に検索サービスで有効である場合にのみ、このウィザードはセマンティック ランク付けをサポートします。 課金対象レベルを使っている場合は、セマンティック ランク付けが有効かどうかを確認します。
サンプル データの準備
このセクションでは、このクイックスタートで機能するデータについて説明します。
Azure アカウントを使用して Azure portal にサインインし、Azure Storage アカウントに移動します。
ナビゲーション ウィンドウの [データ ストレージ] で [コンテナー] を選択します。
新しいコンテナーを作成し、このクイックスタートで使用する正常性プラン PDF ドキュメントをアップロードします。
ロールベースのアクセス権が必要な場合には、Azure portal で Azure Storage アカウントを終了する前に、コンテナーにストレージ BLOB データ閲覧者のアクセス許可を付与します。 または、[アクセス キー] ページからストレージ アカウントへの接続文字列を取得します。
Azure OpenAI の接続の詳細を取得する
ウィザードには、エンドポイント、text-embedding-ada-002 のデプロイ、および API キーまたは Cognitive Services OpenAI ユーザー権限を持つ検索サービス マネージド ID が必要です。
Azure アカウントを使用して Azure portal にサインインし、Azure OpenAI リソースに移動します。
[キーと管理] で、エンドポイントをコピーします。
同じページで、キーをコピーするか、[アクセス制御] をオンにして、ロール メンバーを検索サービス ID に割り当てます。
[モデル デプロイ] で、[デプロイの管理] を選択して Azure AI Studio を開きます。 text-embedding-ada-002 のデプロイ名をコピーします。
ウィザードを起動する
開始するには、Azure portal で Azure AI Search サービスを参照し、[データのインポートとベクトル化] ウィザードを開きます。
Azure アカウントを使用して Azure portal にサインインし、Azure AI Search サービスに移動します。
[概要] ページで、[データのインポートとベクトル化] を選択します。

データへの接続
次の手順では、検索インデックスに使用するデータ ソースに接続します。
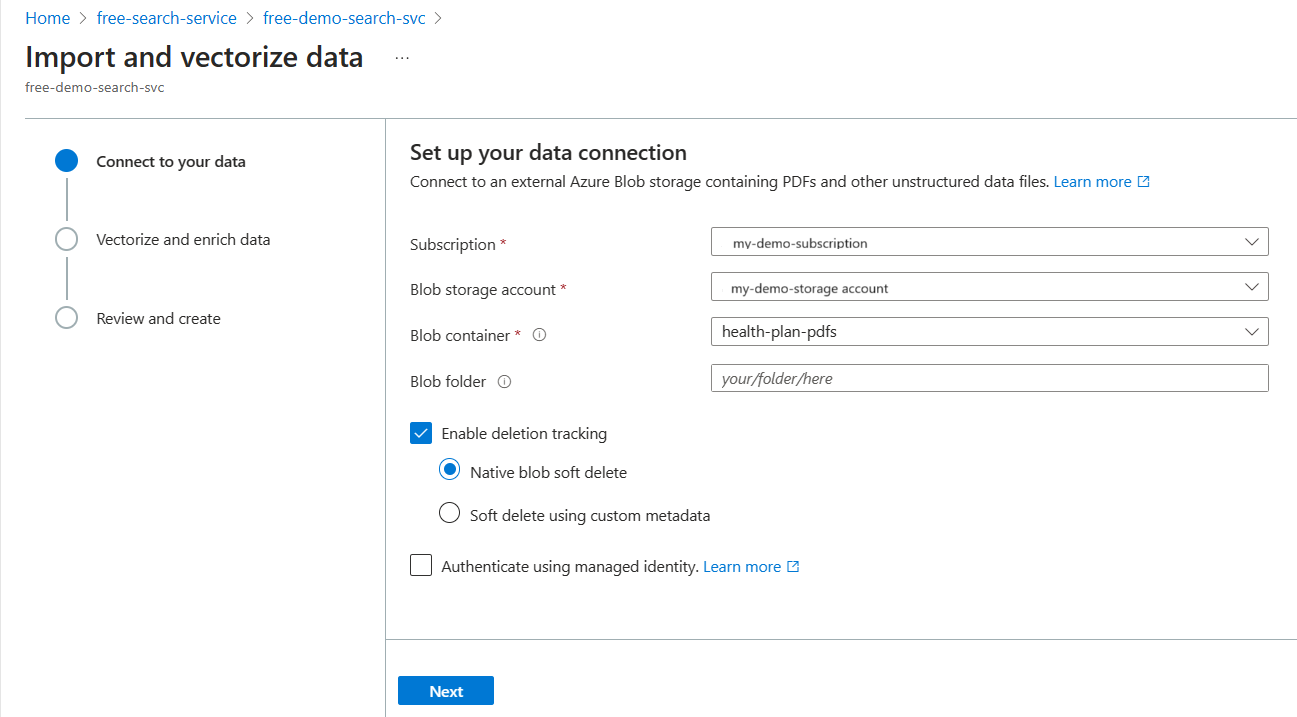
[データのインポートとベクトル化] ウィザードの [データへの接続] タブで、[データ ソース] ドロップダウン リストを展開し、[Azure Blob Storage] を選びます。
データを提供する Azure サブスクリプション、ストレージ アカウント、コンテナーを指定します。
接続については、キーを含むフル アクセス接続文字列を指定するか、コンテナーに対しストレージ BLOB データ閲覧者権限を持つマネージド ID を指定します。
削除検出をするかどうかは次のように指定します。
[次へ: ベクトル化とエンリッチ] を選択して次に移ります。
データのエンリッチとベクトル化
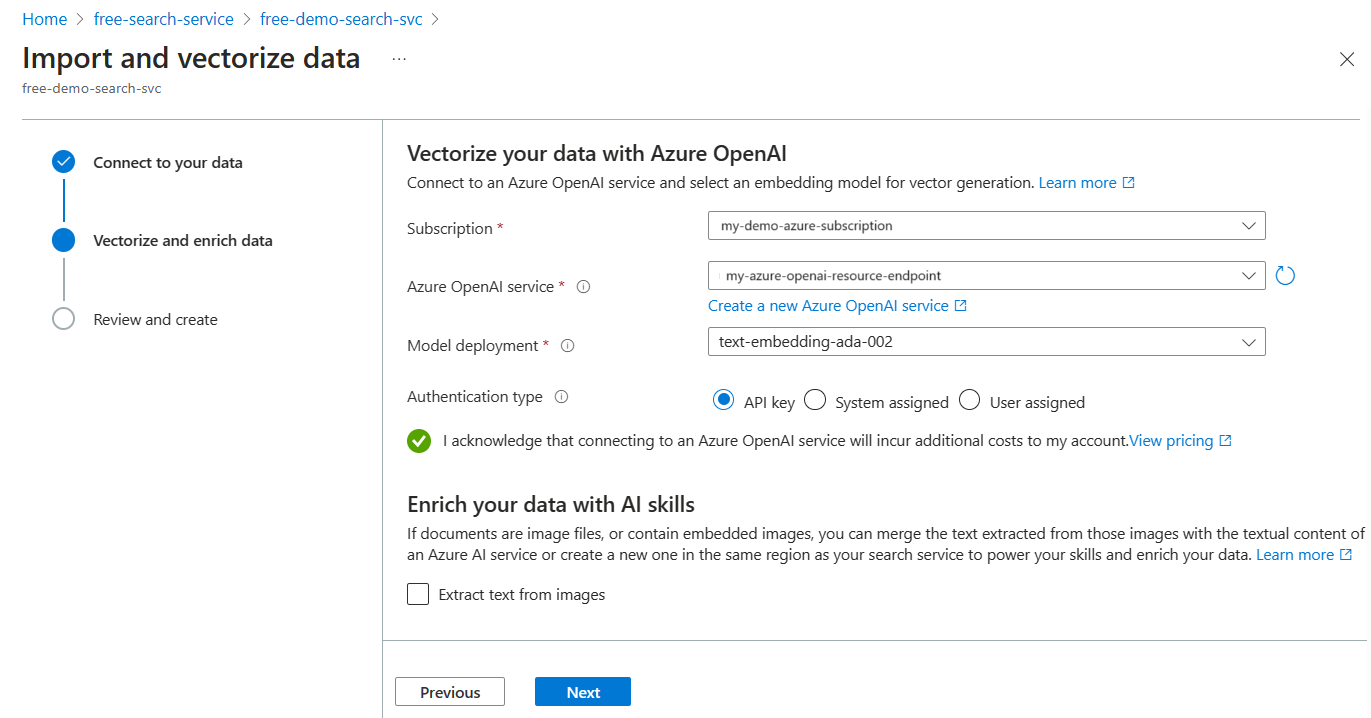
このステップでは、チャンク データのベクトル化に使用する埋め込みモデルを指定します。
サブスクリプション、エンドポイント、API キー、およびモデル デプロイ名を指定します。
必要に応じて、バイナリ画像 (スキャンしたドキュメント ファイルなど) を使用したり、OCR を使用してテキストを認識したりできます。
必要に応じて、セマンティック ランク付けを追加して、クエリ実行の最後に結果を再ランク付けし、最も意味的に関連性の高い一致を上位に昇格させることができます。
インデクサーの実行スケジュールを指定します。
[次へ: 作成と確認] を選択して次に移ります。
ウィザードの実行
このステップでは、次のオブジェクトを作成します。
BLOB コンテナーへのデータ ソース接続。
ベクトル フィールド、ベクタライザー、ベクトル プロファイル、ベクトル アルゴリズムを含むインデックス。 ウィザードのワークフロー中には、既定のインデックスを設計または変更するように求められることはありません。 インデックスは 2023-10-01-Preview バージョンに適合しています。
チャンクのためのテキスト分割スキルおよびベクトル化のための AzureOpenAIEmbeddingModel を備えたスキルセット。
フィールド マッピングおよび出力フィールド マッピングを備えたインデクサー (該当する場合)。
エラーが発生した場合は、まずアクセス許可を確認します。 Azure OpenAI では Cognitive Services OpenAI ユーザー、Azure Storage ではストレージ BLOB データ閲覧者が必要です。 BLOB は非構造化である必要があります (チャンク データは BLOB の "content" プロパティからプルされます)。
結果をチェックする
検索エクスプローラーは、テキスト文字列を入力として受け入れ、ベクトル クエリの実行のためにテキストをベクトル化します。
インデックスを選択します。
必要に応じて [クエリ オプション] を選び、検索結果のベクトル値を非表示にします。 この手順により、検索結果が読みやすくなります。
![[クエリ オプション] ボタンのスクリーンショット。](media/search-get-started-portal-import-vectors/query-options.png)
[JSON ビュー] を選ぶと、text ベクトル クエリ パラメーターにベクトル クエリのテキストを入力できます。
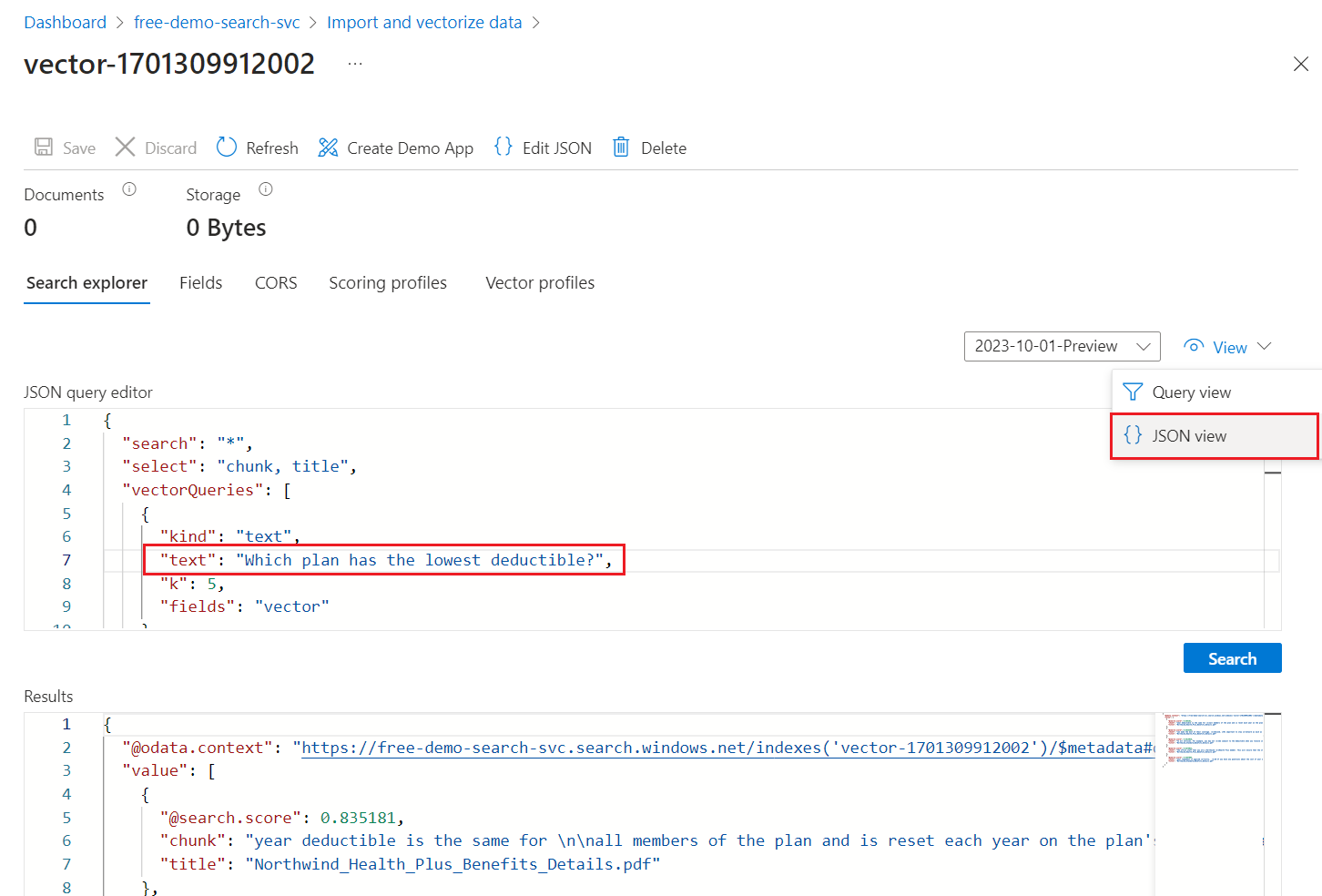
このウィザードには、"vector" フィールドに対してベクトル クエリを発行し、5 つのニアレスト ネイバーを返す既定のクエリが用意されています。 ベクトル値を非表示にすることを選んだ場合、既定のクエリには、検索結果から vector フィールドを除外する "select" ステートメントが含まれます。
{ "select": "chunk_id,parent_id,chunk,title", "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "vector" } ] }テキスト
"*"を、「どのプランの控除額が最も低いですか」などの医療プランに関連する質問に置き換えます。[検索] を選んでクエリを実行します。
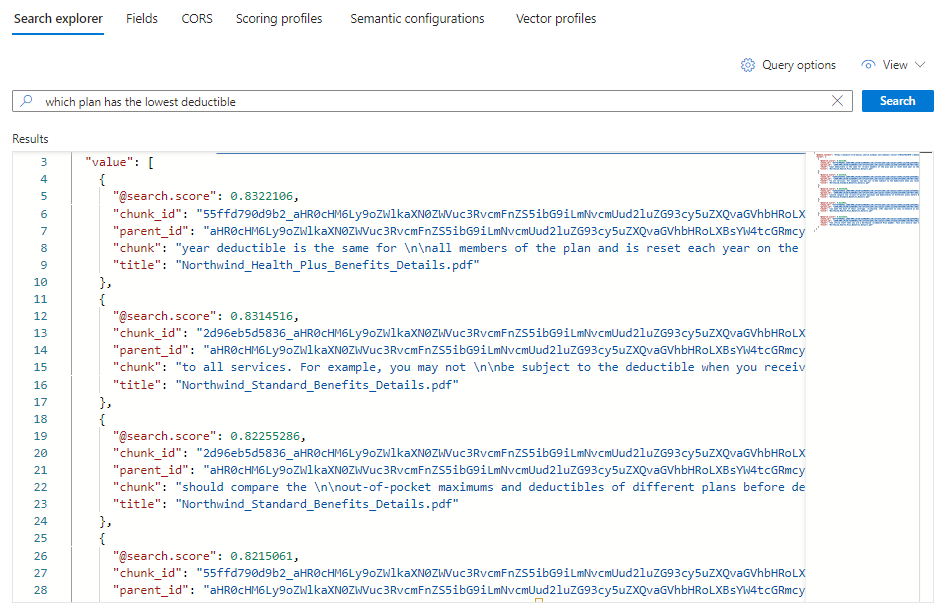
5 つの一致が表示されます。各ドキュメントは元の PDF のチャンクです。 タイトル フィールドには、チャンクの取得元の PDF が表示されます。
特定のドキュメントのすべてのチャンクを表示するには、特定の PDF の title フィールドにフィルターを追加します。
{ "select": "chunk_id,parent_id,chunk,title", "filter": "title eq 'Benefit_Options.pdf'", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "vector" } ] }
クリーンアップ
Azure AI Search は課金対象のリソースです。 不要になった場合は、課金されないようにサブスクリプションから削除してください。
次のステップ
このクイックスタートでは、垂直統合に必要なすべてのオブジェクトを作成する [データのインポートとベクトル化] ウィザードを紹介しました。 各手順について詳しく確認するには、垂直統合サンプルを試してください。