Azure AI Search のデータのインポート ウィザード
Azure portal のデータのインポート ウィザードで、検索サービスでのインデックス作成や AI エンリッチメントに使用される複数のオブジェクトを作成します。 Azure AI Search を初めて使用する場合、お客様にとって自由に使える最も強力な機能の 1 つとなります。 Azure AI Search のほとんどの機能を実行できる、インデックスや強化パイプラインを最小限の労力で作成できます。
概念実証のテストにウィザードを使用する際、これをより効果的に使用できるように、この記事ではウィザードの内部動作について説明します。
この記事では、ステップ バイ ステップでは説明しません。 組み込みのサンプル データでウィザードを使用する方法については、検索インデックスの作成に関するクイックスタートまたはテキスト翻訳とエンティティ スキルセットの作成に関するクイックスタートを参照してください。
ウィザードの開始
Azure portal でダッシュボードから検索サービス ページを開くか、サービスの一覧でご自分のサービスを見つけます。 上部にあるサービスの概要ページで、[データのインポート] を選択します。

ウィザードがブラウザー ウィンドウで完全に展開され、作業するための領域が増えます。
[Import data (データのインポート)] は、Azure Cosmos DB、Azure SQL Database、SQL Managed Instance、Azure Blob Storage を含む、他の Azure サービスから起動することもできます。 サービスの概要ページの左側にあるナビゲーション ウィンドウで、[Add Azure AI Search] (Azure AI Search の追加) を見つけます。
ウィザードで作成されるオブジェクト
次の表のオブジェクトが出力されます。 オブジェクトが作成されたら、ポータルで JSON 定義を確認したり、コードから呼び出したりすることができます。
| オブジェクト | 説明 |
|---|---|
| Indexer | データ ソース、ターゲット インデックス、オプションのスキルセット、オプションのスケジュール、およびエラー処理と Base-64 エンコード用のオプションの構成設定を指定する構成オブジェクトです。 |
| データ ソース | Azure でサポートされるデータ ソースに対する接続情報を保持します。 データ ソース オブジェクトは、インデクサーでのみ使用されます。 |
| インデックス | フルテキスト検索やその他のクエリに使用される物理データ構造です。 |
| スキルセット | 省略可能。 画像ファイルからの情報の分析と抽出を含む、コンテンツの操作、変換、および整形を行うための手順の完全なセットです。 作業量が 1 インデクサーで 1 日 あたり 20 トランザクションの制限に収まらない場合、スキルセットにはエンリッチメントを提供する Azure AI マルチサービス リソースへの参照を含める必要があります。 |
| ナレッジ ストア | 省略可能。 AI エンリッチメント パイプラインからの出力を、独立した分析またはダウンストリーム処理用に Azure Storage テーブルと BLOB に保存します。 |
特典と制限
コードを記述する前に、このウィザードをプロトタイプ作成と概念実証テストに使用できます。 ウィザードでは、外部データ ソースに接続し、データをサンプリングして初期インデックスを作成します。次に、データを JSON ドキュメントとして Azure AI Search のインデックスにインポートします。
スキルセットを評価する場合、ウィザードですべての出力フィールド マッピングを処理し、使用可能なオブジェクトを作成するヘルパー関数を追加します。 解析モードを指定すると、テキストの分割が追加されます。 ウィザードで画像コンテンツとテキストの説明を再結合できるように、画像分析を選択すると、テキストの結合が追加されます。 ナレッジ ストア オプションを選択した場合に有効なプロジェクションをサポートする Shaper スキルが追加されました。 上記のすべてのタスクには学習曲線が付きます。 エンリッチメントを初めて使用する場合は、これらの手順を処理させる機能により、時間と労力を費やすことなく、スキルの価値を測定できます。
サンプリングはインデックス スキーマを推論するプロセスであり、これには制限がいくつかあります。 データ ソースが作成されると、ウィザードによってドキュメントのサンプルがランダムに選択され、データ ソースの一部である列が決定されます。 非常に大規模なデータ ソースの場合はこの処理に時間がかかる可能性があるため、すべてのファイルが読み取られるわけではありません。 ドキュメントが選択されると、フィールド名や種類などのソース メタデータを使用して、インデックス スキーマにフィールド コレクションが作成されます。 ソース データの複雑さに応じて、正確さを求めて初期スキーマを編集したり、完全を期すために拡張したりすることが必要になる場合があります。 インデックスの定義のページで、変更をインラインで行うことができます。
概して、ウィザードを使用する利点は明らかです。要件が満たされていれば、数分以内にクエリ可能なインデックスのプロトタイプを作成できます。 JSON ドキュメントとしてのデータのシリアル化など、インデックス作成の複雑な処理の一部は、ウィザードによって行われます。
このウィザードには、制限がないわけではありません。 制約は次のとおりです。
このウィザードでは、イテレーションと再利用はサポートされていません。 ウィザードをパススルーするたびに、新しいインデックス、スキルセット、およびインデクサー構成が作成されます。 ウィザード内で保持および再利用できるのは、データ ソースのみです。 他のオブジェクトを編集または調整するには、オブジェクトを削除してからやり直すか、REST API または .NET SDK を使用して構造体を変更します。
ソース コンテンツは、サポートされているデータ ソース内にある必要があります。
サンプリングは、ソース データのあるサブセットについて行われます。 大規模なデータ ソースの場合、ウィザードでフィールドが見逃される可能性があります。 サンプリングが不十分な場合は、スキーマを拡張するか、推論されたデータ型を修正することが必要になる場合があります。
ポータルで公開されている AI エンリッチメントは、組み込みのスキルのサブセットに限定されています。
ウィザードで作成できるナレッジ ストアは、いくつかの既定のプロジェクションに限定され、既定の名前付け規則が使用されます。 名前またはプロジェクションをカスタマイズする場合は、REST API または SDK を使用してナレッジ ストアを作成する必要があります。
パブリック アクセスが無効になっている場合、セットアップ中にポータルからデータ ソースにアクセスできないため、ウィザードの使用中は、サポートされているすべてのネットワークへのパブリック アクセスが有効になっている必要があります。 つまり、データ ソースでファイアウォールが有効になっている場合、または共有プライベート リンクを設定している場合は、それらを無効にし、データのインポート ウィザードを実行してから、ウィザードのセットアップが完了した後でそれを有効にする必要があります。 これを行うことができない場合は、REST API または SDK を使用して、Azure AI Search のデータ ソース、インデクサー、スキルセット、インデックスを作成できます。
ワークフロー
このウィザードは、次の主な 4 つの手順で構成されています。
サポートされている Azure データ ソースに接続します。
ソース データのサンプリングによって推論されるインデックス スキーマを作成します。
必要に応じて、内容と構造を抽出または生成する AI エンリッチメントを追加します。 ナレッジ ストアを作成するための入力は、この手順で収集されます。
ウィザードを実行して、オブジェクトの作成、データの読み込み、スケジュールやその他の構成オプションの設定を行います。
ワークフローはパイプラインであるため、一方向となります。 作成したどのオブジェクトもウィザードを使用して編集することはできませんが、更新が許可されている場合は、インデックスやインデクサー デザイナーなどの他のポータル ツール、または JSON エディターを使用することができます。
ウィザードでのデータ ソースの構成
データのインポート ウィザードは、Azure AI Search インデクサーによって提供される内部ロジックを使用して外部のサポートされるデータ ソースに接続します。Azure AI Search インデクサーは、ソースのサンプリング、メタデータの読み取り、内容と構造を読み取るためのドキュメントの解読の機能を備え、その後の Azure AI Search へのインポートのために JSON として内容をシリアル化することもできます。
別のサブスクリプションまたはリージョンでサポートされているデータ ソースに対する接続を貼り付けることができますが、[既存の接続を選択します] ピッカーはアクティブなサブスクリプションが対象になります。
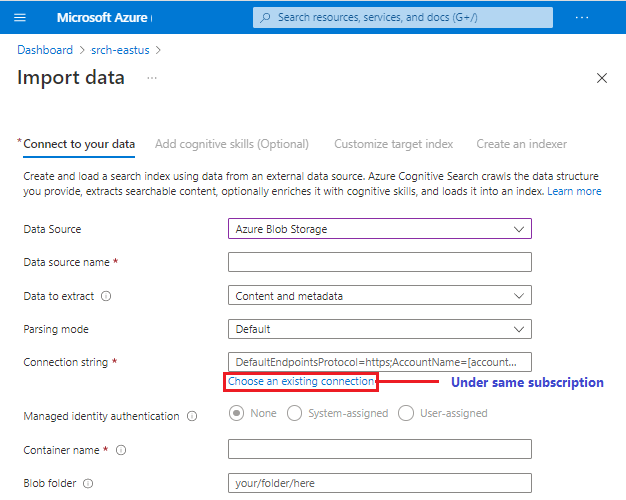
すべてのプレビュー データ ソースがウィザードで使用できることが保証されているわけではありません。 各データ ソースには、他の変更を下流に導入する可能性があるため、スキルセット定義やインデックス スキーマ推論など、ウィザードのすべてのエクスペリエンスを完全にサポートしている場合にのみ、データ ソースの一覧にプレビューのデータ ソースが追加されます。
インポート元として指定できるのは、単一のテーブル、データベース ビュー、または同等のデータ構造体のみですが、構造体には、階層または入れ子になったのサブ構造体を含めることができます。 詳細については、複合型のモデル化の方法に関するページを参照してください。
ウィザードでのスキルセットの構成
データ ソースの種類によって特定の組み込みのスキルが使用可能かどうかが通知されるため、データ ソース定義の後にスキルセットの構成が行われます。 特に、Blob Storage からファイルのインデックスを作成する場合、これらのファイルの解析モードの選択によって、感情分析を使用できるかどうかが決まります。
選択したスキルがウィザードによって追加されますが、正常な結果を得るために必要なその他のスキルも追加されます。 たとえば、ナレッジ ストアを指定した場合、ウィザードによって、プロジェクション (または物理データ構造) をサポートするための Shaper スキルが追加されます。
スキルセットはオプションなので、AI エンリッチメントが不要な場合は、ページの下部にあるボタンを使用してスキップすることができます。
ウィザードでのインデックス スキーマの構成
ウィザードによってデータ ソースがサンプリングされ、フィールドとフィールドの種類が検出されます。 データ ソースによっては、メタデータのインデックスを作成するためのフィールドが用意されている場合もあります。
サンプリングは不正確な演習であるため、次の考慮事項についてインデックスを確認してください。
フィールドの一覧は正確ですか。 データ ソースにサンプリングで含められなかったフィールドがある場合、サンプリングされなかった新しいフィールドを手動で追加し、検索エクスペリエンスに値を追加しないものと、フィルター式にもスコアリング プロファイルにも使用されないものをすべて削除できます。
データ型は受信データに適していますか。 Azure AI Search では、Entity Data Model (EDM) データ型がサポートされています。 Azure SQL データについては、同等の値を示しているマッピング表があります。 詳細な背景については、フィールドのマッピングと変換に関する記事をご覧ください。
"キー" として使用できるフィールドが 1 つありますか。 このフィールドは、Edm.string でなければならず、ドキュメントを一意に識別する必要があります。 リレーショナル データの場合は、主キーにマップされていることがあります。 BLOB の場合、
metadata-storage-pathであることがあります。 フィールドの値に空白またはダッシュが含まれている場合は、インデクサーの作成手順の [詳細オプション] で [Base-64 エンコード キー] オプションを設定し、これらの文字の検証チェックを抑制する必要があります。属性を設定して、インデックスでのこのフィールドの使用方法を指定します。
インデックス内のフィールドの物理的な表現が属性によって決定されるため、この手順に時間をかけてください。 後で属性を変更するときは、プログラムで行う場合も、ほとんどの場合にインデックスを削除して再構築する必要があります。 Searchable や Retrievable などのコア属性では、ストレージへの影響は無視できる程度です。 フィルターを有効にして suggester を使用すると、ストレージの要件が増えます。
Searchable では、全文検索が有効になります。 自由形式のクエリまたはクエリ式で使用されるすべてのフィールドに、この属性が必要です。 Searchable としてマークしたフィールドごとに、逆インデックスが作成されます。
Retrievable の場合、検索結果にフィールドが返されます。 検索結果にコンテンツを提供するすべてのフィールドに、この属性が必要です。 このフィールドを設定しても、インデックス サイズに大きな影響はありません。
Filterable は、フィルター式でフィールドを参照できるようにします。 $filter 式で使用されるすべてのフィールドに、この属性が必要です。 このフィルター式は完全一致用です。 テキスト文字列はそのまま残るため、逐語的なコンテンツに対応するには、追加のストレージが必要です。
Facetable は、ファセット ナビゲーションにフィールドを使用できるようにします。 Filterable としてもマークされているフィールドのみを、Facetable としてマークできます。
Sortable は、並べ替えでフィールドを使用できるようにします。 $Orderby 式で使用されるすべてのフィールドに、この属性が必要です。
字句解析が必要ですか。 Searchable である Edm.string フィールドの場合、言語拡張インデックス作成とクエリの実行が必要な場合は、アナライザーを設定できます。
既定値は標準 Lucene ですが、不規則名詞や動詞形式の解決など、高度な字句処理のために Microsoft のアナライザーを使用する必要がある場合は、Microsoft の英語を選択できます。 ポータルでは、言語アナライザーのみを指定できます。 カスタム アナライザーや、キーワード、パターンなどの非言語アナライザーを使用する場合は、プログラムで実行する必要があります。 アナライザーの詳細については、言語アナライザーの追加に関する記事をご覧ください。
オートコンプリートまたは候補の結果の形式の先行入力機能が必要ですか。 [Suggester] チェックボックスを選択し、選択したフィールドで先行入力クエリ候補とオートコンプリートを有効にします。 suggester は、インデックス内のトークン化された用語の数を増加させるため、より多くのストレージを消費します。
ウィザードでのインデクサーの構成
ウィザードの最後のページでは、インデクサーの構成に関するユーザー入力が収集されます。 スケジュールを指定したり、データ ソースの種類によって異なるその他のオプションを設定したりできます。
内部的には、次の定義もウィザードによって設定されます。これらの定義は作成されるまでインデクサーに表示されません。
- データ ソースとインデックスの間のフィールド マッピング
- スキルの出力とインデックスの間の出力フィールド マッピング
次のステップ
ウィザードの利点と制限事項を理解する最善の方法は、これを段階を追って実行することです。 次のクイック スタートでは、それぞれの手順について説明します。