チュートリアル:.NET SDK を使用して Azure SQL データにインデックスを付ける
Azure SQL Database から検索可能なデータを抽出し、それを Azure AI Search の検索インデックスに送信するようにインデクサーを構成します。
このチュートリアルでは、C# と Azure SDK for .NET を使用して次のタスクを実行します。
- Azure SQL Database に接続するデータ ソースを作成する
- インデクサーの作成
- インデクサーを実行してインデックスにデータを読み込む
- 検証ステップとしてインデックスを照会する
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
前提条件
- SQL Server 認証を使用する Azure SQL Database
- Visual Studio
- Azure AI 検索. 作成または既存の検索サービスの用意
Note
このチュートリアルには無料の検索サービスを使用できます。 Free レベルでは、インデックス、インデクサー、データ ソースがそれぞれ 3 つに限定されています。 このチュートリアルでは、それぞれ 1 つずつ作成します。 開始する前に、ご利用のサービスに新しいリソースを受け入れる余地があることを確認してください。
ファイルのダウンロード
このチュートリアルのソース コードは、Azure-Samples/search-dotnet-getting-started GitHub リポジトリ内の DotNetHowToIndexer フォルダーにあります。
1 - サービスを作成する
このチュートリアルでは、インデックス作成とクエリに Azure AI Search を使用し、外部データ ソースとして Azure SQL Database を使用します。 可能である場合は、近接性と管理性を高めるために、両方のサービスを同じリージョンおよびリソース グループ内に作成してください。 実際には、Azure SQL Database の場所はどのリージョンでもかまいません。
最初に Azure SQL Database で行う作業
このチュートリアルでは、サンプル ダウンロードに hotels.sql ファイルを提供して、データベースにデータを設定します。 Azure AI Search で使用されるのは、ビューやクエリから生成されるようなフラット化された行セットです。 サンプル ソリューションの SQL ファイルでは、単一のテーブルを作成してデータを投入します。
既に Azure SQL Database リソースがある場合は、hotels テーブルをそこに追加して、[クエリを開く] 手順から始めてください。
「クイック スタート: 単一データベースを作成する」の手順を使用して Azure SQL Database を作成します。
データベースのサーバー構成は重要です。
ユーザー名とパスワードの指定を求める SQL Server 認証オプションを選択します。 これは、インデクサーによって使用される ADO.NET 接続文字列に必要です。
パブリック接続を選択します。 これの方が、このチュートリアルが完了しやすくなります。 運用環境ではパブリックは推奨されません。チュートリアルの最後でこのリソースを削除することをお勧めします。
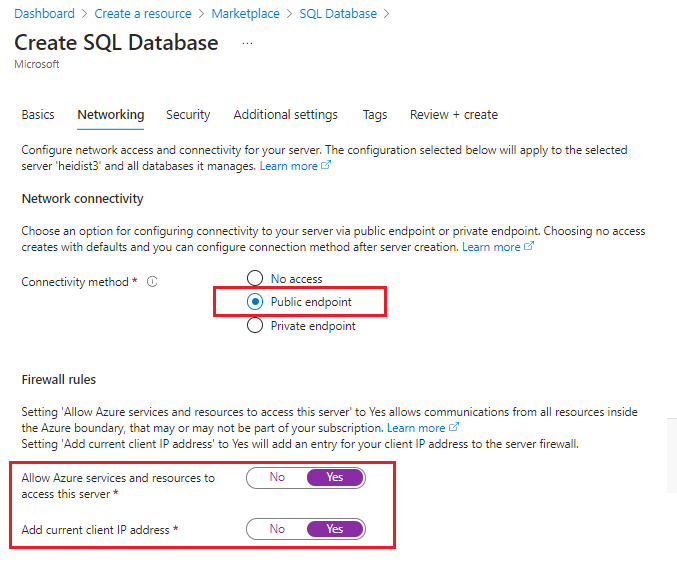
Azure portal で新しいリソースに移動します。
「クイック スタート: Azure portal でサーバーレベルのファイアウォール規則を作成する」の手順を使用して、クライアントからのアクセスを許可するファイアウォール規則を追加します。 コマンド プロンプトから
ipconfigを実行して、IP アドレスを取得できます。クエリ エディターを使用して、サンプル データを読み込みます。 ナビゲーション ウィンドウで [クエリ エディター (プレビュー)] を選択し、サーバー管理者のユーザー名とパスワードを入力します。
アクセス拒否エラーが表示された場合は、エラー メッセージからクライアント IP アドレスをコピーし、サーバーのネットワーク セキュリティ ページを開き、クライアントからのアクセスを許可する受信規則を追加します。
クエリ エディターで [クエリを開く] を選択し、ローカル コンピューター上の hotels.sql ファイルの場所に移動します。
ファイルを選択し、[開く] を選択します。 このスクリプトは次のスクリーンショットのようになります。
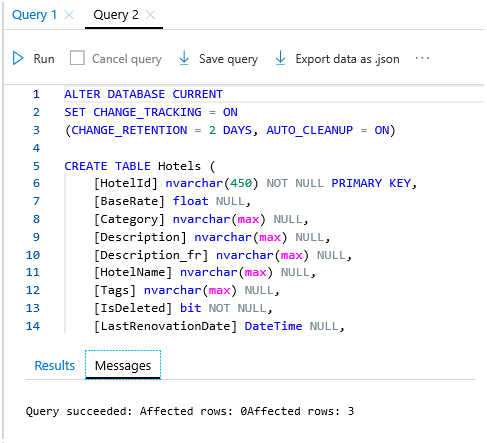
[実行] を選択して、クエリを実行します。 3 つの行において、クエリが正常に実行されたことを示すメッセージが [結果] ウィンドウに表示されます。
このテーブルから行セットが返されるようにするには、検証ステップとして次のクエリを実行します。
SELECT * FROM Hotelsデータベース用の ADO.NET 接続文字列をコピーします。 [設定]>[接続文字列] で、下の例に示すような ADO.NET の接続文字列をコピーします。
Server=tcp:{your_dbname}.database.windows.net,1433;Initial Catalog=hotels-db;Persist Security Info=False;User ID={your_username};Password={your_password};MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;
この接続文字列は、次の演習で環境を設定するときに必要になります。
Azure AI Search
次のコンポーネントは Azure AI Search であり、ポータルで作成できます。 このチュートリアルは Free レベルを使用して完了できます。
Azure AI Search のための管理者 API キーと URL を取得する
API 呼び出しには、サービス URL とアクセス キーが必要です。 両方を使用して検索サービスが作成されるため、Azure AI Search をサブスクリプションに追加した場合は、こちらの手順に従って必要な情報を取得します。
Azure portal にサインインし、ご使用の検索サービスの [概要] ページで、URL を入手します。 たとえば、エンドポイントは
https://mydemo.search.windows.netのようになります。[設定]>[キー] で、サービスに対する完全な権限の管理キーを取得します。 管理キーをロールオーバーする必要がある場合に備えて、2 つの交換可能な管理キーがビジネス継続性のために提供されています。 オブジェクトの追加、変更、および削除の要求には、主キーまたはセカンダリ キーのどちらかを使用できます。
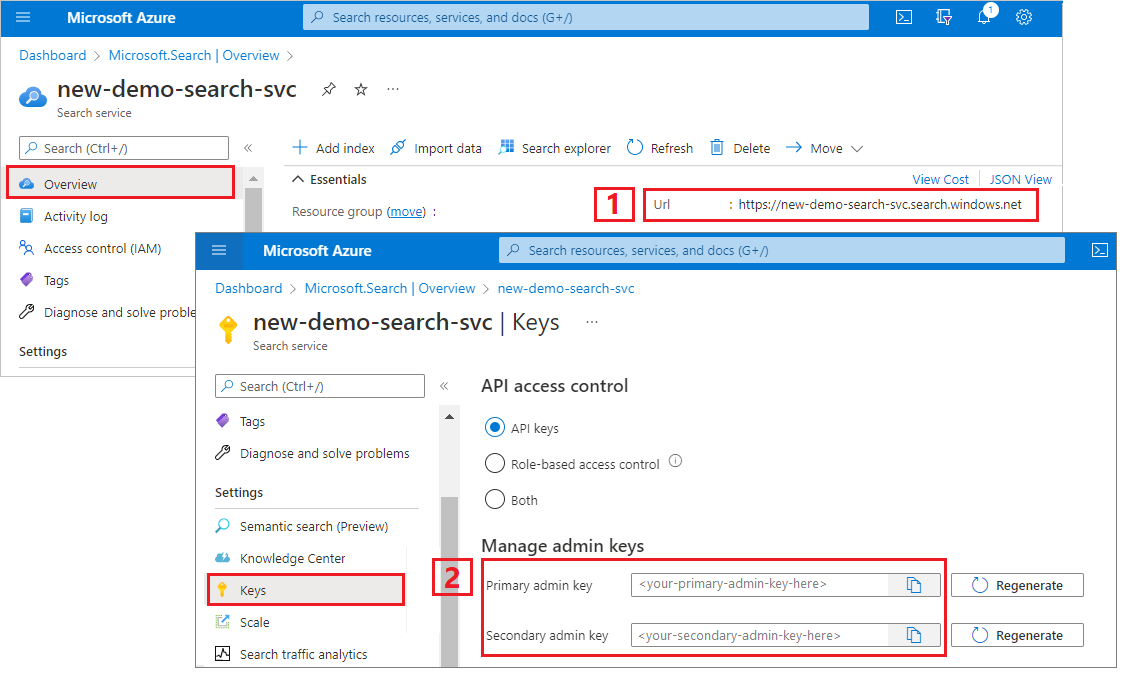
2 - 環境を設定する
Visual Studio を起動し、DotNetHowToIndexers.sln を開きます。
ソリューション エクスプローラーで appsettings.json を開き、接続情報を指定します。
SearchServiceEndPointについては、サービスの概要ページの完全な URL が "https://my-demo-service.search.windows.net"" である場合は、指定する値はその URL 全体となります。AzureSqlConnectionStringには、次のような文字列形式を指定します:"Server=tcp:{your_dbname}.database.windows.net,1433;Initial Catalog=hotels-db;Persist Security Info=False;User ID={your_username};Password={your_password};MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;"{ "SearchServiceEndPoint": "<placeholder-search-full-url>", "SearchServiceAdminApiKey": "<placeholder-admin-key-for-search-service>", "AzureSqlConnectionString": "<placeholder-ADO.NET-connection-string", }SQL 接続文字列のユーザー パスワードを有効なパスワードに置き換えます。 データベース名とユーザー名はコピーされますが、パスワードは手動で入力する必要があります。
3 - パイプラインを作成する
インデクサーには、データ ソース オブジェクトとインデックスが必要です。 関連するコードは 2 つのファイルにあります。
hotel.cs: インデックスを定義するスキーマが含まれています。
Program.cs: サービスの構造を作成したり管理したりするための関数が含まれています。
hotel.cs の内容
インデックス スキーマは、フィールドのコレクションを定義します。この定義には、次の HotelName のフィールドの定義に見られるように、フィールドがフルテキスト検索可能かどうか、フィルター処理可能かどうか、並べ替え可能かどうかなど、許可される操作を指定する属性も含まれています。 SearchableField は、定義によるフルテキスト検索が可能です。 その他の属性は明示的に割り当てます。
. . .
[SearchableField(IsFilterable = true, IsSortable = true)]
[JsonPropertyName("hotelName")]
public string HotelName { get; set; }
. . .
その他にも、スキーマにはさまざまな要素が存在します。検索スコアを高めるためのスコア付けプロファイルやカスタム アナライザーなど、各種コンストラクトがその例です。 ただし、このドキュメントの目的上、スキーマに含まれている定義はごくわずかで、サンプル データセットに含まれているフィールドのみがその構成要素となります。
Program.cs の内容
メイン プログラムには、インデクサー クライアント、インデックス、データ ソース、インデクサーを作成するためのロジックが含まれます。 このコードは、読者がこのプログラムを繰り返し実行する可能性を考慮し、同じ名前のリソースが既に存在しているかどうかを調べて、削除します。
データ ソース オブジェクトの構成には、Azure SQL に組み込まれている変更検出機能を使用するための部分インデックス作成または増分インデックス作成を含む、Azure SQL Database リソースに固有の設定が使用されます。 Azure SQL にあるソースのデモ hotels データベースには、IsDeleted という名前の "論理的な削除" 列があります。 データベースでこの列を true に設定すると、インデクサーによって、Azure AI Search インデックスから対応するドキュメントが削除されます。
Console.WriteLine("Creating data source...");
var dataSource =
new SearchIndexerDataSourceConnection(
"hotels-sql-ds",
SearchIndexerDataSourceType.AzureSql,
configuration["AzureSQLConnectionString"],
new SearchIndexerDataContainer("hotels"));
indexerClient.CreateOrUpdateDataSourceConnection(dataSource);
インデクサー オブジェクトはプラットフォームに依存しません。構成、スケジュール、起動は、ソースに関係なく同じです。 この例のインデクサーには、スケジュールのほか、インデクサーの履歴を消去するリセット オプション、インデクサーを直ちに作成して実行するためのメソッドの呼び出しが含まれています。 インデクサーを作成または更新するには、CreateOrUpdateIndexerAsync を使用します。
Console.WriteLine("Creating Azure SQL indexer...");
var schedule = new IndexingSchedule(TimeSpan.FromDays(1))
{
StartTime = DateTimeOffset.Now
};
var parameters = new IndexingParameters()
{
BatchSize = 100,
MaxFailedItems = 0,
MaxFailedItemsPerBatch = 0
};
// Indexer declarations require a data source and search index.
// Common optional properties include a schedule, parameters, and field mappings
// The field mappings below are redundant due to how the Hotel class is defined, but
// we included them anyway to show the syntax
var indexer = new SearchIndexer("hotels-sql-idxr", dataSource.Name, searchIndex.Name)
{
Description = "Data indexer",
Schedule = schedule,
Parameters = parameters,
FieldMappings =
{
new FieldMapping("_id") {TargetFieldName = "HotelId"},
new FieldMapping("Amenities") {TargetFieldName = "Tags"}
}
};
await indexerClient.CreateOrUpdateIndexerAsync(indexer);
通常、インデクサーの実行はスケジュール設定されますが、開発時には RunIndexerAsync を使用してすぐにインデクサーを実行することもできます。
Console.WriteLine("Running Azure SQL indexer...");
try
{
await indexerClient.RunIndexerAsync(indexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 429)
{
Console.WriteLine("Failed to run indexer: {0}", ex.Message);
}
4 - ソリューションをビルドする
F5 キーを押して、ソリューションをビルドおよび実行します。 プログラムがデバッグ モードで実行されます。 コンソール ウィンドウで各操作の状態が報告されます。
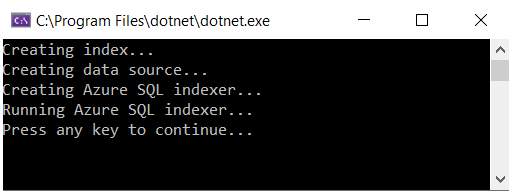
コードは Visual Studio でローカルに実行され、Azure 上の検索サービスに接続されます。次に、それが Azure SQL Database に接続され、データセットが取得されます。 このように多くの操作が伴うため、障害が発生し得るポイントがいくつも存在します。 エラーが発生した場合は、まず次の条件を確認してください。
指定する検索サービスの接続情報は完全な URL です。 サービス名のみを入力した場合、インデックスの作成時に接続エラーが発生して操作が停止します。
appsettings.json のデータベース接続情報。 これは、ポータルから取得した ADO.NET 接続文字列に、実際のデータベースの有効なユーザー名とパスワードを反映したものであることが必要です。 ユーザー アカウントには、データを取得するためのアクセス許可が必要です。 ローカル クライアントの IP アドレスには、ファイアウォールを介したインバウンド アクセスが許可されている必要があります。
リソース制限。 既に述べたように、Free レベルは、インデックス、インデクサー、データ ソースがいずれも 3 つまでに制限されています。 上限に達した場合、新しいオブジェクトを作成できなくなります。
5 - 検索する
Azure portal を使用してオブジェクトの作成を検証し、検索エクスプローラーを使用してインデックスを照会します。
Azure portal にサインインし、ご使用の検索サービスの左側のナビゲーション ウィンドウで、それぞれのページを順に開き、オブジェクトが作成されていることを確認します。 インデックス、インデクサー、データ ソースの名前は、それぞれ "hotels-sql-idx"、"hotels-sql-indexer"、"hotels-sql-ds" です。
[インデックス] タブで、hotels-sql-idx インデックスを選択します。 hotels ページの先頭のタブは [検索エクスプローラー] です。
[検索] を選択して空のクエリを発行します。
インデックスの 3 つのエントリが JSON ドキュメントとして返されます。 Search エクスプローラーは、構造全体が見えるようにドキュメントを JSON 形式で返します。
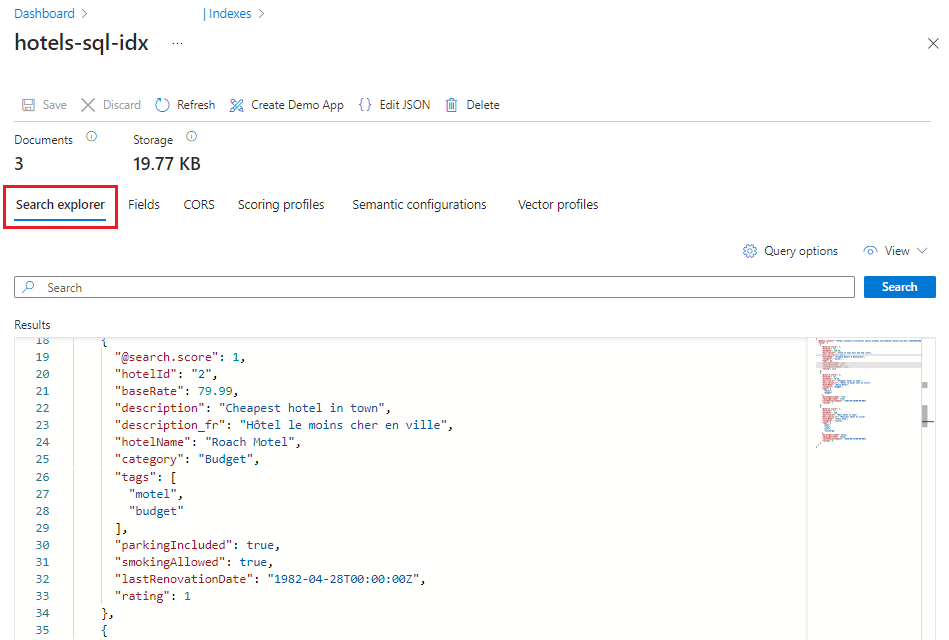
次に、クエリ パラメーターを入力できるように、JSON ビューに切り替えます。
{ "search": "river", "count": true }このクエリは、
riverという語についてフルテキスト検索を呼び出すもので、その結果には、一致したドキュメントの件数が含まれます。 一致したドキュメントの件数は、インデックスが大きく数千から数百万のドキュメントが含まれている場合のテストで役立ちます。 今回のケースで、このクエリに一致するドキュメントは 1 件だけです。最後に、検索結果を対象のフィールドに制限するパラメーターを入力します。
{ "search": "river", "select": "hotelId, hotelName, baseRate, description", "count": true }クエリの応答が選択フィールドに制限され、より簡潔な出力内容が得られます。
リセットして再実行する
開発の初期の実験的な段階では、設計反復のための最も実用的なアプローチは、Azure AI Search からオブジェクトを削除してリビルドできるようにすることです。 リソース名は一意です。 オブジェクトを削除すると、同じ名前を使用して再作成することができます。
このチュートリアルのサンプル コードでは、コードを再実行できるよう、既存のオブジェクトをチェックしてそれらを削除しています。
ポータルを使用して、インデックス、インデクサー、およびデータ ソースを削除することもできます。
リソースをクリーンアップする
所有するサブスクリプションを使用している場合は、プロジェクトの終了時に、不要になったリソースを削除することをお勧めします。 リソースを実行したままにすると、お金がかかる場合があります。 リソースは個別に削除することも、リソース グループを削除してリソースのセット全体を削除することもできます。
ポータルの左側のナビゲーション ウィンドウにある [すべてのリソース] または [リソース グループ] リンクを使って、リソースを検索および管理できます。
次のステップ
SQL Database のインデックス作成の基礎を理解したら、インデクサーの構成について詳しく見てみましょう。