Azure AI Search での検索結果の操作方法
この記事では、Azure AI Search でクエリの応答を操作する方法について説明します。 応答の構造は、クエリ自体のパラメーターによって決まります。ドキュメントの検索 (REST) またはSearchResults クラス (Azure for .NET) に関するページをご覧ください。
クエリのパラメーターによって、次のことが決まります。
- フィールドの選択
- クエリのインデックスで見つかった一致の数
- ページングの結果
- 応答に含まれる結果の数 (既定では最大 50)
- 並べ替え順序
- 結果内の用語を強調表示し、本文内の用語の全体または一部に一致します
結果の構成
結果は表形式で、すべての「取得可能」フィールドのフィールドで構成されるか、$select パラメーターで指定されたフィールドのみに制限されます。 行は一致するドキュメントです。
検索結果に含まれるフィールドを選択できます。 検索ドキュメントには多数のフィールドが含まれる可能性がありますが、一般に、結果セット内の各ドキュメントを表すために必要なものは数個しかありません。 クエリ要求で、応答にどの "取得可能な" フィールドを表示するかを指定するには $select=<field list> を追加します。
各ドキュメントを比較対照して区別するフィールドを選択することにより、ユーザーの側にクリックスルー応答を誘うための十分な情報を提供するフィールドが含まれます。 eコマース サイトでは、それは製品名、説明、ブランド、色、サイズ、価格、評価などである場合があります。 組み込みの hotels-sample インデックスの場合、次の例の "select" フィールドのようになります。
POST /indexes/hotels-sample-index/docs/search?api-version=2020-06-30
{
"search": "sandy beaches",
"select": "HotelId, HotelName, Description, Rating, Address/City"
"count": true
}
Note
結果の画像 (製品の写真やロゴなど) については、それらは Azure AI Search の外部に格納しますが、画像の URL を参照するためのインデックス内のフィールドを検索ドキュメントに追加します。 結果内の画像を実演するサンプル インデックスには、realestate-sample-us のデモ (データのインポート ウィザードで簡単に構築できる組み込みのサンプル データセット) や、ニューヨーク市のジョブのデモ アプリが含まれます。
予期しない結果が生じた場合のヒント
結果の実質 (構造ではなく実質的な中身) が、予期しない内容になっている場合も少なくありません。 たとえば、一部の結果が重複しているように見える場合や、上部の近くに表示され "なければならない" 結果が下の方に配置される場合があります。 クエリの結果が予期しないものである場合は、こちらのクエリ変更を試して、結果が改善されるかどうかを確認できます。
searchMode=any(既定) をsearchMode=allに変更し、いずれかの条件への一致ではなく、すべての条件への一致を強制します。 これは特に、ブール演算子がクエリに含まれているときに当てはまります。さまざまな字句アナライザーやカスタム アナライザーを試して、クエリ結果が変わるかどうかを確認します。 既定のアナライザーは、ハイフンでつながれた単語を分割し、単語を原形に変換します。通常はこれにより、クエリ応答の堅牢性が向上します。 ただし、ハイフンを保持する必要がある場合、または文字列に特殊文字が含まれている場合は、インデックスに適切な形式のトークンが含まれるようにカスタム アナライザーを構成することが必要になる場合があります。 詳細については、「部分的な用語検索と特殊文字を含むパターン (ハイフン、ワイルドカード、正規表現、パターン)」を参照してください。
一致のカウント
count パラメーターは、クエリの一致と見なされるインデックス内のドキュメントの数を返します。 カウントを返すには、クエリ要求に $count=true を追加します。 検索サービスによって課される最大値はありません。 クエリおよびドキュメントの内容によっては、カウントがインデックス内のすべてのドキュメントと同じ大きさになる場合があります。
インデックスが安定している場合、カウントは正確です。 システムがドキュメントをアクティブに追加、更新、または削除している場合、インデックスが完全に作成されていないドキュメントを除き、カウントは概算値になります。
Count は、定期的なメンテナンスや検索サービスのその他のワークロードの影響を受けません。 ただし、複数のパーティションと 1 つのレプリカがある場合は、パーティションの再起動時にドキュメント数 (数分) に短期的な変動が発生する可能性があります。
ヒント
インデックス作成操作をチェックするには、空の検索 search=* クエリに $count=true を追加することで、インデックスに予想される数のドキュメントが含まれているかどうかを確認できます。 結果は、インデックス内のドキュメントの完全な数になります。
クエリ構文をテストするとき、$count=true は、変更によって返される結果が多いか少ないかをすばやく判断できるため、有用なフィードバックになります。
ページングの結果
既定では、検索エンジンからは最初の最大 50 件の一致が返されます。 上位 50 は、クエリが全文検索またはセマンティックであると仮定して、検索スコアによって決定されます。 それ以外の場合、上位 50 は完全一致クエリの任意の順序です (そろいの "@searchScore=1.0" は任意のランク付けを示します)。
結果セットで返されるすべてのドキュメントのページングを制御するには、$top および $skip パラメーターを GET クエリ要求に追加します。または、top および skip を POST クエリ要求に追加します。 このロジックを説明する一覧を次に示します。
15 個の一致するドキュメントの最初のセットに加え、合計の一致の数を返します:
GET /indexes/<INDEX-NAME>/docs?search=<QUERY STRING>&$top=15&$skip=0&$count=true2 番目のセットを返し、次の 15 個を取得するために最初の 15 個をスキップします:
$top=15&$skip=15。 3 番目の 15 個セットに対して繰り返します:$top=15&$skip=30
基になるインデックスが変更されている場合、ページ分割されたクエリの結果の安定性は保証されません。 ページングによって各ページの $skip の値が変更されますが、各クエリは独立しており、クエリ時にインデックス内に存在する (つまり、汎用データベースで見られるような結果のキャッシュやスナップショットは存在しない) ため、データの現在のビューに対して動作します。
次の例は、重複がどのように発生するかを示しています。 4 つのドキュメントを含む次のインデックスがあるとします。
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
{ "id": "4", "rating": 1 }
ここでは、結果を一度に 2 つ、評価の順序で返してもらいたいとします。 結果の最初のページを取得するために $top=2&$skip=0&$orderby=rating desc というクエリを実行すると、次の結果が生成されます。
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
このサービスでは、クエリ呼び出しの間に { "id": "5", "rating": 4 } という 5 番目のドキュメントがインデックスに追加されたとします。 その後すぐに、2 ページ目をフェッチするために $top=2&$skip=2&$orderby=rating desc というクエリを実行すると、次の結果が得られます。
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
ドキュメント 2 が 2 回フェッチされることに注意してください。 これは、新しいドキュメント 5 の方が評価の値が大きいため、ドキュメント 2 の前に並べ替えられ、最初のページに割り当てられるためです。 この動作は予期されない可能性がありますが、検索エンジンの動作としては一般的なものです。
多数の結果をページングする
$top および $skip を使用することで、検索クエリで 100,000 件の結果をページングできるが、結果が 100,000 件を超える場合はどうなりますか。 大きな応答をページングするには、$skip の回避策として並べ替え順序と範囲フィルターを使用します。
この回避策では、並べ替えとフィルターは、ドキュメント ID フィールドかドキュメントごとに一意となる別のフィールドに適用されます。 一意のフィールドの検索インデックスには filterable および sortable 属性が必要です。
並べ替えられた結果の完全なページを返すクエリを発行します。
POST /indexes/good-books/docs/search?api-version=2020-06-30 { "search": "divine secrets", "top": 50, "orderby": "id asc" }検索クエリによって返された最後の結果を選択します。 "id" 値のみの結果例をここに示します。
{ "id": "50" }範囲クエリでその "id" 値を使用し、結果の次のページをフェッチします。 この "id" フィールドには一意の値が必要です。それがない場合、改ページ位置の自動修正に重複する結果が含まれる可能性があります。
POST /indexes/good-books/docs/search?api-version=2020-06-30 { "search": "divine secrets", "top": 50, "orderby": "id asc", "filter": "id ge 50" }クエリから 0 個の結果が返されると、改ページ位置の自動修正が終了します。
Note
"フィルター可能" 属性と "並べ替え可能" 属性は、フィールドが最初にインデックスに追加されたときにのみ有効にできます。既存のフィールドでは有効にできません。
順番の結果
フルテキスト検索クエリでは、結果は次の基準でランク付けできます。
- 検索スコア
- セマンティック再ランカー スコア
- "並べ替え可能" フィールドの並べ替え順序
スコアリング プロファイルを追加することで、特定のフィールドで見つかった一致をブーストすることもできます。
検索スコアによる並べ替え
フルテキスト検索クエリの場合、結果は自動的に、(TF-IDF から導出された) ドキュメント内の用語頻度と近接性に基づいて計算された検索スコアによってランク付けされます。ここで、検索用語に対するより多くの、またはより強力な一致を含むドキュメントにより高いスコアが割り当てられます。
"@search.score" 範囲は無制限か、以前のサービスでは、0 から 1.00 までです (1.00 は含まれません)。
いずれのアルゴリズムの場合でも、"@search.score" が 1.00 の場合は、スコア付けまたはランク付けされていない結果セットを示し、すべての結果に対してスコアは一様に 1.0 になります。 スコア付けされていない結果が発生するのは、クエリ フォームがあいまい検索、ワイルドカードまたは正規表現のクエリ、または空の検索 (search=*) である場合です。 スコア付けされていない結果に対してランク付け構造を設定する必要がある場合は、その目標を達成するため、$orderby 式を検討してください。
セマンティック再ランカーによる並べ替え
セマンティック ランク付けを使用している場合は、結果の並べ替え順序は "@search.rerankerScore" によって決まります。
"@search.rerankerScore" の範囲は 1 から 4.00 で、スコアが高いほどセマンティック一致が強いことを示します。
$orderby を使用した並べ替え
一貫した順序付けがアプリケーションの要件である場合は、フィールドに対して $orderby 式を定義できます。 「並べ替え可能」としてインデックス付けされたフィールドのみを使用して、結果を並べ替えることができます。
$orderby でよく使用されるフィールドとしては、評価、日付、場所などがあります。 場所によるフィルター処理では、フィールド名に加えて、フィルター式で geo.distance() 関数を呼び出す必要があります。
数値フィールド (Edm.Double、Edm.Int32、Edm.Int64) は、数値順 (1、2、10、11、20 など) で並べ替えられます。
文字列フィールド (Edm.String、Edm.ComplexType サブフィールド) は、言語に応じて、ASCII 並べ替え順序または Unicode 並べ替え順序で並べ替えられます。 任意の型のコレクションを並べ替えることはできません。
文字列フィールドの数値の内容は、アルファベット順に並べ替えられます (1、10、11、2、20)。
大文字の文字列の方が小文字より前になります (APPLE、Apple、BANANA、Banana、apple、banana)。 テキスト ノーマライザーを割り当てて並べ替えの前にテキストを前処理し、この動作を変更することができます。 Azure AI Search の並べ替えはフィールドの分析されていないコピーに対して行われるため、フィールドで小文字トークナイザーを使用しても、並べ替え動作には影響しません。
分音記号が前にある文字列は最後に表示されます (Äpfel、Öffnen、Üben)
スコアリング プロファイルを使用して関連性をブーストする
順序の一貫性を高める別の方法として、カスタム スコアリング プロファイルを使用する方法があります。 スコアリング プロファイルを使用すると、検索結果内の項目のランク付けをより細かく制御できるため、特定のフィールドで見つかる一致を向上させることができます。 追加のスコアリング ロジックにより、各ドキュメントの検索スコアがさらに離れるため、レプリカ間のわずかな違いのオーバーライドに役立ちます。 このアプローチにはランク付けアルゴリズムをお勧めします。
検索結果の強調表示
検索結果の強調表示とは、結果内の一致する用語に適用され、一致が容易に見つかるようにするテキストの書式設定 (太字や黄色の強調表示など) を指します。 強調表示は、説明フィールドなど、一致が一目ではわかりにくい、長いコンテンツ フィールドに対して便利です。
強調表示は個々の用語に適用されることに注意してください。 フィールド全体の内容を強調表示する機能はありません。 フレーズを強調する場合は、引用符で囲まれたクエリ文字列で一致する用語 (またはフレーズ) を指定する必要があります。 この手法については、このセクションで詳しく説明します。
検索結果の強調表示の手順については、クエリ要求に関する記事で説明しています。 エンジンのクエリ拡張をトリガーするクエリ (あいまい検索やワイルドカード検索など) では、検索結果の強調表示のサポートが制限されています。
ヒットの強調表示の要件
- フィールドは
Edm.StringまたはCollection(Edm.String)にする必要があります。 - フィールドは、検索可能である必要があります
要求で強調表示を指定する
強調表示された用語を返すには、クエリ要求に "highlight" パラメーターを含めます。 このパラメーターには、コンマ区切りのフィールド リストを設定します。
既定では、形式のマークアップは <em> ですが、highlightPreTag と highlightPostTag パラメーターを使用してタグをオーバーライドできます。 クライアントのコードで応答を処理します (たとえば、太字のフォントや黄色の背景の適用)。
POST /indexes/good-books/docs/search?api-version=2020-06-30
{
"search": "divine secrets",
"highlight": "title, original_title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>"
}
既定では、Azure AI Search によって、フィールドごとに最大 5 つの強調表示が返されます。 ダッシュとそれに続く整数を追加することで、この値を調整できます。 たとえば、"highlight": "description-10" とすると、"description" フィールドの一致するコンテンツで最大 10 個の強調表示された用語が返されます。
強調表示された結果
強調表示がクエリに追加されると、アプリケーションのコードでその構造をターゲットにできるように、応答の結果ごとに "@search.highlights" が含まれます。 "highlight" で指定されたフィールドのリストが応答に含まれます。
キーワード検索では、各用語が個別にスキャンされます。 "divine secrets" のクエリからは、いずれかの用語を含むすべてのドキュメントでの一致が返されます。
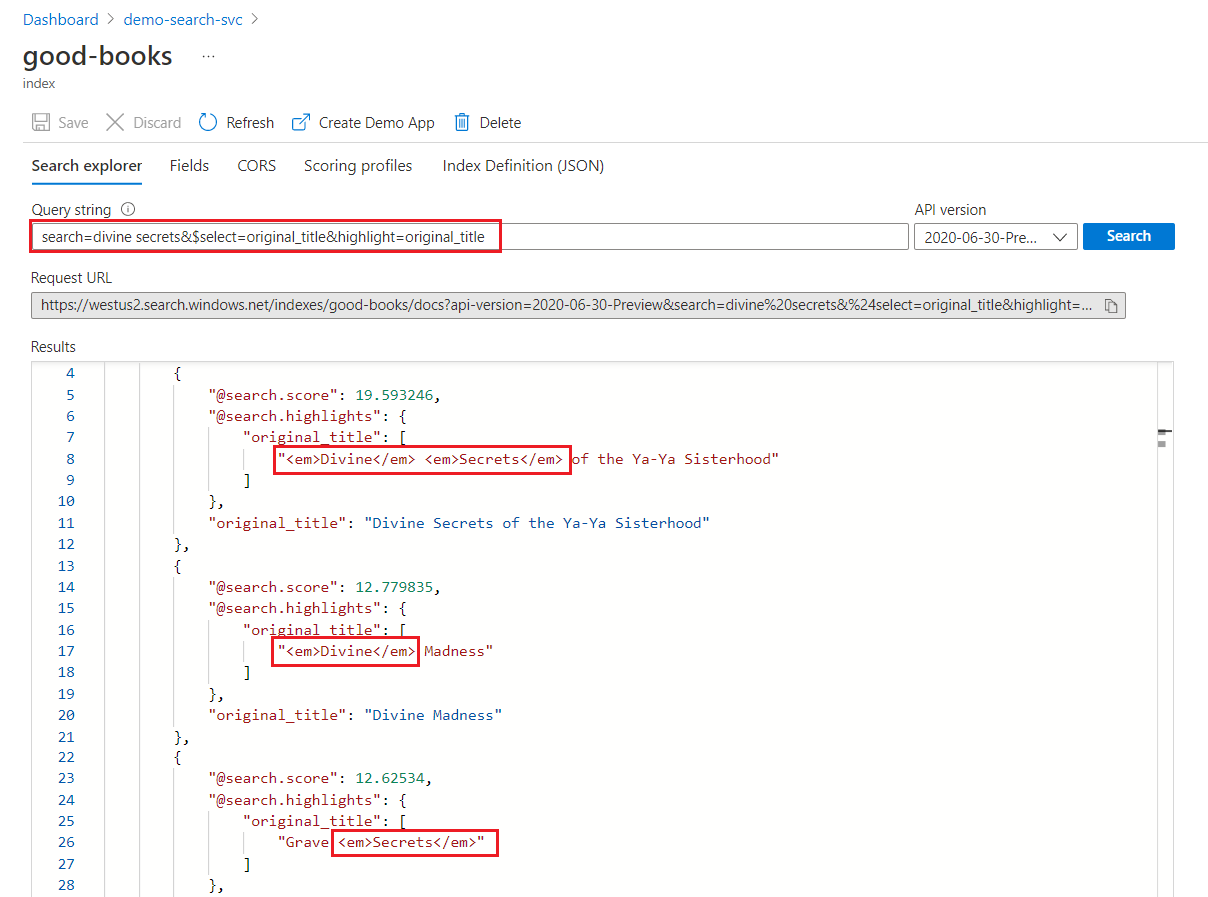
キーワード検索の強調表示
強調表示されたフィールド内では、すべての用語に書式が適用されます。 たとえば、"The Divine Secrets of the Ya-Ya Sisterhood" に対する一致では、それらが連続している場合でも、各用語に個別に書式設定が適用されます。
"@odata.count": 39,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"original_title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
],
"title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
},
{
"@search.score": 12.779835,
"@search.highlights": {
"original_title": [
"<em>Divine</em> Madness"
],
"title": [
"<em>Divine</em> Madness (Cherub, #5)"
]
},
"original_title": "Divine Madness",
"title": "Divine Madness (Cherub, #5)"
},
{
"@search.score": 12.62534,
"@search.highlights": {
"original_title": [
"Grave <em>Secrets</em>"
],
"title": [
"Grave <em>Secrets</em> (Temperance Brennan, #5)"
]
},
"original_title": "Grave Secrets",
"title": "Grave Secrets (Temperance Brennan, #5)"
}
]
語句検索の強調表示
複数の用語が二重引用符で囲まれている語句検索であっても、語句全体の書式設定が適用されます。 次の例は同じクエリですが、"divine search" が引用符で囲まれた語句として送信されている点が異なります (一部の REST クライアントでは、内部の引用符をバックスラッシュ \" でエスケープする必要があります)。
POST /indexes/good-books/docs/search?api-version=2020-06-30
{
"search": "\"divine secrets\"",,
"select": "title,original_title",
"highlight": "title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>",
"count": true
}
条件で両方の用語が与えられているため、検索インデックスで一致するのは 1 つだけです。 上記のクエリに対する応答は次のようになります。
{
"@odata.count": 1,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"title": [
"<b>Divine</b> <b>Secrets</b> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
}
]
}
古いサービスでの語句の強調表示
2020 年 7 月 15 日より前に作成された検索サービスでは、語句クエリに対して異なる強調表示エクスペリエンスが実装されています。
次の例では、引用符で囲まれた語句 "super bowl" を含むクエリ文字列が想定されています。 2020 年 7 月より前は、語句内のすべての用語が強調表示されます。
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is <em>super</em> awesome with a <em>bowl</em> of chips"
]
2020 年 7 月以降に作成された検索サービスの場合、完全な語句のクエリに一致する語句だけが "@search.highlights" で返されます。
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is super awesome with a bowl of chips"
]
次のステップ
クライアントの検索ページをすばやく生成するには、次のオプションを検討してください。
アプリケーション ジェネレーター。ポータルで、検索バー、ファセット ナビゲーション、画像を含む結果領域を備えた HTML ページを作成します。
ASP.NET Core (MVC) アプリに検索を追加する方法に関するページは、機能するクライアントを構築するチュートリアルとコード サンプルです。
「Web アプリに検索を追加する」は、ユーザー エクスペリエンスに React JavaScript ライブラリを使用するチュートリアルとコード サンプルです。 アプリは、Azure Static Web Apps を使用してデプロイされます。