Azure AI Search でフルテキスト クエリを作成する
フルテキスト検索のクエリを作成する場合、この記事では要求を設定するための手順について説明します。 また、クエリ構造の概要を示し、フィールド属性と言語アナライザーによってクエリ結果がどのような影響を受けるかについても説明します。
前提条件
searchableの属性が付けられた文字列フィールドを使用した検索インデックス。検索インデックスに対する読み取りアクセス許可。 読み取りアクセスの場合、要求にクエリ API キーを含めるか、呼び出し元に検索インデックス データ閲覧者許可を付与します。
フルテキスト クエリ要求の例
Azure AI Search では、クエリは 1 つの検索インデックスのドキュメント コレクションに対する読み取り専用の要求であり、クエリの実行を通知し、応答が返されるようにパラメータを設定します。
フルテキスト クエリは search パラメーターで指定され、語句、引用符で囲まれたフレーズ、および演算子で構成されます。 他のパラメーターを使用すると、要求に定義が追加されます。
次の Search POST REST API 呼び出しは、前述のパラメータを使用したクエリ要求を示しています。
POST https://[service name].search.windows.net/indexes/hotels-sample-index/docs/search?api-version=2023-11-01
{
"search": "NY +view",
"queryType": "simple",
"searchMode": "all",
"searchFields": "HotelName, Description, Address/City, Address/StateProvince, Tags",
"select": "HotelName, Description, Address/City, Address/StateProvince, Tags",
"top": "10",
"count": "true"
}
重要なポイント:
searchには一致条件を指定します。通常は用語全体またはフレーズですが、演算子が伴う場合も伴わない場合もあります。 インデックス スキーマ内で "検索可能" の属性を持つフィールドは、このパラメーターの候補になります。queryTypeは、パーサー (simple、full) を設定します。 既定のシンプルなクエリ パーサーは、フルテキスト検索に最適です。 Lucene の完全なクエリ パーサーは、正規表現、近接検索、ファジー検索、ワイルドカード検索などの高度なクエリ コンストラクトに適しています。 このパラメーターは、クエリ応答での高度なセマンティック モデリングのためのセマンティック ランク付け用にsemanticに設定することもできます。searchModeは、一致が式の "all" 条件 (精度を優先) または "any" 条件 (リコールを優先) に基づいているかどうかを指定します。 既定値は "any" です。 大きなテキスト ブロック (コンテンツ フィールドや長い説明) が含まれているインデックスでブール演算子が頻繁な使用されることが多いですが、これが予想される場合は、searchMode=Any|Allパラメーターを使用してクエリをテストし、その設定がブール検索に与える影響を評価してください。searchFieldsは、クエリの実行を特定の検索可能なフィールドに制限します。 開発時には、選択と検索に同じフィールド リストを使用すると便利です。 そうしないと、一致が結果に表示されないフィールド値に基づく可能性があり、ドキュメントが返された理由に対して不確実性が生じます。
応答を形成するために使用するパラメーター:
select: 応答で返すフィールドを指定します。 select ステートメントでは、インデックスで "取得可能" とマークされたフィールドのみを使用できます。top: 指定した数の最もよく一致するドキュメントを返します。 この例では、10 個のヒットのみが返されます。 top と skip (ここには非表示) を使用して、結果のページを移動することができます。count: すべてのインデックス全体で一致するドキュメントの数を示します。これは、返されるものよりも大きくなる可能性があります。orderby: 評価や場所などの値によって結果を並べ替える場合に使用します。 それ以外の場合、既定では、関連性スコアを使用して結果が順位付けされます。 このパラメーターの候補となるには、このフィールドに "並べ替え可能" の属性が必要です。
クライアントを選択する
早期の開発と概念実証テストの場合は、Azure portal または REST クライアントから開始します。 どちらのアプローチも対話型で、対象を絞ったテストに役立ち、コードを書かずにさまざまなプロパティの効果を評価するのに役立ちます。
アプリ内部から検索を呼び出すには、.NET、Java、JavaScript、または Python 用の Azure SDK 内の Azure.Document.Search クライアント ライブラリを使用します。
ポータルでは、インデックスを開くと、フィールド属性に簡単にアクセスできるように、横に並んだタブでインデックス JSON 定義と共に検索エクスプローラーを操作できます。 Fields テーブルを確認して、クエリのテスト中に、検索可能、並べ替え可能、フィルター可能、およびファセット可能なフィールドがどれかを確認します。
Azure portal にサインインし、ご利用の検索サービスを探します。
[インデックス] を開き、インデックスを選択します。
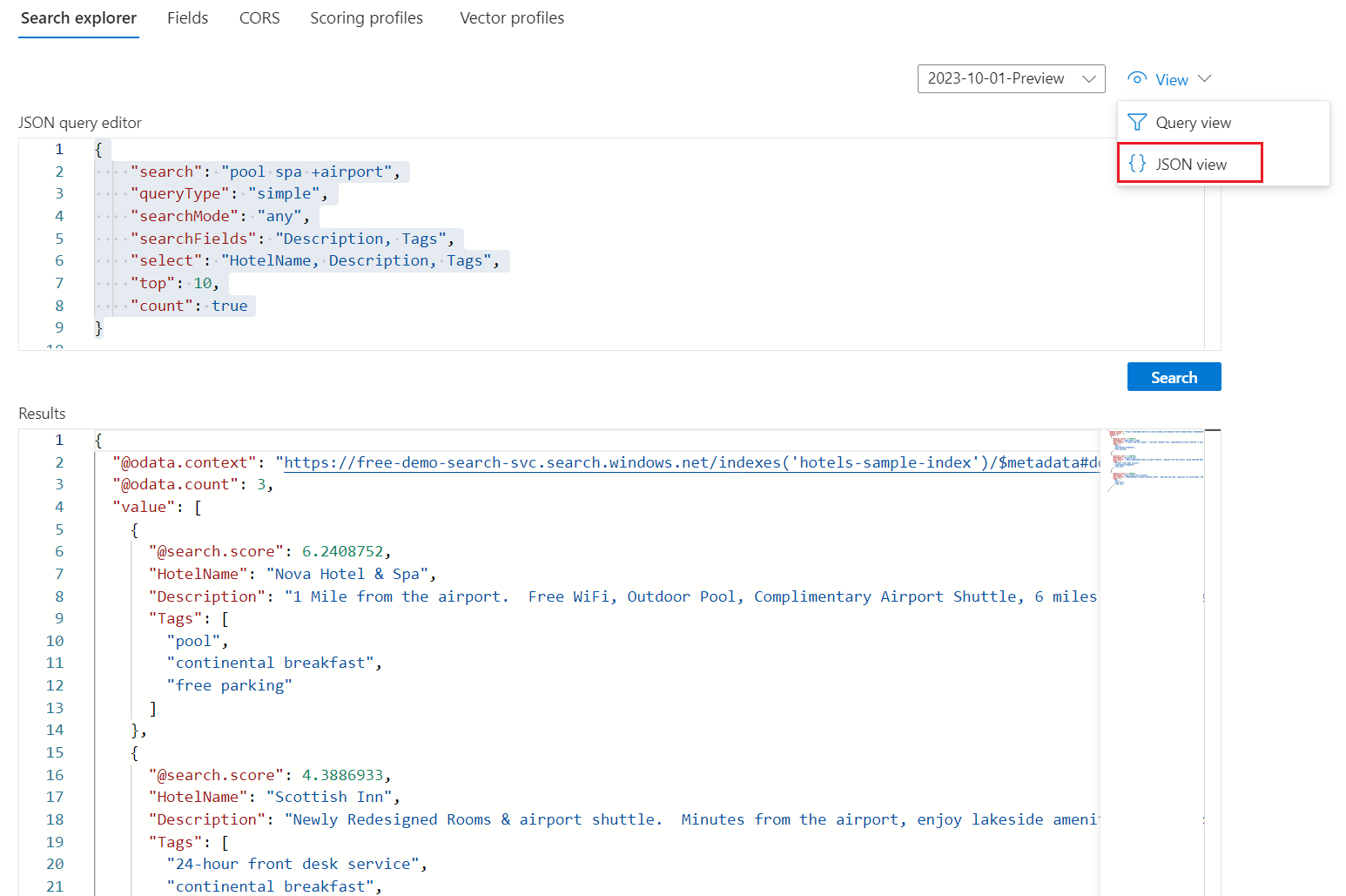
インデックスが [Search エクスプローラー] タブに開き、すぐに検索できます。 [JSON ビュー] に切り替えて、クエリ構文を指定します。
Hotels サンプル インデックスに対して機能するフルテキスト検索クエリ式を次に示します。
{ "search": "pool spa +airport", "queryType": "simple", "searchMode": "any", "searchFields": "Description, Tags", "select": "HotelName, Description, Tags", "top": 10, "count": true }次のスクリーンショットはクエリと応答の例を示したものです。
クエリの種類を選択する: simple | full
クエリがフルテキスト検索の場合、検索語句やフレーズとして渡されたテキストを処理するためにクエリ パーサーが使用されます。 Azure AI Search には、2 つのクエリ パーサーが用意されています。
単純なパーサーは、単純なクエリ構文を認識します。 このパーサーは、自由形式のテキスト クエリの速度と有効性により既定で選択されています。 この構文では、用語検索と語句検索に共通の検索演算子 (AND、OR、NOT) とプレフィックス (
*) 検索をサポートしています (Seattle や Seaside に対する "sea*" など)。 一般的には、最初に単純なパーサーを試してから、アプリケーションの要件でより強力なクエリが必要になる場合に完全なパーサーに移行することをお勧めします。完全な Lucene クエリ構文は、
queryType=fullを要求に追加したときに有効になり、Apache Lucene パーサーに基づいています。
完全な構文と単純な構文は、両方が同じプレフィックスとブール演算をサポートしているという点で重複しますが、完全な構文のほうがより多くの演算子を用意しています。 完全では、ブール式の演算子や、あいまい検索、ワイルドカード検索、近接検索、正規表現などの高度なクエリ用の演算子が多数用意されています。
クエリ メソッドを選択する
検索は基本的にユーザー主導の動作であり、検索ボックスから、またはページでのクリック イベントから、用語や語句が収集されます。 次の表は、予想される検索エクスペリエンスと共にユーザー入力を収集するためのメカニズムをまとめたものです。
| 入力 | エクスペリエンス |
|---|---|
| 検索メソッド | ユーザーは、演算子の有無にかかわらず検索ボックスに用語または語句を入力し、[検索] をクリックして要求を送信します。 検索は同じ要求でフィルターと共に使用できますが、オートコンプリートや提案と共には使用できません。 |
| オートコンプリート メソッド | ユーザーがいくつかの文字を入力すると、新しい文字が入力されるたびにクエリが開始されます。 応答は、インデックスからの完成した文字列になります。 指定された文字列が有効な場合、ユーザーは [検索] をクリックしてそのクエリをサービスに送信します。 |
| 提案メソッド | オートコンプリートと同様に、ユーザーがいくつかの文字を入力すると、増分クエリが生成されます。 応答は一致したドキュメントのドロップダウン リストであり、通常はいくつかの一意または説明のフィールドで表されます。 いずれかの選択が有効な場合、ユーザーが 1 つをクリックすると、一致したドキュメントが返されます。 |
| ファセット ナビゲーション | ページには、クリック可能なナビゲーション リンクまたは階層リンクが表示され、検索範囲を絞り込むことができます。 ファセット ナビゲーション構造は、初期クエリに基づいて動的に構成されます。 たとえば、search=* は、可能なすべてのカテゴリから構成されるファセット ナビゲーション ツリーを設定します。 ファセット ナビゲーション構造はクエリ応答から作成されますが、次のクエリを表現するためのメカニズムでもあります。 REST API リファレンスでは、facets は、ドキュメントの検索操作のクエリ パラメーターとして記述されていますが、search パラメーターを指定せずに使用できます。 |
| filter メソッド | フィルターは、結果を絞り込むためにファセットと共に使用されます。 また、ページの背後にフィルターを実装することもでき、たとえば、言語固有のフィールドでページを初期化することができます。 REST API リファレンスでは、$filter はドキュメントの検索操作のクエリ パラメーターとして記述されていますが、search パラメーターを指定せずに使用できます。 |
クエリでのフィールド属性の影響
クエリの種類と構成に詳しい場合、クエリ要求のパラメーターはインデックスのフィールド属性に依存することをご存じかもしれません。 たとえば、searchable および retrievable のマークが付いているフィールドのみクエリと検索結果で使用できます。 要求で search、filter、orderby パラメーターを設定するとき、予想外の結果を避けるため、属性を確認してください。
以下に示すホテルのサンプル インデックスのポータルのスクリーンショットでは、"LastRenovationDate" と "Rating" の最後の 2 つのフィールドだけが sortable で、これは "$orderby" だけの句で使用するための要件です。

フィールド属性の定義については、「Create Index (REST API)」を参照してください。
クエリに対するトークンの影響
インデックス作成中、検索エンジンでは、文字列にテキスト アナライザーを使用し、クエリ時に一致を見つける可能性を最大化します。 少なくとも文字列は小文字に変換されますが、アナライザーによっては、レンマ化とストップ ワードの削除も行われる可能性があります。 通常、長い文字列や複合語は、空白、ハイフン、またはダッシュによって分割され、個別のトークンとしてインデックスが付けられます。
ここでの要点は、インデックスに含まれていると思われることと、実際に含まれていることは異なる場合があるということです。 クエリで予想された結果が返されない場合は、分析テキスト (REST API) を通じてアナライザーによって作成されたトークンを検査できます。 トークン化とクエリへの影響の詳細については、「部分的な用語検索と特殊文字を含むパターン」をご覧ください。
次のステップ
これで、クエリ要求のしくみについての理解が深まったので、次のクイックスタートで実際に体験してみてください。