Azure Stream Analytics のソリューション パターン
Azure にある他の多くのサービスと同様、Stream Analytics は、他のサービスと組み合わせて、より大きなエンドツーエンドのソリューションを作成する目的で最もよく使用されます。 この記事では、単純な Azure Stream Analytics ソリューションとさまざまなアーキテクチャ パターンについて説明します。 これらのパターンを基礎として、より複雑なソリューションを開発することができます。 この記事で取り上げるパターンは、さまざまなシナリオで使用できます。 シナリオごとのパターンの例については、「Azure ソリューション アーキテクチャ」でご覧いただけます。
Stream Analytics ジョブを作成してリアルタイム ダッシュボード エクスペリエンスを強化する
Azure Stream Analytics を使用して、リアルタイムのダッシュボードとアラートを簡単に作成することができます。 Event Hubs または IoT Hub からイベントを取り込み、Power BI ダッシュボードにストリーミング データ セットをフィードするシンプルなソリューションが挙げられます。 詳細については、「Stream Analytics で不正な通話のデータを分析し、Power BI ダッシュボードで結果を視覚化する」という詳しいチュートリアルを参照してください。
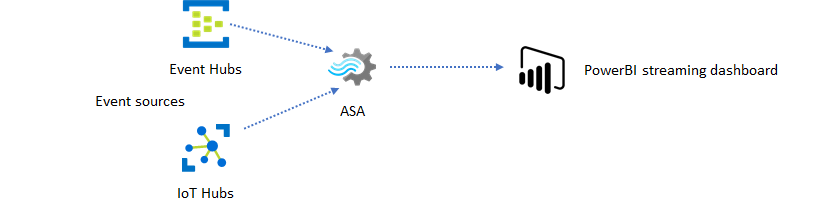
このソリューションは、Azure portal を使用してわずか数分で構築できます。 大規模にコーディングする必要はありません。 代わりに、SQL 言語を使用してビジネス ロジックを表現できます。
このソリューション パターンでは、イベント ソースからブラウザーの Power BI ダッシュボードまでの間で、最短待機時間が実現されます。 Azure Stream Analytics は、このビルトイン機能を備えた唯一の Azure サービスです。
ダッシュボードに SQL を使用する
Power BI ダッシュボードは、待ち時間は短いものの、本格的な Power BI レポートを生成する用途には使用できません。 レポート作成パターンとしては、データをまず SQL Database に出力するのが一般的です。 その後、Power BI の SQL コネクタを使用して、SQL に最新のデータを照会します。
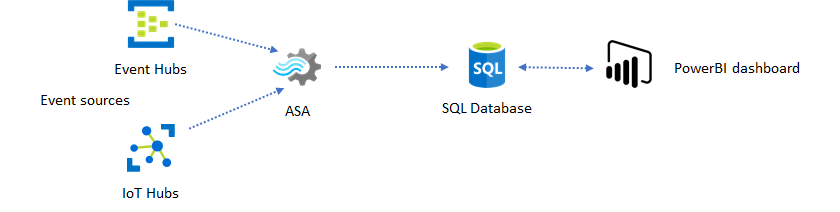
SQL Database を使用すると、柔軟性は向上しますが、待ち時間はわずかに長くなります。 待ち時間の要件が 1 秒を超えるジョブには、このソリューションが最適です。 この方法を使用すれば、Power BI の機能を最大限に活用して、レポートに使用するデータをさらにスライスしてダイスしたり、その他の視覚化オプションを使用したりできます。 また、Tableau など他のダッシュボード ソリューションを使用する柔軟性も得られます。
SQL は、高スループットのデータ ストアではありません。 Azure Stream Analytics から SQL Database への最大スループットは、現時点では約 24 MB/秒です。 実際のソリューションのイベント ソースからもっと高速にデータが生成される場合、Stream Analytics の処理ロジックを使用して、SQL への出力速度を下げる必要があります。 フィルタリング、ウィンドウ集計、テンポラル結合を使用したパターン マッチング、分析関数などの手法を利用できます。 SQL への出力速度は、「Azure SQL Database への Azure Stream Analytics の出力」で説明されている手法を使って、最適化することができます。
イベント メッセージングを使用してリアルタイムの分析情報をアプリケーションに取り込む
Stream Analytics がよく利用されるもう 1 つの用途として、リアルタイム アラートの生成があります。 このソリューション パターンでは、Stream Analytics のビジネス ロジックを使用して、テンポラル パターンや空間パターン、異常を検出して、アラート シグナルを生成できます。 ただし、Stream Analytics の推奨エンドポイントとして Power BI が使用されるダッシュボード ソリューションとは異なり、他の中間データ シンクを使用することができます。 そうしたシンクとして、Event Hubs、Service Bus、Azure Functions などが挙げられます。 どのデータ シンクが実際のシナリオに最適であるかは、アプリケーション ビルダーが判断しなければなりません。
既存のビジネス ワークフローでアラートを生成するためには、ダウンストリームのイベント コンシューマー ロジックを実装する必要があります。 Azure Functions でカスタム ロジックを実装できるため、この統合を実施する最も手軽な方法は Azure Functions です。 Stream Analytics ジョブの出力としての Azure Functions の使用に関するチュートリアルについては、「Azure Stream Analytics ジョブから Azure Functions を実行する」を参照してください。 また、Azure Functions では、テキストやメールを含め、さまざまな種類の通知がサポートされます。 こうした統合には、Logic Apps も使用できます。この場合、Stream Analytics と Logic Apps の間に Event Hubs を使用することになります。
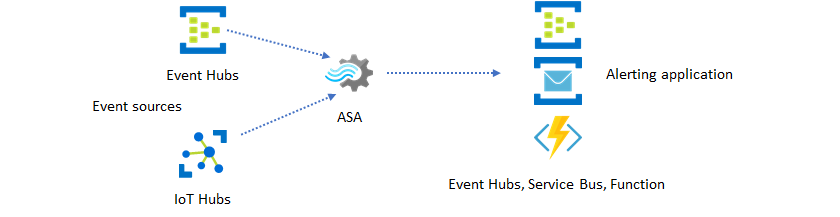
他方で、Azure Event Hubs サービスは、きわめて柔軟性の高い統合ポイントとなります。 Azure Data Explorer や Time Series Insights などの他の多くのサービスで、Event Hubs のイベントを消費できます。 このソリューションは、Azure Stream Analytics から Event Hubs シンクにサービスを直接接続することによって実現できます。 Event Hubs は、このような統合シナリオを実現するための、Azure における最速のスループットを備えたメッセージング ブローカーでもあります。
動的アプリケーションと Web サイト
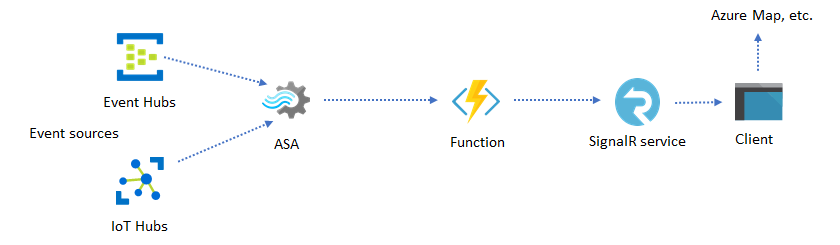
Azure Stream Analytics と Azure SignalR Service を使用すると、カスタムのリアルタイム ビジュアル化 (ダッシュボードやマップの視覚化など) を実現できます。 SignalR を使用すると、Web クライアントを更新し、リアルタイムに動的コンテンツを表示することができます。
データ ストアを使用してリアルタイムの分析情報をアプリケーションに取り込む
今日見られるほとんどの Web サービスと Web アプリケーションでは、プレゼンテーション層の処理に要求/応答パターンが使用されています。 要求/応答パターンは構築が容易であり、ステートレスなフロントエンドとスケーラブルなストア (Azure Cosmos DB など) を使えば、短い応答時間で、簡単にスケーリングすることができます。
CRUD ベースのシステムでは、大量のデータがパフォーマンス ボトルネックを引き起こすことが少なくありません。 パフォーマンスのボトルネックを解決するために、イベント ソーシング ソリューション パターンが使用されます。 テンポラルなパターンと分析情報も、従来のデータ ストアからは抽出することが難しく効率も良くありません。 大量のデータを扱う近年のデータ ドリブン型アプリケーションでは、データフローベースのアーキテクチャがよく使用されます。 そのアーキテクチャの要となるのが、移動中のデータを対象にしたコンピューティング エンジンとしての Azure Stream Analytics です。
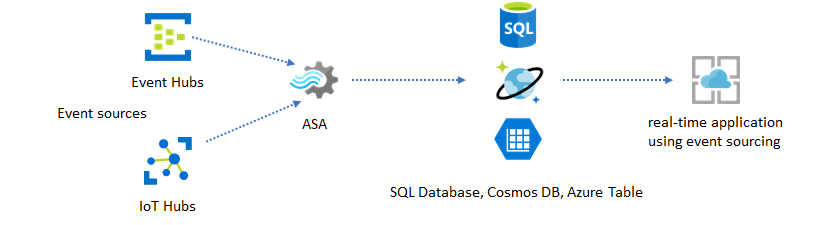
このソリューション パターンでは、Azure Stream Analytics によってイベントが処理されてデータ ストアに集約されます。 アプリケーション レイヤーは、従来の要求/応答パターンを使用して、そのデータ ストアと対話することになります。 Stream Analytics には大量のイベントをリアルタイムに処理する機能があるため、アプリケーションは非常にスケーラブルであり、データ ストア レイヤーを増強する必要はありません。 実質的にはデータ ストア レイヤーが、システムにおけるマテリアライズドビューとなります。 Stream Analytics の出力として Azure Cosmos DB を使う方法は、「Azure Cosmos DB への Azure Stream Analytics の出力」で説明されています。
処理ロジックが複雑で、特定のロジック領域を個別にアップグレードする必要があるような実際のアプリケーションでは、中間イベント ブローカーとしての Event Hubs に複数の Stream Analytics ジョブを組み合わせることができます。

このパターンでは、システムの回復性と管理しやすさが向上します。 一方、Stream Analytics では 1 回限りの処理が保証されているものの、中間の Event Hubs に重複するイベントが到達する可能性も、わずかながらあります。 ダウンストリームの Stream Analytics ジョブは、ルックバック ウィンドウでロジック キーを使用し、イベントを重複排除することが重要となります。 イベント配信の詳細については、イベント配信の保証に関するリファレンスを参照してください。
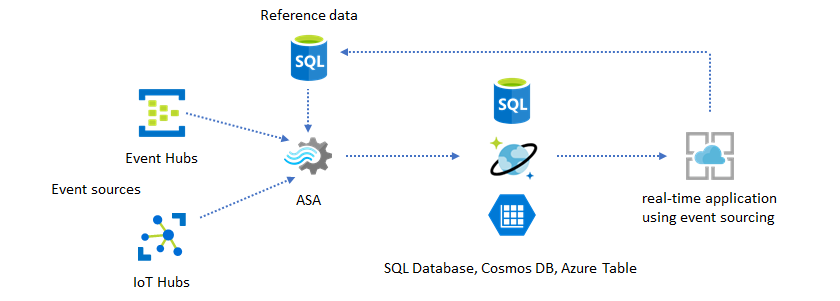
アプリケーションのカスタマイズに参照データを使用する
Azure Stream Analytics の参照データ機能は、アラートのしきい値、処理ルール、ジオフェンスなど、特にエンドユーザーのカスタマイズを考えて設計されています。 アプリケーション レイヤーは、パラメーターの変更を受け付けて、それらを SQL Database に格納できます。 Stream Analytics ジョブはそのデータベースに対して定期的に変更を照会し、参照データの結合によって、カスタマイズのパラメーターを利用しやすい状態にします。 参照データを使用してアプリケーションのカスタマイズを行う方法の詳細については、SQL 参照データと参照データの結合に関するページを参照してください。
このパターンを使用すれば、ルールのしきい値が参照データから定義されるようなルール エンジンを実装することもできます。 ルールの詳細については、「Azure Stream Analytics での、設定可能なしきい値に基づいたルールの処理」を参照してください。
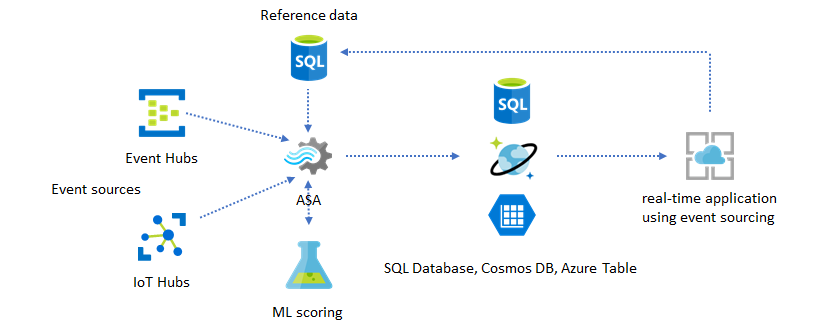
リアルタイムの分析情報に Machine Learning を追加する
Azure Stream Analytics のビルトインの異常検出モデルを使用すると、リアルタイム アプリケーションに Machine Learning を簡単に導入することができます。 Machine Learning のより多様なニーズについては、Azure Stream Analytics と Azure Machine Learning のスコアリング サービスの統合に関するページを参照してください。
同じ Stream Analytics パイプラインにオンライン トレーニングとスコアリングを導入したいと考えている、詳しい知識のあるユーザーの方は、線形回帰を使用してそれを行う例を参照してください。
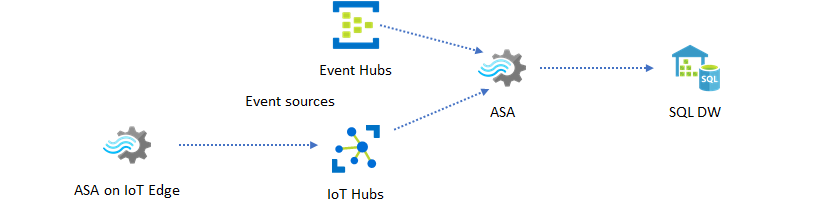
リアルタイム データ ウェアハウジング
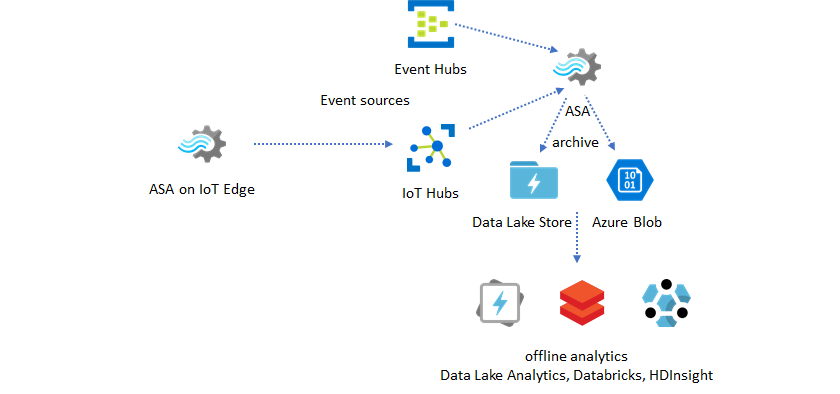
もう 1 つの一般的なパターンとして、リアルタイム データ ウェアハウジングがあります。これはストリーミング データ ウェアハウスとも呼ばれます。 アプリケーションからのイベントを Event Hubs や IoT Hub で受け取る以外にも、IoT Edge 上で動作する Azure Stream Analytics を使用して、データ クレンジング、データの削減、データ ストア、データ転送のニーズに応えることができます。 IoT Edge 上で動作する Stream Analytics であれば、システムにおける帯域幅の制限や接続の問題に適切に対処できます。 Stream Analytics は、Azure Synapse Analytics への書き込み中に、最大 200 MB/秒のスループット率をサポートできます。
リアルタイム データを分析用にアーカイブする
データ サイエンスとデータ分析のアクティビティは、その大半がオフラインで実行されます。 Azure Stream Analytics では、Azure Data Lake Store Gen2 や Parquet の出力形式でデータをアーカイブすることができます。 この機能を使えば、Azure Data Lake Analytics や Azure Databricks、Azure HDInsight に対し、手間なく直接データを取り込むことができます。 このソリューションでは、Azure Stream Analytics が凖リアルタイムの抽出、変換、読み込み (ETL) エンジンとして使用されます。 Data Lake にアーカイブ済みのデータは、さまざまなコンピューティング エンジンを使用して調査することができます。
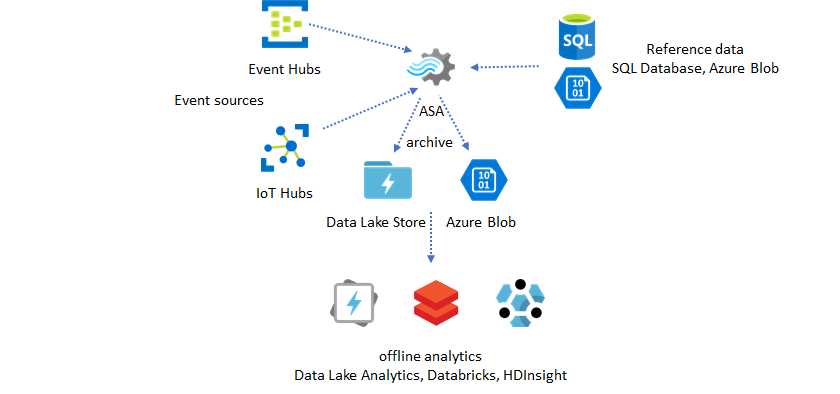
エンリッチメントに参照データを使用する
データ エンリッチメントは、多くの場合、ETL エンジンの要件となっています。 Azure Stream Analytics は、SQL Database と Azure Blob Storage の両方の参照データを使ったデータ エンリッチメントをサポートします。 データ エンリッチメントによって、Azure Data Lake と Azure Synapse Analytics の両方へのデータ ランディングを実現できます。
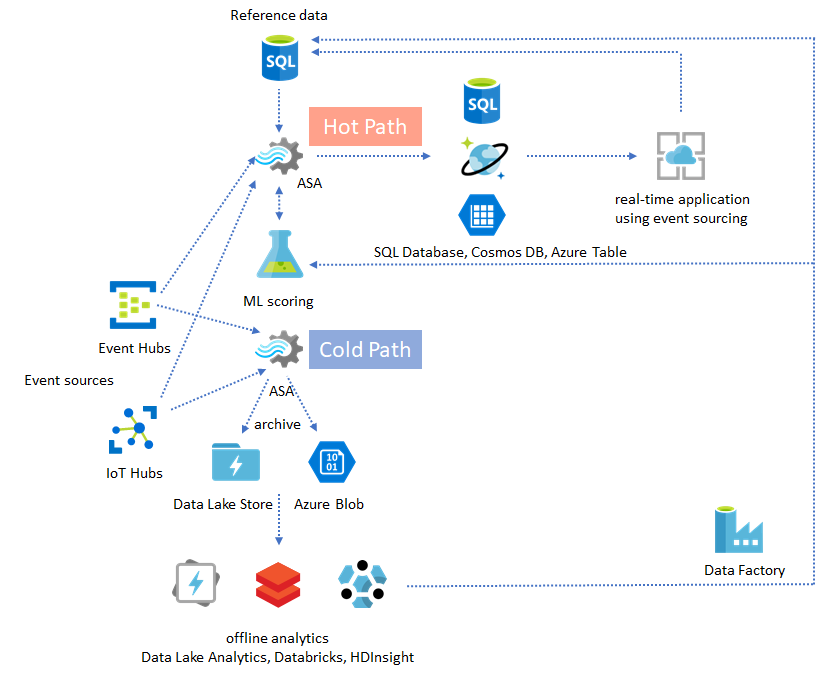
アーカイブ データからの分析情報を運用化する
ほぼリアルタイムのアプリケーション パターンにオフライン分析パターンを組み合わせると、フィードバック ループを作成することができます。 フィードバック ループを使用することにより、アプリケーションは絶えず変化するデータのパターンに自動的に適応することができます。 このフィードバック ループは、アラートのしきい値を変えるだけの単純なものもあれば、機械学習モデルを再トレーニングするような複雑なものもあります。 同じソリューション アーキテクチャは、クラウドで実行される ASA ジョブと IoT Edge で実行される ASA ジョブの両方に適用できます。
ASA ジョブを監視する方法
Azure Stream Analytics ジョブは、受信イベントを常時リアルタイムに処理するために、24 時間 365 日実行することができます。 そのアップタイム保証は、アプリケーション全体の正常性にとってきわめて重要となります。 Stream Analytics は業界で唯一 99.9% の可用性保証を提供するストリーミング分析サービスですが、それでも、ある程度のダウン タイムが発生します。 これまでに、Stream Analytics には、ジョブの正常性を反映するメトリック、ログ、ジョブ状態が導入されてきました。 そのいずれもが Azure Monitor サービスを通じて公開され、さらに OMS にエクスポートすることができます。 詳細については、「Azure portal で Stream Analytics ジョブを監視する」を参照してください。

主な監視対象は次の 2 つです。
-
まず、ジョブが実行中であることを確認する必要があります。 実行状態のジョブがなければ、新しいメトリックもログも生成されません。 ジョブが失敗状態になる原因は、SU の使用率が高い (つまりリソース不足) など、多岐にわたります。
-
これは、処理パイプラインに実時間 (秒) でどの程度の遅れが生じているかを反映するメトリックです。 遅延の一部は、内包されている処理ロジックに原因があります。 そのため、絶対値を監視するよりも、増加の傾向を監視することの方がはるかに重要となります。 定常状態の遅延は、監視やアラートではなく、アプリケーションの設計によって対処する必要があります。
障害発生時は、まずアクティビティ ログと診断ログからエラーを探すことが最良の選択肢となります。
回復性を備えたミッション クリティカルなアプリケーションを作成する
Azure Stream Analytics に SLA 保証があっても、また、エンド ツー エンド アプリケーションをいかに慎重に実行したとしても、機能停止は発生します。 ミッション クリティカルなアプリケーションを正常に復旧するためには、機能停止に備える必要があります。
アラートを生成するためのアプリケーションで最も重要なことは、次のアラートを検出することです。 復旧する際は、必要に応じて、過去のアラートを無視し、現在の時刻からジョブを再開してもかまいません。 ジョブの開始時刻のセマンティクスは、最初の入力時刻ではなく、最初の出力時刻が基準となります。 指定された時刻における最初の出力が完全かつ適切であることを保証するために、入力は、適切な時間だけ過去に巻き戻されます。 結果的に、不完全な集計が返されたり、アラートが予期せずトリガーされたりすることはありません。
ある程度の時間を過去にさかのぼって出力を開始することもできます。 Event Hubs と IoT Hub の保持ポリシーはどちらも、過去を基準として処理を実行できるだけの十分な量のデータを保持するようになっています。 その代わり、どの程度早く現在の時刻に追い付き、適時に新しいアラートの生成を開始できるかが問題となります。 時間の経過と共に、データはその価値を失います。そのため、現在の時刻にすばやく追い付くことが重要となります。 すばやく追い付くためには、次の 2 つの方法があります。
- 現在の時刻に追い付こうとする際には、プロビジョニングするリソース (SU) を増やす。
- 現在の時刻から再開する。
現在の時刻から再開するのが最も簡単ですが、その代償として、処理の過程で空白期間が残ります。 アラート生成のシナリオでは、このように再開して問題がないケースもあるかもしれませんが、ダッシュボードのシナリオでは問題となる場合があり、また、アーカイブやデータ ウェアハウジングのシナリオでは実用に耐えません。
プロビジョニングするリソースを増やせば処理は高速化しますが、処理速度が急激に上がることで複雑な影響が生じます。
SU 数の増大に合わせて実際のジョブをスケーリングできることを確認します。 中にはスケーリングできないクエリも存在します。 クエリを並列化できることを確認する必要があります。
入力スループットをスケーリングするために、より多くのスループット ユニット (TU) を追加できるだけのパーティションがアップストリームの Event Hubs または IoT Hub に存在することを確認します。 各 Event Hubs の TU は、出力速度 2 MB/秒で限界に達します。
出力シンク (SQL Database、Azure Cosmos DB) に十分なリソースがプロビジョニングされていて、出力の急増がスロットルされないことを確認します。スロットルが原因でシステムが動かなくなることがあります。
最も重要なことは、処理速度の変化を予測し、これらのシナリオをテストしたうえで運用環境に移行すること、そして、エラーからの回復過程における処理のスケーリングに正しく備えることです。
受信したすべてのイベントが遅延するという極端なシナリオでは、ジョブに到着遅延時間枠を適用した場合に、遅延したイベントがすべてドロップされる可能性があります。 最初はイベントのドロップが不可解な動作に見えるかもしれません。しかし、Stream Analytics がリアルタイム処理エンジンであることを踏まえれば、受信するイベントが実時間に近いことは当然のことと言えます。 これらの制約に違反したイベントはドロップする必要があるのです。
ラムダ アーキテクチャまたはバックフィル プロセス
さいわい、こうした遅延イベントは、前述のデータ アーカイブ パターンを使用すれば、適切に処理することができます。 アーカイブ ジョブで受信イベントを到着時刻に処理し、Azure BLOB または Azure Data Lake Store には、対応するイベント時刻と共に適切なタイム バケットにイベントをアーカイブするという考え方です。 どれだけ遅れてイベントが到着しようと、決してドロップされることはありません。 いずれは必ず適切なタイム バケットに到着します。 復旧過程で、アーカイブ済みのイベントを再処理し、その結果を任意のストアにバックフィルすることができます。 これは、ラムダ パターンが実装される方法と似ています。
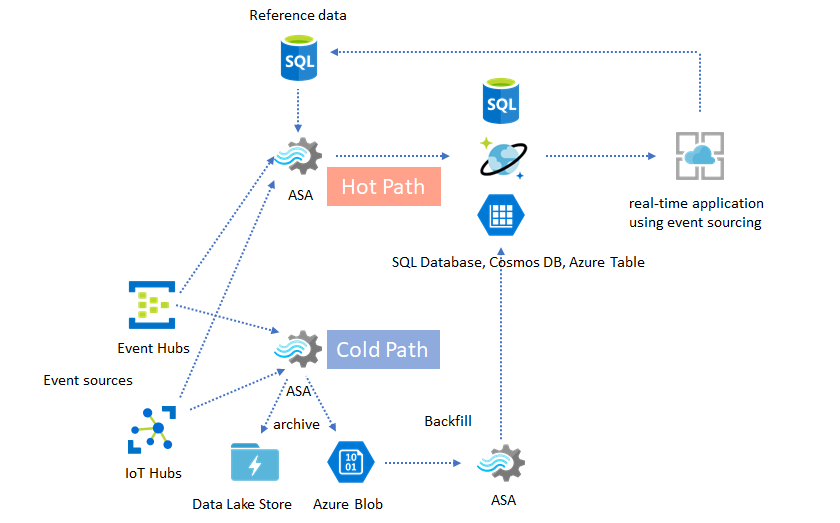
バックフィル プロセスは、オフライン バッチ処理システムで行う必要があります。オフライン バッチ処理システムは、ほぼ確実に、Azure Stream Analytics とはプログラミング モデルが異なります。 つまり、処理ロジック全体を独自に再実装する必要があります。
定常状態の処理ニーズを上回るスループットを処理するために、バックフィルでもやはり、出力シンクにプロビジョニングするリソース量を少なくとも一時的には増やすことが重要です。
| シナリオ | 現在の時刻からの再開のみ | 最後に停止した時刻からの再開 | 現在の時刻からの再開 + アーカイブ済みのイベントでのバックフィル |
|---|---|---|---|
| ダッシュボード | 空白期間が生じる | 停止期間が短ければ問題なし | 停止期間が長い場合に使用 |
| アラート | 許容範囲内 | 停止期間が短ければ問題なし | 不要 |
| イベント ソーシング アプリ | 許容範囲内 | 停止期間が短ければ問題なし | 停止期間が長い場合に使用 |
| データ ウェアハウス | データ損失 | 許容範囲内 | 不要 |
| オフライン分析 | データ損失 | 許容範囲内 | 不要 |
まとめ
当然のことながら、複雑なエンド ツー エンドのシステムでは、前述したすべてのソリューション パターンを組み合わせることもできます。 そうして統合されたシステムには、ダッシュボード、アラート、イベント ソーシング アプリケーション、データ ウェアハウジング、オフライン分析機能を実装することができます。
その鍵は、コンポーザブルなパターンでシステムを設計し、それぞれのサブシステムを個別に構築、テスト、アップグレード、復旧できるようにすることです。
次のステップ
Azure Stream Analytics を使用したさまざまなソリューション パターンを見てきました。 次はさらに踏み込んで、初めての Stream Analytics ジョブを作成してみましょう。