Stream Analytics ストリーミング ユニットの理解と調整
ストリーミング ユニットとストリーミング ノードについて
ストリーミング ユニット (SU) は、Stream Analytics ジョブを実行するために割り当てられているコンピューティング リソースを表しています。 SU 数が大きいほど、多くの CPU とメモリ リソースがジョブ用に割り当てられます。 この能力により、クエリ ロジックに集中することができ、Stream Analytics ジョブがタイミングよく実行されるようハードウェアを管理する必要がなくなります。
Azure Stream Analytics は、SU V1 (非推奨) と SU V2 (推奨) の 2 つのストリーミング ユニット構造をサポートしています。
SU V1 モデルは、6 SU ごとにジョブの 1 個のストリーミング ノードに対応する ASA の最初のオファリングです。 ジョブは 1 SU でも 3 SU でも実行できます。これらは分数ストリーミング ノードに対応します。 分散コンピューティング リソースを提供するストリーミング ノードを追加することで、6 SU ジョブ以降は、12、18、24 ...と 6 SU 単位でスケーリングします。
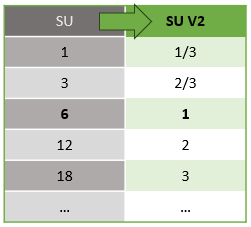
SU V2 モデル (推奨) は、同じコンピューティング リソースに対して有利な価格が設定された単純化された構造です。 SU V2 モデルでは、1 SU V2 がジョブの 1 個のストリーミング ノードに対応します。 2 SU V2 は 2 個、3 SU V2 は 3 個などと、ストリーミング ノードに対応します。 1/3 SU V2 ジョブおよび 2/3 SU V2 ジョブを 1 個のストリーミング ノードで使用することもできますが、提供されるコンピューティング リソースは部分的になります。 1/3 SU V2 ジョブおよび 2/3 SU V2 ジョブは、小規模なスケールを必要とするワークロードにコスト効率の高いオプションを提供します。
V1 ストリーミング ユニットおよび V2 ストリーミング ユニットの基盤となるコンピューティング能力は次のとおりです。
SU の価格については、「Azure Stream Analytics の価格に関するページ」をご覧ください。
ストリーミング ユニットの変換とその適用場所を理解する
REST API レイヤーから UI (Azure Portal と Visual Studio Code) に発生するストリーミング ユニットの自動変換があります。 この変換は、アクティビティ ログでも、SU 値が UI の値とは異なる場所に表示されます。 これは仕様であり、REST API フィールドは整数値に制限され、ASA ジョブは小数ノード (1/3 および 2/3 ストリーミング ユニット) をサポートしているためです。 ASA の UI には、ノード値 1/3、2/3、1、2、3、..が表示されます。 バックエンド (アクティビティ ログ、REST API レイヤー) では、それぞれ 3、7、10、20、30 と同じ値に 10 を乗算した値が表示されます。
| Standard | Standard V2 (UI) | Standard V2 (ログ、Rest API などのバックエンド) |
|---|---|---|
| 1 | 1/3 | 3 |
| 3 | 2/3 | 7 |
| 6 | 1 | 10 |
| 12 | 2 | 20 |
| 18 | 3 | 30 |
| ... | ... | ... |
これにより、同じ粒度を伝え、V2 SKU の API レイヤーの小数点をなくすことができます。 この変換は自動的に行われ、ジョブのパフォーマンスには影響しません。
消費量とメモリ使用率を把握する
待ち時間が短いストリーミング処理を実現するために、Azure Stream Analytics ジョブはすべての処理をメモリ内で実行します。 メモリが不足した場合は、ストリーミング ジョブが失敗します。 そのため、実稼働ジョブでは、ストリーミング ジョブのリソース使用状況を監視し、ジョブの稼働を 24 時間、週 7 日維持するのに十分なリソースが割り当てられていることを確認することが重要です。
SU 使用率 (%) メトリックはワークロードのメモリ消費量を表し、その範囲は 0% から 100% となります。 最小フットプリントのストリーミング ジョブでは、このメトリックの範囲は、通常 10% から 20% です。 SU% 使用率が高い (80% を超える) 場合、または入力イベントのバックログが発生する場合 (CPU 使用率が表示されないため、SU% 使用率が低い場合でもバックログが発生する) は、ワークロードがより多くのコンピューティング リソースを必要としている可能性があります。その場合は、ストリーミング ユニットの数を増やす必要があります。 偶発的なスパイクを考慮して、SU メトリックを 80% 未満に維持することをお勧めします。 増加したワークロードに対応し、ストリーミング ユニットを増やすには、SU 使用率メトリックが 80% でのアラートを設定することを検討してください。 また、透かしの遅延とバックログされたイベントのメトリックを使用して、影響があるかどうかを確認することもできます。
Stream Analytics のストリーミング ユニット (SU) を構成する
Azure portal にサインインする
リソースの一覧で、スケールする Stream Analytics ジョブを見つけて開きます。
ジョブ ページの [構成] 見出しで、 [スケーリング] を選択します。 ジョブを作成するときの既定の SU 数は 1 です。

ドロップダウン リストで SU オプションを選択して、ジョブの SU を設定します。 特定の SU 範囲に制限されていることに注意してください。
ジョブの実行中に、そのジョブに割り当てられた SU の数を変更することができます。 ジョブがパーティション分割されていない出力を使用する場合、または異なる PARTITION BY 値を持つマルチステップ クエリを実行する場合は、ジョブの実行中に選択できる SU 数が特定の SU 値のセットに制限される場合があります。
ジョブのパフォーマンスを監視する
Azure portal を使用して、ジョブのパフォーマンスに関連するメトリックを追跡することができます。 メトリックの定義については、Azure Stream Analytics ジョブのメトリックに関するページを参照してください。 ポータルでのメトリックの監視の詳細については、「Azure portal で Stream Analytics ジョブを監視する」を参照してください。
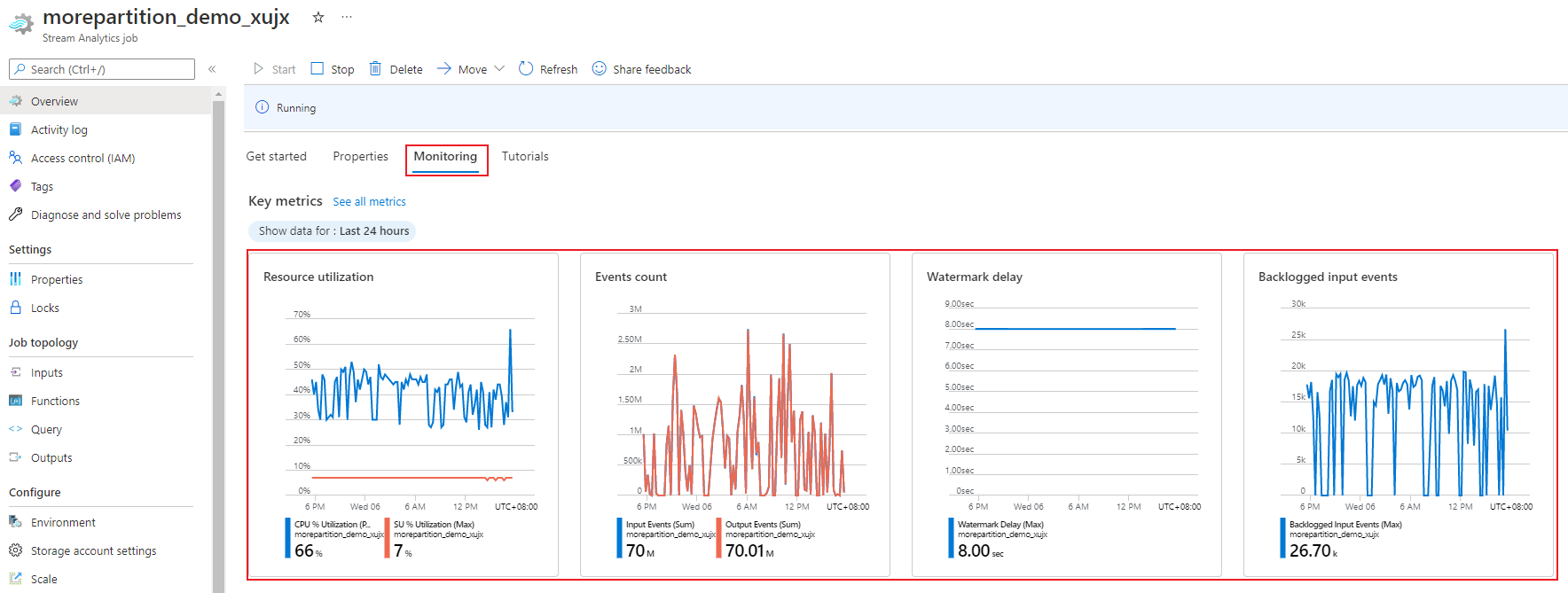
ワークロードの予想されるスループットを計算します。 スループットが予想よりも低い場合は、入力パーティションを調整し、クエリをチューニングして、ジョブに SU を追加します。
ジョブに必要な SU の数
特定のジョブに必要な SU の数の選択は、入力のパーティション構成と、ジョブで定義されたクエリによって異なります。 [スケール] ページでは、適切な SU の数を設定することができます。 SU は、必要な量より多めに割り当てておくことをお勧めします。 メモリをより多く割り当てると、Stream Analytics 処理エンジンによって待ち時間とスループットが最適化されます。
一般に、PARTITION BY を使用しないクエリの場合は、1 SU V2 から始めるのがベスト プラクティスです。 そのうえで、試行錯誤により最適な数を検討します。具体的には、典型的な量のデータを渡して SU% 使用率のメトリックを確認し、SU の数を調整する作業を繰り返すことによって、最適な SU の数を割り出します。 Stream Analytics ジョブで使用できるストリーミング ユニットの最大数は、ジョブに定義されたクエリのステップ数と各ステップのパーティション数によって異なります。 制限の詳細については、こちらを参照してください。
適切な SU 数の選択について詳しくは、「スループット向上のための Azure Stream Analytics ジョブのスケーリング」をご覧ください。
注意
特定のジョブに必要な SU 数の選択は、入力のパーティション構成と、ジョブに定義されたクエリによって異なります。 1 つのジョブについて、クォータまでの SU 数を選択できます。 Azure Stream Analytics サブスクリプション クォータの詳細については、「 Stream Analytics の制限」をご覧ください。 このクォータを超えてサブスクリプションの SU 数を増やす場合は、Microsoft サポートまでご連絡ください。 ジョブあたりの SU 数の有効な値は、1/3、2/3、1、2、3 などです。
SU の使用率が増加する要因
Stream Analytics によって提供されるステートフルな演算子のコア セットは、一時的な (時間指向の) クエリ要素です。 Stream Analytics では、サービスのアップグレード時の、メモリ消費量、回復性のチェックポイント処理、および状態の回復を管理することにより、ユーザーの代わりに内部的にこれらの操作の状態を管理します。 Stream Analytics では、状態を完全に管理していますが、ユーザーが考慮する必要のある推奨事項が多数があります。
複雑なクエリ ロジックを持つジョブは、入力イベントを継続的に受け取らない場合でも、高い SU 使用率 (%) になる可能性があることに注意してください。 これは、入出力イベントが突然急増した後に発生する可能性があります。 ジョブは、クエリが複雑な場合は、メモリ内に状態を保持し続けることがあります。
SU% 使用率は、予想されるレベルに戻る前に、短期間で突然 0 に低下することがあります。 この現象は、一時的なエラーや、システムによって開始されたアップグレードが原因で発生します。 クエリが完全に並列になっていない場合は、ジョブのストリーミング ユニットの数を増やしても、SU 使用率 (%) は減少しないことがあります。
一定期間にわたって使用率を比較している間、イベント率のメトリックを使用します。 InputEvents と OutputEvents のメトリックでは、読み取りおよび処理されたイベント数が示されます。 逆シリアル化エラーなど、エラー イベントの数を示すメトリックもあります。 時間単位あたりのイベント数が増えると、ほとんどの場合、SU 使用率 (%) が増加します。
一時的な要素のステートフルなクエリ ロジック
Azure Stream Analytics ジョブの固有の機能の 1 つに、ウィンドウ集計、一時的な結合、一時的な分析関数などのステートフル処理の実行があります。 これらの各演算子によって状態情報が保持されます。 これらのクエリ要素の最大ウィンドウ サイズは 7 日間です。
テンポラル ウィンドウの概念は、いくつかの Stream Analytics クエリ要素に現れます。
ウィンドウ集計 (タンブリング ウィンドウ、ホッピング ウィンドウ、スライディング ウィンドウの GROUP BY)
テンポラル結合: DATEDIFF 関数を使用した JOIN
テンポラル分析関数: LIMIT DURATION を使用した ISFIRST、LAST、LAG
Stream Analytics ジョブが使用するメモリ (ストリーミング ユニット メトリックの一部) は、次の要因の影響を受けます。
ウィンドウ集計
ウィンドウ集計用に使用されたメモリ (状態のサイズ) は、常にウィンドウのサイズと比例していません。 代わりに、使用されるメモリはデータの基数または各時間枠のグループ数と比例しています。
たとえば、次のクエリは、clusterid に関連付けられた数字がクエリの基数です。
SELECT count(*)
FROM input
GROUP BY clusterid, tumblingwindow (minutes, 5)
前のクエリで大きな基数によって引き起こされる問題を軽減するために、clusterid でパーティション分割されたイベントをイベント ハブに送信し、次の例で示すように PARTITION BY を使用してシステムで各入力パーティションを個別に処理できるようにすることでクエリをスケールアウトできます。
SELECT count(*)
FROM input PARTITION BY PartitionId
GROUP BY PartitionId, clusterid, tumblingwindow (minutes, 5)
クエリは、パーティション分割されると、複数のノードに広がります。 その結果、各ノードで受信される clusterid 値の数が削減されるため、group by 演算子の基数が減少します。
削減手順の必要性をなくすには、イベント ハブ パーティションをグループ化キーでパーティション分割する必要があります。 詳細については、「Event Hubs の概要」を参照してください。
一時的な結合
一時的な結合で消費されるメモリ (状態サイズ) は、イベント入力速度にウィグル領域サイズを乗算した、結合の一時的なウィグル領域におけるイベント数に比例します。 つまり、結合によって消費されたメモリは、平均イベント率に DateDiff 時間の範囲を掛けたものと比例しています。
結合内の不一致のイベントの数は、クエリのメモリ使用率に影響します。 次のクエリは、クリックに結びつく広告のインプレッションを検索します。
SELECT clicks.id
FROM clicks
INNER JOIN impressions ON impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10.
この例では、多数の広告が表示されても、ほとんどのユーザーがクリックしていない可能性があり、時間枠内にすべてのイベントを保持する必要があります。 消費されるメモリは、時間枠のサイズおよびイベント レートに比例します。
これを修復するには、結合キー (この場合は ID) でパーティション分割されたイベントをイベント ハブに送信し、次に示すように PARTITION BY を使用して各入力パーティションをシステムが個別に処理できるようにすることでクエリをスケールアウトします。
SELECT clicks.id
FROM clicks PARTITION BY PartitionId
INNER JOIN impressions PARTITION BY PartitionId
ON impression.PartitionId = clicks.PartitionId AND impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10
クエリは、パーティション分割されると、複数のノードに広がります。 その結果、各ノードで受信されるイベントの数が減少するため、結合ウィンドウに保持される状態のサイズが減少します。
一時的な分析関数
一時的な分析関数で使用されたメモリ (状態サイズ) は、期間で乗算したイベント レートに比例します。 分析関数によって消費されるメモリは、時間枠のサイズではなく、むしろ各時間枠のパーティション数に比例しています。
修復は、一時的な結合と同様です。 PARTITION BY を使用してクエリをスケールアウトできます。
誤順序バッファー
ユーザーは、[イベント順序] 構成ウィンドウで誤順序バッファー サイズを構成できます。 バッファーは、ウィンドウの継続期間にわたって入力を保持し、それらを並べ替えるために使用されます。 バッファーのサイズは、誤順序ウィンドウのサイズを乗算したイベント入力速度に比例します。 既定のウィンドウ サイズは 0 です。
誤順序バッファーのオーバーフローを修復するには、PARTITION BY を使用してクエリをスケールアウトします。 クエリは、パーティション分割されると、複数のノードに広がります。 その結果、各ノードで受信されるイベントの数が減少するため、各並べ替えバッファー内のイベント数が減少します。
入力パーティション数
ジョブ入力の各入力パーティションにはバッファーがあります。 入力パーティション数が多いほど、ジョブで消費されるリソースが多くなります。 ストリーミング ユニットごとに、Azure Stream Analytics は約 7 MB/秒の入力を処理できます。 したがって、Stream Analytics のストリーミング ユニットの数と、イベント ハブのパーティション数を調整することにより、最適化することができます。
2 つのパーティション (イベント ハブの最小数) を持つイベント ハブでは、通常、1/3 ストリーミング ユニットで構成されたジョブで十分です。 イベント ハブにより多くのパーティションがある場合、Stream Analytics ジョブはより多くのリソースを消費しますが、イベント ハブによって提供される追加のスループットを必ずしも使用しません。
1 V2 ストリーミング ユニットを持つジョブでは、イベント ハブに 4 個または 8 個のパーティションが必要になる場合があります。 ただし、リソースの使用を抑えるために不要なパーティションは増やさないようにします。 たとえば、ストリーミング ユニットが 1 つある Stream Analytics ジョブで、イベント ハブのパーティションが 16 以上ある場合などです。
参照データ
ASA の参照データは、高速検索を行うためにメモリに読み込まれます。 現在の実装では、同じ参照データで複数回結合する場合でも、参照データを使用する結合操作ごとに参照データのコピーがメモリに保持されます。 PARTITION BY を使用したクエリでは、各パーティションに参照データのコピーが 1 つあるため、パーティションは完全に分離されます。 相乗効果により、複数のパーティションで参照データを使用して複数回結合した場合、メモリ使用量がすぐに非常に高くなることがあります。
UDF 関数の使用
UDF 関数を追加すると、Azure Stream Analytics は、JavaScript ランタイムをメモリに読み込みます。 これは SU% に影響します。