RHEL で Azure NetApp Files を使用した SAP HANA スケールアップの高可用性
この記事では、HANA ファイル システムが Azure NetApp Files を使用して NFS 経由でマウントされている場合に、SAP HANA システム レプリケーションをスケールアップ デプロイで構成する方法について説明します。 サンプルの構成およびインストール コマンドでは、インスタンス番号として 03、HANA システム ID として HN1 が使用されています。 SAP HANA システム レプリケーション は、1 つのプライマリ ノードと、少なくとも 1 つのセカンダリ ノードで構成されています。
このドキュメントの各手順に付いているプレフィックスとその意味は次のとおりです。
- [A] :この手順はすべてのノードに適用されます
- [1] :この手順は node1 にのみ適用されます
- [2] :この手順は node2 にのみ適用されます
前提条件
はじめに、次の SAP Note およびガイドを確認してください
- SAP Note 1928533: 次の情報が含まれています。
- SAP ソフトウェアのデプロイでサポートされる Azure 仮想マシン (VM) サイズのリスト。
- Azure VM サイズの容量に関する重要な情報。
- サポートされる SAP ソフトウェア、およびオペレーティング システム (OS) とデータベースの組み合わせ。
- Microsoft Azure 上の Windows と Linux に必要な SAP カーネル バージョン。
- SAP Note 2015553: SAP でサポートされる Azure 上の SAP ソフトウェア デプロイの前提条件が記載されています。
- SAP ノート 405827 には、HANA 環境の推奨ファイル システムがリストされています。
- SAP Note 2002167: Red Hat Enterprise Linux 用の OS 設定が推奨されています。
- SAP Note 2009879: Red Hat Enterprise Linux 用の SAP HANA ガイドラインが記載されています。
- SAP Note 3108302 には、Red Hat Enterprise Linux 9.x 用の SAP HANA ガイドラインがあります。
- SAP Note 2178632: Azure 上の SAP について報告されるすべての監視メトリックに関する詳細情報が記載されています。
- SAP Note 2191498: Azure 上の Linux に必要な SAP Host Agent のバージョンが記載されています。
- SAP Note 2243692: Azure 上の Linux で動作する SAP のライセンスに関する情報が記載されています。
- SAP Note 1999351はAzure Enhanced モニタリング拡張機能 for SAP に関するその他のトラブルシューティング情報が記載されています。
- SAP Community Wiki には、Linux に必要なすべての SAP Note が掲載されています。
- Linux 上の SAP のための Azure Virtual Machines の計画と実装
- Linux 上の SAP のための Azure Virtual Machines のデプロイ
- Linux 上の SAP のための Azure Virtual Machines DBMS のデプロイ
- Pacemaker クラスターでの SAP HANA システム レプリケーション
- Red Hat Enterprise Linux (RHEL) の一般的なドキュメント:
- Azure 固有の RHEL ドキュメント:
- SAP HANA 用 Azure NetApp Files 上の NFS v4.1 ボリューム
概要
従来、スケールアップ環境では、SAP HANA のすべてのファイル システムはローカル ストレージからマウントされていました。 Red Hat Enterprise Linux での SAP HANA システム レプリケーションの高可用性 (HA) の設定については、「RHEL での SAP HANA システム レプリケーションの設定」で公開されています。
Azure NetApp Files NFS 共有でスケールアップ システムの SAP HANA HA を実現するには、1 つのノードで Azure NetApp Files 上の NFS 共有へのアクセスが失われたときに HANA リソースが回復するために、追加のリソース構成がクラスターに必要です。 クラスターは NFS マウントを管理して、リソースの正常性を監視できるようにします。 ファイル システム マウントと SAP HANA リソース間の依存関係が適用されます。
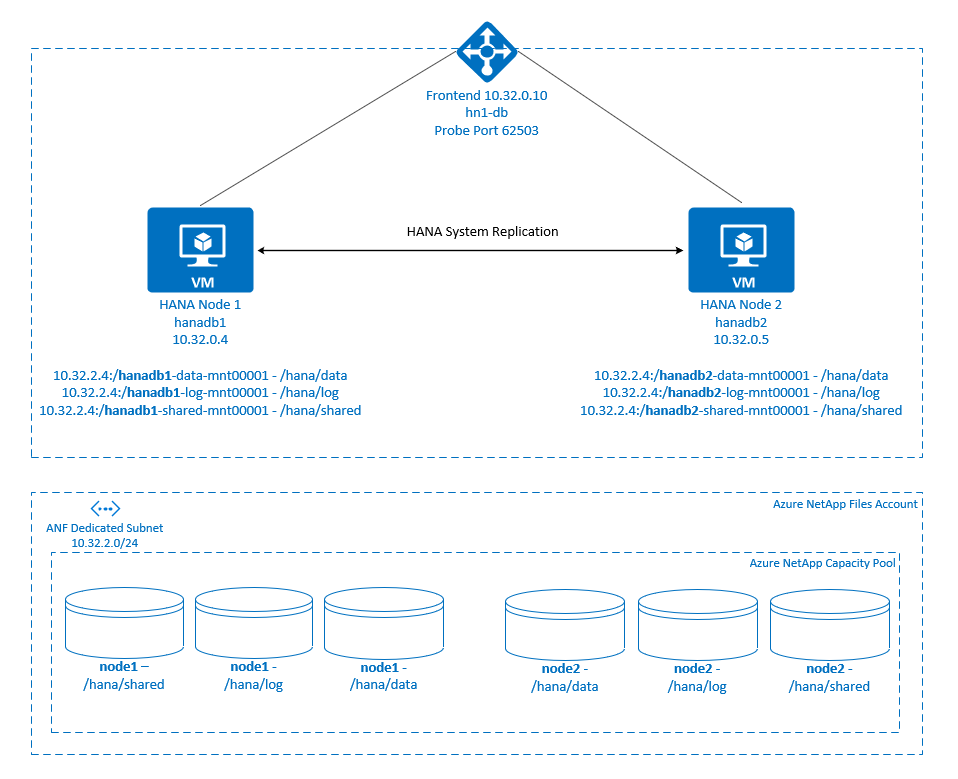 .
.
SAP HANA ファイル システムは、各ノードで Azure NetApp Files を使用して NFS 共有にマウントされます。 ファイル システム /hana/data、/hana/log、および /hana/shared は、各ノードに固有です。
node1 にマウント (hanadb1):
- /hana/data の 10.32.2.4:/hanadb1-data-mnt00001
- /hana/log の 10.32.2.4:/hanadb1-log-mnt00001
- /hana/shared の 10.32.2.4:/hanadb1-shared-mnt00001
node2 にマウント (hanadb2):
- /hana/data の 10.32.2.4:/hanadb2-data-mnt00001
- /hana/log の 10.32.2.4:/hanadb2-log-mnt00001
- /hana/shared の 10.32.2.4:/hanadb2-shared-mnt00001
Note
ファイル システム /hana/shared、/hana/data、および /hana/log は、2 つのノード間で共有されません。 各クラスター ノードには、独自の独立したファイル システムがあります。
SAP HANA システム レプリケーションの構成では、専用の仮想ホスト名と仮想 IP アドレスが使用されます。 Azure では、仮想 IP アドレスを使用するためにロード バランサーが必要になります。 以下に示す構成には、次のようなロード バランサーが含まれています。
- フロントエンド IP アドレス: 10.32.0.10 (hn1-db)
- プローブ ポート: 62503
Azure NetApp Files インフラストラクチャを設定する
Azure NetApp Files インフラストラクチャの設定を続行する前に、「Azure NetApp Files のドキュメント」の内容をよく理解しておいてください。
Azure NetApp Files はいくつかの Azure リージョンで利用できます。 選択した Azure リージョンで Azure NetApp Files が提供されているかどうかを確認してください。
Azure リージョン別の Azure NetApp Files の利用可能性については、Azure リージョン別の Azure NetApp Files の利用可能性に関するページを参照してください。
重要な考慮事項
SAP HANA スケールアップ システム用の Azure NetApp Files ボリュームを作成するときは、「SAP HANA 用 Azure NetApp Files 上の NFS v4.1 ボリューム」に記載されている重要な考慮事項に注意してください。
Azure NetApp Files での HANA データベースのサイズ指定
Azure NetApp Files ボリュームのスループットは、「Azure NetApp Files のサービス レベル」に記載されているように、ボリューム サイズとサービス レベルの機能です。
Azure NetApp Files を使用して SAP HANA on Azure 用のインフラストラクチャを設計するときは、「SAP HANA 用 Azure NetApp Files 上の NFS v4.1 ボリューム」に記載されている推奨事項に注意してください。
この記事の構成には、単純な Azure NetApp Files ボリュームが含まれています。
重要
パフォーマンスが重要な運用システムの場合は、SAP HANA の Azure NetApp Files アプリケーション ボリューム グループを評価し、使用を検討することをお勧めします。
Azure NetApp Files リソースのデプロイ
以下の手順では、ご使用の Azure 仮想ネットワークが既にデプロイされていることを前提としています。 Azure NetApp Files のリソースと、そのリソースがマウントされる VM は、同じ Azure 仮想ネットワーク内またはピアリングされた Azure 仮想ネットワーク内にデプロイする必要があります。
「NetApp アカウントを作成する」の手順に従って、選択した Azure リージョンに NetApp アカウントを作成します。
Azure NetApp Files の容量プールの設定に関するページの手順に従って、Azure NetApp Files の容量プールを設定します。
この記事で示されている HANA アーキテクチャでは、Ultra サービス レベルで 1 つの Azure NetApp Files 容量プールが使用されています。 Azure 上の HANA ワークロードの場合、Azure NetApp Files の Ultra または Premiumサービス レベルを使用することをお勧めします。
「サブネットを Azure NetApp Files に委任する」の手順に従って、サブネットを Azure NetApp Files に委任します。
「Azure NetApp Files の NFS ボリュームを作成する」の手順に従って、Azure NetApp Files のボリュームをデプロイします。
ボリュームをデプロイするときは、NFSv4.1 バージョンを必ず選択してください。 指定された Azure NetApp Files のサブネット内にボリュームをデプロイします。 Azure NetApp ボリュームの IP アドレスは、自動的に割り当てられます。
Azure NetApp Files のリソースと Azure VM は、同じ Azure 仮想ネットワーク内またはピアリングされた Azure 仮想ネットワーク内に配置する必要があることに注意してください。 たとえば、
hanadb1-data-mnt00001とhanadb1-log-mnt00001はボリューム名で、nfs://10.32.2.4/hanadb1-data-mnt00001とnfs://10.32.2.4/hanadb1-log-mnt00001は Azure NetApp Files ボリュームのファイル パスです。hanadb1:
- ボリューム hanadb1-data-mnt00001 (nfs://10.32.2.4:/hanadb1-data-mnt00001)
- ボリューム hanadb1-log-mnt00001 (nfs://10.32.2.4:/hanadb1-log-mnt00001)
- ボリューム hanadb1-shared-mnt00001 (nfs://10.32.2.4:/hanadb1-shared-mnt00001)
hanadb2:
- ボリューム hanadb2-data-mnt00001 (nfs://10.32.2.4:/hanadb2-data-mnt00001)
- ボリューム hanadb2-log-mnt00001 (nfs://10.32.2.4:/hanadb2-log-mnt00001)
- ボリューム hanadb2-shared-mnt00001 (nfs://10.32.2.4:/hanadb2-shared-mnt00001)
Note
この記事で /hana/shared をマウントするすべてのコマンドは、NFSv4.1 の /hana/shared ボリュームに対して示されています。
/hana/shared ボリュームを NFSv3 ボリュームとしてデプロイした場合は、必ず /hana/shared のマウント コマンドを NFSv3 用に調整してください。
インフラストラクチャの準備
Azure Marketplace には、高可用性アドオンを備えた SAP HANA に適したイメージが含まれています。これは、さまざまなバージョンの Red Hat を使用して新しい VM をデプロイするために使用できます。
Azure portal 経由での手動による Linux VM のデプロイ
このドキュメントは、リソース グループ、Azure Virtual Network、サブネットが既にデプロイ済みであることを前提としています。
SAP HANA 用の VM をデプロイします。 HANA システムでサポートされている適切な RHEL イメージを選択します。 VM は、仮想マシン スケール セット、可用性ゾーン、可用性セットのいずれかの可用性オプションでデプロイできます。
重要
選択した OS が、デプロイで使用する予定の特定の種類の VM 上の SAP HANA に対して SAP 認定されていることを確認してください。 SAP HANA 認定されている VM の種類とその OS リリースは、「SAP HANA 認定されている IaaS プラットフォーム」で調べることができます。 特定の VM の種類に対して SAP HANA でサポートされている OS のリリースの完全な一覧を取得するために、VM の種類の詳細を確認するように注意してください。
Azure Load Balancer の構成
VM 構成中に、ネットワーク セクションでロード バランサーを作成するか既存のものを選択する選択肢もあります。 HANA データベースの高可用性セットアップ用に Standard Load Balancer をセットアップするには、次の手順のようにします。
Azure portal を使って高可用性 SAP システム用の標準ロード バランサーを設定するには、「ロード バランサーの作成」の手順に従います。 ロード バランサーのセットアップ時には、以下の点を考慮してください。
- フロントエンド IP 構成: フロントエンド IP を作成します。 お使いのデータベース仮想マシンと同じ仮想ネットワークとサブネットを選択します。
- バックエンド プール: バックエンド プールを作成し、データベース VM を追加します。
- インバウンド規則: 負荷分散規則を作成します。 両方の負荷分散規則で同じ手順に従います。
- フロントエンド IP アドレス: フロントエンド IP を選択します。
- バックエンド プール: バックエンド プールを選択します。
- 高可用性ポート: このオプションを選択します。
- [プロトコル]: [TCP] を選択します。
- 正常性プローブ: 次の詳細を使って正常性プローブを作成します。
- [プロトコル]: [TCP] を選択します。
- ポート: 例: 625<インスタンス番号>。
- サイクル間隔: 「5」と入力します。
- プローブしきい値: 「2」と入力します。
- アイドル タイムアウト (分): 「30」と入力します。
- フローティング IP を有効にする: このオプションを選択します。
Note
正常性プローブ構成プロパティ numberOfProbes (ポータルでは [異常なしきい値] とも呼ばれます) は考慮されません。 成功または失敗した連続プローブの数を制御するには、プロパティ probeThreshold を 2 に設定します。 現在、このプロパティは Azure portal を使用して設定できないため、Azure CLI または PowerShell コマンドを使用してください。
SAP HANA に必要なポートについて詳しくは、SAP HANA テナント データベース ガイドのテナント データベースへの接続に関する章または SAP Note 2388694 を参照してください。
重要
フローティング IP は、負荷分散シナリオの NIC セカンダリ IP 構成ではサポートされていません。 詳細については、Azure Load Balancer の制限事項に関する記事を参照してください。 VM に別の IP アドレスが必要な場合は、2 つ目の NIC をデプロイします。
Note
パブリック IP アドレスのない VM が、Standard の Azure Load Balancer の内部 (パブリック IP アドレスのない) インスタンスのバックエンド プール内に配置されている場合、パブリック エンドポイントへのルーティングを許可するように追加の構成が実行されない限り、アウトバウンド インターネット接続はありません。 アウトバウンド接続を実現する方法の詳細については、SAP の高可用性シナリオにおける Azure Standard Load Balancer を使用した Virtual Machines のパブリック エンドポイント接続に関する記事を参照してください。
重要
Azure Load Balancer の背後に配置された Azure VM では TCP タイムスタンプを有効にしないでください。 TCP タイムスタンプを有効にすると正常性プローブが失敗する可能性があります。 パラメーター net.ipv4.tcp_timestamps を 0 に設定します。 詳細については、「Azure Load Balancer の正常性プローブ」と、SAP Note 2382421 をご覧ください。
Azure NetApp Files ボリュームのマウント
[A] HANA データベース ボリュームのマウント ポイントを作成します。
sudo mkdir -p /hana/data sudo mkdir -p /hana/log sudo mkdir -p /hana/shared[A] NFS ドメイン設定を確認します。 ドメインが既定の Azure NetApp Files ドメイン (つまり、defaultv4iddomain.com) として構成され、マッピングが nobody に設定されていることを確認します。
sudo cat /etc/idmapd.conf出力例:
[General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobody重要
Azure NetApp Files の既定のドメイン構成 (defaultv4iddomain.com) と一致するように、VM 上の
/etc/idmapd.confに NFS ドメインを設定していることを確認します。 NFS クライアント (つまり、VM) と NFS サーバー (つまり、Azure NetApp Files 構成) のドメイン構成が一致しない場合、VM にマウントされている Azure NetApp Files ボリューム上のファイルに対するアクセス許可はnobodyと表示されます。[1] node1 (hanadb1) にノード固有のボリュームをマウントします。
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-shared-mnt00001 /hana/shared sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-log-mnt00001 /hana/log sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-data-mnt00001 /hana/data[2] node2 (hanadb2) にノード固有のボリュームをマウントします。
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-shared-mnt00001 /hana/shared sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-log-mnt00001 /hana/log sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-data-mnt00001 /hana/data[A] すべての HANA ボリュームが NFS プロトコル バージョン NFSv4 でマウントされていることを確認します。
sudo nfsstat -mフラグ
versが 4.1 に設定されていることを確認します。 hanadb1 の例:/hana/log from 10.32.2.4:/hanadb1-log-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4 /hana/data from 10.32.2.4:/hanadb1-data-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4 /hana/shared from 10.32.2.4:/hanadb1-shared-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4[A]nfs4_disable_idmapping を確認します。 これは、Y に設定されている必要があります。nfs4_disable_idmapping が配置されるディレクトリ構造を作成するには、mount コマンドを実行します。 アクセスがカーネルとドライバー用に予約されるため、
/sys/modulesの下に手動でディレクトリを作成することはできません。nfs4_disable_idmappingを確認します。sudo cat /sys/module/nfs/parameters/nfs4_disable_idmappingnfs4_disable_idmappingを次のように設定する必要がある場合:sudo echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmapping構成を永続的にします。
sudo echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.conf
nfs_disable_idmappingパラメーターを変更する方法の詳細については、Red Hat ナレッジ ベースを参照してください。
SAP HANA のインストール
[A] すべてのホストにホスト名解決を設定します。
DNS サーバーを使用するか、すべてのノードの
/etc/hostsファイルを変更することができます。 この例では、/etc/hostsファイルを使用する方法を示します。 次のコマンドの IP アドレスとホスト名を置き換えます。sudo vi /etc/hosts/etc/hostsファイルに次の行を挿入します。 お使いの環境に合わせて IP アドレスとホスト名を変更します。10.32.0.4 hanadb1 10.32.0.5 hanadb2[A] SAP ノート 3024346 - Linux Kernel Settings for NetApp NFS の説明に従って、NFS を使用して Azure NetApp 上で SAP HANA を実行する目的で OS を準備します。 NetApp 構成設定用に構成ファイル
/etc/sysctl.d/91-NetApp-HANA.confを作成します。sudo vi /etc/sysctl.d/91-NetApp-HANA.conf構成ファイルに次のエントリを追加します。
net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[A] より多くの最適化設定を含む構成ファイル
/etc/sysctl.d/ms-az.confを作成します。sudo vi /etc/sysctl.d/ms-az.conf構成ファイルに次のエントリを追加します。
net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10ヒント
SAP ホスト エージェントからポート範囲を管理できるように、
sysctl構成ファイルでは明示的にnet.ipv4.ip_local_port_rangeとnet.ipv4.ip_local_reserved_portsを設定しないでください。 詳細については、SAP ノート 2382421 を参照してください。[A] SAP ノート 3024346 - Linux Kernel Settings for NetApp NFS で推奨されているように、
sunrpc設定を調整します。sudo vi /etc/modprobe.d/sunrpc.conf次の行を挿入します。
options sunrpc tcp_max_slot_table_entries=128[A] HANA 用の RHEL OS 構成を実行します。
RHEL のバージョンに基づいて、次の SAP ノートの説明に従って OS を構成します。
[A] SAP HANA をインストールします。
HANA 2.0 SPS 01 から、MDC が既定のオプションです。 HANA システムをインストールすると、SYSTEMDB と、同じ SID を持つテナントが一緒に作成されます。 既定のテナントが必要ない場合もあります。 インストール時に初期テナントを作成しない場合は、SAP ノート 2629711 の指示に従ってください。
HANA DVD から hdblcm プログラムを実行します。 プロンプトで次の値を入力します。
- [Choose installation](インストールの選択): 「1」(インストールの場合) を入力します。
- [Select more components for installation](インストールする追加コンポーネントの選択): 「1」と入力します。
- [Enter Installation Path](インストール パスの入力) [/hana/shared]: Enter キーを押して既定値をそのまま使用します。
- [Enter Local Host Name](ローカル ホスト名の入力) [..]: Enter キーを押して既定値をそのまま使用します。 Do you want to add additional hosts to the system? (システムに別のホストを追加しますか?) (y/n) [n]: n。
- [Enter SAP HANA System ID](SAP HANA システム ID の入力): 「HN1」と入力します。
- [Enter Instance Number](インスタンス番号の入力) [00]: 「03」と入力します。
- [Select Database Mode / Enter Index](データベース モードの選択/インデックスを入力) [1]: Enter キーを押して既定値をそのまま使用します。
- [Select System Usage / Enter Index](システム用途の選択/インデックスを入力) [4]: 「4」を入力します (カスタム)。
- [Enter Location of Data Volumes](データ ボリュームの場所を入力) [/hana/data]: Enter キーを押して既定値をそのまま使用します。
- [Enter Location of Log Volumes](ログ ボリュームの場所を入力) [/hana/log]: Enter キーを押して既定値をそのまま使用します。
- Restrict maximum memory allocation? (メモリの最大割り当てを制限しますか?) [n]: Enter キーを押して既定値をそのまま使用します。
- [Enter Certificate Host Name For Host '...'](ホスト '...' の証明書ホスト名を入力) [...]: Enter キーを押して既定値をそのまま使用します。
- [Enter SAP Host Agent User (sapadm) Password](SAP ホスト エージェント ユーザー (sapadm) のパスワードの入力): ホスト エージェントのユーザー パスワードを入力します。
- [Confirm SAP Host Agent User (sapadm) Password](SAP ホスト エージェント ユーザー (sapadm) のパスワードの確認入力): 確認のためにホスト エージェントのユーザー パスワードをもう一度入力します。
- [Enter System Administrator (hn1adm) Password](システム管理者 (hn1adm) のパスワードの入力): システム管理者のパスワードを入力します。
- [Confirm System Administrator (hn1adm) Password](システム管理者 (hn1adm) のパスワードの確認入力): 確認のためにシステム管理者のパスワードをもう一度入力します。
- [Enter System Administrator Home Directory](システム管理者のホーム ディレクトリを入力) [/usr/sap/HN1/home]: Enter キーを押して既定値をそのまま使用します。
- [Enter System Administrator Login Shell](システム管理者のログイン シェルを入力) [/bin/sh]: Enter キーを押して既定値をそのまま使用します。
- [Enter System Administrator User ID](システム管理者のユーザー ID を入力) [1001]: Enter キーを押して既定値をそのまま使用します。
- [Enter ID of User Group (sapsys)](ユーザー グループ (sapsys) のID を入力) [79]: Enter キーを押して既定値をそのまま使用します。
- [Enter Database User (SYSTEM) Password](データベース ユーザー (SYSTEM) のパスワードの入力): データベース ユーザーのパスワードを入力します。
- Confirm Database User (SYSTEM) Password (データベース ユーザー (SYSTEM) のパスワードを確認): 確認用にデータベース ユーザーのパスワードを再入力します。
- Restart system after machine reboot? (コンピューターの再起動後にシステムを再起動しますか?) [n]: Enter キーを押して既定値をそのまま使用します。
- 続行しますか? (y/n): 概要を確認します。 「y」と入力して続行します。
[A] SAP Host Agent をアップグレードします。
SAP Software Center から最新の SAP Host Agent アーカイブをダウンロードし、次のコマンドを実行してエージェントをアップグレードします。 アーカイブのパスを置き換えて、ダウンロードしたファイルを示すようにします。
sudo /usr/sap/hostctrl/exe/saphostexec -upgrade -archive <path to SAP Host Agent SAR>[A] ファイアウォールを構成します。
Azure Load Balancer のプローブ ポート用にファイアウォール規則を作成します。
sudo firewall-cmd --zone=public --add-port=62503/tcp sudo firewall-cmd --zone=public --add-port=62503/tcp –permanent
SAP HANA システム レプリケーションの構成
SAP HANA システム レプリケーションのセットアップの手順に従って、SAP HANA システム レプリケーションを構成します。
クラスター構成
このセクションでは、Azure NetApp Files を使用して NFS 共有に SAP HANA をインストールしている場合に、クラスターをシームレスに運用するために必要な手順について説明します。
Pacemaker クラスターの作成
Azure での Red Hat Enterprise Linux に対する Pacemaker のセットアップに関する記事の手順に従って、この HANA サーバーに対して基本的な Pacemaker クラスターを作成します。
重要
systemd ベースの SAP スタートアップ フレームワークにより、SAP HANA インスタンスを systemd で管理できるようになりました。 必要な Red Hat Enterprise Linux (RHEL) の最小バージョンは RHEL 8 for SAP です。 SAP Note 3189534 で説明されているように、SAP HANA SPS07 リビジョン 70 以降の新規インストール、または HANA 2.0 SPS07 リビジョン 70 以降への HANA システムの更新では、SAP スタートアップ フレームワークが systemd に自動的に登録されます。
HA ソリューションを使い、systemd 対応 SAP HANA インスタンスと組み合わせて SAP HANA システムのレプリケーションを管理する場合は (SAP Note 3189534 を参照)、HA クラスターが systemd の干渉なしに SAP インスタンスを管理できるようにするための追加手順が必要です。 そのため、systemd と統合された SAP HANA システムの場合は、すべてのクラスター ノードで Red Hat KBA 7029705 で説明されている追加手順のようにする必要があります。
Python システム レプリケーション フック SAPHanaSR を実装する
この手順は、クラスターとの統合を最適化し、クラスターのフェールオーバーが必要になった場合の検出を改善するための重要な手順です。 SAPHanaSR Python フックを構成することを強くお勧めします。 「Python システム レプリケーション フック SAPHanaSR を実装する」の手順を実行します。
ファイル システム リソースの構成
この例では、各クラスター ノードに独自の HANA NFS ファイル システム /hana/shared、/hana/data、および /hana/log があります。
[1] クラスターをメンテナンス モードにします。
sudo pcs property set maintenance-mode=true[1]hanadb1 マウント用のファイル システム リソースを作成します。
sudo pcs resource create hana_data1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-data-mnt00001 directory=/hana/data fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs sudo pcs resource create hana_log1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-log-mnt00001 directory=/hana/log fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs sudo pcs resource create hana_shared1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-shared-mnt00001 directory=/hana/shared fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs[2]hanadb2 マウント用のファイル システム リソースを作成します。
sudo pcs resource create hana_data2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-data-mnt00001 directory=/hana/data fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfs sudo pcs resource create hana_log2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-log-mnt00001 directory=/hana/log fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfs sudo pcs resource create hana_shared2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-shared-mnt00001 directory=/hana/shared fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfs監視ごとにファイル システムの読み取り/書き込みテストを実行するように、
OCF_CHECK_LEVEL=20属性が監視操作に追加されます。 この属性がない場合、監視操作ではファイル システムがマウントされていることのみを確認します。 接続が失われると、アクセス不可能であるにもかかわらずファイル システムがマウントされたままになる場合があるため、これは問題になる可能性があります。on-fail=fence属性も監視操作に追加されます。 このオプションを使用すると、ノードで監視操作が失敗した場合、そのノードはすぐにフェンスされます。 このオプションがない場合、既定の動作では、障害が発生したリソースに依存するすべてのリソースが停止され、障害が発生したリソースが再起動されてから、障害が発生したリソースに依存するすべてのリソースが起動されます。障害が発生したリソースに SAPHana リソースが依存している場合、この動作は時間がかかる可能性があるだけでなく、完全に失敗する可能性もあります。 HANA 実行可能ファイルを保持している NFS サーバーにアクセスできない場合、SAPHana リソースは正常に停止できません。
推奨されるタイムアウト値を使用すると、クラスター リソースが、NFSv4.1 リース更新に関連するプロトコル固有の一時停止に耐えられるようになります。 詳細については、NetApp での NFS のベスト プラクティスに関するページを参照してください。 上記の構成のタイムアウトは、特定の SAP セットアップに合わせて調整する必要がある場合があります。
より高いスループットを必要とするワークロードの場合は、「SAP HANA 用 Azure NetApp Files 上の NFS v4.1 ボリューム」で説明されているように
nconnectマウント オプションの使用を検討してください。nconnectが、ご使用の Linux リリースの Azure NetApp Files でサポートされているかどうかを確認します。[1] 場所の制約を構成します。
hanadb1 固有のマウントを管理するリソースを hanadb2 で決して実行できないように、またその逆も起きないように、場所の制約を構成します。
sudo pcs constraint location hanadb1_nfs rule score=-INFINITY resource-discovery=never \#uname eq hanadb2 sudo pcs constraint location hanadb2_nfs rule score=-INFINITY resource-discovery=never \#uname eq hanadb1resource-discovery=neverオプションを設定するのは、各ノード固有のマウントで同じマウント ポイントを共有するからです。 たとえば、hana_data1はマウント ポイント/hana/dataを使用し、hana_data2もマウント ポイント/hana/dataを使用します。 同じマウント ポイントを共有することにより、クラスター起動時にリソースの状態をチェックするときにプローブ操作の誤検出が起きる可能性があり、その結果として不要な回復動作が発生する可能性があります。 このシナリオを回避するには、resource-discovery=neverを設定します。[1] 属性リソースを構成します。
属性リソースを構成します。 これらの属性は、ノードのすべての NFS マウント (
/hana/data、/hana/log、および/hana/data) がマウントされている場合に true に設定されます。 それ以外の場合は、false に設定されます。sudo pcs resource create hana_nfs1_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs1_active sudo pcs resource create hana_nfs2_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs2_active[1] 場所の制約を構成します。
hanadb1 の属性リソースが hanadb2 で決して実行されないように、またその逆も起きないように、場所の制約を構成します。
sudo pcs constraint location hana_nfs1_active avoids hanadb2 sudo pcs constraint location hana_nfs2_active avoids hanadb1[1] 順序制約を作成します。
ノードの NFS マウントがすべてマウントされた後でないとノードの属性リソースが起動しないように、順序制約を構成します。
sudo pcs constraint order hanadb1_nfs then hana_nfs1_active sudo pcs constraint order hanadb2_nfs then hana_nfs2_activeヒント
構成にグループ
hanadb1_nfsまたはhanadb2_nfsの外部のファイル システムが含まれる場合は、ファイル システム間に順序の依存関係がなくなるように、sequential=falseオプションを含めます。 すべてのファイル システムは、相対的な起動順序の制約はありませんが、hana_nfs1_activeよりも先に起動しなければなりません。 詳細については、HANA ファイル システムが NFS 共有にある場合に Pacemaker クラスターでのスケールアップで SAP HANA システム レプリケーションを構成する方法に関する記事を参照してください。
SAP HANA クラスター リソースの構成
「SAP HANA クラスター リソースの作成」の手順に従って、クラスターに SAP HANA リソースを作成します。 SAP HANA リソースを作成したら、SAP HANA リソースとファイル システム (NFS マウント) の間に場所ルール制約を作成する必要があります。
[1] SAP HANA リソースと NFS マウント間の制約を構成します。
ノードの NFS マウントがすべてマウントされている場合にのみ SAP HANA リソースをノードで実行できるように、場所ルール制約を設定します。
sudo pcs constraint location SAPHanaTopology_HN1_03-clone rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne trueRHEL 7.x の場合:
sudo pcs constraint location SAPHana_HN1_03-master rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne trueRHEL 8.x/9.x の場合:
sudo pcs constraint location SAPHana_HN1_03-clone rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne trueクラスターのメンテナンス モードを解除します。
sudo pcs property set maintenance-mode=falseクラスターとすべてのリソースの状態をチェックします。
Note
この記事には、Microsoft が使用しなくなった用語への言及が含まれています。 ソフトウェアからこの用語が削除された時点で、この記事から削除します。
sudo pcs status出力例:
Online: [ hanadb1 hanadb2 ] Full list of resources: rsc_hdb_azr_agt(stonith:fence_azure_arm): Started hanadb1 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem):Started hanadb1 hana_log1 (ocf::heartbeat:Filesystem):Started hanadb1 hana_shared1 (ocf::heartbeat:Filesystem):Started hanadb1 Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Started hanadb1 hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb1 hanadb2 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb1 ] Slaves: [ hanadb2 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb1 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb1
Pacemaker クラスターで HANA アクティブ/読み取り可能のシステム レプリケーションを構成する
SAP HANA 2.0 SPS 01 以降では、SAP HANA システム レプリケーションでアクティブ/読み取り可能のセットアップを使用できます。この場合、読み取り処理の多いワークロードに対して SAP HANA システム レプリケーションのセカンダリ システムを積極的に活用できます。 クラスターでこのような設定をサポートするには、2 番目の仮想 IP アドレスが必要です。これにより、セカンダリ読み取りが有効な SAP HANA データベースにクライアントからアクセスできます。
引き継ぎの実行後もセカンダリ レプリケーション サイトにアクセスできるようにするために、クラスターは SAPHana リソースのセカンダリと共に仮想 IP アドレスを移動する必要があります。
2 番目の仮想 IP を使用して、HANA アクティブ/読み取りが有効なシステム レプリケーションを Red Hat HA クラスターで管理するために必要な追加の構成については、「Pacemaker クラスターで HANA アクティブ/読み取り可能のシステム レプリケーションを構成する」を参照してください。
先に進む前に、ドキュメントの前のセクションでの説明に従って、SAP HANA データベースを管理する Red Hat 高可用性クラスターの構成が完了していることを確認してください。
クラスターの設定をテストする
ここでは、設定をテストする方法について説明します。
テストを開始する前に、Pacemaker に (pcs status での) 失敗したアクションがないこと、予期しない場所の制約 (たとえば移行テストの残り物) がないこと、HANA システム レプリケーションが (たとえば
systemReplicationStatusで) 同期状態であることを確認します。sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"ノードが NFS 共有 (
/hana/shared) へのアクセスを失った場合の障害シナリオに備えてクラスター構成を検証します。SAP HANA リソース エージェントでは、フェールオーバー中の操作の実行は
/hana/sharedに保存されるバイナリに依存しています。 提示されるシナリオでは、ファイル システム/hana/sharedは NFS 経由でマウントされます。サーバーの 1 つが NFS 共有へのアクセスを失う障害をシミュレートすることは困難です。 テストとして、ファイル システムを読み取り専用として再マウントできます。 この方法は、アクティブ ノードで
/hana/sharedへのアクセスが失われた場合に、クラスターがフェールオーバーできることを検証します。予想される結果:
/hana/sharedを読み取り専用ファイル システムにすると、ファイル システムに対して読み取り/書き込み操作を実行するリソースhana_shared1のOCF_CHECK_LEVEL属性が失敗します。 ファイル システムに何も書き込むことができず、HANA リソースのフェールオーバーを実行します。 HANA ノードが NFS 共有へのアクセスを失った場合も、同じ結果が予想されます。テスト開始前のリソースの状態:
sudo pcs status出力例:
Full list of resources: rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hanadb1 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem): Started hanadb1 hana_log1 (ocf::heartbeat:Filesystem): Started hanadb1 hana_shared1 (ocf::heartbeat:Filesystem): Started hanadb1 Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Started hanadb1 hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb1 hanadb2 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb1 ] Slaves: [ hanadb2 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb1 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb1次のコマンドを使用して、アクティブなクラスター ノードで
/hana/sharedを読み取り専用モードにできます。sudo mount -o ro 10.32.2.4:/hanadb1-shared-mnt00001 /hana/sharedhanadbは、stonith(pcs property show stonith-action) で設定されているアクションに基づいて、再起動または電源オフのいずれかを行います。 サーバー (hanadb1) がダウンすると、HANA リソースはhanadb2に移動します。 クラスターの状態はhanadb2から確認できます。sudo pcs status出力例:
Full list of resources: rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hanadb2 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem): Stopped hana_log1 (ocf::heartbeat:Filesystem): Stopped hana_shared1 (ocf::heartbeat:Filesystem): Stopped Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Stopped hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb2 ] Stopped: [ hanadb1 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb2 ] Stopped: [ hanadb1 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb2 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb2「RHEL での SAP HANA システム レプリケーションの設定」で説明されているテストも実行して、SAP HANA クラスター構成を十分にテストすることをお勧めします。