クラウド ネイティブとは
ヒント
このコンテンツは eBook の「Azure 向けクラウド ネイティブ .NET アプリケーションの設計」からの抜粋です。.NET Docs で閲覧できるほか、PDF として無料ダウンロードすると、オンラインで閲覧できます。

作業を中断して、"クラウド ネイティブ" という用語の定義を同僚に尋ねてみてください。 いくつかの違った回答が返ってくる可能性が高いでしょう。
では、簡単な定義から始めましょう。
クラウドネイティブのアーキテクチャとテクノロジは、クラウドに組み込み、クラウド コンピューティング モデルをフル活用するワークロードを設計、構築、運用するためのアプローチです。
Cloud Native Computing Foundation によって、公式の定義が提供されています。
クラウドネイティブ テクノロジは、パブリック、プライベート、ハイブリッド クラウドなどの近代的でダイナミックな環境において、スケーラブルなアプリケーションを構築および実行するための能力を組織にもたらします。 このアプローチの代表例には、コンテナー、サービス メッシュ、マイクロサービス、イミュータブル インフラストラクチャ、宣言型 API があります。
これらの手法により、回復性、管理力、可観測性のある疎結合システムが実現します。 これらを堅牢な自動化と組み合わせることで、インパクトのある変更を最小限の労力で頻繁かつ予測どおりに行うことができます。
クラウドネイティブでは、"スピード" と "機敏性" が重要です。 ビジネス システムは、ビジネスの能力を実現することから、ビジネスのスピードと成長を加速させる戦略的変革のための武器になることへと進化しています。 すぐに市場に投入できる新しいアイデアを得ることが不可欠です。
同時に、ビジネス システムはますます複雑になり、ユーザーの要求も増えています。 迅速な応答性、革新的な機能、ダウンタイム ゼロが期待されます。 パフォーマンスの問題、繰り返し発生するエラー、および機敏に動けないことは、許容されなくなりました。 ユーザーは競合他社を訪問するでしょう。 クラウドネイティブ システムは、迅速な変更、大規模、および回復力を包含するように設計されます。
ここでは、クラウドネイティブな手法を実装した企業をいくつか紹介します。 実現された、スピード、機敏性、およびスケーラビリティについて考えてみましょう。
| [会社] | エクスペリエンス |
|---|---|
| Netflix | 600 を超えるサービスを運用環境で提供しています。 配置回数は 1 日あたり 100 回です。 |
| Uber | 1,000 を超えるサービスを運用環境で提供しています。 配置回数は週あたり数千回です。 |
| 3,000 を超えるサービスを運用環境で提供しています。 配置回数は 1 日あたり 1000 回です。 |
ご覧のように、Netflix、Uber、WeChat は、多くの独立したサービスで構成されるクラウドネイティブなシステムを公開しています。 このアーキテクチャ スタイルによって、市場の状況に迅速に対応できます。 完全な再配置を行わずに、稼動中の複雑なアプリケーションの小さな部分を瞬時に更新します。 サービスは必要に応じて個別にスケーリングされます。
クラウド ネイティブの柱
クラウド ネイティブのスピードと機敏性は多くの要素に由来します。 最も重要なのは "クラウド インフラストラクチャ" です。 しかし、それだけではありません。図 1-3 に示すその他 5 つの基本な柱によっても、クラウドネイティブ システムの基盤が提供されます。
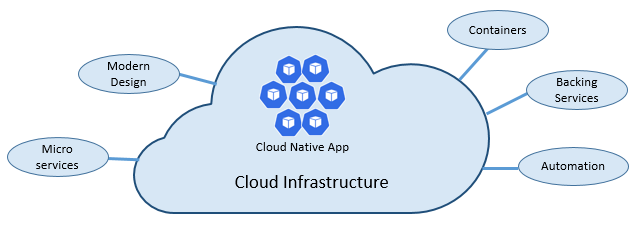
図 1-3. クラウドネイティブの基本的な柱
それぞれの柱の重要性をよく理解できるように、もう少し時間を取ってみましょう。
クラウド
クラウドネイティブ システムは、クラウド サービス モデルを最大限に活用します。
これらのシステムは、仮想化された動的なクラウド環境で効果を発揮するように設計され、サービスとしてのプラットフォーム (PaaS) コンピューティング インフラストラクチャおよび管理対象サービスを全面的に使用しています。 基礎となるインフラストラクチャは "ディスポーザブル" として扱われます。つまり、自動化を介して、数分間でプロビジョニングされ、オンデマンドでサイズ変更、スケール、または破棄が行われます。
ペットと商品の扱い方の違いを考えてみましょう。 従来のデータ センターでは、サーバーはペットとして扱われます。物理的な機械であり、意味のある名前を与えられ、大切にされます。 同じマシンにリソースを追加してスケールします (スケールアップ)。 サーバーに不具合が生じると、正常に戻すために対処します。 サーバーが使用できなくなると、だれもが気付きます。
コモディティ サービス モデルは異なります。 各インスタンスは、仮想マシンまたはコンテナーとしてプロビジョニングされます。 これらはまったく同じであり、Service-01 や Service-02 のようなシステム識別子が割り当てられます。 より多くのインスタンスを作成してスケーリングします (スケールアウト)。 インスタンスが使用不能になっても、誰も気付きません。
コモディティ モデルには、不変のインフラストラクチャが採用されています。 サーバーの修復や変更は行われません。 障害が発生したり更新が必要になったりすると、破棄され、新しいものがプロビジョニングされます。すべて自動化されています。
クラウドネイティブ システムでは、コモディティ サービス モデルが採用されています。 実行を続ける際に、インフラストラクチャはスケールインまたはスケールアウトしますが、どのマシンで実行しているかは関係ありません。
Azure クラウド プラットフォームでは、自動スケーリング、自己復旧、監視機能を備えた、このようなきわめてエラスティックなインフラストラクチャがサポートされています。
モダン デザイン
クラウドネイティブ アプリはどのように設計すればよいでしょうか。 アーキテクチャはどのようになりますか。 遵守するのは、どのような原則、パターン、およびベスト プラクティスですか。 インフラストラクチャおよび運用に関する重要な考慮事項は何でしょうか。
Twelve-Factor Application
クラウドベース アプリケーションの構築方法として広く受け入れられているのが Twelve-Factor Application です。 ここでは、最新のクラウド環境向けに最適化されたアプリケーションを構築するために、開発者が従う一連の原則およびプラクティスについて説明します。 環境間の移植性と宣言型の自動化に、特に注意が払われています。
あらゆる Web ベース アプリケーションにも当てはまりますが、多くの専門家は、Twelve-Factor をクラウドネイティブ アプリを構築するための堅固な基盤と見なしています。 これらの原則に基づいて構築されたシステムでは、配置とスケールを機敏に行うことができ、市場の変化に迅速に対応して機能を追加できます。
次の表に、Twelve-Factor 方法論を示します。
| 要因 | 説明 |
|---|---|
| 1 - コード ベース | 各マイクロサービスの 1 つのコード ベースが、独自のリポジトリに格納されています。 バージョン管理によって追跡され、複数の環境 (QA、ステージング、運用環境) に配置できます。 |
| 2 ‐ 依存関係 | 各マイクロサービスでは、それぞれの依存関係を分離してパッケージ化し、システム全体に影響を与えずに変更を行います。 |
| 3 ‐ 構成 | 構成情報は、マイクロサービスから取り出され、コード外部の構成管理ツールを使用して外部化されます。 同じ配置が、正しい構成の適用により、複数の環境に伝達されます。 |
| 4 ‐ 補助的サービス | 補助リソース (データ ストア、キャッシュ、メッセージ ブローカー) をアドレス指定可能な URL を介して公開する必要があります。 これによって、アプリケーションからリソースが分離され、交換可能になります。 |
| 5 - ビルド、リリース、実行 | リリースごとに、ビルド、リリース、および実行の各ステージに対して厳密な分離を適用する必要があります。 それぞれに一意の ID をタグ付けし、ロールバックできる機能をサポートする必要があります。 最新の CI/CD システムは、この原則に従うのに役立ちます。 |
| 6 - プロセス | 各マイクロサービスは、実行中の他のサービスから分離され、独自のプロセス内で実行する必要があります。 必要な状態を、補助的サービス (分散キャッシュまたはデータ ストア) に外部化します。 |
| 7 - ポートのバインド | 各マイクロサービスは、独自のポートで公開されるインターフェイスと機能を含めて、自己完結している必要があります。 これによって、他のマイクロサービスから分離されます。 |
| 8 - コンカレンシー | 容量を増やす必要がある場合は、利用可能な最も強力なマシン上で単一の大規模なインスタンスをスケールアップするのとは対照的に、複数の同一のプロセス (コピー) にわたってサービスを水平方向にスケールアウトします。 アプリケーションがコンカレントになり、クラウド環境でのスケールアウトがシームレスに行われるように開発します。 |
| 9 - ディスポーザビリティ | サービス インスタンスは、ディスポーザブルである必要があります。 高速起動を優先してスケーラビリティの機会を増やし、正常にシャットダウンしてシステムを適切な状態に保つことができます。 Docker コンテナーおよびオーケストレーターによって、本質的にこの要件が満たされます。 |
| 10 - 開発/運用のパリティ | 環境をアプリケーション ライフサイクル全体で可能な限り同様に維持し、コストのかかるショートカットを回避します。 ここでは、コンテナーの採用が大きく貢献します。同じ実行環境が推進されるためです。 |
| 11 - ログ | マイクロサービスによって生成されるログをイベント ストリームとして扱います。 この処理はイベント アグリゲーターを使用して行います。 ログ データをデータマイニングやログ管理ツール (Azure Monitor や Splunk など) に伝達し、最終的には長期間アーカイブを行います。 |
| 12 - 管理プロセス | データ クリーンアップやコンピューティング分析などの管理タスクを 1 回限りのプロセスとして実行します。 独立したツールを使用して、アプリケーションとは別に、これらのタスクを運用環境から呼び出します。 |
『Beyond the Twelve-Factor App』(Twelve-Factor App の先に) で、著者 Kevin Hoffman は本来の 12 個の要因それぞれを詳しく説明しています (2011 年)。 さらに、現在の最新クラウド アプリケーション設計を反映する追加の 3 つの要因についても述べています。
| 新しい要因 | 説明 |
|---|---|
| 13 - API ファースト | すべてをサービスにします。 コードが、フロントエンド クライアント、ゲートウェイ、または別のサービスによって使用される仮定します。 |
| 14 - テレメトリ | ワークステーション上で、アプリケーションとその動作の詳細を確認します。 クラウドでは、行いません。 監視、ドメイン固有、および正常性/システム データのコレクションが設計に含まれていることを確認します。 |
| 15 - 認証/承認 | 最初から ID を実装します。 パブリック クラウドでは、使用可能な RBAC (ロールベースのアクセス制御) 機能を検討してください。 |
この章および全体を通して、12 個および追加の要因の多くを紹介します。
Azure Well-Architected Framework
特にクラウドネイティブなアーキテクチャを実装する場合、クラウドベースのワークロードの設計とデプロイは困難な場合があります。 Microsoft では、お客様とチームが堅牢なクラウド ソリューションを提供するのに役立つ業界標準のベスト プラクティスを提供しています。
Microsoft Well-Architected Framework は、クラウドネイティブなワークロードの品質向上に使用できる一連の基本原則です。 フレームワークは、優れたアーキテクチャの 5 つの柱で構成されています。
| 原則 | 説明 |
|---|---|
| コスト管理 | 増加する価値の早期生成に重点を置きます。 Build-Measure-Learn の原則を適用し、市場投入までの時間を短縮する一方で、資本集約型ソリューションを回避します。 従量課金制の戦略を使用して、大規模な投資を前もって提供するのではなく、スケールアウトに応じた投資を行います。 |
| オペレーショナル エクセレンス | 環境と運用を自動化して、速度を上げ、人的エラーを減らします。 問題の更新プログラムを迅速にロール バックまたはロール フォワードします。 監視と診断を最初から実装します。 |
| パフォーマンス効率 | ワークロードに対する要求を効率的に満たします。 水平スケーリング (スケール アウト) を優先し、これをシステム設計に組み込みます。 潜在的なボトルネックが検出されるように、パフォーマンスとロード テストを継続的に実行します。 |
| 信頼性 | 回復性と可用性の両方を備えるワークロードを構築します。 回復性により、ワークロードは障害から復旧し、機能を継続できます。 可用性により、ユーザーはいつでもワークロードにアクセスできます。 障害を予想し、そこから復旧するアプリケーションを設計します。 |
| Security | 設計と実装から、デプロイと運用まで、アプリケーションのライフサイクル全体にセキュリティを実装します。 ID 管理、インフラストラクチャ アクセス、アプリケーション セキュリティ、データ主権と暗号化に細心の注意を払います。 |
開始するために、Microsoft では、適切に設計された 5 つの柱に対して現在のクラウド ワークロードを評価するのに役立つ一連のオンライン評価を提供しています。
マイクロサービス
クラウドネイティブ システムは、最新のアプリケーションを構築するための一般的なアーキテクチャ スタイルであるマイクロサービスを採用しています。
共有ファブリックを介してやり取りする、独立した小さいサービスの分散セットとして構築されたマイクロサービスは、次の特性を共有します。
それぞれは、より大きなドメインのコンテキストにおいて、特定のビジネス機能を実装します。
それぞれは、自律的に開発され、独立して配置できます。
それぞれは、独自のデータ ストレージ テクノロジ、依存関係、およびプログラミング プラットフォームを自己完結型でカプセル化しています。
それぞれは、独自のプロセス内で実行し、標準通信プロトコル (HTTP/HTTPS、gRPC、WebSockets、AMQP など) を使用して他と通信します。
これらがまとまって、1 つのアプリケーションを形成します。
図 1-4 は、モノリシック アプリケーション アプローチとマイクロサービス アプローチを比較したものです。 モノリスは 1 つのプロセスで実行される多層アーキテクチャで構成されていることに注意してください。 通常、リレーショナル データベースが使用されます。 ただし、マイクロサービス アプローチでは、機能が独立したサービスに分離され、それぞれに独自のロジック、状態、およびデータが含まれています。 各マイクロサービスが独自のデータストアをホストします。
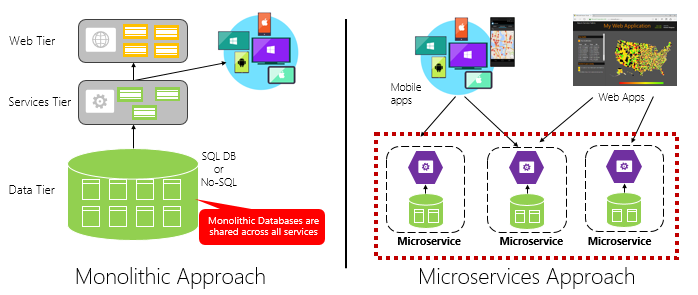
図 1-4。 モノリシックとマイクロサービスのアーキテクチャの比較
この章で前述した Twelve-Factor Application のプロセスの原則がマイクロサービスによってどのように推進されるかをご確認ください。
"要因 #6 の指定: "各マイクロサービスは、実行中の他のサービスから分離され、独自のプロセス内で実行する必要があります。""
マイクロサービスについて
マイクロサービスによって機敏性が提供されます。
この章の前半では、モノリスとして構築された e コマース アプリケーションを、マイクロサービスを使用したものと比較しました。 この例では、明確な利点がいくつかわかりました。
各マイクロサービスには自律したライフサイクルがあり、個別に進化することができ、頻繁に配置できます。 新しい機能や更新プログラムをデプロイするために、四半期ごとのリリースを待つ必要はありません。 稼動中のアプリケーションの小さな部分を更新することができ、システム全体を中断させるリスクは軽減します。 更新は、アプリケーションを完全に再配置せずに行うことができます。
各マイクロサービスは個別にスケールできます。 アプリケーション全体を 1 つのユニットとしてスケールアウトするのではなく、目的のパフォーマンス レベルやサービス レベル アグリーメントを満たすためのより多くの処理能力を必要とするサービスのみをスケールアウトします。 細分化されたスケーリングによって、システムをより細かく制御できるようになり、システム全体ではなくシステムの一部をスケーリングすることで全体的なコストを削減することができます。
マイクロサービスを理解するための優れた参照ガイドとして、『.NET Microservices: Architecture for Containerized .NET Applications』(.NET マイクロサービス: コンテナー化された .NET アプリケーションのアーキテクチャ) をお勧めします。 この本は、マイクロサービスの設計とアーキテクチャについて深く掘り下げています。 これは、Microsoft から無料でダウンロードできるフルスタック マイクロサービス リファレンス アーキテクチャの手引きです。
マイクロサービスの開発
マイクロサービスは、どの最新開発プラットフォームに対しても作成できます。
Microsoft .NET プラットフォームは最適な選択です。 無料かつオープンソースであり、マイクロサービスの開発を簡易化する組み込み機能が多数用意されています。 .NET はクロスプラットフォームです。 Windows、macOS、およびほとんどの Linux に対して、アプリケーションをビルドして実行できます。
.NET は非常に高いパフォーマンスを備え、Node.js およびその他の競合プラットフォームとの比較でも高く評価されています。 興味深いのですが、TechEmpower によって、多数の Web アプリケーション プラットフォームおよびフレームワークで広範囲のパフォーマンス ベンチマークが測定されました。 .NET は上位 10 までに入り、Node.js や他の競合プラットフォームを引き離しました。
.NET は、Microsoft および GitHub 上の .NET コミュニティによって管理されています。
マイクロサービスの課題
分散型クラウドネイティブ マイクロサービスによって、計り知れない機敏性とスピードが実現しますが、多くの課題があります。
通信
フロントエンド クライアント アプリケーションは、どのようにバックエンド コア マイクロサービスと通信しますか。 直接通信を許可しますか。 または、柔軟性、制御、およびセキュリティを提供するゲートウェイ ファサードを使用して、バックエンド マイクロサービスを抽象化しますか。
バックエンド コア マイクロサービスはどのように相互に通信しますか。 直接 HTTP 呼び出しを許可しますか (これは結合の増加につながり、パフォーマンスと機敏性に影響があります)。 または、キューやトピックのテクノロジを使用してメッセージングを切り離すことを検討しますか。
通信については、「クラウドネイティブの通信パターン」の章を参照してください。
回復性
マイクロサービス アーキテクチャによって、インプロセスからアウトプロセス ネットワーク通信にシステムが移行されます。 分散アーキテクチャで、サービス B がサービス A からのネットワーク呼び出しに応答しないと、何が発生しますか。 また、サービス C が一時的に使用できなくなり、それを呼び出す他のサービスがブロックされた場合、どうなりますか。
回復性については、「クラウドネイティブの回復性」の章を参照してください。
"分散データ"
仕様では、各マイクロサービスは自らのデータをカプセル化し、パブリック インターフェイスを介して操作を公開します。 この場合、複数のサービスにわたって、データを照会したり、トランザクションを実装したりするにはどうすればよいでしょうか。
分散データについては、「クラウドネイティブ データ パターン」の章を参照してください。
シークレット
マイクロサービスで、シークレットと機密構成データを安全に保存し、管理するにはどうすればよいでしょうか。
シークレットの詳細については、クラウドネイティブのセキュリティに関する記事を参照してください。
Dapr で複雑さを管理する
Dapr は、オープンソースの分散アプリケーション ランタイムです。 プラグ可能なコンポーネントのアーキテクチャにより、分散アプリケーションの背後にある "仕組み" を大幅に簡略化します。 Dapr ランタイムに事前構築されたインフラストラクチャ機能とコンポーネントをアプリケーションにバインドする動的な接着剤が提供されます。 図 1-5 は、2 万フィートから Dapr を見た様子です。
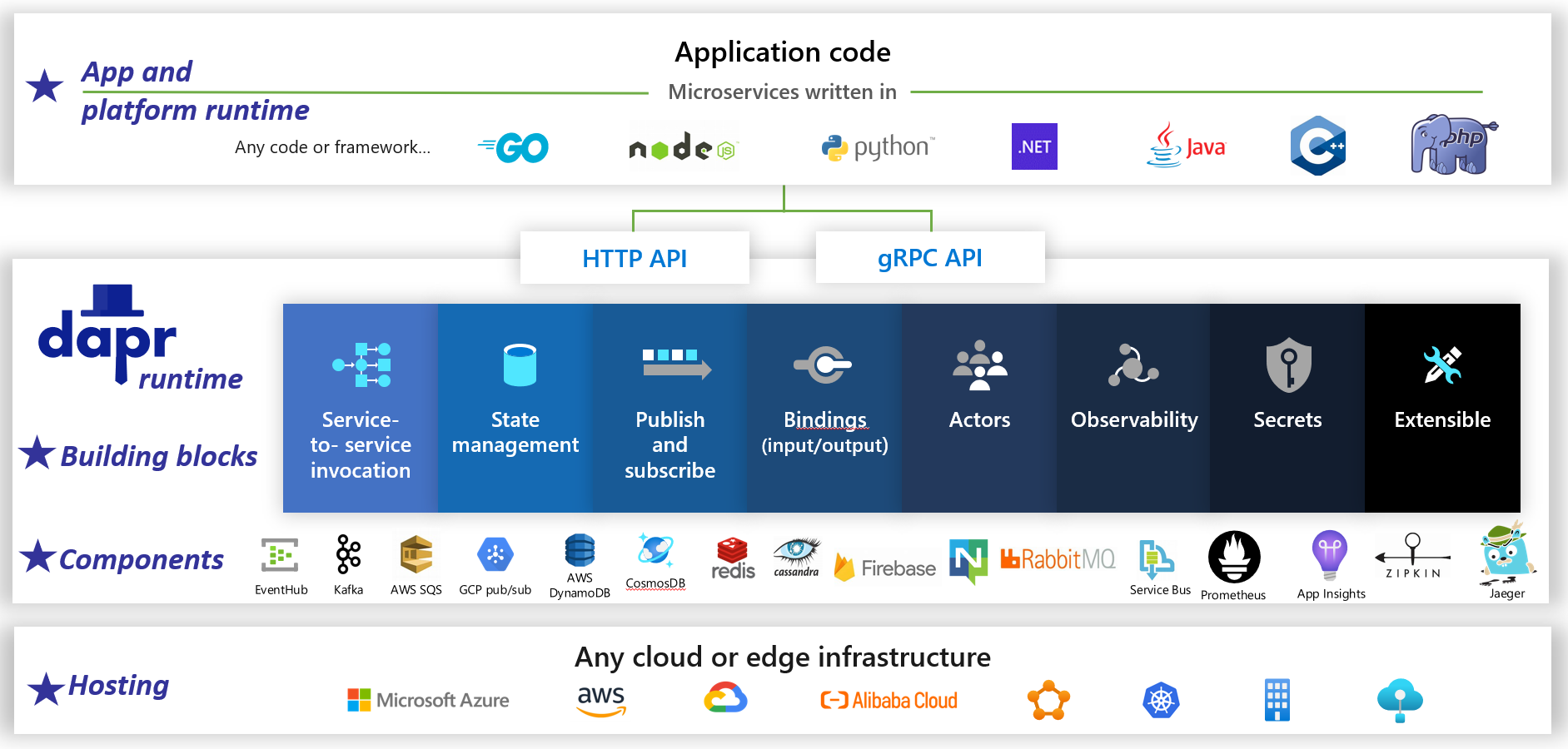 図 1-5。 2 万フィートからの Dapr。
図 1-5。 2 万フィートからの Dapr。
図の一番上の行で、Dapr により一般的な開発プラットフォーム向けの言語固有の SDK が提供されるしくみに注意してください。 Dapr v1 には、.NET、Go、Node.js、Python、PHP、Java、JavaScript のサポートが含まれます。
言語固有の SDK によって開発者のエクスペリエンスが強化されますが、Dapr はプラットフォームに依存しません。 内部的には、Dapr のプログラミング モデルの機能は、標準の HTTP/gRPC 通信プロトコルを介して公開されます。 任意のプログラミング プラットフォームで、ネイティブの HTTP および gRPC API を介して Dapr を呼び出すことができます。
図の中央にある青いボックスは、Dapr の構成ブロックを表します。 それぞれにより、アプリケーションで使用できる分散アプリケーション機能に事前構築された仕組みコードが公開されます。
コンポーネント行は、アプリケーションで使用できる定義済みのインフラストラクチャ コンポーネントの大規模なセットを表します。 コンポーネントは、記述する必要のないインフラストラクチャ コードと考えてください。
下の行では、Dapr とそれによって実行できるさまざまな環境の移植性が強調されています。
今後 Dapr は、クラウドネイティブなアプリケーションの開発に大きな影響を与える可能性があります。
Containers
"クラウドネイティブ" に関するあらゆる会話で "コンテナー" という用語を耳にすることが当たり前になりました。 『Cloud Native Patterns』 (クラウド ネイティブ パターン) という本では、"コンテナーはクラウドネイティブ ソフトウェアの優れた実行手段である" と述べています。Cloud Native Computing Foundation は、クラウドネイティブのトレイル マップ (企業がクラウドネイティブの体験を開始するガイダンス) の最初の手順に、マイクロサービスのコンテナー化を位置づけています。
{kind=link}
マイクロサービスのコンテナー化はシンプルで簡単です。 コード、その依存関係、およびランタイムが、コンテナー イメージと呼ばれるバイナリにパッケージ化されます。 イメージは、イメージのリポジトリまたはライブラリとして機能するコンテナー レジストリに格納されます。 レジストリは、開発用コンピューター、データ センター、またはパブリック クラウドに配置できます。 Docker 自体は、Docker Hub を使用してパブリック レジストリを管理します。 Azure クラウドには非公開のコンテナー レジストリがあり、実行するクラウド アプリケーションの近くにコンテナー イメージが格納されます。
コンテナー イメージは、アプリケーションの開始時またはスケーリング時に、実行中のコンテナー インスタンスに変換します。 インスタンスは、コンテナー ランタイム エンジンがインストールされている任意のコンピューター上で実行されます。 コンテナー化されたサービスのインスタンスは、必要に応じていくつでも作成できます。
図 1-6 は、3 つの異なるマイクロサービスがそれぞれのコンテナーにあり、1 つのホストで実行されていることを示しています。
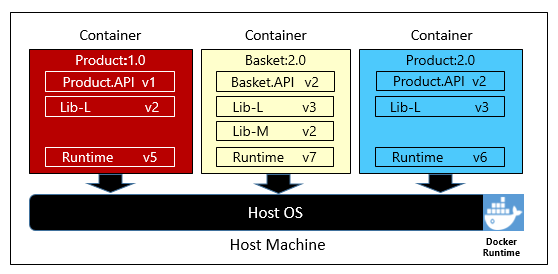
図 1-6. コンテナー ホストで実行されている複数のコンテナー
各コンテナーが独自の依存関係とランタイムのセット (それぞれ異なる可能性がある) をどのように保持しているかに注意してください。 ここで、異なるバージョンの Product マイクロサービスが同一ホスト上で実行していることに気付きます。 各コンテナーは、基礎となるホスト オペレーティング システム、メモリ、およびプロセッサのスライスを共有しますが、互いに分離しています。
このコンテナー モデルが Twelve-Factor Application の依存関係の原則をどのように適切に採用しているかに注意してください。
"要因 #2 の指定: "各マイクロサービスによって、それぞれの依存関係を分離してパッケージ化し、システム全体に影響を与えずに変更を行います。""
コンテナーでは、Linux と Windows 両方のワークロードがサポートされます。 Azure クラウドでは両方が包含されています。 興味深いことですが、Azure で最も一般的なオペレーティング システムになっているのは Windows Server ではなく Linux です。
複数のコンテナー ベンダーが存在しているものの、Docker が最大の市場シェアを獲得しています。 この企業はソフトウェア コンテナーの動向を推進してきました。 クラウドネイティブ アプリケーションのパッケージ化、配置、実行のための事実上の標準になっています。
コンテナーについて
コンテナーによって、環境間での移植性が提供され、一貫性が保証されます。 すべてを 1 つのパッケージにカプセル化することで、マイクロサービスとその依存関係を、基礎となるインフラストラクチャから "分離" します。
Docker ランタイム エンジンがホストされているすべての環境にコンテナーを配置できます。 コンテナー化されたワークロードでは、フレームワーク、ソフトウェア ライブラリ、およびランタイム エンジンによって各環境を事前に構成するコストも不要になります。
基礎となるオペレーティング システムとホスト リソースを共有することで、コンテナーのフットプリントは、完全な仮想マシンよりもかなり小さくなります。 サイズが小さくなると、特定のホストが一度に実行できる "密度" (マイクロサービスの数) が増加します。
コンテナーのオーケストレーション
Docker などのツールによって、イメージの作成やコンテナーの実行が行われますが、それらを管理するツールも必要です。 コンテナー管理は、コンテナー オーケストレーターと呼ばれる特別なソフトウェア プログラムを使用して行われます。 多数の独立した実行中コンテナーを使用して大規模に運用する場合は、オーケストレーションが不可欠です。
図 1-7 は、コンテナー オーケストレーターによって自動化される管理タスクを示しています。
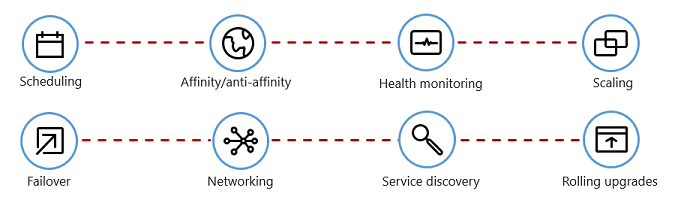
図 1-7. コンテナー オーケストレーターが行うこと
次の表では、一般的なオーケストレーション タスクについて説明します。
| タスク | 説明 |
|---|---|
| スケジュール設定 | コンテナー インスタンスを自動的にプロビジョニングします。 |
| アフィニティ/アンチアフィニティ | 隣接しているコンテナーまたは相互に遠く離れたコンテナーをプロビジョニングし、可用性とパフォーマンスを高めます。 |
| 正常性の監視 | エラーを自動的に検出して修正します。 |
| [フェールオーバー] | 失敗したインスタンスを正常なコンピューターに自動的に再プロビジョニングします。 |
| Scaling | 需要に合わせて、コンテナー インスタンスを自動的に追加または削除します。 |
| ネットワーク | コンテナー通信のネットワーク オーバーレイを管理します。 |
| サービス探索 | コンテナーが互いを見つけられるようにします。 |
| ローリング アップグレード | ダウンタイム ゼロの配置を使用して増分アップグレードを調整します。 問題のある変更を自動的にロールバックします。 |
コンテナー オーケストレーターによって、Twelve-Factor Application のディスポーザビリティとコンカレンシーの原則がどのように採用されているかに注意してください。
"要因 #9 の指定: "サービス インスタンスはディスポーザブルである必要があります。これにより、高速で起動してスケーラビリティの機会を増やし、正常にシャットダウンしてシステムを適切な状態に保つことができます。"" Docker コンテナーおよびオーケストレーターによって、この要件が本質的に満たされます。
"要因 #8 の指定: "サービスによって、使用可能な最高性能のマシン上で 1 つの大きなインスタンスをスケールアップするのではなく、多数の小さな同一プロセス (コピー) 全体でスケールアウトします。""
いくつかのコンテナー オーケストレーターが存在していますが、クラウドネイティブの世界で事実上の標準となったのは Kubernetes です。 これは、コンテナー化されたワークロードを管理するための、移植可能で拡張可能なオープンソース プラットフォームです。
独自の Kubernetes インスタンスをホストすることもできますが、そうするとリソースのプロビジョニングと管理に責任を持つことになり、複雑になる可能性があります。 Azure クラウドでは、Kubernetes が管理サービスとして提供されます。 Azure Kubernetes Service (AKS) と Azure Red Hat OpenShift (ARO) の両方を使用すると、Kubernetes の機能と能力を管理サービスとしてフル活用できます。その際、インストールと保守を行う必要はありません。
コンテナー オーケストレーションの詳細については、「クラウドネイティブ アプリケーションのスケーリング」を参照してください。
補助的サービス
クラウドネイティブ システムは、データ ストア、メッセージ ブローカー、監視、ID サービスなど、さまざまな補助リソースに依存しています。 これらのサービスは、補助的サービスと呼ばれています。
図 1-8 は、クラウドネイティブ システムが使用する多くの一般的な補助的サービスを示しています。
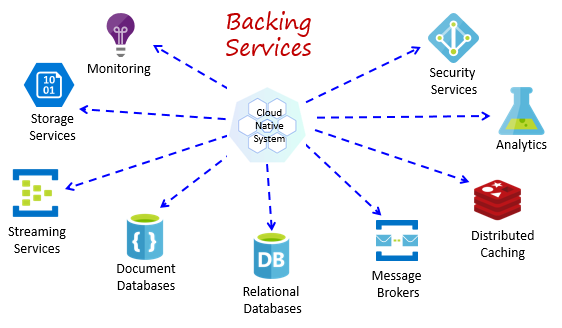
図 1-8. 一般的な補助的サービス
独自の補助的サービスをホストすることもできますが、その場合は、それらのリソースのライセンス、プロビジョニング、および管理を行う必要があります。
クラウド プロバイダーは、さまざまな "管理された補助的サービス" を提供しています。サービスを所有するのではなく、単に使用します。 クラウド プロバイダーは大規模にリソースを運用し、パフォーマンス、セキュリティ、およびメンテナンスの責任を負います。 監視、冗長性、可用性は、サービスに組み込まれています。 プロバイダーによってサービス レベル パフォーマンスは保証され、管理サービスは完全にサポートされています。チケットをオープンすると、問題が解決されます。
クラウドネイティブ システムでは、クラウド ベンダーの管理された補助的サービスが優先されます。 時間と労力の節約が重要になる場合があります。 独自にホストしてトラブルが発生する運用リスクにより、すぐにコストが増加する可能性があります。
ベスト プラクティスは、補助的サービスを "アタッチされるリソース" として扱い、外部構成に格納された構成情報 (URL および資格情報) を使用して、動的にマイクロサービスにバインドすることです。 このガイダンスは、この章で前述した Twelve-Factor Application で詳しく説明されています。
"要因 #4" の指定: 補助的サービスは "アドレス指定可能な URL を介して公開する必要があります。 これによって、アプリケーションからリソースが分離され、交換可能になります。"
"要因 #3" の指定: "構成情報は、マイクロサービスから取り出され、コード外部の構成管理ツールを使用して外部化されます。"
このパターンを使用すると、コードを変更せずに、補助的サービスをアタッチおよびデタッチできます。 マイクロサービスを QA からステージング環境に進める場合があります。 ステージング環境の補助的サービスを指すようにマイクロサービスの構成を更新し、その設定を環境変数を使用してコンテナーに挿入します。
クラウド ベンダーによって、独自の補助的サービスと通信するための API が提供されます。 これらのライブラリでは、独自の仕組みと複雑さがカプセル化されています。 しかし、これらの API と直接通信することで、コードと特定の補助的サービスが密接に結合されます。 ベンダー API の実装の詳細を分離する方法が広く受け入れられています。 中間層 (中間 API) を導入して、汎用的な処理をサービス コードに公開し、その内部のベンダー コードをラップします。 このような疎結合によって、メインのサービス コードに変更を加える必要なしに、補助的サービスを切り替えたり、コードを別のクラウド環境に移したりできるようになります。 前に説明した Dapr は、あらかじめ構築された一連の構成要素でこのモデルに従います。
最終的には、補助的サービスによって、この章で前述した Twelve-Factor Application のステートレスの原則が推進されます。
"要因 #6" の指定: "各マイクロサービスは、実行中の他のサービスから分離され、独自のプロセス内で実行する必要があります。 必要な状態を、補助的サービス (分散キャッシュまたはデータ ストア) に外部化します。"
補助的サービスについては、「クラウドネイティブ データ パターン」および「クラウドネイティブの通信パターン」を参照してください。
オートメーション
これまで見てきたように、クラウドネイティブ システムでは、スピードと機敏性を実現するために、マイクロサービス、コンテナー、最新のシステム設計が採用されています。 しかしそれは、ストーリーの一部にすぎません。 これらのシステムの実行基盤となるクラウド環境をどのようにプロビジョニングすればよいでしょうか。 アプリの機能と更新プログラムを迅速に配置するにはどうすればよいでしょうか。 全体を仕上げるにはどうすればよいでしょうか。
広く受け入れられてるプラクティス、Infrastructure as Code (IaC) を取り入れます。
IaC を使用して、プラットフォームのプロビジョニングとアプリケーションの配置を自動化できます。 基本的には、テストやバージョン管理などのソフトウェア エンジニアリング プラクティスを、DevOps プラクティスに適用します。 インフラストラクチャと配置は、自動化され、一貫した、反復可能なものになります。
インフラストラクチャの自動化
Azure Resource Manager、Azure Bicep、HashiCorp の Terraform、Azure CLI などのツールを使用すると、必要なクラウド インフラストラクチャを宣言によってスクリプト化できます。 リソース名、場所、容量、およびシークレットは、パラメーター化され、動的になります。 スクリプトがバージョン管理され、プロジェクトの成果物としてソース管理にチェックインされます。 スクリプトを呼び出して、一貫性のある反復可能なインフラストラクチャを、システム環境全体 (QA、ステージング、運用など) にプロビジョニングします。
内部では IaC はべき等です。つまり、同じスクリプトを何度も実行しても副作用がありません。 チームが変更を加える必要がある場合、スクリプトを編集して再実行します。 更新されたリソースのみが影響を受けます。
記事「コードとしてのインフラストラクチャとは」の中で、執筆者 Sam Guckenheimer は次のように説明しています。"IaC を導入するチームは、安定した環境を迅速かつ大規模に実現できます。 コードによって環境の望ましい状態を表すことで、環境の手動構成が回避され、一貫性が確保されます。 IaC を使用したインフラストラクチャのデプロイは反復可能であり、構成ドリフトや依存関係の不足によって発生するランタイムの問題を防止します。 DevOps チームは、統合された一連のプラクティスおよびツールを使用して連携し、アプリケーションとそれを支えるインフラストラクチャを迅速、確実、大規模に実現できます。"
配置の自動化
前述した Twelve-Factor Application では、完成したコードを実行中のアプリケーションに変換する際に個別のステップが求められます。
"要因 #5" の指定: "リリースごとに、ビルド、リリース、実行の各ステージにわたって厳密な分離を適用する必要があります。 それぞれに一意の ID をタグ付けし、ロールバックできる機能をサポートする必要があります。"
最新の CI/CD システムは、この原則に従うのに役立ちます。 個別のビルドと配信のステップが提供され、ユーザーがすぐに利用できる一貫性のある高品質のコードが保証されます。
図 1-9 は、配置プロセスにおける分離を示しています。

図 1-9. CI/CD パイプラインでの配置ステップ
前の図で、タスクの分離に特に注意を向けてください。
- 開発者は、"内部ループ" と呼ばれる、コード、実行、デバッグを繰り返して、開発環境で機能を構築します。
- 完成すると、そのコードは GitHub、Azure DevOps、BitBucket などのコード リポジトリに "プッシュ" されます。
- プッシュによって、コードをバイナリの成果物に変換するビルド ステージがトリガーされます。 この作業は継続的インテグレーション (CI) パイプラインによって実装されます。 これにより、アプリケーションのビルド、テスト、およびパッケージ化が自動的に行われます。
- リリース ステージでは、バイナリ成果物が選択され、外部のアプリケーションと環境の構成情報が適用され、イミュータブル リリースが生成されます。 リリースが、指定された環境に配置されます。 この作業は、継続的デリバリー (CD) パイプラインによって実装されます。 各リリースを識別できる必要があります。 "この配置では、アプリケーションのリリース 2.1.1 を実行しています。" と言うことができます。
- 最終的に、リリースされた機能がターゲットの実行環境で実行されます。 リリースはイミュータブルです。つまり、どのように変更する場合でも新しいリリースを作成する必要があります。
このようなプラクティスを適用することで、組織はソフトウェアの配布方法を大きく進化させることができました。 多くが、四半期ごとのリリースからオンデマンド更新に移行しました。 目標は、修正コストを下げるために、開発サイクルの早い段階で問題を発見することです。 統合の間隔が広くなるほど、問題の解決にかかるコストが上がります。 統合プロセスの一貫性により、チームはコードの変更を頻繁にコミットできるようになり、コラボレーションとソフトウェアの品質が向上します。
コードとしてのインフラストラクチャおよびデプロイの自動化については、GitHub および Azure DevOps と合わせて、「DevOps」で詳しく説明されています。
.NET
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示