チュートリアル: Model Builder で画像内の一時停止標識を検出する
ML.NET Model Builder と Azure Machine Learning を使用して、物体検出モデルを構築し、画像内の一時停止標識を検出して特定する方法について説明します。
このチュートリアルでは、次の作業を行う方法について説明します。
- データを準備して理解する
- Model Builder 構成ファイルを作成する
- シナリオを選択する
- トレーニング環境を選択する
- データを読み込む
- モデルをトレーニングする
- モデルを評価する
- モデルを使用して予測を行う
前提条件
前提条件の一覧とインストール手順は、モデル ビルダーのインストール ガイドを参照してください。
Model Builder の物体検出の概要
オブジェクト検出はコンピューターのビジョンの問題です。 画像の分類に密接に関連していますが、オブジェクト検出では、より詳細なスケールで画像分類が実行されます。 オブジェクト検出では、画像内のエンティティの特定 "と" 分類の両方が行われます。 物体検出モデルは、一般的にディープ ラーニングとニューラル ネットワークを使用してトレーニングされます。 詳細については、ディープ ラーニングと機械学習の違いに関するページを参照してください。
オブジェクト検出は、画像に異なる種類のオブジェクトが複数含まれる場合に使用します。

オブジェクト検出のユース ケースには、次のようなものがあります。
- 自動運転車
- ロボティクス
- 顔検出
- 職場の安全
- オブジェクトのカウント
- アクティビティ認識
このサンプルでは、Model Builder で構築された機械学習モデルを使用して、画像内の一時停止標識を検出する C# .NET Core コンソール アプリケーションを作成します。 このチュートリアルのソース コードは、dotnet/machinelearning-samples GitHub リポジトリにあります。
データを準備して理解する
一時停止標識データセットは、Unsplash からダウンロードされ、それぞれに少なくとも 1 つの一時停止標識が含まれている 50 個の画像で構成されています。
新しい VoTT プロジェクトを作成する
50 個の一時停止標識画像のデータセットをダウンロードして、解凍します。
VoTT を開いて、 [新しいプロジェクト] を選択します。
[プロジェクトの設定] で、 [表示名] を "StopSignObjDetection" に変更します。
[セキュリティ トークン] を [新しいセキュリティ トークンの生成] に変更します。
[ソース接続] の横にある [接続の追加] を選択します。
[接続の設定] で、ソース接続の [表示名] を "StopSignImages" に変更し、 [ローカル ファイル システム] を [プロバイダー] として選択します。 [フォルダー パス] で、50 個のトレーニング画像を格納する Stop-Signs フォルダーを選択し、 [接続の保存] を選択します。
![VoTT の [新しい接続] ダイアログ](media/object-detection-model-builder/vott-new-connection.png)
[プロジェクトの設定] で、 [ソース接続] を [StopSignImages] (先ほど作成した接続) に変更します。
[ターゲット接続] も [StopSignImages] に変更します。 [プロジェクトの設定] は、次のスクリーンショットのようになっているはずです。
![VoTT の [プロジェクトの設定] ダイアログ](media/object-detection-model-builder/vott-new-project.png)
[プロジェクトの保存] を選択します。
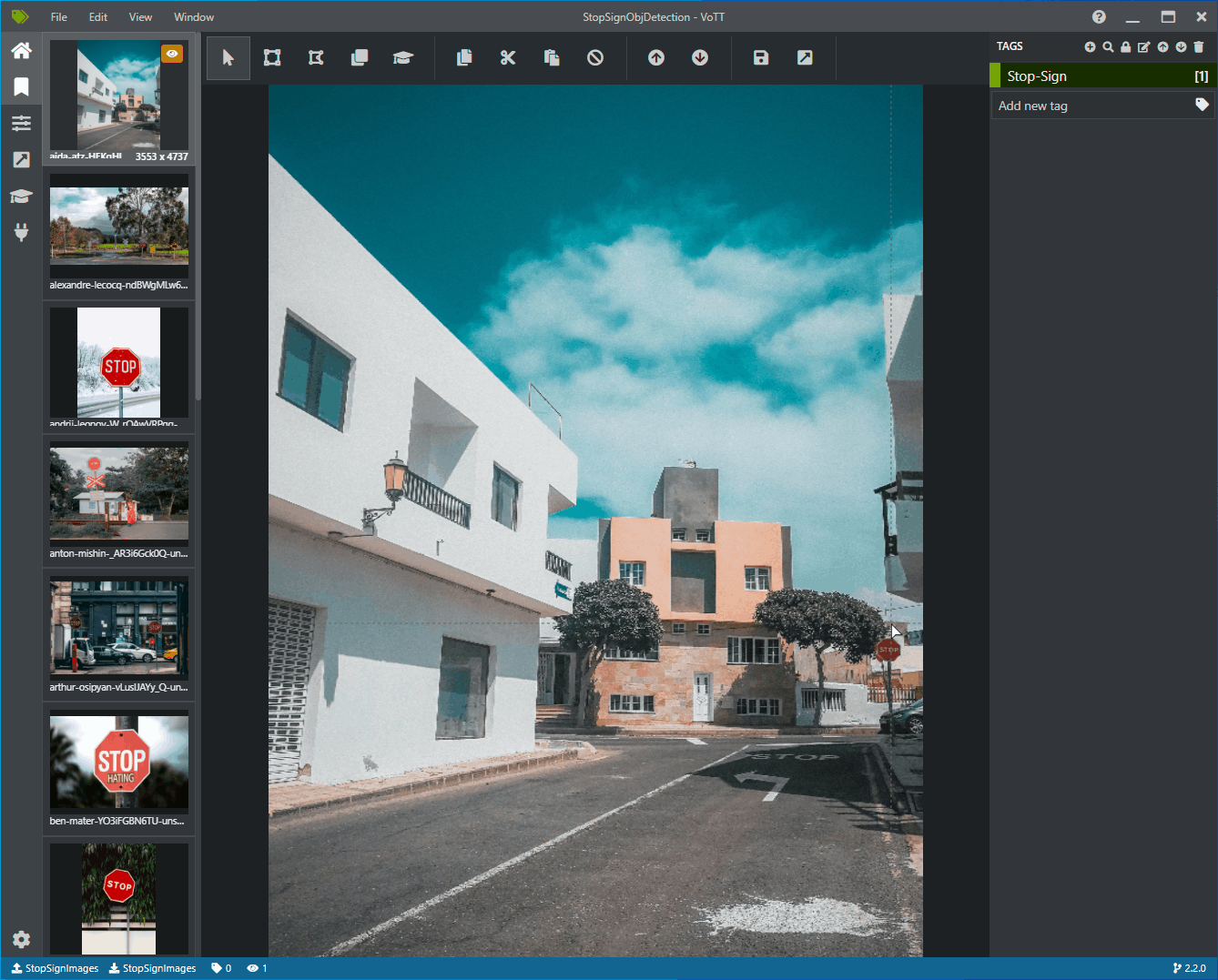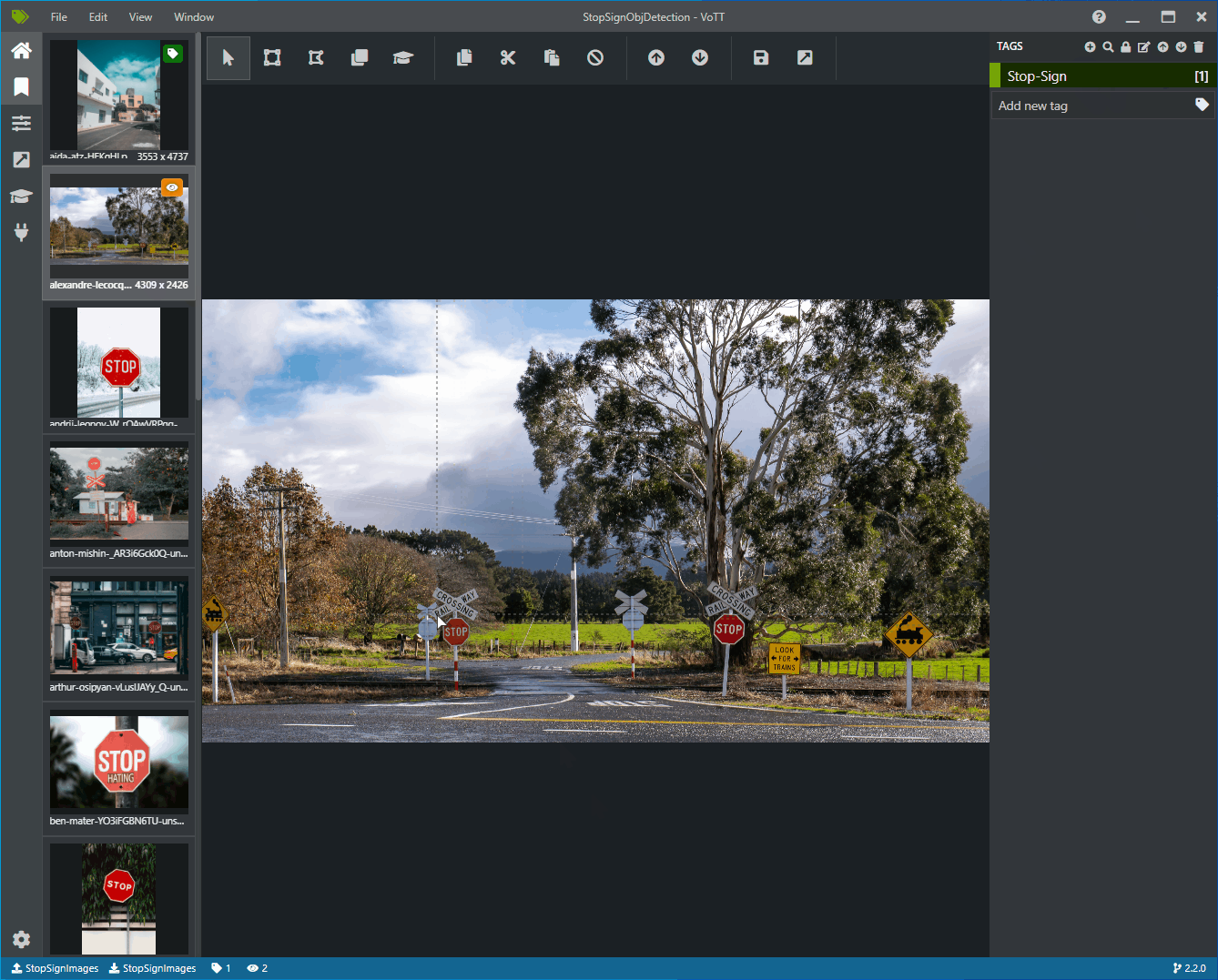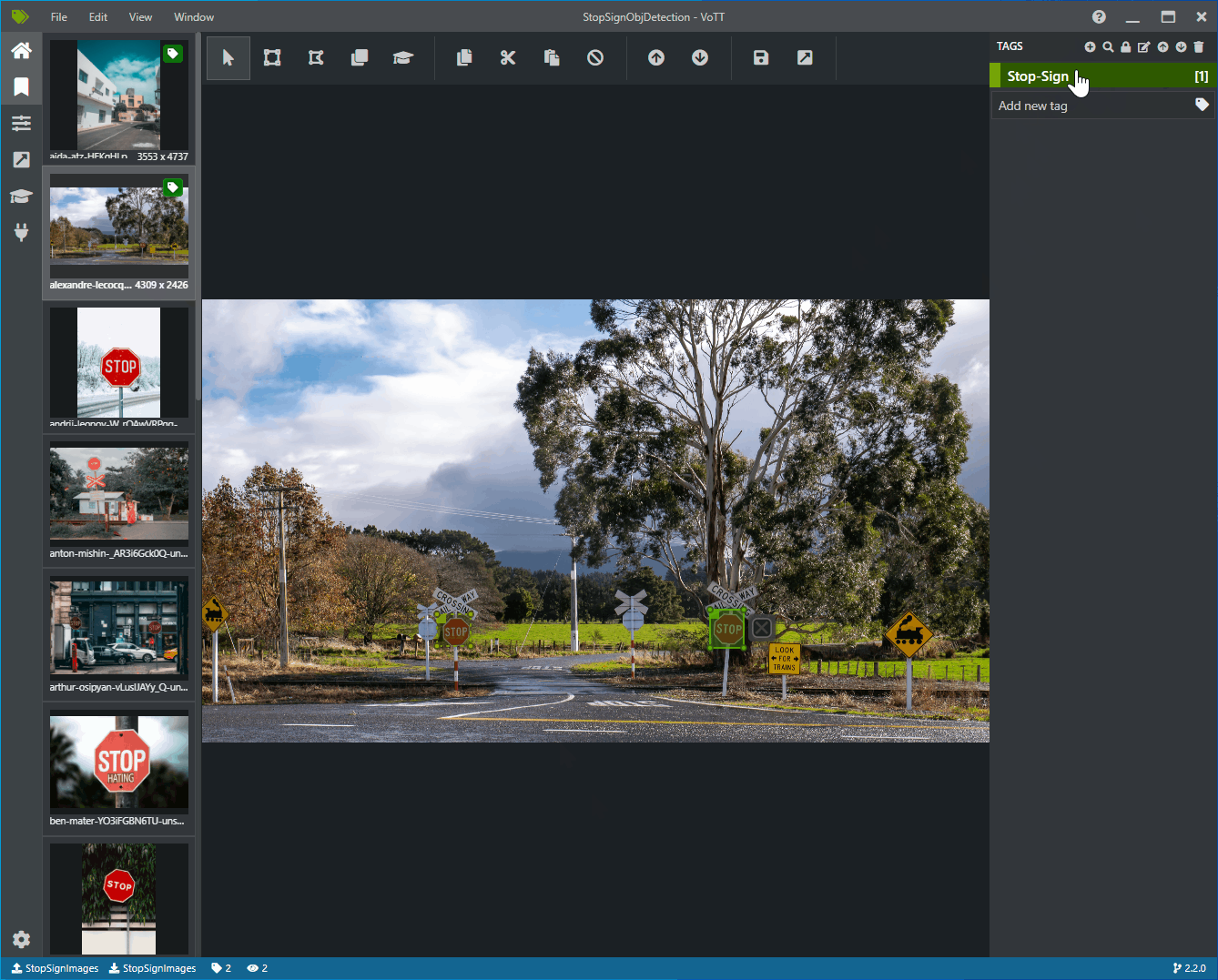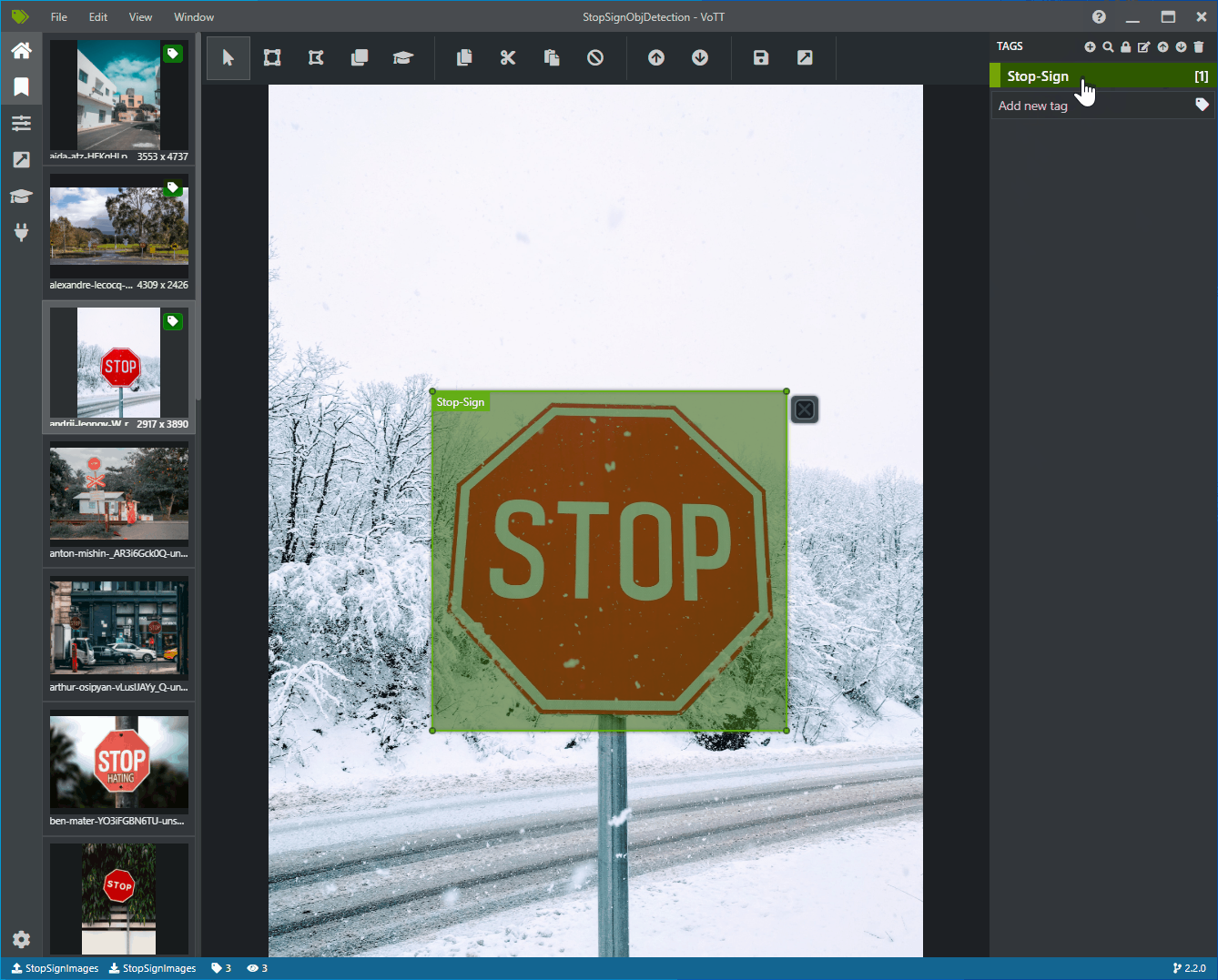
タグとラベルの画像を追加する
これで、左側にすべてのトレーニング画像のプレビュー画像、中央に選択した画像のプレビュー、右側に [タグ] 列があるウィンドウが表示されるはずです。 この画面は、タグ エディターです。
新しいタグを追加するには、 [タグ] ツールバーの最初 (プラス形) のアイコンを選択します。
![VoTT の [新しいタグ] アイコン](../how-to-guides/media/vott/vott-new-tag-icon.png)
タグに "Stop-Sign" という名前を付け、キーボードの Enter を押します。
![VoTT の [新しいタグ]](media/object-detection-model-builder/vott-new-tag.png)
クリックしてドラッグし、画像内の各一時停止標識の周囲に四角形を描画します。 カーソルで四角形を描画できない場合は、上部のツールバーから [四角形の描画] ツールを選択するか、キーボード ショートカット R を使用してください。
四角形の描画後、前の手順で作成した [Stop-Sign] タグを選択して、境界ボックスにタグを追加します。
データセット内の次の画像のプレビュー画像をクリックし、このプロセスを繰り返します。
すべての画像のすべての一時停止標識に対して、手順 3 から 4 を繰り返します。
VoTT JSON をエクスポートする
すべてのトレーニング画像をラベル付けしたら、Model Builder でトレーニングに使用されるファイルをエクスポートできます。
左側のツールバーの 4 番目のアイコン (ボックスに斜めの矢印があるもの) を選択し、 [エクスポート設定] に移動します。
[プロバイダー] は [VoTT JSON] のままにします。
[アセットの状態] を、 [タグ付きアセットのみ] に変更します。
[画像を含める] をオフにします。 画像を含める場合は、生成されるエクスポート フォルダーにトレーニング画像がコピーされますが、これは必要ではありません。
[エクスポート設定の保存] を選択します。
![VoTT の [エクスポート設定]](media/object-detection-model-builder/vott-export.png)
タグ エディター (リボンのような形をした、左側のツールバーの 2 番目のアイコン) に戻ります。 上部のツールバーで、 [プロジェクトのエクスポート] アイコン (ボックス内の矢印のような形をした最後のアイコン) を選択するか、キーボード ショートカットの Ctrl+E を使用します。
![VoTT の [エクスポート] ボタン](../how-to-guides/media/vott/vott-export-button.png)
このエクスポートによって、Stop-Sign-Images フォルダーに vott-json-export という新しいフォルダーが作成され、その新しいフォルダーに StopSignObjDetection-export という名前の JSON ファイルが生成されます。 この JSON ファイルは、次の手順で、Model Builder で物体検出モデルをトレーニングするために使用します。
コンソール アプリケーションの作成
Visual Studio で、StopSignDetection という C# .NET Core コンソール アプリケーションを作成します。
mbconfig ファイルの作成
- ソリューション エクスプローラーで、StopSignDetection プロジェクトを右クリックし、 [追加]>[機械学習モデル] を選択し、Model Builder UI を開きます。
- ダイアログで、Model Builder プロジェクトに StopSignDetection という名前を付け、 [追加] をクリックします。
シナリオを選択する
このサンプルの場合、シナリオは物体検出です。 Model Builder の [シナリオ] 手順で、 [物体検出] シナリオを選択します。
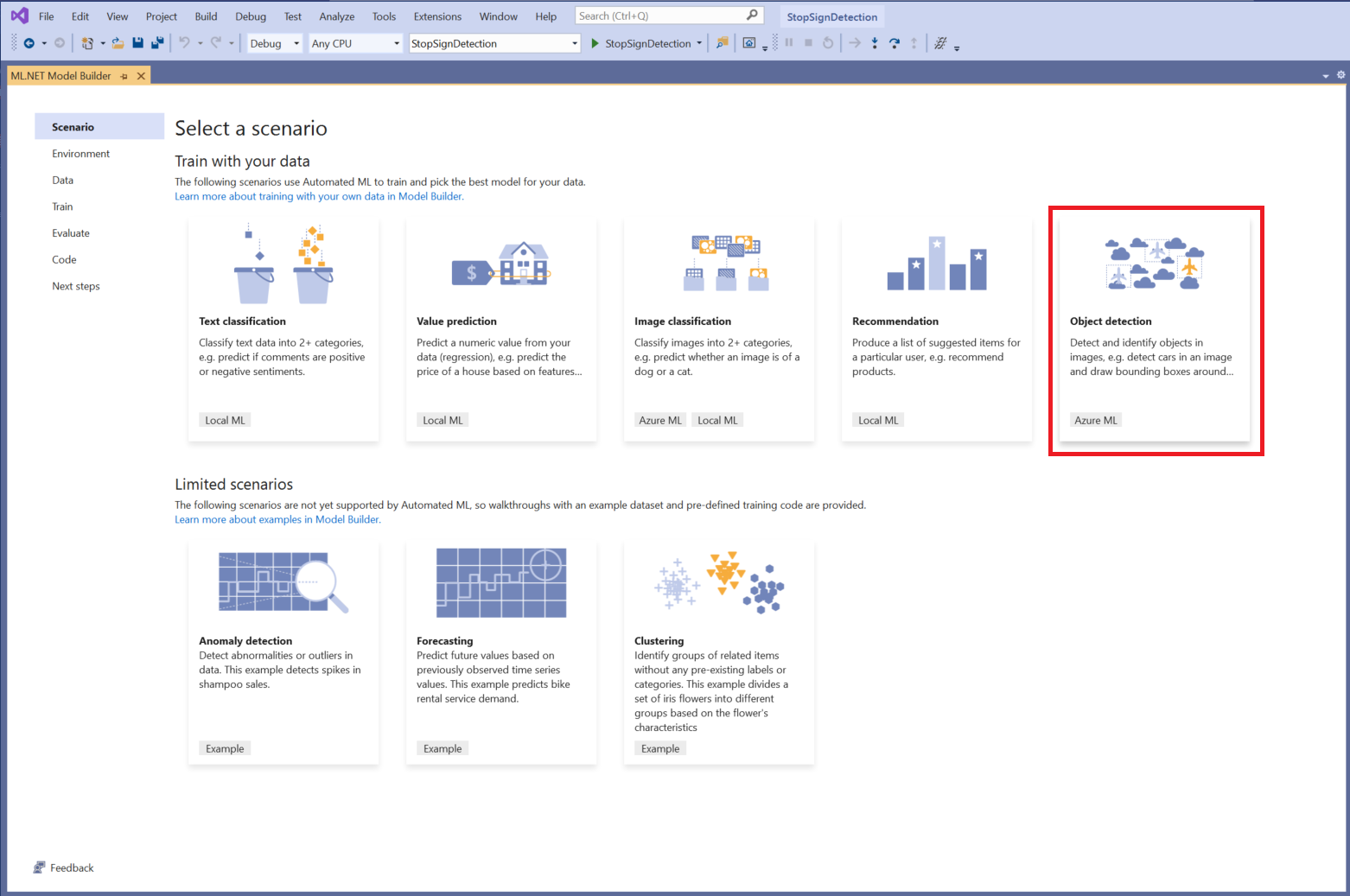
シナリオの一覧に [物体検出] が表示されない場合は、Model Builder のバージョンの更新が必要になることがあります。
トレーニング環境を選択する
現時点で、Model Builder では Azure Machine Learning による物体検出モデルのトレーニングのみがサポートされているため、既定で Azure トレーニング環境が選択されています。
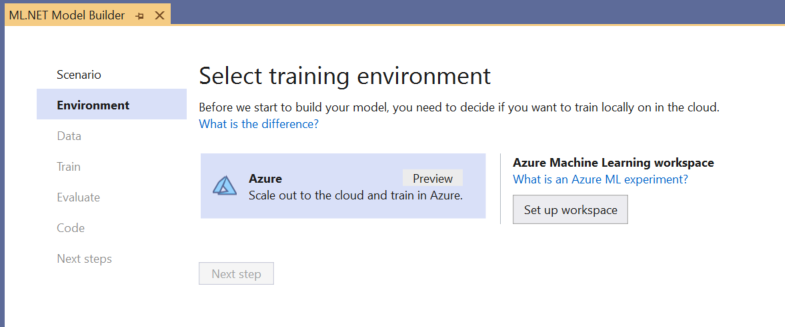
Azure ML を使用してモデルをトレーニングするには、Model Builder から Azure ML 実験を作成する必要があります。
Azure ML 実験は、1 回以上の機械学習トレーニングの実行の構成と結果をカプセル化するリソースです。
Azure ML 実験を作成するには、まず Azure で環境を構成する必要があります。 実験を実行するには、次のものが必要です。
- Azure サブスクリプション
- ワークスペース: トレーニング実行の一部として作成される Azure ML のすべてのリソースと成果物の一元的な場所を提供する Azure ML リソースです。
- コンピューティング: Azure Machine Learning コンピューティングとは、トレーニングに使用するクラウドベースの Linux VM です。 Model Builder でサポートされているコンピューティングの種類の詳細を確認してください。
Azure ML ワークスペースを設定する
環境を構成するには:
[ワークスペースの設定] ボタンを選択します。
[新しい実験の作成] ダイアログで、Azure サブスクリプションを選択します。
既存のワークスペースを選択するか、新しい Azure ML ワークスペースを作成します。
新しいワークスペースを作成する場合、次のリソースがプロビジョニングされます。
- Azure Machine Learning ワークスペース
- Azure Storage
- Azure Application Insights
- Azure Container Registry
- Azure Key Vault
そのため、このプロセスには数分かかることがあります。
既存のコンピューティングを選択するか、新しい Azure ML コンピューティングを作成します。 このプロセスは数分かかることがあります。
既定の実験名のままにして、 [作成] を選択します。
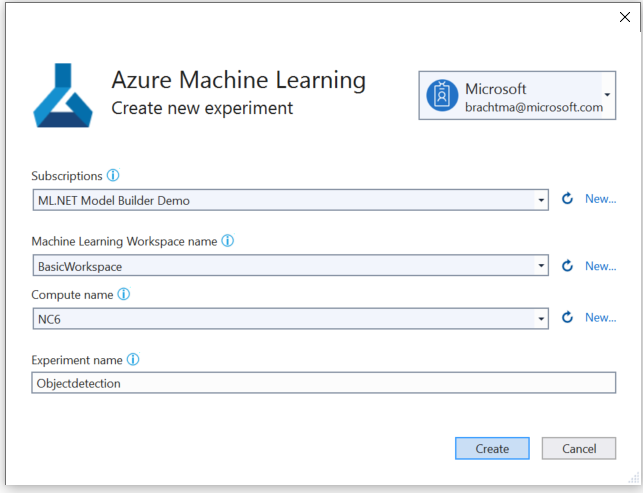
最初の実験が作成され、実験名がワークスペースに登録されます。 それ以降の実行は (同じ実験名を使用した場合)、同じ実験の一部としてログに記録されます。 そうでない場合は、新しい実験が作成されます。
構成に満足したら、Model Builder の [次のステップ] ボタンを選択して、 [データ] ステップに移動します。
データを読み込む
Model Builder の [データ] ステップで、トレーニング データセットを選択します。
重要
現在、Model Builder には、VoTT によって生成された JSON の形式のみを使用できます。
[入力] セクション内にあるボタンを選択し、エクスプローラーを使用して、Stop-Signs/vott-json-export ディレクトリにある
StopSignObjDetection-export.jsonを見つけます。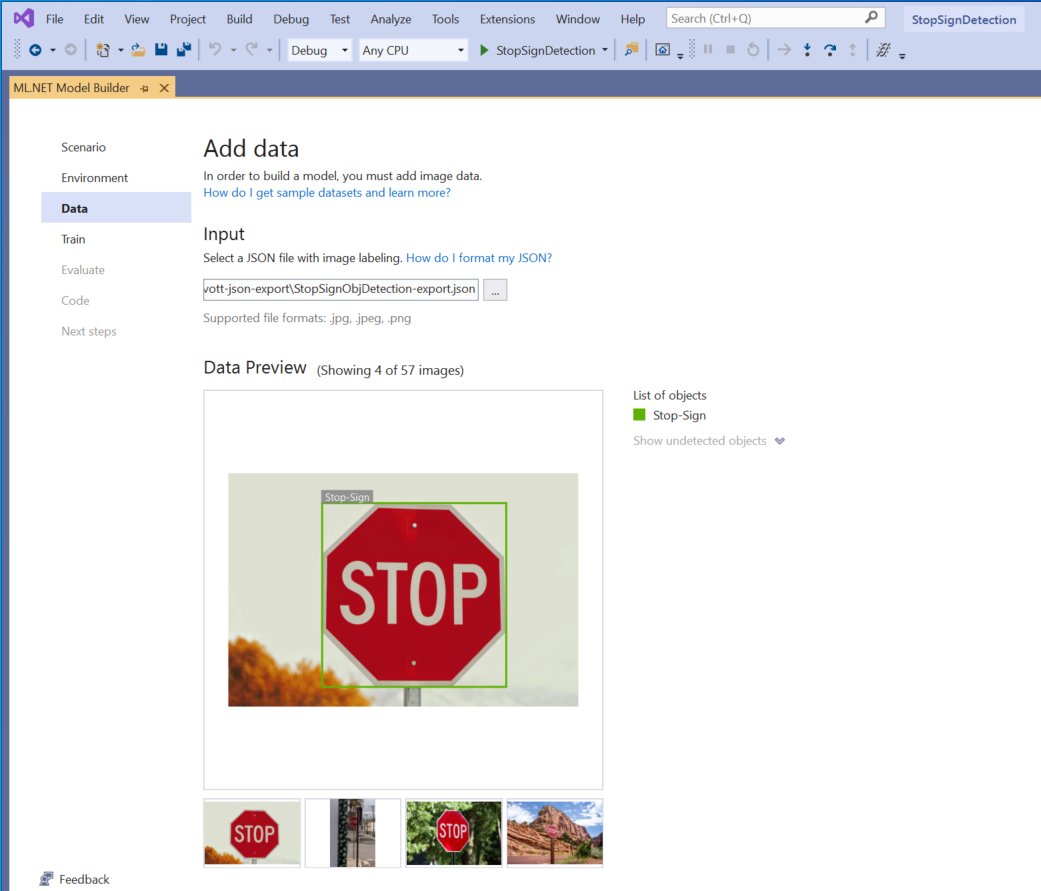
データ プレビューでデータが正しく表示されている場合は、 [次のステップ] を選択して、 [トレーニング] ステップに進みます。
モデルをトレーニングする
次のステップは、モデルをトレーニングすることです。
Model Builder の [トレーニング] 画面で、 [トレーニングの開始] ボタンを選択します。
この時点で、データは Azure Storage にアップロードされ、Azure ML でトレーニング プロセスが開始されます。
トレーニング プロセスには時間がかかり、この時間は選択したコンピューティングのサイズやデータ量によって変わります。 Azure でのモデルの初回トレーニング時は、リソースをプロビジョニングする必要があるため、トレーニング時間が若干長くなることが予想されます。 この 50 個の画像のサンプルでは、トレーニングに約 16 分かかりました。
Visual Studio で [Azure portal で現在の実行を監視する] リンクを選択すると、Azure Machine Learning ポータルで実行の進行状況を追跡できます。
トレーニングが完了したら、 [次のステップ] ボタンを選択して、 [評価] ステップに進みます。
モデルを評価する
[評価] 画面には、モデルの精度など、トレーニング プロセスの結果の概要が表示されます。
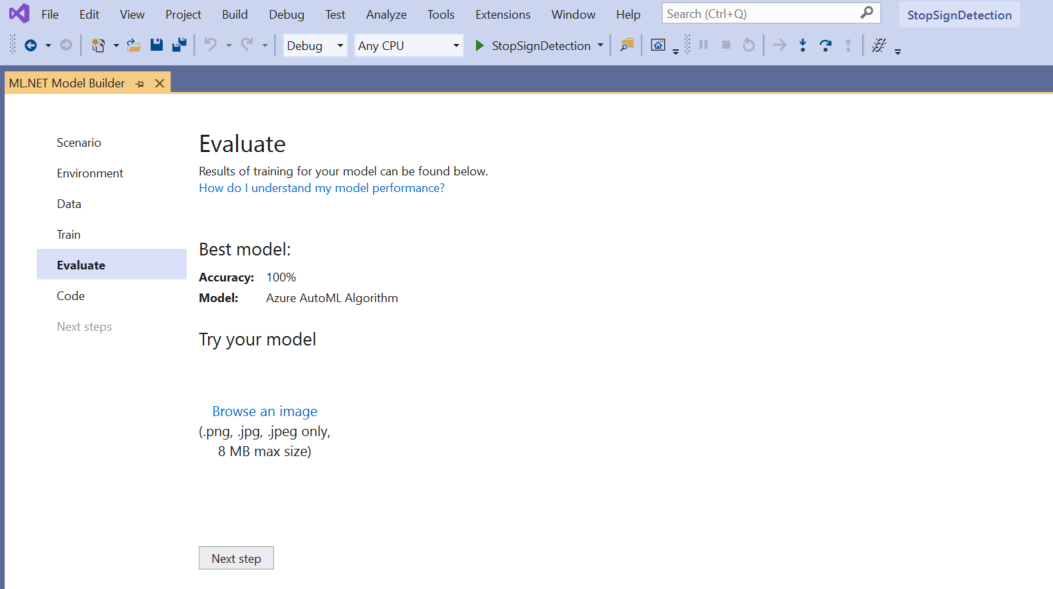
この例では、精度が 100% と表示されていますが、これは、データセット内の画像が少なすぎるため、モデルがオーバーフィットしている可能性がかなり高いことを意味します。
[独自のモデルを試す] 実験を使用して、モデルが想定どおりに実行されているかどうかをすばやく確認できます。
[画像の参照] を選択し、テスト画像 (できれば、モデルでトレーニングの一部として使用されていないもの) を提供します。
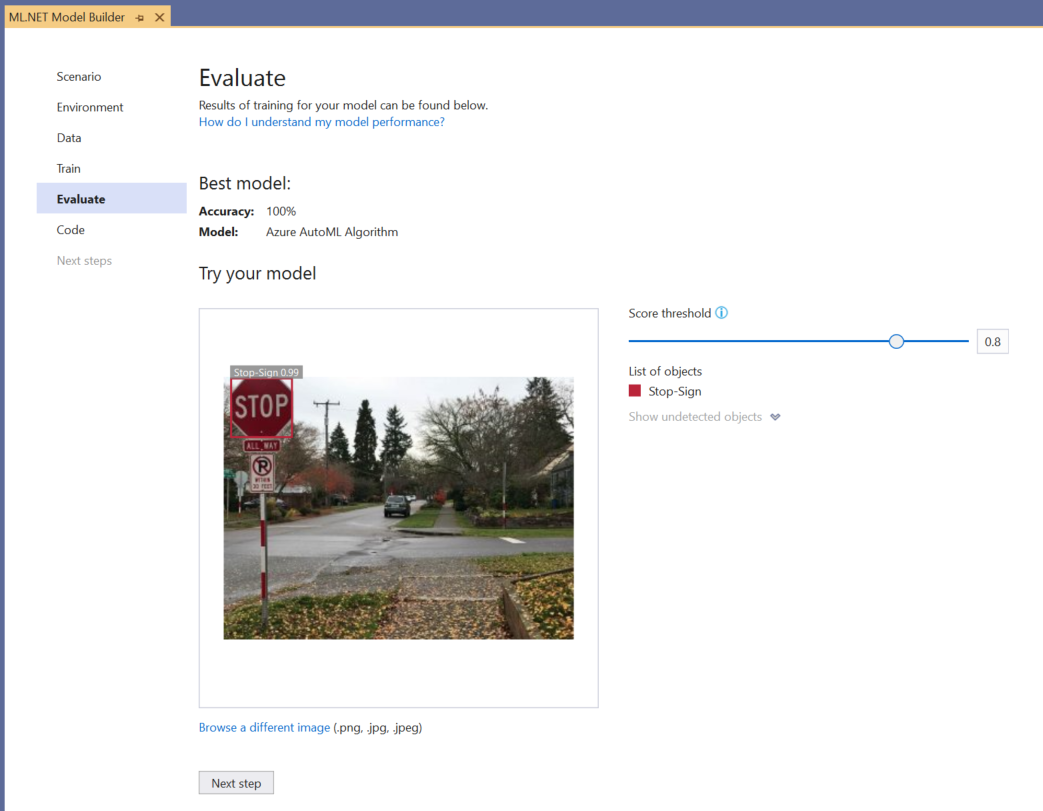
検出された各境界ボックスに表示されるスコアは、検出されたオブジェクトの信頼度を示します。 たとえば、上のスクリーンショットでは、一時停止標識を囲む境界ボックス上のスコアは、モデルで、検出されたオブジェクトは一時停止標識であることが 99% 確実であるとされていることを示しています。
スコアしきい値は、しきい値スライダーで増減でき、それらのスコアに基づいて検出されたオブジェクトが追加および削除されます。 たとえば、しきい値が 0.51 の場合、モデルには、信頼スコアが 0.51 以上のオブジェクトのみが表示されます。 しきい値を大きくするほど、検出されるオブジェクトが少なくなり、しきい値を小さくするほど、検出されるオブジェクトが多くなります。
精度のメトリックに不満がある場合、モデルの精度を高めるために試してみる簡単な 1 つの方法は、使用するデータを増やすことです。 そうでない場合は、 [次のステップ] リンクを選択して、Model Builder の [使用] ステップに進みます。
(省略可能) モデルを使用する
この手順では、モデルを使用するために使用できるプロジェクト テンプレートが用意されています。 この手順は省略可能であり、モデルの指定方法については、ニーズに合った方法を選択することができます。
- コンソール アプリ
- Web API
コンソール アプリ
コンソール アプリをソリューションに追加する場合、プロジェクトの名前を入力するように求めるプロンプトが表示されます。
コンソール プロジェクトに StopSignDetection_Console と名前を付けます。
[ソリューションに追加] をクリックして、現在のソリューションにプロジェクトを追加します。
アプリケーションを実行します。
プログラムによって生成される出力は次のスニペットのようになります。
Predicted Boxes: Top: 73.225296, Left: 256.89764, Right: 533.8884, Bottom: 484.24243, Label: stop-sign, Score: 0.9970765
Web API
Web API をソリューションに追加する場合、プロジェクトの名前を入力するように求めるプロンプトが表示されます。
Web API プロジェクトに StopSignDetection_API と名前を付けます。
[ソリューションに追加] をクリックして、現在のソリューションにプロジェクトを追加します。
アプリケーションを実行します。
PowerShell を開き、次のコードを入力します。PORT には、アプリケーションがリッスンしているポートを入力します。
$body = @{ ImageSource = <Image location on your local machine> } Invoke-RestMethod "https://localhost:<PORT>/predict" -Method Post -Body ($body | ConvertTo-Json) -ContentType "application/json"成功した場合、出力は次のテキストのようになります。
boxes labels scores boundingBoxes ----- ------ ------ ------------- {339.97797, 154.43184, 472.6338, 245.0796} {1} {0.99273646} {}boxes列には、検出されたオブジェクトの境界ボックス座標が示されます。 これらの値は、それぞれ左、上、右、下の座標に属します。labelsは、予測されたラベルのインデックスです。 この場合、値 1 は停止のサインです。scoresには、境界ボックスがそのラベルに属することをモデルがどの程度確信しているかを定義します。
注意
(省略可能) 境界ボックスの座標は、幅 800 ピクセル、高さ 600 ピクセルに正規化されます。 以降の後処理でお使いのイメージの境界ボックスの座標をスケーリングするには、次の操作を行います。
- 上と下の座標を元のイメージの高さで乗算し、左と右の座標を元のイメージの幅で乗算します。
- 上と下の座標を 600 で割り、左と右の座標を 800 で割ります。
たとえば、元のイメージの寸法の
actualImageHeightとactualImageWidth、およびpredictionと呼ばれるModelOutputが指定された場合、BoundingBox座標をスケーリングする方法は次のコード スニペットのとおりです。var top = originalImageHeight * prediction.Top / 600; var bottom = originalImageHeight * prediction.Bottom / 600; var left = originalImageWidth * prediction.Left / 800; var right = originalImageWidth * prediction.Right / 800;1 つのイメージに複数の境界ボックスがある場合は、イメージ内の各境界ボックスに同じプロセスを適用する必要があります。
おめでとうございます。 Model Builder を使用して、画像内の一時停止標識を検出する機械学習モデルを正常に構築しました。 このチュートリアルのソース コードは、dotnet/machinelearning-samples GitHub リポジトリにあります。
その他のリソース
このチュートリアルで説明しているトピックについて詳しくは、次のリソースを参照してください。
.NET
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示